









收藏和点赞,您的关注是我创作的动力
概要
基于深度学习算法,以PaddlePaddle深度学习框架作为实验环境,选取了开源的安全帽识别数据库和实地拍摄的安全帽佩戴照片,使用样本扩增增加了实验数据集的样本数,选取了Faster R-CNN、SSD与YOLO v3三种深度神经网络模型,构建出安全帽智能识别模型。
在实验数据集上对三种模型分别实验,对比实验结果。结果显示,基于YOLOv3的模型具有识别精度高,识别速率快等特点,识别准确率达到了99.97%。为了验证了本文提出方法的有效性,使用Python语言开发了安全帽佩戴识别的原型系统。
关键词:深度学习;安全帽识别;Python;YOLO v3
一、研究的内容与方法
本课题对基于深度学习的安全帽佩戴识别方法进行了研究,以PaddleHub深度学习框架作为实验环境,选取了开源的安全帽识别数据库和实地拍摄的安全帽佩戴照片,使用样本扩增增加了实验数据集的样本数,选取了Faster RCNN、SSD与YOLOv3三种深度神经网络模型,构建出安全帽智能识别模型。在实验数据集上对三种模型进行了对比实验。分别计算了准确率、速率与稳定性,对实验结果进行了对比分析。为了验证了本文提出方法的有效性,使用Python语言开发了安全帽佩戴识别的原型系统,用于模拟建筑工地上识别安全帽的过程。
二、基于深度学习的安全帽识别算法
2.1 深度学习
深度学习,是实现人工智能的必经之路——机械学习中的一种,是人工神经网络研究不断深入后的产物之一,它的结构特点是包含多个隐藏层感知器。深度学习中更为抽象的高层次表示特征是由多个低层次的特征组合而成,这使深度学习模型更容易发现数据特征的表示结构。由于深度学习模型的构造理念是通过模拟人脑来建立高效分析与学习的神经网络,因此深度学习具有通过模拟人脑的思考方式来解释图像、声音等数据的能力。深度学习是一种常用的模式分析方法的统称,根据研究的具体内容,主要使用三种方法:
一是卷积神经网络,也就是基于卷积运算的神经网络系统;二是基于多层神经元的自编码神经网络,主要包括自编码与稀疏编码两类;三是深度执行网络,主要通过多层自编码神经网络进行预训练,继而与鉴别信息结合对神经网络权值进行优化。
深度学习在通过多层处理后,能够将初始“低层”的特征表示逐渐向“高层”的特征表示转化,以达到用相对简单、基础的模型完成更为困难、复杂的学习任务。从这一角度,也可以把深度学习理解为特征学习或是表示学习
在以往的机械学习实现实际任务时,通常依赖专家对描述样本的特征进行设计,这使得专家对样本特征设计的好坏,直接影响了实际系统的性能。而特征学习则通过机械学习技术来弥补这一缺点,这使得深度学习拜托了对专家的依赖。
2.2 算法流程
本课题的算法流程图如图1所示
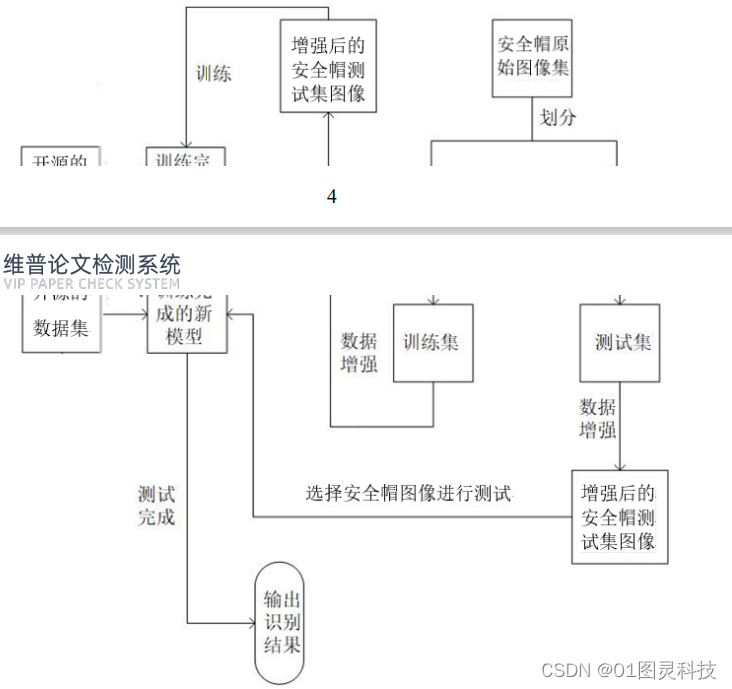
图1 算法流程图
首先,将开源的安全帽数据集与工地实地拍摄获取的安全帽原始图片按比例分为训练集与测试集,并对它们分别进行数据增强。然后再用数据增强后训练集对深度模型进行训练。训练完成后,用数据增强后的测试集安全帽图片对已训练的模型进行测试,最后输出识别结果。
2.3 目标检测算法
本文选用了Faster R-CNN、SSD与YOLO v3三种深度模型。Faster R-CNN模型在ILSVRV与COCO等竞赛中均获得多项第一,SSD是在Faster RCNN与YOLO v1 之后的高级的物体检测模型。与 Faster RCNN与YOLO v1相比,SSD在识别速度和性能上都得到了明显的提升。下面对三种模型分别进行介绍。
2.3.1 Faster R-CNN
Faster R-CNN在目标检测领域表现出极强的生命力,虽然Faster R-CNN是2015年建立的算法,但它现在仍然是许多的目标监测系统的基础,并且在解决拥挤或是小物体等问题上仍然具有较大的有优势,这在更新迅速的深度学习领域是十分少见的,不仅如此,Faster R-CNN的利用范围也十分广阔,例如:水果种类检测,宠物种类检测以及本文的安全帽检测等等。
2.3.2 SSD
SSD的全称为Single Shot MultiBox Detector是WeiLiu在ECCV上提出的深度模型,是一种目标检测模型。虽然SSD是在2016年提出的模型,但现在仍然是主要的目标检测算法之一,兼顾了Faster R-CNN与YOLOv1的优缺点,在速度上优于Faster R-CNN,在精度上优于YOLOv1;并且在处理小目标时对比YOLO有着结构上的优势。
2.3.3 YOLO v3
YOLO v3是在YOLOv2与YOLOv1的基础上建立的一种目标检测算法采用了残差跳连接和上采样等新架构值,YOLO v3最为突出的特点是它能够检测三种不同的尺度。YOLO是一种全卷积网络,它是通过在特征映射上使用1x1的核来产生最终的输出,而YOLOv3在此基础上完成了优化和改进,它能够在网络的三个位于不同位置的大小不同的特征图使用1x1核来进行检测。
三 实验与结果分析
3.1 实验数据集
3.1.1 实验数据集的构建
实验的数据集包括两部分,一部分来源于一个开源的安全帽识别数据集(https://github.com/njvisionpower/Safety-Helmet-Wearing-Dataset),该数据集已经完成了图片样本的标注。另外一部分是本人在工地现场拍摄的照片,也进行了标注。
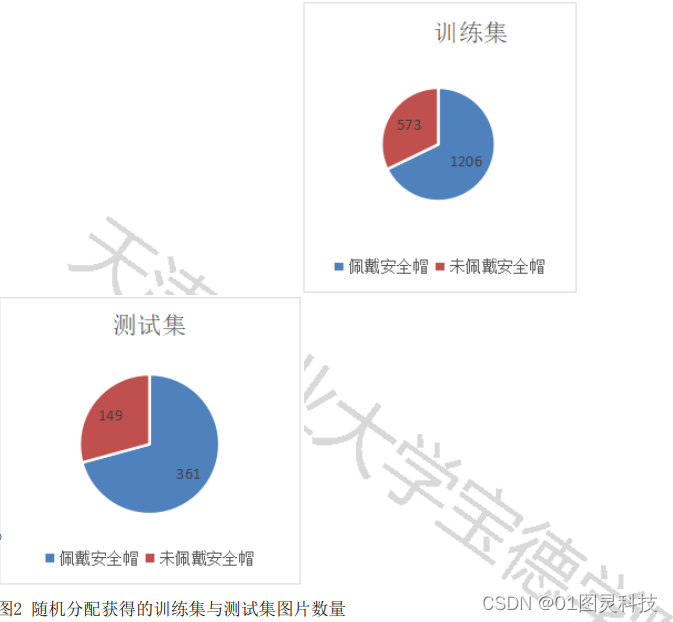
佩戴安全帽两个集合,构成有标签的数据样本。随后再将数据集随机划分成训练集与测试集两个部分。两个部分的比例为训练集:测试集=8:2。得到的训练集和测试集的样本数量分布如图2所示。
3.1.2 数据集的分类
首先将数据集中本人拍摄的安全帽图片样本进行了人工分类,与开源数据集样本一起,划分为佩戴安全帽与未佩戴安全帽两个集合,构成有标签的数据样本。随后再将数据集随机划分成训练集与测试集两个部分。两个部分的比例为训练集:测试集=8:2。得到的训练集和测试集的样本数量分布如图2所示。
3.1.3 增强数据集
为了得到更多的训练图片,实验使用Tensorflow开发库对数据进行了增强,目的是达到扩充原始数据集的效果。Tensorflow开发库是深度学习库,它是开源的,支持所有流行语言,如Python、C++、Java、R和Go,并且它受到所有云服务(AWS、Google和Azure)的支持。Tensorflow内部包含有大量的工具,可以对模型进行设计和调试,同时也提供了基本的数据增强工具。
本课题使用了Tensorflow库对数据集进行了旋转、变形等随机操作,得到增强后的数据集。增强后的数据集包括:佩戴安全帽图片样本总数达到3143张,未佩戴安全帽的图片样本总数达到2271张。在佩戴安全帽的图片样本中,将2514张作为训练集,将629张作为测试集;未佩戴安全帽的图片中将1816张作为训练集,将455张作为测试集。训练集和测试集的样本统计结果如表1所示。图3和图4分别为佩戴安全帽图片样本和未佩戴安全帽图片的样本示例。
表1 训练集和测试集的样本统计

四 原型系统实现
因为在实验过程中发现,YOLOv3是三个对比实验中最为突出的一个,在损失函数曲线图中的曲线收敛速度相比另外两种算法更快,而且网络波动的幅度也较小,收敛的值比较小,且准确率在三者中也是最高的一个,得到了YOLOv3在安全帽智能检测领域的适用性较高的结果。因此,本课题基于训练好的YOLOv3模型使用Python语言开发了安全帽佩戴识别的原型系统,用于模拟建筑工地上识别安全帽的过程。该系统实现为一个Web页面。
4.1 生成系统的Web页面
通过Python程序编写生成了该系统的Web页面。在Python程序运行结束时会给出生成的页面的本地地址和端口号,一般为http://localhost:8000。在浏览器上输入该地址和端口号就可以打开系统的Web页面,进行安全帽的识别操作。下面是该Python程序的源代码。
 图8是Python程序的运行结果。输出了系统页面的地址。
图8是Python程序的运行结果。输出了系统页面的地址。
图8 运行结果
打开地址http://localhost:8000就可以实际进行安全帽图像的智能识别操作。
4.2 上传检测图片
识别系统需要上传检测图片,相关代码如下。

用户只需要点击选择文件就可以打开浏览窗口对图片进行选择,如图10所示。
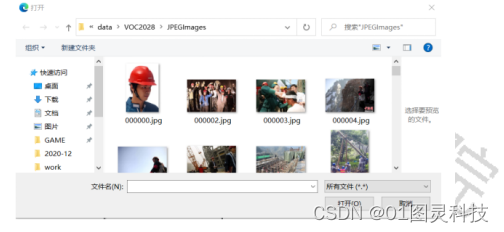
图10 选择图片
在选择了图片之后,运行界面就会改变,便于用户对选择的图片进行确认,以及进行下一步的操作,如图11所示。


图11图片确认
五 结 论
本课题针对企业作业和工地施工过程佩戴安全帽的自动识别问题,基于深度学习,提出了一种安全帽佩戴识别方法。该方法基于深度学习算法,以PaddlePaddle深度学习框架作为实验环境,选取了开源的安全帽识别数据库和实地拍摄的安全帽佩戴照片,使用样本扩增增加了实验数据集的样本数,选取了Faster R-CNN、SSD与YOLO v3三种深度神经网络模型,构建出安全帽智能识别模型。在实验数据集上对三种模型分别实验,对比实验结果。结果显示,基于YOLOv3的模型具有识别精度高,识别速率快等特点,识别准确率达到了99.97%。为了验证了本文提出方法的有效性,使用Python语言开发了安全帽佩戴识别的原型系统。
在本课题的研究与实现过程中,遇到了许多困难在设计这个系统之前,例如,算法调用失败的经历就多次遇到,图像显示、参数传递出现的问题更是数不胜数,在浏览各大网站之后慢慢摸索,逐渐改善了研究,解决了问题,经过了这一系列的努力,不仅懂得了学习一项技术最重要的是能够脚踏实地,勇敢面对失败才能更加靠近成功,而且提高了自身的专业能力,赋予自己面对将来挑战的信心。由于能力和时间有限,系统仍有着诸多不足,在将来的学习工作中将不断完善。
目录
目 录
内容摘要I
AbstractII
1 绪论1
1.1 目的及意义1
1.2 国内外的发展现状1
1.3 研究的内容与方法2
2 基于深度学习的安全帽识别算法3
2.1 深度学习3
2.2 算法流程4
2.3 目标检测算法4
3 实验结果分析6
3.1 数据集6
3.2 实验环境搭建8
3.3 实验设置9
3.4 实验结果分析10
4 原型系统实现13
4.1 模块调用以及运行网址呼出13
4.2 检测图片上传14
4.3 检测结果显示15
5 结论与研究成果17
参考文献18

















 1913
1913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









