






redis五种基本类型可以涵盖项目中大多数的使用场景,而它们的底层实现在面试的过程中也是提问的提问的比较多的,今天就花时间来深入理解一下这五种基本数据类型的底层实现吧!
五种数据类型分别是:string , list , set , zset 以及 hash,下面我们一一介绍:
数据类型的底层实现
-
string
存储字符串对象可能有三种编码方式,分别是int,raw以及embstr。
-
int:当存储的是一个整数值,并且这个整数值在long的范围内,那么就用整数值来保存,并将编码方式设置为int。
-
row:当存储的是一个字符串对象,并且大于39个字节,那么就使用sds这个数据结构进行存储,并将编码方式设置为row。
-
embstr:当存储的是一个字符串对象,并且小于39个字节,那么就使用embstr的编码方式存储字符串对象,跟row编码方式相比,embstr是一种用于保存短字符串的优化编码方式,它只需要调用一次内存分配函数申请一块连续的内存空间,里面包含字符串对象和sds数据结构;而row编码方式需要调用两次内存分配函数分别创建字符串对象和sds的结构。
-
需要补充的一点就是浮点数是转成字符串对象进行保存,计算的时候先转成浮点数,计算完毕后再转成字符串对象进行保存。
-
-
list
在redis3.2版本之前,当数据量较小的时候使用压缩列表存储,数据量大的时候使用双向链表存储;3.2版本之后,统一使用快速列表存储。
-
双向链表:前后指针以及链表长度。
-
压缩列表:由一块连续的内存空间存储数据,里面有存储的数据,数据长度,尾节点偏移量等属性,可以实现双向遍历。
-
快速列表:类似于双向链表,不过指针连接的不是节点,而是一个个压缩列表。
提问:为什么数据量小的时候用压缩列表,而大的时候使用双向链表呢?
答:压缩列表因为是连续的存储空间,同时没有前后指针,所以可以节省一定的内存空间,但是它没有多余的空间,存放满了就需要申请分配空间,同时也存在内存拷贝的情况,这样就会耗费一定的性能,所以数据量大的时候就使用双向链表存储数据。
-
-
set
当存储的元素都是整数时,并且元素个数小于512个,那么就使用整数集合存储。否则使用hashtable存储,key为元素,值为null。
-
zset
当元素数量小于128个,并且所有元素的大小不超过64字节时使用压缩列表(存储集合对象时使用两个紧挨着的节点,一个存放元素值,一个存放分数);其他情况使用跳表+hashtable(两者互补,在进行范围性操作的时候,需要对集合元素进行排序,跳表排序的时间复杂度为O(logn),hashtable查找元素的时间复杂度为O(1))。
-
hash
当元素个数小于512个,并且键值对的键和值的长度都小于64字节使用压缩列表(存储参考zset);其他情况使用hashtable存储。
那么上面的内容你可能对一些数据结构比较感到疑惑,那么我针对sds和跳表数据类型进行补充说明以便于更好的消化知识。
string类型的sds结构
sds里面有三个属性,分别是 int len (字符数组的长度)、 int free(字节数组中可用的长度)、char buf[] (存放字符的数组)。我们存放的字符串是在这个字符数组中,以 '\0'收尾,这个'\0' 是不计入长度的。
然后我们说一下sds这样设计的好处:
1. 使用len用来记录以存放的字符的长度,保证了计算字符串长度这个操作的时间复杂度降为O(1),如果不加的话需要遍历字节数组,时间复杂度为O(n)。 2. free记录了可用字符数组的长度,这里面就涉及到扩容了。
我简单说一下扩容。初始存放字符"abc",那么len =3, free = 0。当我们继续向字节数组中添加“def”的时候,这时候空间不够了,那么就需要动态分配内存空间,扩容后 len = 6,free= 6 (至于为什么等于6呢,这里设计的时候是以string类型存放数据 1mb进行划分,如果小于1mb,那么再次扩容后 len = free,这样就避免了频繁进行扩容;如果大于1mb,那么free = 1mb)。
还有一点,就是涉及到了惰性删除,当我们删除“abc”中的“bc”后,len变为 1,而free变为2,原来的内存空间并不会立马释放,这样也起到了避免频繁扩容的效果。
这样我们就大概了解了free的作用了,就是记录了可用字节的空间,从而避免了频繁的扩容。
跳表
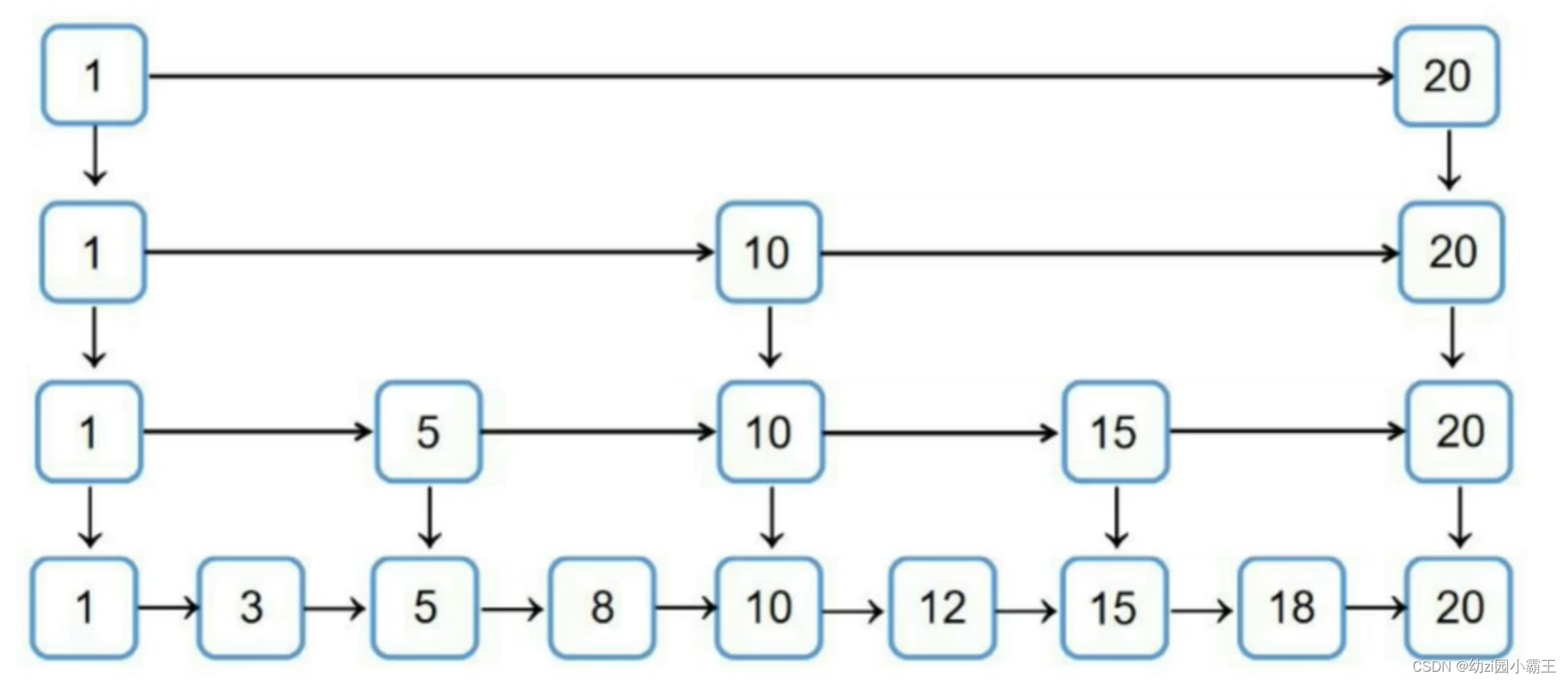
跳表是什么?
跳表是一种在链表的基础上增加了多级索引的数据类型。它可以通过多级索引进行转跳,实现快速查找元素的效果。
每个节点存放了右边第一个元素和下层元素的指针,遍历的时候从最高层开始遍历。
跳表查找元素的时间复杂度是多少?
O(logn)。同样增删元素时间复杂度为O(logn)。
为什么使用跳表,而不是使用二叉搜索树或者红黑树?
1. zset有一个重要特性就是范围查询,使用跳表可以利用多级索引快速查找起点,然后向后遍历就可以了;而二叉搜索树或者红黑树进行范围查询效率就没有这么高。 2. 跳表更容易实现,而二叉搜索树和红黑树需要额外维护节点。
跳表如果插入重复数据会怎么样?
会更新该元素的分数,并根据分数调整该元素的排序位置。















 3760
3760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









