






机器学习 — 介绍与工具
文章目录
一,机器学习定义
机器学习(Machine Learning)本质上就是让计算机自己在数据中学习规律,并根据所得到的规律对未来数据进行预测。
机器学习包括如聚类、分类、决策树、贝叶斯、神经网络、深度学习(Deep Learning)等算法。
机器学习的基本思路是模仿人类学习行为的过程,如我们在现实中的新问题一般是通过经验归纳,总结规律,从而预测未来的过程
二,机器学习的发展历史
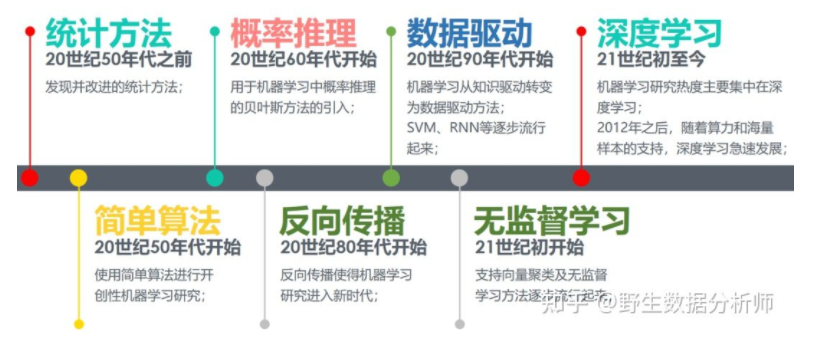
从上世纪50年代的图灵测试提出、塞缪尔开发的西洋跳棋程序,标志着机器学习正式进入发展期。
60年代中到70年代末的发展几乎停滞。
80年代使用神经网络反向传播(BP)算法训练的多参数线性规划(MLP)理念的提出将机器学习带入复兴时期。
90年代提出的“决策树”(ID3算法),再到后来的支持向量机(SVM)算法,将机器学习从知识驱动转变为数据驱动的思路。
21世纪初Hinton提出深度学习(Deep Learning),使得机器学习研究又从低迷进入蓬勃发展期。
从2012年开始,随着算力提升和海量训练样本的支持,深度学习(Deep Learning)成为机器学习研究热点,并带动了产业界的广泛应用。
三,机器学习分类
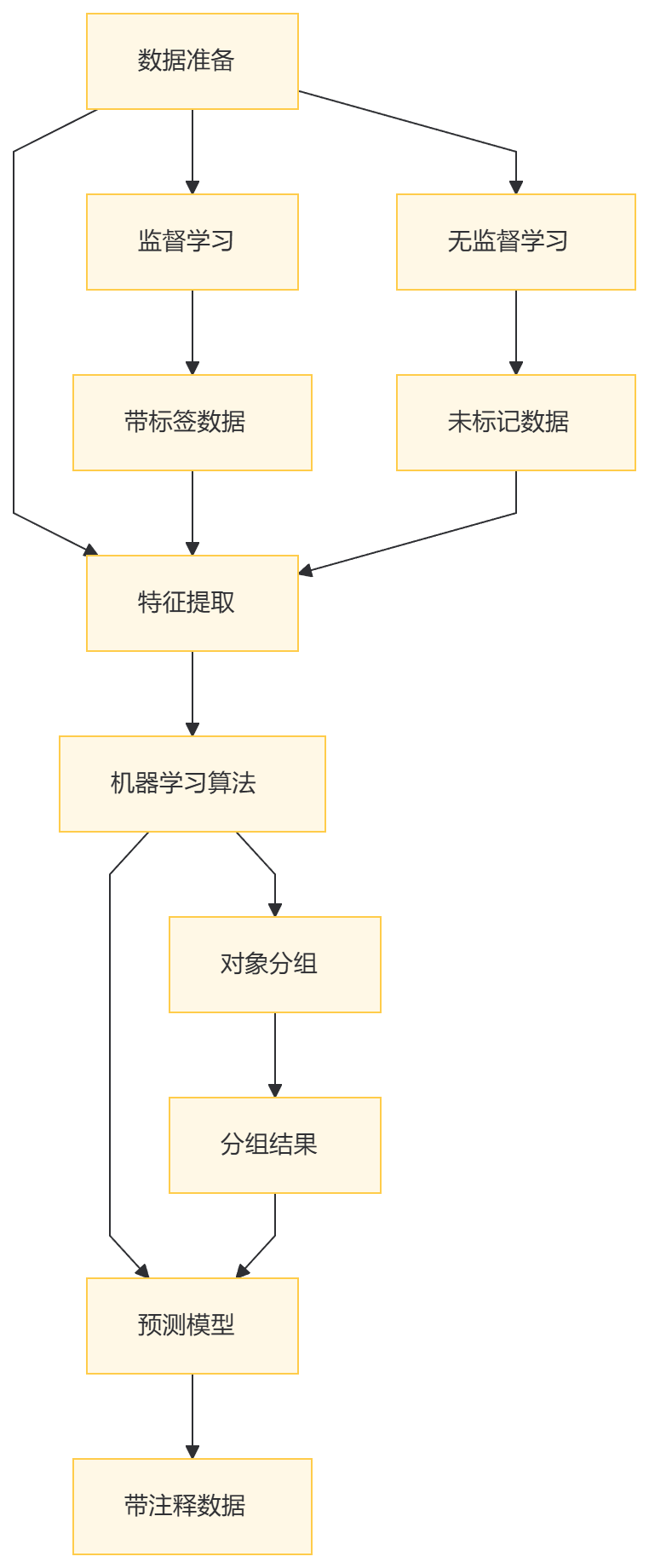
机器学习经过几十年的发展,衍生出了很多种分类方法,这里按学习模式的不同,可分为监督学习、半监督学习、无监督学习和强化学习。
3.1 监督学习
监督学习(Supervised Learning)是从有标签的训练数据中学习模型,然后对某个给定的新数据利用模型预测它的标签。如果分类标签精确度越高,则学习模型准确度越高,预测结果越精确。
- 回归:预测连续,具体的数值
常见的监督学习的回归算法有线性回归、回归树、K邻近、Adaboost、神经网络等
- 分类:预测非连续的,离散型数据
常见的监督学习的分类算法有朴素贝叶斯、决策树、SVM、逻辑回归、K邻近、Adaboost、神经网络等
3.2 半监督学习
半监督学习(Semi-Supervised Learning)是利用少量标注数据和大量无标注数据进行学习的模式。
半监督学习侧重于在有监督的分类算法中加入无标记样本来实现半监督分类。
常见的半监督学习算法有Pseudo-Label、Π-Model、Temporal Ensembling、Mean Teacher、VAT、UDA、MixMatch、ReMixMatch、FixMatch等。
3.3 无监督学习
无监督学习(Unsupervised Learning)是从未标注数据中寻找隐含结构的过程。
无监督学习主要用于关联分析、聚类和降维。
常见的无监督学习算法有稀疏自编码(Sparse Auto-Encoder)、主成分分析(Principal Component Analysis, PCA)、K-Means算法(K均值算法)、DBSCAN算法(Density-Based Spatial Clustering of Applications with Noise)、最大期望算法(Expectation-Maximization algorithm, EM)等。
3.4 强化学习
强化学习(Reinforcement Learning)类似于监督学习,但未使用样本数据进行训练,是是通过不断试错进行学习的模式。
在强化学习中,有两个可以进行交互的对象:智能体(Agnet)和环境(Environment),还有四个核心要素:策略(Policy)、回报函数(收益信号,Reward Function)、价值函数(Value Function)和环境模型(Environment Model),其中环境模型是可选的。
强化学习常用于机器人避障、棋牌类游戏、广告和推荐等应用场景中。
为了便于读者理解,用灰色圆点代表没有标签的数据,其他颜色的圆点代表不同的类别有标签数据。监督学习、半监督学习、无监督学习、强化学习
四,机器学习的应用场合
机器学习的应用场景非常广泛,几乎涵盖了各个行业和领域。以下是一些常见的机器学习应用场景的示例:
-
自然语言处理(NLP)
自然语言处理是人工智能中的重要领域之一,涉及计算机与人类自然语言的交互。NLP技术可以实现语音识别、文本分析、情感分析等任务,为智能客服、聊天机器人、语音助手等提供支持。
-
医疗诊断与影像分析
机器学习在医疗领域有着广泛的应用,包括医疗图像分析、疾病预测、药物发现等。深度学习模型在医疗影像诊断中的表现引人注目。
-
金融风险管理
机器学习在金融领域的应用越来越重要,尤其是在风险管理方面。模型可以分析大量的金融数据,预测市场波动性、信用风险等。
-
预测与推荐系统
机器学习在预测和推荐系统中也有广泛的应用,如销售预测、个性化推荐等。协同过滤和基于内容的推荐是常用的技术。
-
制造业和物联网
物联网(IoT)在制造业中的应用越来越广泛,机器学习可用于处理和分析传感器数据,实现设备预测性维护和质量控制。
-
能源管理与环境保护
机器学习可以帮助优化能源管理,减少能源浪费,提高能源利用效率。通过分析大量的能源数据,识别优化的机会。
-
决策支持与智能分析
机器学习在决策支持系统中的应用也十分重要,可以帮助分析大量数据,辅助决策制定。基于数据的决策可以更加准确和有据可依。
-
图像识别与计算机视觉
图像识别和计算机视觉是另一个重要的机器学习应用领域,它使计算机能够理解和解释图像。深度学习模型如卷积神经网络(CNN)在图像分类、目标检测等任务中取得了突破性进展。
五,机器学习趋势分析
机器学习正真开始研究和发展应该从80年代开始,深度神经网络(Deep Neural Network)、强化学习(Reinforcement Learning)、卷积神经网络(Convolutional Neural Network)、循环神经网络(Recurrent Neural Network)、生成模型(Generative Model)、图像分类(Image Classification)、支持向量机(Support Vector Machine)、迁移学习(Transfer Learning)、主动学习(Active Learning)、特征提取(Feature Extraction)
六,机器学习的开发步骤
- 收集数据:无论是来自excel,access,文本文件等的原始数据,这一步(收集过去的数据)构成了未来学习的基础。相关数据的种类,密度和数量越多,机器的学习前景就越好。
- 准备数据:任何分析过程都会依赖于使用的数据质量如何。人们需要花时间确定数据质量,然后采取措施解决诸如缺失的数据和异常值的处理等问题。探索性分析可能是一种详细研究数据细微差别的方法,从而使数据的质量迅速提高。
- 练模型:此步骤涉及以模型的形式选择适当的算法和数据表示。清理后的数据分为两部分 - 训练和测试(比例视前提确定); 第一部分(训练数据)用于开发模型。第二部分(测试数据)用作参考依据。
- 评估模型:为了测试准确性,使用数据的第二部分(保持/测试数据)。此步骤根据结果确定算法选择的精度。检查模型准确性的更好测试是查看其在模型构建期间根本未使用的数据的性能。
- 提高性能:此步骤可能涉及选择完全不同的模型或引入更多变量来提高效率。这就是为什么需要花费大量时间进行数据收集和准备的原因。
七,机器学习工具–scikit-learn

- Python语言机器学习工具
- Scikit-learn包括许多智能的机器学习算法的实现
- Scikit-learn文档完善,容易上手,丰富的API接口函数
- Scikit-learn官网
- Scikit-learn中文文档
- scikit-learn中文社区
- scikit-learn安装
https://www.sklearncn.cn/62/
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-learn


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









