






目录
存储引擎概念
MySQL中的数据用各种不同的技术存储在文件中,每一种技术都使用不同的存储机制、索引技巧、锁定水平并最终提供不同的功能和能力,这些不同的技术以及配套的功能在MySQL中称为存储引擎。
存储引擎是MySQL将数据存储在文件系统中的存储方式或者存储格式。
MySQL数据库中的组件,负责执行实际的数据I/O操作。
MySQL系统中,存储引擎处于文件系统之上,在数据保存到数据文件之前会传输到存储引擎,之后按照各个存储引擎的存储格式进行存储。
MySQL常用的存储引擎
- MyISAM:不支持事务和外键约束,占用资源较小,访问速度快,表级锁定,适用于不需要事务处理,单独写入或查询的应用场景。
- InnoDB:支持事务处理、外键约束、占用资源比MyISAM大,支持行级锁定,读写并发能力较好,适用于一致性要求高、数据更新频繁的应用场景。
一个表只能使用一个存储引擎,一个库中不同的表可以使用不同的存储引擎。
MyISAM存储引擎
MyISAM特点介绍
- MyISAM不支持事务,也不支持外键约束,只支持全文索引,数据文件和索引文件是分开保存的。
- 访问速度快,对事务完整性没有要求。
- MyISAM适合查询、插入为主的应用。
- MyISAM在磁盘上存储成三个文件,文件名和表名都相同,但是扩展名分别为:
- .frm文件存储表结构的定义
- 数据文件的扩展名为.MYD (MYData)
- 索引文件的扩展名是.MYI (MYIndex)
- 表级锁定形式,数据在更新时锁定整个表。
- 数据库在读写过程中相互阻塞。
- 会在数据写入的过程阻塞用户数据的读取
- 也会在数据读取的过程中阻塞用户的数据写入
- 数据单独写入或读取,速度过程较快且占用资源相对少
- MyISAM支持的存储格式
- 静态表
- 动态表
- 压缩表
MyISAM支持的存储格式
静态(固定长度)表
静态表是默认的存储格式。静态表中的字段都是非可变字段,这样每个记录都是固定长度的。
这种存储方式的优点是存储非常迅速,容易缓存,出现故障容易恢复。
缺点是占用的空间通常比动态表多。
动态表
动态表包含可变字段,记录不是固定长度的,这样存储的优点是占用空间较少,但是频繁的更新、删除记录会产生碎片,需要定期执行OPTIMIZE语句或myisamchk-r命令来改善性能,并且出现故障的时候恢复相对比较困难(因为会产生磁盘碎片,而且存储空间不是连续的)。
压缩表
压缩表由 myisamchk 工具创建,占据非常小的空间,因为每条记录都是被单独压缩的,所以只有非常小的访问开支(压缩的过程中会占用CPU性能)。
MyISAM适用的生产场景举例
- 公司业务不需要事务的支持
- 单方面读取或写入数据比较多的业务
- MyISAM存储引擎数据读写都比较频繁场景不适合
- 使用读写并发访问相对较低的业务
- 数据修改相对较少的业务
- 对数据业务一致性要求不是非常高的业务
- 服务器硬件资源相对比较差
InnoDB存储引擎
InnoDB特点介绍
- 支持事务,支持4个事务隔离级别
- MySQL从5.5.5版本开始,默认的存储引擎为InnoDB
- 读写阻塞与事务隔离级别相关
- 能非常高效的缓存索引和数据
- 表与主键以簇的方式存储
- 支持分区、表空间,类似oracle数据库
- 支持外键约束,5.5前不支持全文索引,5.5后支持全文索引对硬件资源要求还是比较高的场合
- 行级锁定,但是全表扫描仍然会是表级锁定,如
update table set a=1 where user like '%zhang%';- 使用like进行模糊查询时,会进行全表扫描,锁定整个表。
- 对没有创建索引的字段进行查询,也会进行全表扫描锁定整个表。
- 使用索引进行查询,则是行级锁定。
- InnoDB中不保存表的行数如
select count(*) from table;时, InnoDB需要扫描1遍整个表来计算有多少行,但是MyISAM只要简单的读出保存好的行数即可。需要注意的是,当count(*)语句包含where条件时 MyISAM也需要扫描整个表 - 对于自增长的字段,InnoDB中必须包含只有该字段的索引,但是在 MyISAM表中可以和其他字段一起建立组合索引
- 清空整个表时,InnoDB是一行一行的删除,效率非常慢。MyISAM则会重建表
InnoDB 使用表级锁定的场景
- 全表扫描的时候,比如 where 语句中使用 like 做模糊查询的时候
select count(*)统计全表的记录行数的时候- 使用没有索引的字段操作的时候(InnoDB行锁是通过给索引项实现的,如果没有索引那就会全表扫描)
InnoDB适用生产场景分析
- 业务需要事务的支持
- 行级锁定对高并发有很好的适应能力,但需确保查询是通过索引来完成
- 业务数据更新较为频繁的场景,如:论坛,微博等
- 业务数据一致性要求较高,如:银行业务
- 硬件设备内存较大,利用InnoDB较好的缓存能力来提高内存利用率,减少磁盘IO的压力
企业选择存储引擎依据
- 需要考虑每个存储引擎提供了哪些不同的核心功能及应用场景
- 支持的字段和数据类型
- 所有引擎都支持通用的数据类型
- 但不是所有的引擎都支持其它的字段类型,如二进制对象
- 锁定类型:不同的存储引擎支持不同级别的锁定
- 表锁定:MyISAM支持
- 行锁定:InnoDB支持
- 索引的支持
- 建立索引在搜索和恢复数据库中的数据时能显著提高性能
- 不同的存储引擎提供不同的制作索引的技术
- 有些存储引擎根本不支持索引
- 事务处理的支持
- 提高在向表中更新和插入信息期间的可靠性
- 可根据企业业务是否要支持事务选择存储引擎
查看和修改存储引擎
查看存储引擎
查看系统支持的存储引擎
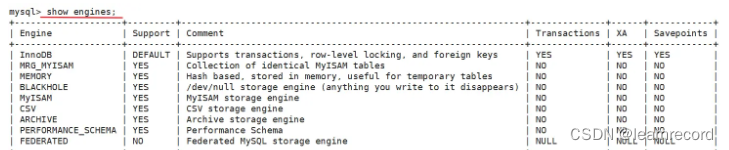
查看系统支持的存储引擎: show engines;
| 列名 | 作用 |
|---|---|
| Engine | 存储引擎的名称 |
| Support | YES表示引擎受支持且处于活动状态,NO表示不支持,DEFAULT表示默认存储引擎。DISABLED表示支持引擎但已将其禁用 |
| Comment | 存储引擎的简要说明 |
| Transactions | 存储引擎是否支持事务 |
| XA | 存储引擎是否支持XA事务 |
| Savepoints | 存储引擎是否支持回滚点(标记点) |
查看数据表使用的存储引擎
-
方法一:
show create table 表名;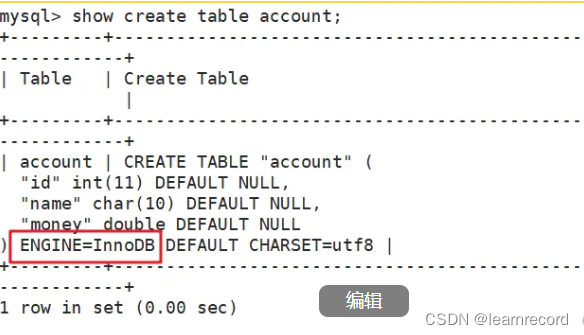
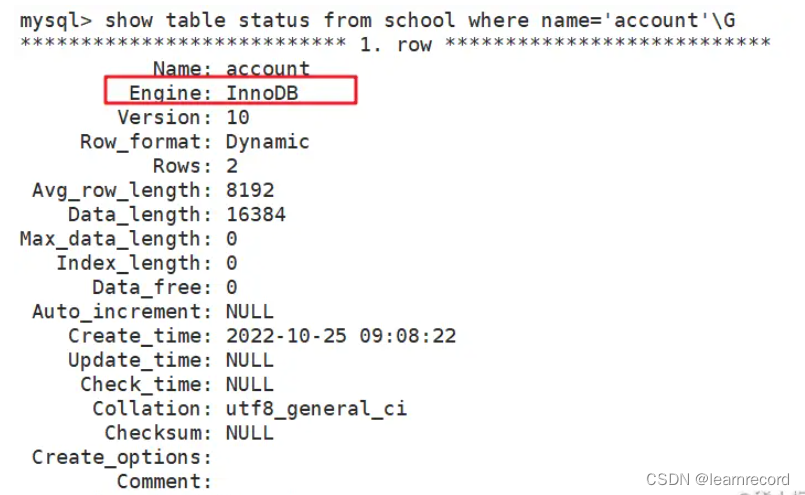
-
方法二:
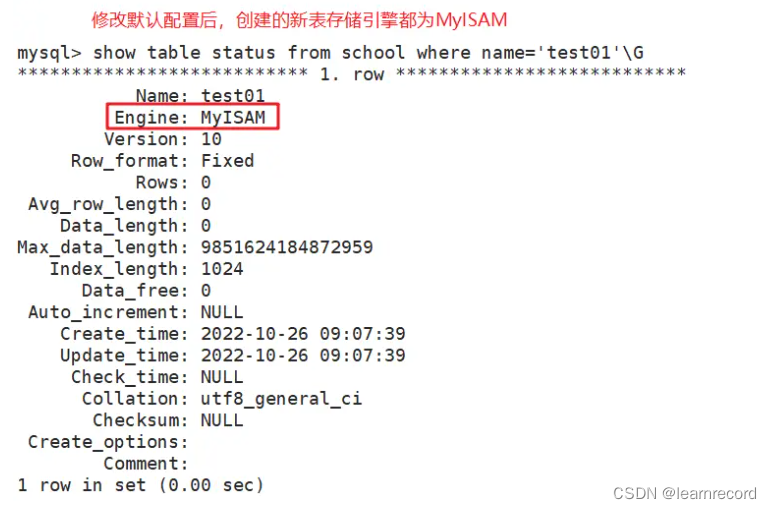
show table status from 库名 where name='表名'\G
如果不用where指定表名,那么就会查看库中的所有表。 -
修改存储引擎
- 方法一:alter table修改
use 库名;alter table 表名 engine=存储引擎名称;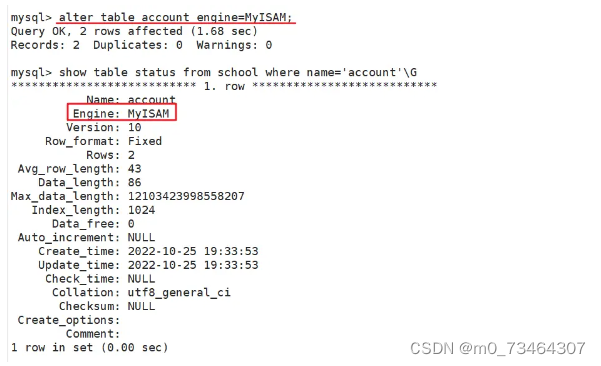
注意:MyISAM不支持外键约束,如果数据表设置了外键,则无法修改为MyISAM
- 方法二:修改配置文件,在 [mysqld] 配置项下面 default-storage-engine=XXX 设置默认的存储引擎
此方法只对修改配置文件并重启mysql服务之后新创建的表有效,已经存在的表不会有变更。
创建数据表时如果没有指定存储引擎,则会使用默认存储引擎。
vim /etc/my.cnf
......
[mysqld]
default-storage-engine=InnoDB #修改这一行,指定默认存储引擎为InnoDB
systemctl restart mysqld #重启服务
复制代码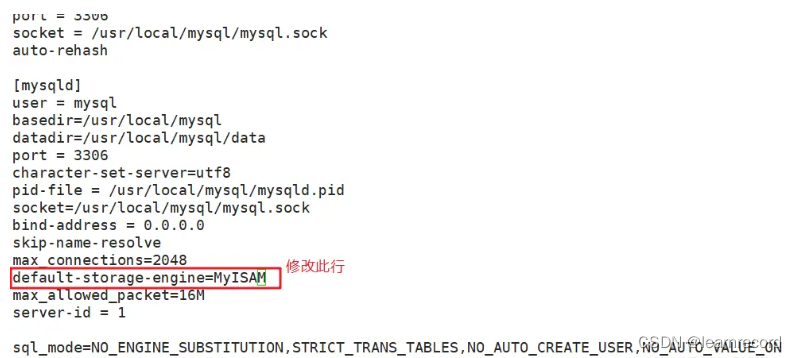
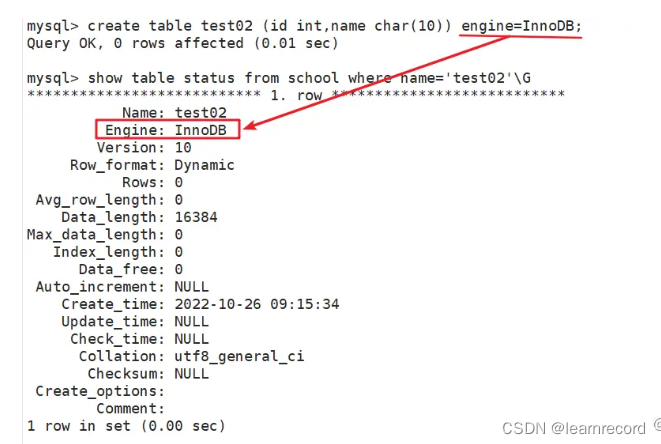
- 方法三:create table 创建表时指定存储引擎
use 库名;create table 表名(字段1 数据类型,...) engine=存储引擎名称;
InnoDB行锁与索引的关系
创建一个表用于试验
create table t1(id int primary key,name char(10),age int);
insert into t1 values(1,'aaa',22);
insert into t1 values(2,'bbb',23);
insert into t1 values(3,'aaa',24);
insert into t1 values(4,'bbb',25);
insert into t1 values(5,'ccc',26);
insert into t1 values(6,'zzz',27);
alter table t1 add index name_index(name); #对name字段创建普通索引
复制代码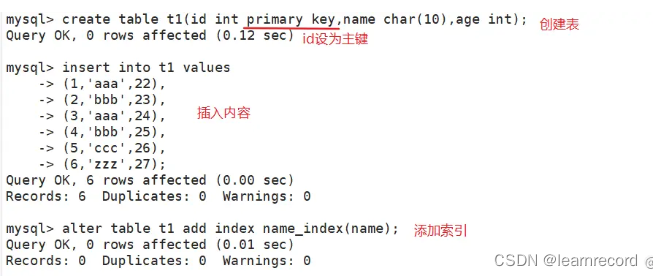
行级锁定与表级锁定
InnoDB行锁是通过给索引项加锁来实现的,如果没有索引,InnoDB将通过隐藏的聚簇索引来对记录加锁。
-
delete from t1 where id=1;
因为id字段是主键,Innodb对于主键使用了聚簇索引,删除过程中会直接锁住整行记录。行级锁定。 -
delete from t1 where name='aaa';
因为name字段是普通索引,会先锁住索引的两行(因为aaa有两行),接着会锁住相应主键对应的记录。行级锁定。 -
delete from t1 where age=23;
因为age字段没有索引,会使用全表扫描过滤,这时表上的各个记录都将加上锁。表级锁定。
死锁
行锁如果使用不当会导致死锁
死锁一般是事务相互等待对方释放资源,最后形成环路造成的
| 终端1 | 终端2 |
|---|---|
| begin; | begin; |
| delete from t1 where id=5;#事务结束前,id=5的行会被锁定 | |
| select * from t1 where id=1 for update; #加排他锁,模拟并发情况,锁定id=1的行 | |
| delete from t1 where id=1; #死锁产生 | |
| update t1 set name='abc' where id=5; #死锁产生。因为会话1中id=5的行还在删除过程中,该行已被锁定 | |
| rollback; #回滚,结束事务。id=5的行被解锁 | |
| update t1 set name='abc' where id=5; #成功更新数据 |
for update: 可以为数据库中的行上一个排它锁。当一个事务的操作未完成时,其他事务可以读取该行数据,但是不能写入、更新或删除。
死锁效果演示
-
终端一和终端二都开启事务

-
终端1锁定id=5的行,终端2锁定id=1的行

-
终端1对id=1的行操作,终端2对id=1的行操作,死锁产生

-
终端1回滚后,终端2成功修改记录
如何避免死锁
- 使用更合理的业务逻辑,以固定的顺序访问表和行数据
- 大事务拆小,大事务更容易出现死锁,如果业务允许,将大事务拆成多个小事务执行
- 在同一个事务中,尽可能做一次锁定所需的所有资源,减少死锁概率
- 降低隔离级别。如果业务允许,可以降低隔离级别,比如把RR调整成RC,这样可以避免很多造成死锁的因素
- 为表字段添加合理的索引。因为不使用会进行表级锁定,死锁的概率就会提高
总结
- MyISAM:不支持事务和外键约束,占用资源较小,访问速度快,表级锁定,支持全文索引,适用于不需要事务处理,单独写入或查询的应用场景。
- 存储格式:表名.frm(表结构文件)、表名.MYD(数据文件)、表名.MYI(索引文件)
- InnoDB:支持事务处理、外键约束,缓存能力较好,支持行级锁定,读写并发能力较好,5.5版本后支持全文索引,适用于一致性要求高、数据更新频繁的应用场景。
- 存储格式:表名.frm(表结构文件)、表名.idb(表数据文件/索引文件)、db.opt(表属性文件)















 1157
1157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









