







目录
http协议就是上层,也就是应用层协议,该协议为超文本传输协议,其中我们经常使用的链接就是 https 协议。
URL
URL就是网址,网址是分为几部分的:

-
http表示协议名
-
:// 后面是登录信息
-
@后面是域名
-
:后面是端口号,默认80
-
/是web根目录
-
?后面是参数
urlencode和urldecode
在URL中式不能出现特殊字符的,如果出现了特殊字符是需要编码的,等到了对端是需要解码的。
例如:
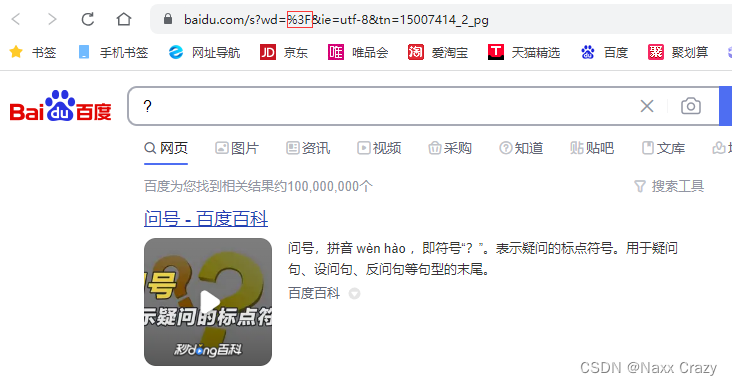
?就会被转成3F,其实中文也是需要编码的!
而解码就是编码的逆向。
HTTP请求
在前面的协议那里,我们自己定了一个协议,我们自己定的协议也是应用层协议,而http协议也是应用层协议,本质上这两个协议是没什么区别的,但是我们自己定的协议是为了学习协议,而并不是为了超越!
既然是协议,那么一定是有请求就有响应,先看一下HTTP协议的请求:
http协议主要分为四部分:
-
请求行
-
请求报头
-
空行
-
正文
就是上面的这四部分,其中请求行里面有三个字段,每个字段使用空格隔开:
-
请求方法:get put 一般就是这两种方法
-
URL:就是想要请求的资源路径,如果不带路径的话,那么就是默认web根目录
-
协议/版本
还有后面的几个字段:
-
请求报头:里面是有很多字段的,其中包括了 Content-Type: 表示传输的文本类型,还有 Content-Length: 表示正文的长度...
-
空行:\r\n, 而上面的每一部分都使用 \r\n 隔开,而请求报头中也是有很多行的也使用 \r\n 隔开
-
正文:正文就是需要传输的内容
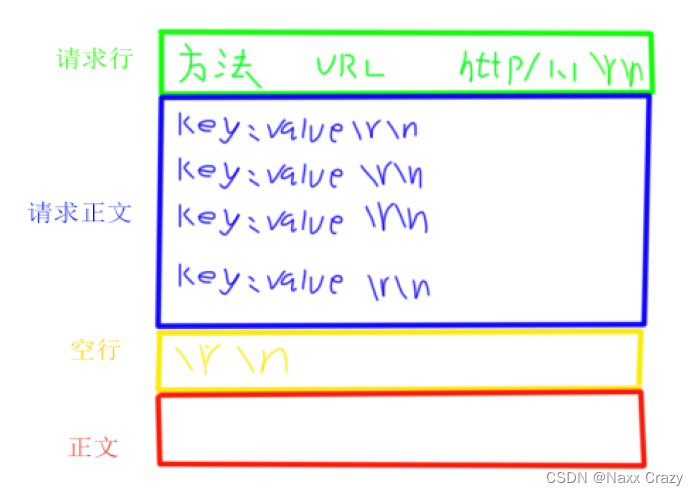
HTTP方法
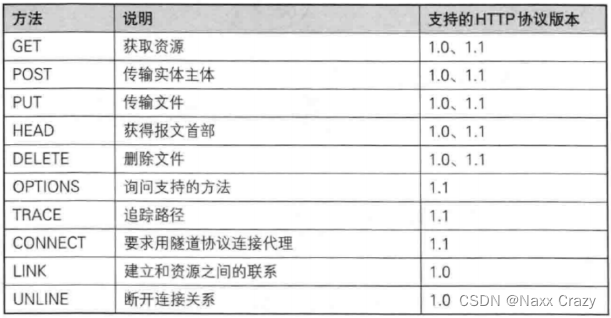
HTTP响应
http响应和http请求差不多,只有第一行是有区别的,http响应也是四部分:
-
状态行
-
响应报头
-
空行
-
正文
只有第一行是有区别的,第一行里面分为三部分:
-
协议/版本
-
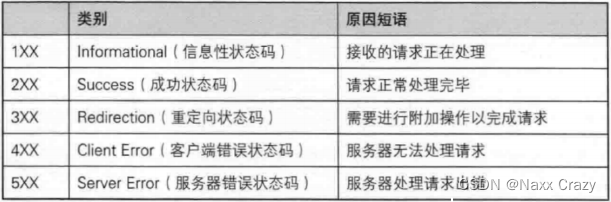
状态码:其中状态码是有很多种的,如果是成功的话 200 表示 OK,还有就是常见的 404 表示没有该资源
-
状态码描述:200 就是 OK,404 的描述就是 NotFound

HTTP状态码及描述
如何解包和向上交付
对于我们以后学习的协议,我们需要研究的是两个问题:
1.如何解包
下面有几个问题:
1.怎么把分开报头与有效载荷
在前面的HTTP协议中,我们知道HTTP协议中主要是四部分,正文在空行的后面,所以如果我们想要区分有效载荷和报头,空行前面的就是报头,而后面的就是有效载荷,所以通过空行,我们就可以分开报头与有效载荷。
2.怎么将正文全部读取完毕
在HTTP报头里面,有一个字段 Content-Length: 字段,该字段表示的就是正文的长度,所以通过该字段,我们可以将正文读取完
2.如何向上交付
因为这里是HTTP协议,也就是应用层协议,所以不需要关心向上交付,但是在后面的传输层协议,以及网络层,数据链路层都是需要关心如何向上交付的。
看——HTTP协议
下面,我们写一个代码来看一下HTTP协议:
这里我们会用到很多之前写过的东西,比如Sock类,还有其他的一些内容,下面我们就写一个代码,就是将读取到的数据打印出来:
下面的这个是 .hpp 文件
typedef std::function<void(int)> callBack_t;
class HttpServer
{
public:
HttpServer(uint16_t port, callBack_t callBack)
: _port(port), _callBack(callBack)
{
// 1. 创建套接字
_listensock = _sock.Socket();
log(INFO, "创建监听套接字成功~");
// 2. bind
_sock.Bind(_listensock, _port);
log(INFO, "bind 成功~");
// 3. 设置监听套接字
_sock.Listen(_listensock);
log(INFO, "设置监听套接字成功~");
}
void start()
{
struct sockaddr_in peer;
socklen_t len;
while (true)
{
int sock = _sock.Accept(_listensock, (struct sockaddr *)&peer, &len);
log(INFO, "获取到一个新链接 sock: %d", sock);
if (fork() == 0)
{
// 子进程关闭不需要的监听套接字
close(_listensock);
_callBack(sock);
// 子进程执行结束,关闭掉 sock
close(sock);
exit(0);
}
// 父进程关闭掉 sock
close(sock);
}
}
private:
Sock _sock; // 套接字接口
uint16_t _port; // 端口号
callBack_t _callBack; // 回调函数
int _listensock;
static Log log;
};
Log HttpServer::log;下面这个是 .cc 文件:
#include "httpServer.hpp"
#include <memory>
#include <vector>
#include <string>
#include "Usage.hpp"
#include <fstream>
#include "Util.hpp"
#define WWWROOT "./wwwroot"
void httpServer(int sockfd)
{
char buffer[10240];
ssize_t s = recv(sockfd, buffer, 10240, 0);
if (s > 0)
{
buffer[s] = 0;
std::cout << buffer << std::endl;
}
}
int main(int argc, char *argv[])
{
if (argc != 2)
{
Usage(argv[0]);
exit(0);
}
std::unique_ptr<HttpServer> sev(new HttpServer(atoi(argv[1]), httpServer));
sev->start();
return 0;
}这里就是我们启动服务器,然后我们调用对应的方法,最后会执行 httpServer 函数,该函数会读取请求,然后打印出来。
结果:
[INFO] [2023-12-10 14:54:23] 获取到一个新链接 sock: 4
GET / HTTP/1.1 —— 这个就是请求行
Host: 60.204.198.212:8080 —— 从这行开始到
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9 —— 到这里中间都是请求报头
—— 这行是空行,因为没有正文,所以不显示那么我们可以如何响应一个HTTP呢?
如果我们想响应一个,那么我们只需要在 httpServer 函数里面编写即可:
-
我们先对读取到的内容做解析,我们将每一行的内容都拿出来。
-
然后我们拿到请求行的文件路径,如果没有带路径那么就是默认是 / (表示web根目录)
-
拿到文件路径后,我们打开文件,如果打开失败,说明没有该文件,我们就需要返回 404 表示NotFound
-
打开成功后,我们读取文件内容,而文件内容就是正文
-
后面可构建响应,其中响应的格式我们也说过了,我们在代码里面体现
返回 HTTP 响应
这里我们打算返回一个很简单的响应,hello world,我们通过 html 来返回:
void httpServer(int sockfd)
{
char buffer[10240];
ssize_t s = recv(sockfd, buffer, 10240, 0);
if (s > 0)
{
buffer[s] = 0;
std::cout << buffer << std::endl;
}
// 响应的状态行
std::string response = "HTTP/1.1 200 OK\r\n";
// 空行
response += "\r\n";
// 正文
response += "<h1>hello world</h1>";
send(sockfd, response.c_str(), response.size(), 0);
}结果:
我们就获取到了对应的数据。
下面我们还要做什么?我们可以在网络上随便找一些 html 的代码,然后放在一个特定的文件中,我们进行请求,看是否可以请求到内容:
1.对HTTP请求解析
既然是切分字符串,那么我们写一个函数,可以指定分隔符切割,将切割好的字符串放在一个 vector<string> 的容器中,下面的这个函数就不介绍了:
#pragma once
#include <iostream>
#include <vector>
#include <string>
class Util
{
public:
static void cutString(const std::string& str, const std::string& sep, std::vector<std::string>* out)
{
size_t start = 0;
while(true)
{
ssize_t pos = str.find(sep, start);
if(pos != start) out->push_back(str.substr(start, pos - start));
if(pos == std::string::npos) break;
start = pos + sep.size();
}
}
};那么我们就可以开始切分:
void httpServer(int sockfd)
{
char buffer[10240];
ssize_t s = recv(sockfd, buffer, 10240, 0);
if (s > 0)
{
buffer[s] = 0;
std::cout << buffer << std::endl;
}
// 将每一行都读取出来
std::vector<std::string> httpLine;
Util::cutString(buffer, "\r\n", &httpLine);
for (auto &str : httpLine)
{
std::cout << ">" << str << std::endl;
}
std::cout << "\n";
// 将第一行的 方法 URL 协议/版本 提取出来
std::vector<std::string> reqLine;
Util::cutString(httpLine[0], " ", &reqLine);
for (auto &str : reqLine)
{
std::cout << ">>" << str << std::endl;
}
}结果:
对每一行的解析
>GET / HTTP/1.1
>Host: 60.204.198.212:8080
>Connection: keep-alive
>Cache-Control: max-age=0
>Upgrade-Insecure-Requests: 1
>User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36
>Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
>Accept-Encoding: gzip, deflate
>Accept-Language: zh-CN,zh;q=0.9
>
对第一行的解析
>>GET
>>/
>>HTTP/1.12.构建HTTP响应
解析完成后,我们就可以构建响应,如果有对应的文件,那么就是可以返回,将文件内容构建为响应的正文,如果没有文件,那么就是 404
void httpServer(int sockfd)
{
char buffer[10240];
ssize_t s = recv(sockfd, buffer, 10240, 0);
if (s > 0)
{
buffer[s] = 0;
std::cout << buffer << std::endl;
}
// 将每一行都读取出来
std::vector<std::string> httpLine;
Util::cutString(buffer, "\r\n", &httpLine);
// 将第一行的 方法 URL 协议/版本 提取出来
std::vector<std::string> reqLine;
Util::cutString(httpLine[0], " ", &reqLine);
// 构建http响应
std::string httpResp;
// 找到想打开是目标文件
std::string filePath(reqLine[1]);
// 对目标文件路径进行初始化
filePath = WWWROOT + filePath; // WWWROOT 是宏 ./wwwroot
// 定义 fstream 对象
std::fstream in;
// 打开文件
in.open(filePath);
// 判断是否打开文件成功
if (!in.is_open())
{
// 打开失败,说明没有该文件
httpResp = "http/1.1 404 NotFound\r\n";
httpResp += "\r\n";
}
else
{
// 打开成功,文件的内容就是正文
httpResp = "http/1.1 200 OK\r\n";
httpResp += "\r\n";
// body 是正文内容
std::string body, line;
while (std::getline(in, line))
{
body += line;
}
// http报头里面还有一项是正文长度
// httpResp += "Content-Length:";
// httpResp += std::to_string(body.size());
httpResp += body;
}
send(sockfd, httpResp.c_str(), httpResp.size(), 0);
}结果:
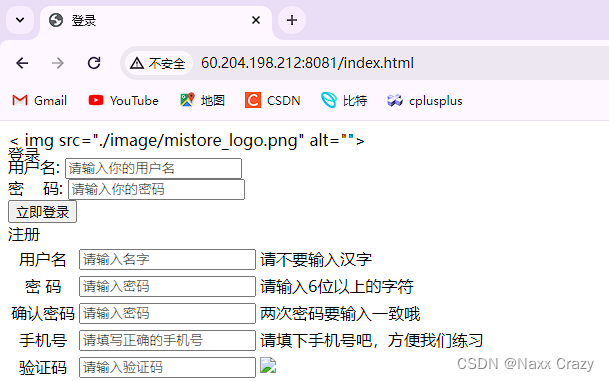
里面的 html 就是随便复制的,不需要关心。
上面,我们的HTTP响应里面没有带响应报头,里面只有状态行、空行、正文,其实现在的浏览器以及是很强大了,所以即使我们不带报头也是没问题,但是这里是实验,所以就不带了,因为响应报头里面的那些字段还是比较麻烦的。
HTTP的方法
我们上网一般有两种需求:
1.请求资源
2.上传资源
而HTTP协议中的方法有两种最为常用:GET POST
GET:表示从网络中获取资源。
POST:表示上传资源。
但是GET方法也可以上传资源,那么这两种方法有什么不同呢?

HEAD:表示获取响应的报头,正文不要,其中是有很多方法用户是无法使用的,所以一般我们使用的就是POST和GET,下面我们看一下这两种方法提交数据的区别。
如果测试GET和POST提交方法的区别,最好就是使用表单,下面我们也可以搜索一个简单的表单,来验证一下:
<form action="/a/b/c/index.html" method="get">
<input type="text" name="username"><br>
<input type="password" name="pwd"><br>
<input type="submit">
</form>这就是一个超级简单的表单,这个只能用于提交数据,其中 action 后面就是提交后的数据交给哪一个资源,method 表示使用什么方法,下面先看一下表单的结果:

输入 zhangsan 123456 就是这样,所以我们现在提交一下

使用 get 方法提交后,我们看到 url 里面路径后面拼接上了我们的 username 和 pwd 这样的私密性就比较低了,那么我们下面使用 post 方法,只需要把 get 换为 post 即可
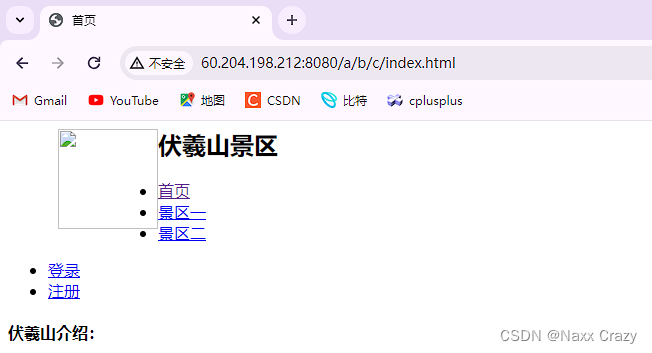
这是 post 方法提交后的结果,没有把账户和密码添加到后面
这就是这两种方法的区别,虽然说 get 方法也可以将数据提交给服务器,但是并不建议这样做,因为get方法是在url里面提交,所以一定是有限制的。
而post方法是通过正文提交的,所以不需要担心传输的大小,所以一般我们传输音频,视频等默认使用post方法提交。
HTTP handlet
handler 就是请求报头,请求报头有很多,但是我们不一定都要带,例如:没有正文的话,就可以不带 Content-Length 字段。所以我们可以不带,下面看几个常见的:
-
Content-Type: 因为 HTTP 协议是超文本传输协议,所以我们是需要区分传输的类型的,所以该字段表示传输类型,传输类型里面有 .html 表示静态网页,.jpg 表示是图片...
-
Content-Length: 表示是正文的长度,没有正文的话,可以不带
-
Host: 表示主机ip及端口
-
Connection: 表示连接方法,如果是 keep-alive 表示长连接
还有很多的 handler 有需要的可以自己查一下。
HTTP 特性
最后就是http的特点,http协议是超文本传输协议:
-
速度快
-
灵活
-
无连接
-
无状态
速度快就不需要解释了,那么为什么灵活?
在HTTP报头里面有一个 Content-Type的字段,表示传输的是什么类型,所以就是灵活。
还有就是无连接?为什么是无连接呢?HTTP协议的底层使用的是TCP协议,可是TCP协议是有连接的呀?这里就需要区分HTTP协议和TCP协议了,虽然TCP协议是有连接的,但是HTTP协议一般只会处理一个请求,然后就会断开连接,所以是无连接的,但是现在也是有长连接的,表示一直连接,所以HTTP协议是无连接的。
还有就是HTTP协议是无状态的,为什么说是无状态呢?无状态是什么意思?
无状态的意思就是,HTTP协议不会记录用户的状态信息,也就是HTTP协议不能区分用户是否来自同一台服务器,每一个请求都是独立的,而且HTTP协议也不会记录用户的历史信息。
既然不会记录历史信息,那么如果我们登录一个网站的时候,为什么我们下一次登录的时候,还是登录状态?不是说HTTP协议是无状态的吗?
虽然HTTP协议是无状态的,但是浏览器可以帮助记录。
在HTTP协议中有一个 cookie: 是请求带的请求报头 和 setcookie: 是响应带的表示设置 cookie 信息。
而当我们响应里面带了 Set-Cookie: 那么就会把 cookie 信息设置到对方的内存/文件里面,有了 cookie 信息就可以帮助我们HTTP协议可以记录,但是Cookie如果是文件的话,那么是不够隐私的,因为如果 cookie 在文件里面,那么别人打开 cookie 就可以看到我们的账号和密码,所以并不是单单采用 cookie 而是采用 cookie 和 session ,cookie 里面保存的是唯一值,而 session 里面才保存的是重要信息,而有了 cookie 里面的为一值就可以找到对应的 session 了,而 session 在服务器端,所以被别人看到的概率较低。
下面我们可以设置一下 cookie ,而当设置了 cookie ,当下一次请求的时候,会自动携带 cookie 信息。
我们以及在我们的代码里面设置了 cookie 信息,所以当我们新一次请求的时候,就会再一次协议。
结果:
// 打开成功,文件的内容就是正文
httpResp = "http/1.1 200 OK\r\n";
// body 是正文内容
std::string body, line;
while (std::getline(in, line))
{
body += line;
}
httpResp += "Content-type: text/html\r\n";
// http报头里面还有一项是正文长度
httpResp += "Content-Length: ";
httpResp += std::to_string(body.size()) + "\r\n";
httpResp += "Set-Cookie: 我是一个 cookie 信息\r\n";
// 空行
httpResp += "\r\n";
httpResp += body;上面就是设置 cookie 截取的一段代码,倒数第四行就是将设置一个 cookie 的报头添加到响应中了,我们请求的时候,我们看一下是否会携带 cookie 信息。
结果:
GET /a/b/c/img/%E7%BA%A2%E7%9F%B3%E6%9E%974.jpg HTTP/1.1
Host: 60.204.198.212:8080
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36
Accept: image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8
Referer: http://60.204.198.212:8080/a/b/c/index.html
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: 我是一个 cookie 信息; 我是一个 cookie 信息这里就带上了我们设置的 cookie 信息。
















 1562
1562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











