






目录
上一篇部署了etcd分布式数据库、master01节点,
本篇文章部署Kubernetes集群中的 worker node 节点和 CNI 网络插件
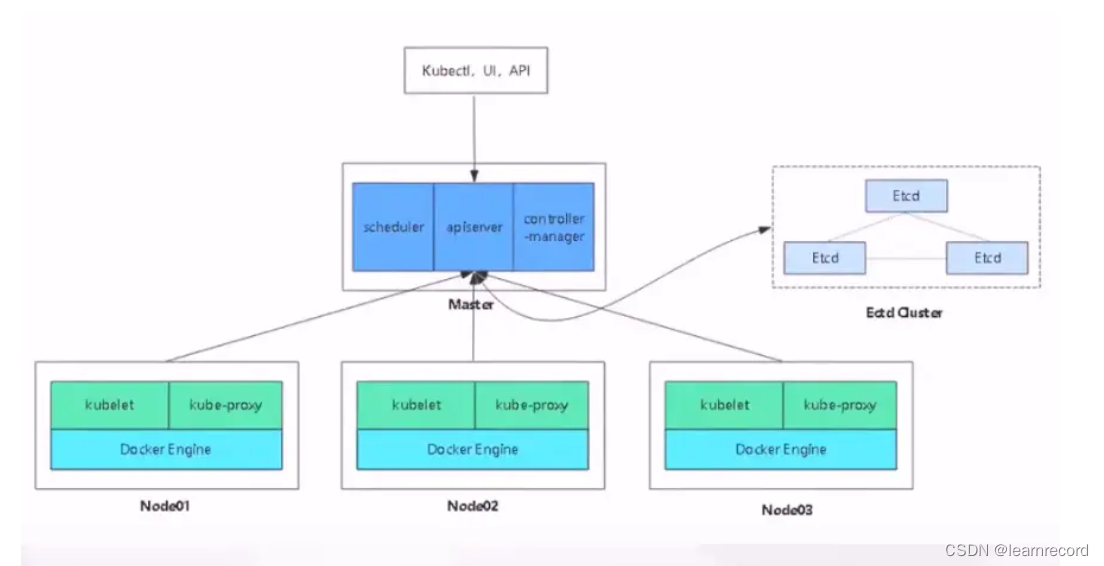
部署node节点
所有node节点部署 docker引擎
#所有 node 节点部署docker引擎
#安装依赖包
yum install -y yum-utils device-mapper-persistent-data lvm2
#设置阿里云镜像源
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
#安装 docker-ce
yum install -y docker-ce #docker-ce-cli、containerd.io会作为依赖包被安装
systemctl start docker.service #启动docker
systemctl enable docker.service #设置为开机自启
复制代码部署 Worker Node 组件
在所有 node 节点上操作
#创建kubernetes工作目录,并创建四个子目录cfg、bin、ssl、logs。cfg用于存放配置文件,bin用于存放执行文件,ssl用于存放证书文件,logs用于存放日志文件
mkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}
#上传 node.zip 到 /opt 目录中,解压 node.zip 压缩包,获得kubelet.sh、proxy.sh
cd /opt/
unzip node.zip
chmod +x kubelet.sh proxy.sh #为两个脚本文件增加执行权限
复制代码在 master01 节点上操作
#把 kubelet、kube-proxy 拷贝到两个node 节点
cd /opt/k8s/kubernetes/server/bin
scp kubelet kube-proxy root@192.168.44.30:/opt/kubernetes/bin/
scp kubelet kube-proxy root@192.168.44.40:/opt/kubernetes/bin/
#创建/opt/k8s/kubeconfig 目录,上传 kubeconfig.sh 文件到该目录中,生成 kubeconfig 的配置文件。
#kubeconfig文件包含集群参数(CA证书、API Server 地址),客户端参数(上面生成的证书和私钥),集群context上下文参数(集群名称、用户名)。Kubenetes组件(如kubelet、 kube-proxy) 通过启动时指定不同的kubeconfig 文件可以切换到不同的集群,连接到apiserver
mkdir /opt/k8s/kubeconfig
cd /opt/k8s/kubeconfig
chmod +x kubeconfig.sh
./kubeconfig.sh 192.168.44.20 /opt/k8s/k8s-cert/ #运行脚本,生成 kubeconfig 的配置文件。脚本后面跟的参数是 master01的IP、证书目录
#把配置文件bootstrap.kubeconfig、kube-proxy.kubeconfig拷贝到node节点
scp bootstrap.kubeconfig kube-proxy.kubeconfig root@192.168.44.30:/opt/kubernetes/cfg/
scp bootstrap.kubeconfig kube-proxy.kubeconfig root@192.168.44.40:/opt/kubernetes/cfg/
#RBAC授权,使用户 kubelet-bootstrap 能够有权限发起 CSR 请求
kubectl create clusterrolebinding kubelet-bootstrap --clusterrole=system:node-bootstrapper --user=kubelet-bootstrap
#CSR 请求就是kublet向APIserver请求证书的操作
#若执行失败,可先给kubectl绑定默认cluster-admin管理员集群角色,授权集群操作权限
kubectl create clusterrolebinding cluster-system-anonymous --clusterrole=cluster-admin --user=system:anonymous
复制代码注释
-
kubelet 采用 TLS Bootstrapping 机制,自动完成到 kube-apiserver 的注册,在 node 节点量较大或者后期自动扩容时非常有用。
-
Master apiserver 启用 TLS 认证后,node 节点 kubelet 组件想要加入集群,必须使用CA签发的有效证书才能与 apiserver 通信,当 node 节点很多时,签署证书是一件很繁琐的事情。因此 Kubernetes 引入了 TLS bootstraping 机制来自动颁发客户端证书,kubelet 会以一个低权限用户自动向 apiserver 申请证书,kubelet 的证书由 apiserver 动态签署。
-
kubelet 首次启动通过加载 bootstrap.kubeconfig 中的用户 Token 和 apiserver CA 证书发起首次 CSR 请求,这个 Token 被预先内置在 apiserver 节点的 token.csv 中,其身份为 kubelet-bootstrap 用户和 system:kubelet-bootstrap 用户组;想要首次 CSR 请求能成功(即不会被 apiserver 401 拒绝),则需要先创建一个 ClusterRoleBinding,将 kubelet-bootstrap 用户和 system:node-bootstrapper 内置 ClusterRole 绑定(通过 kubectl get clusterroles 可查询),使其能够发起 CSR 认证请求。
-
TLS bootstrapping 时的证书实际是由 kube-controller-manager 组件来签署的,也就是说证书有效期是 kube-controller-manager 组件控制的;kube-controller-manager 组件提供了一个 --experimental-cluster-signing-duration 参数来设置签署的证书有效时间;默认为 8760h0m0s,将其改为 87600h0m0s,即 10 年后再进行 TLS bootstrapping 签署证书即可。
-
也就是说 kubelet 首次访问 API Server 时,是使用 token 做认证,通过后,Controller Manager 会为 kubelet 生成一个证书,以后的访问都是用证书做认证了。
在所有node节点上操作,启动kubelet服务
#node01节点执行kubelet.sh脚本文件,启动 kubelet 服务,位置参数1为node01的ip地址。
cd /opt/
./kubelet.sh 192.168.44.30
ps aux | grep kubelet
#node02节点执行kubelet.sh脚本文件,启动 kubelet 服务,位置参数1为node02的ip地址。
cd /opt/
./kubelet.sh 192.168.44.40
ps aux | grep kubelet
复制代码在 master01 节点上操作,通过 CSR 请求
#检查到 node01节点和node02节点的 kubelet 发起的 CSR 请求,Pending 表示等待集群给该节点签发证书
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
node-csr-BUxnASfsYjtsTElTC7Dx3PET__fh376QuJYMZrurzSw 4m39s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending
node-csr-vF25KypSyYi4yn2HaHGw-hqvsaJkLR2QkyicsFjJfII 13m kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending
#通过node01节点kubelet的 CSR 请求
kubectl certificate approve node-csr-BUxnASfsYjtsTElTC7Dx3PET__fh376QuJYMZrurzSw
#通过node02节点kubelet的 CSR 请求
kubectl certificate approve node-csr-vF25KypSyYi4yn2HaHGw-hqvsaJkLR2QkyicsFjJfII
#Approved,Issued 表示已授权 CSR 请求并签发证书
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
node-csr-BUxnASfsYjtsTElTC7Dx3PET__fh376QuJYMZrurzSw 23m kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Approved,Issued
node-csr-vF25KypSyYi4yn2HaHGw-hqvsaJkLR2QkyicsFjJfII 31m kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Approved,Issued
#查看node节点,由于网络插件还没有部署,节点会没有准备就绪,所以显示NotReady
kubectl get node
NAME STATUS ROLES AGE VERSION
192.168.44.30 NotReady <none> 11m v1.20.11
192.168.44.40 NotReady <none> 12m v1.20.11
复制代码在所有 node 节点上操作,启动kube-proxy服务
##node01节点操作,加载 ip_vs 模块,启动kube-proxy服务
#加载 ip_vs 模块
for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;done
#运行脚本,启动kube-proxy服务
cd /opt/
./proxy.sh 192.168.44.30
ps aux | grep kube-proxy
##node02节点操作,加载 ip_vs 模块,启动kube-proxy服务
#加载 ip_vs 模块
for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;done
#运行脚本,启动kube-proxy服务
cd /opt/
./proxy.sh 192.168.44.40
ps aux | grep kube-proxy
复制代码附录1:kubeconfig.sh
#!/bin/bash
#example: kubeconfig.sh 192.168.44.20 /opt/k8s/k8s-cert/
#脚本后面跟的第一个位置参数是:master01的IP,第二个位置参数是:证书目录。
#创建bootstrap.kubeconfig文件
#该文件中内置了 token.csv 中用户的 Token,以及 apiserver CA 证书;kubelet 首次启动会加载此文件,使用 apiserver CA 证书建立与 apiserver 的 TLS 通讯,使用其中的用户 Token 作为身份标识向 apiserver 发起 CSR 请求
BOOTSTRAP_TOKEN=$(awk -F ',' '{print $1}' /opt/kubernetes/cfg/token.csv)
APISERVER=$1
SSL_DIR=$2
export KUBE_APISERVER="https://$APISERVER:6443"
# 设置集群参数
kubectl config set-cluster kubernetes \
--certificate-authority=$SSL_DIR/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=bootstrap.kubeconfig
#--embed-certs=true:表示将ca.pem证书写入到生成的bootstrap.kubeconfig文件中
# 设置客户端认证参数,kubelet 使用 bootstrap token 认证
kubectl config set-credentials kubelet-bootstrap \
--token=${BOOTSTRAP_TOKEN} \
--kubeconfig=bootstrap.kubeconfig
# 设置上下文参数
kubectl config set-context default \
--cluster=kubernetes \
--user=kubelet-bootstrap \
--kubeconfig=bootstrap.kubeconfig
# 使用上下文参数生成 bootstrap.kubeconfig 文件
kubectl config use-context default --kubeconfig=bootstrap.kubeconfig
#----------------------
#创建kube-proxy.kubeconfig文件
# 设置集群参数
kubectl config set-cluster kubernetes \
--certificate-authority=$SSL_DIR/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=kube-proxy.kubeconfig
# 设置客户端认证参数,kube-proxy 使用 TLS 证书认证
kubectl config set-credentials kube-proxy \
--client-certificate=$SSL_DIR/kube-proxy.pem \
--client-key=$SSL_DIR/kube-proxy-key.pem \
--embed-certs=true \
--kubeconfig=kube-proxy.kubeconfig
# 设置上下文参数
kubectl config set-context default \
--cluster=kubernetes \
--user=kube-proxy \
--kubeconfig=kube-proxy.kubeconfig
# 使用上下文参数生成 kube-proxy.kubeconfig 文件
kubectl config use-context default --kubeconfig=kube-proxy.kubeconfig
复制代码附录2:kubelet.sh
#!/bin/bash
NODE_ADDRESS=$1
DNS_SERVER_IP=${2:-"10.0.0.2"}
#创建 kubelet 启动参数配置文件
cat >/opt/kubernetes/cfg/kubelet <<EOF
KUBELET_OPTS="--logtostderr=false \
--v=2 \
--log-dir=/opt/kubernetes/logs \
--hostname-override=${NODE_ADDRESS} \
--network-plugin=cni \
--kubeconfig=/opt/kubernetes/cfg/kubelet.kubeconfig \
--bootstrap-kubeconfig=/opt/kubernetes/cfg/bootstrap.kubeconfig \
--config=/opt/kubernetes/cfg/kubelet.config \
--cert-dir=/opt/kubernetes/ssl \
--pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google-containers/pause-amd64:3.0"
EOF
#--hostname-override:指定kubelet节点在集群中显示的主机名或IP地址,默认使用主机hostname;kube-proxy和kubelet的此项参数设置必须完全一致
#--network-plugin:启用CNI
#--kubeconfig:指定kubelet.kubeconfig文件位置,当前为空路径,会自动生成,用于如何连接到apiserver,里面含有kubelet证书,master授权完成后会在node节点上生成 kubelet.kubeconfig 文件
#--bootstrap-kubeconfig:指定连接 apiserver 的 bootstrap.kubeconfig 文件
#--config:指定kubelet配置文件的路径,启动kubelet时将从此文件加载其配置
#--cert-dir:指定master颁发的kubelet证书生成目录
#--pod-infra-container-image:指定Pod基础容器(Pause容器)的镜像。Pod启动的时候都会启动一个这样的容器,每个pod之间相互通信需要Pause的支持,启动Pause需要Pause基础镜像
#----------------------
#创建kubelet配置文件(该文件实际上就是一个yml文件,语法非常严格,不能出现tab键,冒号后面必须要有空格,每行结尾也不能有空格)
cat >/opt/kubernetes/cfg/kubelet.config <<EOF
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
address: ${NODE_ADDRESS}
port: 10250
readOnlyPort: 10255
cgroupDriver: cgroupfs
clusterDNS:
- ${DNS_SERVER_IP}
clusterDomain: cluster.local
failSwapOn: false
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 2m0s
enabled: true
x509:
clientCAFile: /opt/kubernetes/ssl/ca.pem
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 5m0s
cacheUnauthorizedTTL: 30s
evictionHard:
imagefs.available: 15%
memory.available: 100Mi
nodefs.available: 10%
nodefs.inodesFree: 5%
maxOpenFiles: 1000000
maxPods: 110
EOF
#PS:当命令行参数与此配置文件(kubelet.config)有相同的值时,就会覆盖配置文件中的该值。
#----------------------
#创建 kubelet.service 服务管理文件
cat >/usr/lib/systemd/system/kubelet.service <<EOF
[Unit]
Description=Kubernetes Kubelet
After=docker.service
Requires=docker.service
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kubelet
ExecStart=/opt/kubernetes/bin/kubelet $KUBELET_OPTS
Restart=on-failure
KillMode=process
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable kubelet
systemctl restart kubelet
复制代码附录3:proxy.sh
#!/bin/bash
#example:proxy.sh 192.168.44.30
#脚本后跟的位置参数1是node节点的IP地址。
NODE_ADDRESS=$1
#创建 kube-proxy 启动参数配置文件
cat >/opt/kubernetes/cfg/kube-proxy <<EOF
KUBE_PROXY_OPTS="--logtostderr=true \
--v=4 \
--hostname-override=${NODE_ADDRESS} \
--cluster-cidr=172.17.0.0/16 \
--proxy-mode=ipvs \
--kubeconfig=/opt/kubernetes/cfg/kube-proxy.kubeconfig"
EOF
#--hostnameOverride: 参数值必须与 kubelet 的值一致,否则 kube-proxy 启动后会找>不到该 Node,从而不会创建任何 ipvs 规则
#--cluster-cidr:指定 Pod 网络使用的聚合网段,Pod 使用的网段和 apiserver 中指定的 service 的 cluster ip 网段不是同一个网段。 kube-proxy 根据 --cluster-cidr 判断集群内部和外部流量,指定 --cluster-cidr 选项后 kube-proxy 才会对访问 Service IP 的请求做 SNAT,即来自非 Pod 网络的流量被当成外部流量,访问 Service 时需要做 SNAT。
#--proxy-mode:指定流量调度模式为ipvs模式,可添加--ipvs-scheduler选项指定ipvs调度算法(rr|wrr|lc|wlc|lblc|lblcr|dh|sh|sed|nq)
#--kubeconfig: 指定连接 apiserver 的 kubeconfig 文件
#----------------------
#创建 kube-proxy.service 服务管理文件
cat >/usr/lib/systemd/system/kube-proxy.service <<EOF
[Unit]
Description=Kubernetes Proxy
After=network.target
[Service]
EnvironmentFile=-/opt/kubernetes/cfg/kube-proxy
ExecStart=/opt/kubernetes/bin/kube-proxy $KUBE_PROXY_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable kube-proxy
systemctl restart kube-proxy
复制代码部署网络组件
网络插件主要两种:Flannel、Calico。安装其中任意一个即可。
方法一:部署Flannel
在 node01 节点上操作
#上传 cni-plugins-linux-amd64-v0.8.6.tgz 和 flannel.tar 到 /opt 目录中
cd /opt/
docker load -i flannel.tar
docker images
#解压
mkdir /opt/cni/bin
tar zxvf cni-plugins-linux-amd64-v0.8.6.tgz -C /opt/cni/bin
#传给node02节点
scp cni/ flannel.tar root@192.168.44.40:/root/
docker load -i flannel.tar
复制代码在 master01 节点上操作\
#上传 kube-flannel.yml 文件到 /opt/k8s 目录中,部署 CNI 网络
cd /opt/k8s
kubectl apply -f kube-flannel.yml
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
kube-flannel-ds-hjtc7 1/1 Running 0 7s
kubectl get nodes
NAME STATUS ROLES AGE VERSION
192.168.44.30 Ready <none> 81m v1.20.11
复制代码方法二:部署 Calico
在 master01 节点上操作
#calico.yaml 文件可以直接从网上获取,使用wget下载即可
#上传 calico.yaml 文件到 /opt/k8s 目录中,部署 CNI 网络
cd /opt/k8s
vim calico.yaml
#修改里面定义Pod网络(CALICO_IPV4POOL_CIDR),要与前面kube-controller-manager配置文件指定的cluster-cidr网段一致
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16" #默认是192.168.0.0/16,需要改成和kube-controller-manager配置文件指定的cluster-cidr网段一致
#通过calico.yaml资源清单,使用kubectl apply创建pod,-f指定清单文件
kubectl apply -f calico.yaml
#等待1~2分钟,查看pod状态,-n指定命名空间,默认是default命名空间。都是Running状态就OK了。
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-659bd7879c-gq5fb 1/1 Running 0 2m53s
calico-node-dd4gc 1/1 Running 0 2m53s
calico-node-rg299 1/1 Running 0 2m53s
#再次查看集群的节点信息,都是Ready状态。
#等 Calico Pod 都 Running,节点也会准备就绪
kubectl get nodes
NAME STATUS ROLES AGE VERSION
192.168.44.30 Ready <none> 73m v1.20.11
192.168.44.42 Ready <none> 74m v1.20.11
#至此,单master节点k8s集群就部署成功了
复制代码部署 CoreDNS
CoreDNS:可以为集群中的 service 资源创建一个域名与 IP 的对应关系解析。
service发现是k8s中的一个重要机制,其基本功能为:在集群内通过服务名对服务进行访问,即需要完成从服务名到ClusterIP的解析。
k8s主要有两种service发现机制:环境变量和DNS。没有DNS服务的时候,k8s会采用环境变量的形式,但一旦有多个service,环境变量会变复杂,为解决该问题,我们使用DNS服务。
在所有 node 节点上操作
#上传 coredns.tar 到 /opt 目录中,之后导入镜像
cd /opt
docker load -i coredns.tar
复制代码在 master01 节点上操作
#上传 coredns.yaml 文件到 /opt/k8s 目录中,部署 CoreDNS
cd /opt/k8s
#通过coredns.yaml资源清单,使用kubectl apply创建该pod,-f指定清单文件
kubectl apply -f coredns.yaml
#等待1~2分钟,查看pod状态,-n指定命名空间,默认是default命名空间。coredns是Running状态就OK了。
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-6954c77b9b-r4lc6 1/1 Running 0 5m21s
#DNS 解析测试
kubectl run -it --rm dns-test --image=busybox:1.28.4 sh
If you don't see a command prompt, try pressing enter.
/ # nslookup kubernetes
Server: 10.0.0.2
Address 1: 10.0.0.2 kube-dns.kube-system.svc.cluster.local
Name: kubernetes
Address 1: 10.0.0.1 kubernetes.default.svc.cluster.local
/ #
复制代码CNI网络插件介绍
Kubernetes的三种网络

K8S 中 Pod 网络通信
Pod 内容器与容器之间的通信
在同一个 Pod 内的容器(Pod 内的容器是不会跨宿主机的)共享同一个网络命令空间,相当于它们在同一台机器上一样,可以用 localhost 地址访问彼此的端口。
同一个 Node 内 Pod 之间的通信
每个 Pod 都有一个真实的全局 IP 地址,同一个 Node 内的不同 Pod 之间可以直接采用对方 Pod 的 IP 地址进行通信,Pod1 与 Pod2 都是通过 Veth 连接到同一个 docker0 网桥,网段相同,所以它们之间可以直接通信。
不同 Node 上 Pod 之间的通信
Pod 地址与 docker0 在同一网段,docker0 网段与宿主机网卡是两个不同的网段,且不同 Node 之间的通信只能通过宿主机的物理网卡进行。
要想实现不同 Node 上 Pod 之间的通信,就必须想办法通过主机的物理网卡 IP 地址进行寻址和通信。因此要满足两个条件:Pod 的 IP 不能冲突;将 Pod 的 IP 和所在的 Node 的 IP 关联起来,通过这个关联让不同 Node 上 Pod 之间直接通过内网 IP 地址通信。
Overlay Network
叠加网络,在二层或者三层基础网络上叠加的一种虚拟网络技术模式,该网络中的主机通过虚拟链路隧道连接起来(类似于VPN)。
VXLAN
将源数据包封装到UDP中,并使用基础网络的IP/MAC作为外层报文头进行封装,然后在以太网上传输,到达目的地后由隧道端点解封装并将数据发送给目标地址。
Flannel 插件
Flannel 的功能是让集群中的不同节点主机创建的 Docker 容器都具有全集群唯一的虚拟 IP 地址。
Flannel 是 Overlay 网络的一种,也是将 TCP 源数据包封装在另一种网络包里面进行路由转发和通信,目前支持 udp、vxlan、 host-GW 3种数据转发方式。
- UDP(默认方式,基于应用转发,配置简单,性能最差)
- VXLAN(基于内核转发)
- Host-gw(性能最好、配置麻烦)
Flannel UDP 模式(端口8285)
udp模式的工作原理:(基于应用进行转发,Flannel提供路由表,Flannel封装、解封装)
数据从 node01 上 Pod 的源容器中发出后,经由所在主机的 docker0 虚拟网卡转发到 flannel0 虚拟网卡,flanneld 服务监听在 flannel0 虚拟网卡的另外一端。
Flannel 通过 Etcd 服务维护了一张节点间的路由表。源主机 node01 的 flanneld 服务将原本的数据内容封装到 UDP 中后根据自己的路由表通过物理网卡投递给目的节点 node02 的 flanneld 服务,数据到达以后被解包,然后直接进入目的节点的 flannel0 虚拟网卡,之后被转发到目的主机的 docker0 虚拟网卡,最后就像本机容器通信一样由 docker0 转发到目标容器。

ETCD 之 Flannel 提供说明:
- 存储管理Flannel可分配的IP地址段资源
- 监控 ETCD 中每个 Pod 的实际地址,并在内存中建立维护 Pod 节点路由表
vxlan 模式(官方预留端口号默认4789)(实际使用端口8472)
vxlan 是一种overlay(虚拟隧道通信)技术,通过三层网络搭建虚拟的二层网络,跟 udp 模式具体实现不太一样:
- udp模式是在用户态实现的,数据会先经过tun网卡,到应用程序,应用程序再做隧道封装,再进一次内核协议栈,而vxlan是在内核当中实现的,只经过一次协议栈,在协议栈内就把vxlan包组装好。
- udp模式的tun网卡是三层转发,使用tun是在物理网络之上构建三层网络,属于ip in udp,vxlan模式是二层实现, overlay是二层帧,属于mac in udp。
- vxlan由于采用mac in udp的方式,所以实现起来会涉及mac地址学习,arp广播等二层知识,udp模式主要关注路由
Flannel VXLAN模式跨主机的工作原理:(Flannel提供路由表,由内核封装、解封装)
- 数据帧从主机A上Pod的源容器中发出后,经由所在主机的docker0/cni0 网络接口转发到flannel.1 接口
- flannel.1 收到数据帧后添加VXLAN 头部,由内核进行封装在UDP报文中
- 主机A通过物理网卡发送封包到主机B的物理网卡中
- 主机B的物理网卡再通过VXLAN 默认端口8472转发到flannel.1 接口进行解封装
- 解封装以后,内核将数据帧发送到Cni0, 最后由Cni0 发送到桥接到此接口的容器B中。

UDP和VXLAN的区别
由于UDP模式是在用户态做转发(即基于应用进行转发,由应用程序进行封装和解封装),会多一次报文隧道封装,因此性能上会比在内核态做转发的VXLAN模式差。
UDP和VXLAN的区别:
- UDP基于应用程序进行转发,由应用程序进行封装和解封装;VXLAN由内核进行封装和解封装,内核效率比应用程序要高,所以VXLAN比UDP要快。
- UDP是数据包,VXLAN是数据帧。
- UDP的网卡Flannel0,VXLAN的网卡Flannel.1。
Calico 插件
k8s组网方案对比
flannel 方案
需要在每个节点_上把发向容器的数据包进行封装后,再用隧道将封装后的数据包发送到运行着目标Pod的node节点上。目标node节点再负责去掉封装,将去除封装的数据包发送到目标Pod上。数据通信性能则大受影响。
calico方案
Calico不使用隧道或NAT来实现转发,而是把Host当作Internet中的路由器,使用BGP同步路由,并使用iptables来做安全访问策略,完成跨Host转发来。
采用直接路由的方式,这种方式性能损耗最低,不需要修改报文数据,但是如果网络比较复杂场景下,路由表会很复杂,对运维同事提出了较高的要求。
Calico的组成和工作原理
基于三层路由表进行转发,不需要封装和解封装。
Calico主要由三个部分组成
- Calico CNI插件:主要负责与kubernetes对接,供kubelet 调用使用。
- Felix:负责维护宿主机上的路由规则、FIB转发信息库等。
- BIRD:负责分发路由规则,类似路由器。
- Confd:配置管理组件。
Calico工作原理
- Calico是通过路由表来维护每个pod的通信。
- Calico 的CNI插件会为每个容器设置一个 veth pair设备,然后把另一端接入到宿主机网络空间,由于没有网桥,CNI插件还需要在宿主机上为每个容器的veth pair设备配置一条路由规则,用于接收传入的IP包。
- 有了这样的veth pair设备以后,容器发出的IP包就会通过veth pair设备到达宿主机,然后宿主机根据路由规则的下一跳地址,发送给正确的网关,然后到达目标宿主机,再到达目标容器
- 这些路由规则都是Felix 维护配置的,而路由信息则是Calico BIRD 组件基于BGP(动态路由协议,可以选路)分发而来。
- calico实际上是将集群里所有的节点都当做边界路由器来处理,他们一起组成了一个全互联的网络,彼此之间通过BGP交换路由,这些节点我们叫做BGP Peer。

flannel和calico对比
flannel
- 配置方便,功能简单,是基于overlay叠加网络实现的(在原有数据包中再封装一层),由于要进行封装和解封装的过程对性能会有一定的影响,同时不具备网络策略配置能力。
- 三种模式:UDP、 VXLAN、HOST-GW
- 默认网段是:10.244.0.0/16
calico
- 功能强大,基于路由表进行转发,没有封装和解封装的过程,对性能影响较小,具有网络策略配置能力,但是路由表维护起来较为复杂。
- 模式:BGP、IPIP
- 默认网段192 .168.0.0/16
目前比较常用的CNI网络组件是flannel和calico,flannel的功能比较简单,不具备复杂的网络策略配置能力,calico是比较出色的网络管理插件,但具备复杂网络配置能力的同时,往往意味着本身的配置比较复杂,所以相对而言,比较小而简单的集群使用flannel,考虑到日后扩容,未来网络可能需要加入更多设备,配置更多网络策略,则使用calico更好。
(flannel在封装和解封装的过程中,会有性能损耗。calico没有封装解封装过程,没有性能损耗)
总结
flannel是k8s的pod能够实现跨节点通信的cni网络插件
模式:
- UDP:最早,性能较差
- VXLAN:默认,推荐,性能比UDP更好
- Host-gw:性能最好,但配置繁琐
flannel的UDP模式工作原理(端口号默认8285)
- 应用数据从源主机的Pod发出到cnio网桥接口,再由cnio转发到flannel0虚拟网卡接口
- flanneld服务会监听flannelo接口的数据,flanneld服务会将内部数据包封装到UDP报文里
- 根据flannel在etcd维护的路由表通过物理网卡转发到目标主机
- UDP报文送达到目标主机的flanneld服务后会被解封装,然后会通过目标主机的fl.annelo接口转发到目标主机的eni0o网桥,最后再被cni0转发到目标Pod
flannel的VXLAN模式工作原理(官方预留端口号默认4789)(实际使用端口8472)
- pod将数据帧(包含IP头部与报文)转发到cni0网桥,再转发到flannel.1虚拟网卡接口,
- flannel.1网卡会在数据帧上添加VXLAN头部作为标识,再将数据帧由内核进行封装到UDP报文中
- 根据flannel在etcd维护的路由表,封装目标主机的IP地址和MAC地址,通过物理网卡,转发到目标主机
- 目标主机会通过8472端口,将数据包发送到flannel.1虚拟网卡接口,flannel.1会将udp报文进行解封装,
- 并且解封装VXLAN头部信息,转发到网桥cni0,cni0网桥将数据帧转发到连接在网桥上的目标pod
K8S的三种网络
- 节点网络(通过物理网卡通信,如ens33)
- pod网络(通过pod ip进行通信)
- service网络(通过cluster ip进行通信)
flannel和calico 区别?
- flannel使用的三种模式:udp、vxlan、host-gw
- flannel 通常使用 vxlan 模式,采用的是叠加网络,IP隧道方式传输数据,可以实现跨子网进行传输。传输过程中需要进行封包和解包的过程,对性能有一定的影响。
- 功能简单配置方便,利于管理,但不具有复杂的网络策略规则配置的能力
- calico使用的三种模式:ipip、bgp、混合
- calico的ipip模式,同样可以实现跨子网传输,但传输过程中一样需要进行封装和解封装的操作,对性能有一定的影响
- calico的bgp模式可以直接根据bgp路由规则转发,并且传输过程中不需要封装和解封装,因此性能较好,但是只能在同一子网中使用,无法进行跨网使用;bgp模式具有更丰富的网络策略配置管理能力;但是维护起来较为复杂
所以对于较小规模且网络要求简单的k8s集群,我们可以采用flannel,对于集群规模较大且要求更多的网络策略时,可以采用功能更全面的calico















 495
495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









