







🌟想了解其它网安工具?看看这个:[网安工具] 网络安全工具管理 —— 工具仓库 · 管理手册
https://github.com/Threezh1/JSFinder![]() https://github.com/Threezh1/JSFinder
https://github.com/Threezh1/JSFinder
0x01:JSFinder 工具简介
JSFinder 是由开发者 Threezh1 等人维护的一款开源的工具,主要用于从网站的 JavaScript 文件中快速提取 URL 和子域名,以辅助安全研究人员进行渗透测试和信息收集。
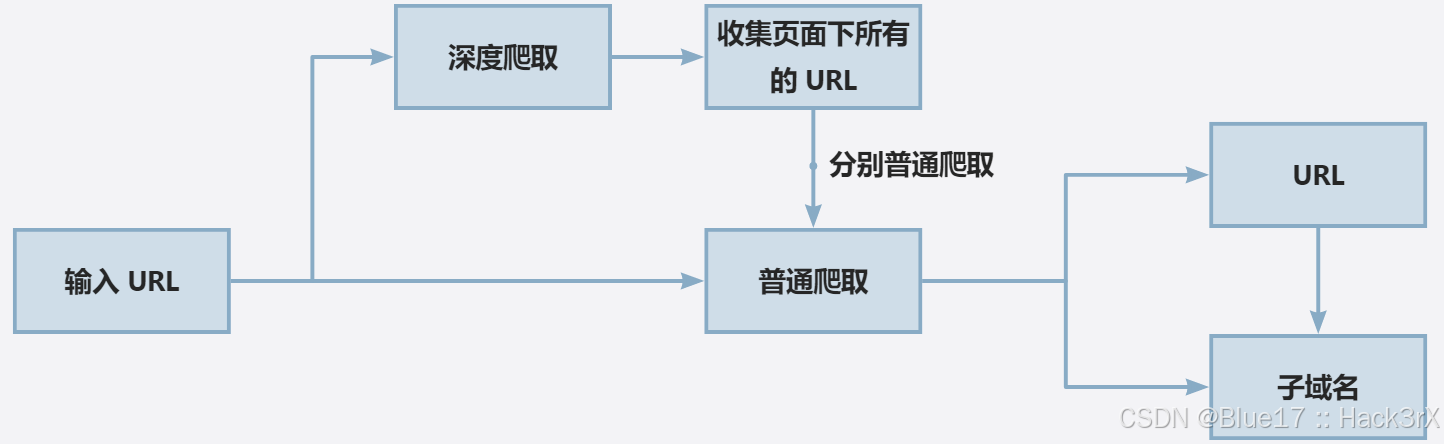
JSFinder 获取 URL 和子域名的流程如下图所示:
0x02:JSFinder 使用教程
注意:该工具的使用需要安装 Python 环境,笔者运行的环境是 Python 3.9.6
0x0201:JSFinder 工具安装
JSFinder 工具获取
JSFinder 依赖于 Python 3 的环境,读者从上面笔者提供的资源中下载好 JSFinder 后可以通过下面这个命令尝试运行 JSFinder.py:
python JSFinder.py -u http://www.baidu.com如果脚本成功运行,则证明安装成功,如果没能成功运行,并提示 No Module name xxx,则只需要把 xxx 替换掉下面的语句安装对应模块即可(这个就是证明缺少依赖包,安装一下就行):
pip install xxx0x0202:JSFinder 使用示例
本部分笔者将演示一些 JSFinder 的常见示例,如果你对该工具已经有所了解,仅仅是为了查询参数用法,可以跳转到本文的第三部分,即 “速查手册” 部分。
1. 对目标进行简单的爬取
使用下面的命令,不携带任何参数,JSFinder 就会爬取目标页面中所有的 js 链接,并在其中发现 URL 和子域名:
python JSFinder.py -u http://www.baidu.com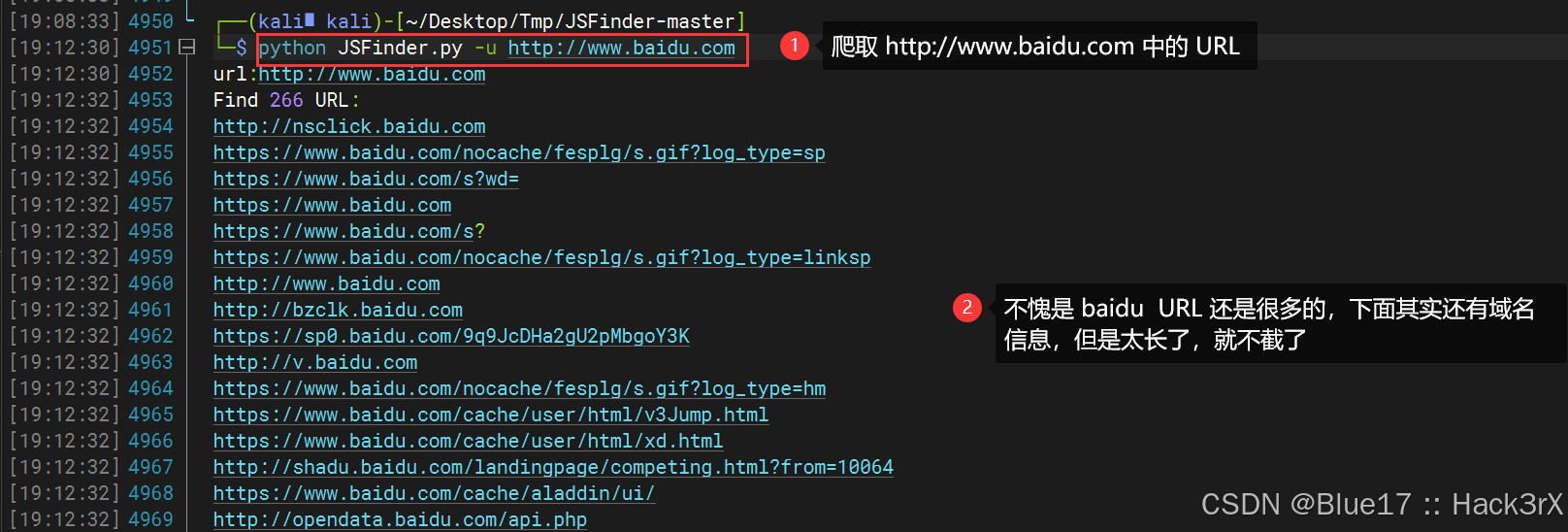
2. 对目标进行深度爬取
通过 -d 参数,JSFinder 可以深入一层页面来爬取 JS,但同时,这会消耗它更长时间(而且容易打偏,想想 Baidu 的那么多外链页面):
python JSFinder.py -u http://www.baidu.com -d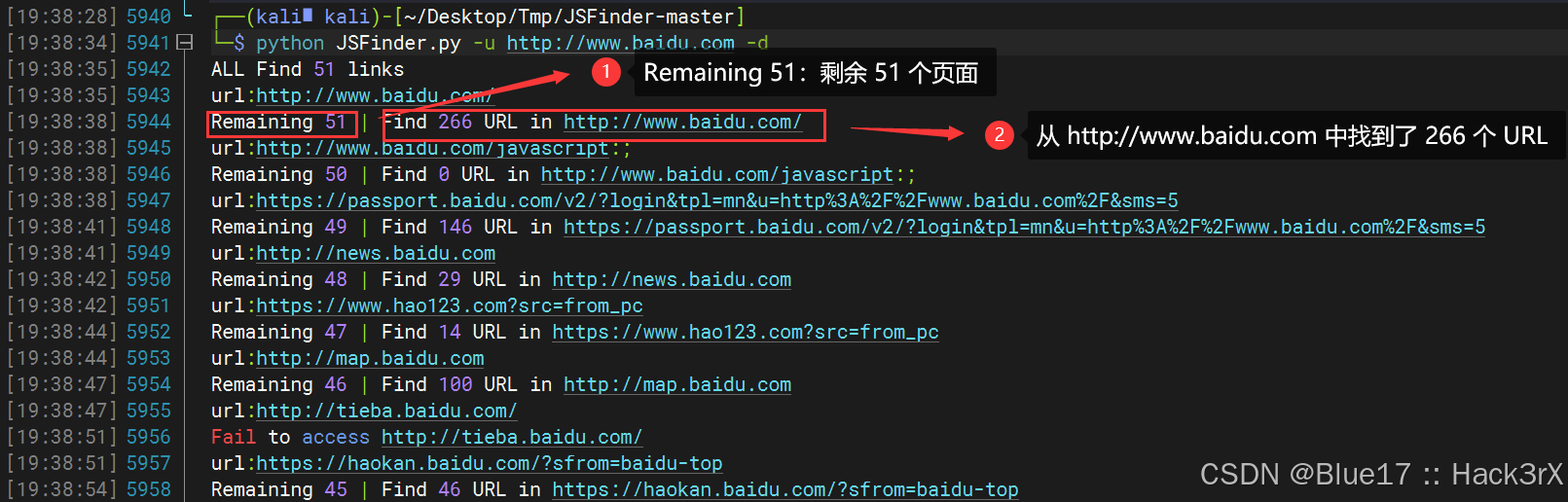
0x03:JSFinder 速查手册
0x0301:JSFinder 常见用法 — 速查表
### 爬取目标页面中所有的 js 链接,并在其中发现 URL 和子域名
python JSFinder.py -u http://www.baidu.com
### 深入一层页面爬取 JS,但会消耗更长的时间
python JSFinder.py -u http://www.baidu.com -d
### 将爬取的 URL & 域名分别进行存储
python JSFinder.py -u http://www.baidu.com -ou url.txt -os domain.txt
### 批量指定 URL / 指定 JS 进行爬取(不支持 -d 进行深度爬取操作)
# 批量指定 URL
python JSFinder.py -f url_list.txt
# 批量指定 JS
python JSFinder.py -f js_list.txt -j
### 指定 Cookie 来爬取页面
python JSFinder.py -u http://www.mi.com -c "session=xxx"0x0302:JSFinder 参数说明 — 中文版
用法:
JSFinder.py [options]
选项:
-h, --help
查看帮助信息
-u <URL>, --url <URL>
要扫描的目标网站
-c <COOKIE>, --cookie <COOKIE>
网站的 Cookie 凭证信息
-f <FILE_PATH>, --file <FILE_PATH>
从文件里读取一堆网址或 JS 文件路径
-ou <FILE_PATH>, --outputurl <FILE_PATH>
把找到的 URL 链接存放到用户指定的文件中
-os <FILE_PATH>, --outputsubdomain <FILE_PATH>
把发现的子域名保存到用户指定的文件中
-j, --js
批量从 JS 文件查找链接
-d, --deep
深度扫描(深入一层页面爬取 JS,但时间会消耗的更长)


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











