






 本文详细介绍了多元线性回归的基本概念、一元线性回归模型、回归系数的解释、内生性问题及其解决方法,包括蒙特卡罗模拟验证、标准化回归和Stata工具的应用。讨论了拟合优度R²的评估标准和对数据处理(如取对数)的需求。
本文详细介绍了多元线性回归的基本概念、一元线性回归模型、回归系数的解释、内生性问题及其解决方法,包括蒙特卡罗模拟验证、标准化回归和Stata工具的应用。讨论了拟合优度R²的评估标准和对数据处理(如取对数)的需求。
多元线性回归[清风正7]
回归分析
研究X和Y之间相关性的分析
1.相关性 != 因果性
2.X自变量 Y因变量[核心]
使命:
1、识别重要变量[“变量选择” 逐步回归法]
2、判断相关性的方向[正/负]
3、估计权重[回归系数]
分类:
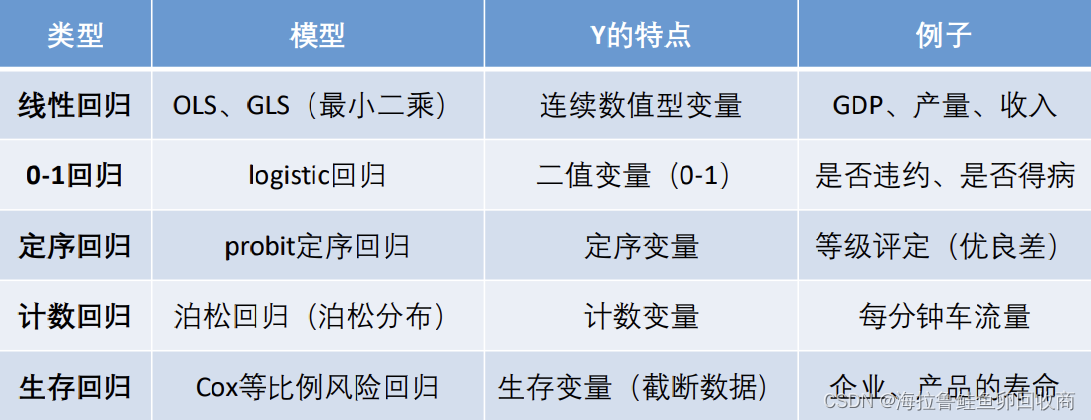
数据分类:
1、横截面数据:在某一时间点收集的不同对象的数据[多元线性回归]
2、时间序列分析:对同一对象在不同时间连续观察所取得的数据[移动平均、指数平滑、ARIMA、GARCH\VAR、协积]
3、面板数据:横截面数据+时间序列
数据来源:经管之家(原经济论坛)-国内活跃的经济、管理、金融、统计在线教育和咨询网站 (pinggu.org)
一元线性回归
回顾一元线性函数拟合:设置拟合曲线 y = kx + b
[k,b使得后面括号内函数最小]
令最小,求导,令一阶导数为0
(L在机器学习中被称为损失函数,在回归中被称为残差平方和)
一元线性回归模型
x、y满足线性关系:
其中、
是回归系数,
为无法观测的且满足一定条件的扰动项
令预测值
其中,
为残差
线性假定并不要求初始模型都呈严格线性关系,自变量与因变量可以通过变量替换而转化乘线性模型。
回归系数的解释
引入新的自变量可能对回归系数影响很大 ——> 遗漏变量导致的内生性
μ为无法观测的且满足一定条件的扰动项
如果满足 误差项μ和所有自变量x均不相关,则称该回归模型具外生性
如果相关则存在内生性,回归系数估计不准确:不满足无偏和一致性
[包含了所有与y相关,但未添加到回归模型中的变量
如果这些变量和我们已经添加的自变量相关,则存在内生性]
蒙特卡罗模拟Monte_Carlo
验证内生性会造成回归系数的巨大误差
times = 300; % 蒙特卡洛的次数
R = zeros(times,1); % 储存扰动项u和x1的相关系数
K = zeros(times,1); % 储存遗漏了x2之后,只用y对x1回归得到的回归系数
for i = 1: times
n = 30; % 样本数据量为n
x1 = -10+rand(n,1)*20; % x1在-10和10上均匀分布,大小为30*1
u1 = normrnd(0,5,n,1) - rand(n,1); % 随机生成一组随机数
x2 = 0.3*x1 + u1; % x2与x1的相关性不确定, 因为我们设定了x2要加上u1这个随机数
% 这里的系数0.3没特殊的意义,可以改成其他的测试。
u = normrnd(0,1,n,1); % 扰动项u服从标准正态分布
y = 0.5 + 2 * x1 + 5 * x2 + u ; % 构造y
k = (n*sum(x1.*y)-sum(x1)*sum(y))/(n*sum(x1.*x1)-sum(x1)*sum(x1)); % y = k*x1+b 回归估计出来的k
K(i) = k;
u = 5 * x2 + u; % 回归中忽略了5*x2,所以扰动项要加上5*x2
r = corrcoef(x1,u); % 2*2的相关系数矩阵
R(i) = r(2,1);
end
plot(R,K,'*')
xlabel("x_1和u'的相关系数")
ylabel("k的估计值")【扰动项与所有解释变量不相关】
可以区分解释变量为核心解释变量与控制变量
核心解释变量:感兴趣的变量,因此希望得到对其系数的 一致估计(当样本容量无限增大时,收敛于待估计参数的真值 )。
控制变量:并无太大兴趣;之所以放入回归方程,为了 “控制住” 那些对被解释变量有影响的遗漏因素。
在实际应用中,只要保证核心解释变量与𝝁不相关即可
对回归系数的解释可用偏导数来定义
控制其他变量不变的情况下,每增加一个单位,对
造成的影响
补充:什么时候取对数
(1)与市场价值相关的,例如,价格、销售额、工资等都可以取对数;
(2)以年度量的变量,如受教育年限、工作经历等通常不取对数;
(3)比例变量,如失业率、参与率等,两者均可;
(4)变量取值必须是非负数,如果包含0,则可以对y取对数ln(1+y)
好处:
(1)减弱数据的异方差性
(2)如果变量本身不符合正态分布,取了对数后可能渐近服从正态分布
(3)模型形式的需要,让模型具有经济学意义
四类模型回归系数的解释
1.一元线性回归 y = a + bx + μ
x每增加1个单位,y平均变化b个单位
2.双对数模型 lny = a + blnx + μ
x每增加1%,y平均变化b%
3.半对数模型 y = a + blnx + μ
x每增加1%,y平均变化b/100个单位
4.半对数模型 lny = a + bx + μ
x每增加1个单位,y平均变化(100b)%
特殊的自变量:虚拟变量X
性别、地域等
为了避免完全多重共线性的影响,引入虚拟变量的个数一般是分类数减1。
eg:性别即可分为引入一个虚拟变量female,为女性时,female = 1,男性时,female = 0

Stata的使用
1.定量数据
summarize 变量1,变量2... 变量n
可以双击变量添加
2.定性数据
tabulate 变量名,gen(A)
返回对应的这个变量的频率分布表,并生成对应的虚拟变量(以A开头)
例如:常规、有机、特殊 -> A1, A2, A3
常规:A1 = 1, A2 = 0, A3 = 0
有机:A1 = 0, A2 = 1, A3 = 0
....
3.回归
regress y x1 x2 ... xk [普通最小二乘估计法]
变量可以选定之前生成的虚拟变量
Stata可以自动检测数据的完全多重共线性问题
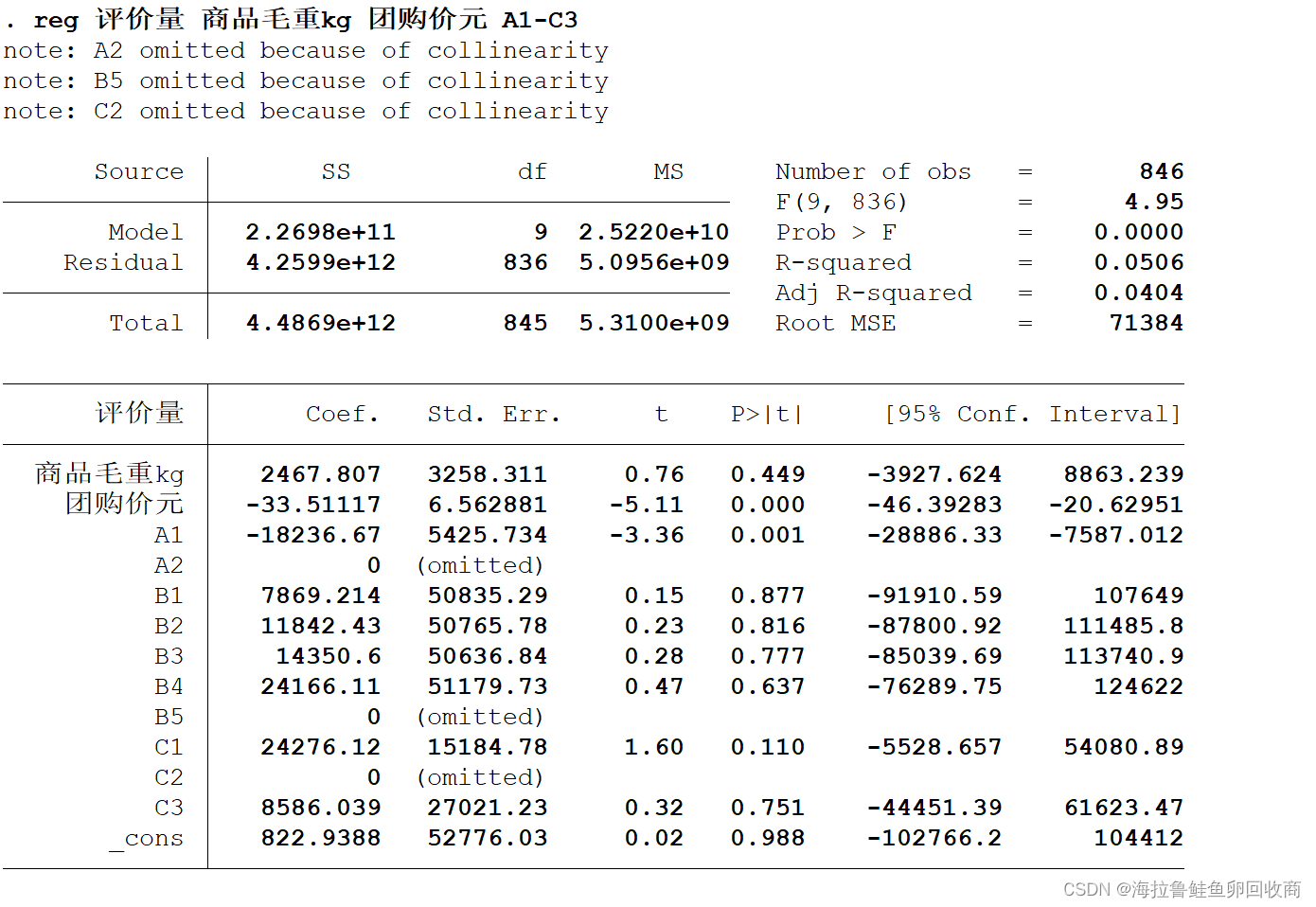
Source SS df[自由度]
Model -> SSR k[自变量个数]
Residual -> SSE n-k-1
Total -> SST n-1
*n为样本个数
调整后拟合优度 k为自变量个数
Number of obs 样本个数
F( , ) 检验值
Prob > F 检验值对应的p值 -> 联合显著性检验
p值 < 0.05 ,拒绝原假设H0 ,通过联合显著性检验,模型才有意义
Adj R-squared 调整后拟合优度[我们真正使用的]
为什么用调整后拟合优度而不是直接使用呢?
我们引入的自变量越多,拟合优度会变大。但我们倾向于使用调整后的拟合优度,如果新引入的自变量对SSE的减少程度特别少,那么调整后的拟合优度反而会减小。
y Coef.[回归系数] Std.Err.[标准误差] t[=Coef./Std.Err.] t检验统计量 P > |t| [p值]
x1 β1
x2 β2
...
β0
对p值作比较,显著性检验,
在....的置信水平下,....变量和...变量对应的回归系数是显著的,解释一下这些回归系数[控制其他自变量不变的情况下,..每增加..,...]
4.回归结果保存到word
// ssc install reg2docx, all replace
est store m1
reg2docx m1 using m1.docx, replace
5.标准化回归
regress y x1 x2 ... xk,beta
(1)为什么常数项没有标准化回归系数? 常数的均值是其本身,经过标准化后变成了0.
(2)为啥和之前的回归结果完全相同,除了多了最后那一列标准化回归系数? 对数据进行标准化处理不会影响回归系数的标准误,也不会影响显著性.
拟合优度R²太低
(1)回归分为解释型回归和预测型回归。
预测型回归一般才会更看重R²。
解释型回归更多的关注模型整体显著性以及自变量的统计显著性和经济意义显著性即可。[用的多]
(2)可以对模型进行调整,例如对数据取对数或者平方后再进行回归。
(3)数据中可能有存在异常值或者数据的分布极度不均匀。
标准化回归系数
为了更为精准的研究影响因变量的重要因素(去除量纲的影响),我们可考虑使用标准化回归系数。
对数据进行标准化,就是将原始数据减去它的均数后,再除以该变量的标准差,计算得到新的变量值,新变量构成的回归方程称为标准化回归方程,回归后相应可得到标准化回归系数。
标准化系数的绝对值越大,说明对因变量的影响就越大(只关注显著的回归系数)。















 3727
3727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









