






 本文研究了如何使用Pytorch构建中文情感分析模型,通过迁移学习处理电影和教育评价数据。模型构建涉及数据预处理、文本特征提取、神经网络搭建与优化,结果表明模型在情感分类上有一定限制,未来需考虑更复杂的情感理解和个性化教育策略。
本文研究了如何使用Pytorch构建中文情感分析模型,通过迁移学习处理电影和教育评价数据。模型构建涉及数据预处理、文本特征提取、神经网络搭建与优化,结果表明模型在情感分类上有一定限制,未来需考虑更复杂的情感理解和个性化教育策略。
收藏和点赞,您的关注是我创作的动力
概要
情感分析在最近的十年内得到了快速的发展,这归功于大数据的支持。相较于英语而言,中文的使用同样广泛。如何把握中文里的情感也是服务行业所关注的问题。本文旨在研究中文情绪分析的设计与开发,意在基于Pytorch平台,利用深度学习去构建神经网络模型从而去判断中文文本数据中所蕴含的情绪,试图通过迁移学习的方式,把电影评价数据的模型应用在教育评价的数据上。本文先是通过了对文献的分析,得到了迁移学习的基础,再是通过深度神经网络模型的搭建以及网上电影评价数据来训练,最终得到一个对于电影评价、教育评价都适用的模型。
【关键词】:Pytorch;神经网络;情感分析;迁移学习
一、相关基础理论
2.1 主流深度学习框架
Pytorch是Facebook在2017年推出的开源深度学习框架,源于torch更新后的一种新产品。因其是原生的python包,所以它与python是无缝集成的,同样使用了命令式编码风格。其易于上手、入门的缘故,非专业人士同样可以使用该平台来提高工作效率。Pytorch及其扩展函数库构成了一个丰富、完整的神经网络构建、应用平台,开源,免费,学习和使用方便[10]。相较于TensorFlow,Pytorch具有动态计算图表、精简的后端与高度可拓展等优势,深度学习专业人员可以利用该平台进行深度学习领域项目的设计与应用。
2.2 神经网络
2.2.1 神经网络基础
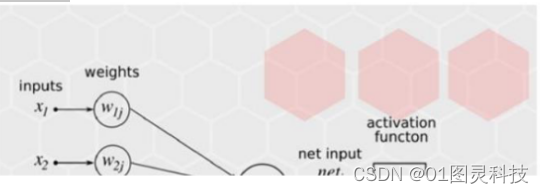
人工神经网络(Artificial Neural Networks),简称为神经网络(NNs)是一种受人脑的生物神经网络启发而设计的计算模型。这种网络基于系统的复杂程序,善于从输入的数据和标签中学习到相关映射关系,从而达成完成预测或者解决分类问题的目的。人工神经网络本质上是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型,用于拟合任意映射,因此也被称为通用拟合器。神经网络的运行包含前馈的预测过程和反馈的学习过程。
如图2-1所示,在前馈的预测过程中,信号(Inputs)从输入单元输入,并沿着网络连边传输,每个信号会与连边上的权重(Weights)进行乘积,从而得到隐含层单元的输入;接下来,隐含层单元对所有连边输入的信号进行汇总(通过transfer function进行求和),然后经过一定的处理(激活函数)进行输出( );这些输出的信号再乘以从隐含层到输出的那组连线上的权重( ),从而得到输入给输出单元的信号;最后,输出单元再对每一条输入连边的信号进行汇总,并进行加工处理再输出。最后的输出就是整个神经网络的输出。神经网络在训练阶段会通过优化函数调节每条连边上的权重 数值。
在反馈的学习过程中,每个输出神经元会首先计算出它的预测误差,然后将这个误差沿着网络的所有连边进行反向传播,得到每个隐含层节点的误差。最后,根据每条连边所连通的两个节点的误差计算连边上的权重更新量,从而完成网络的学习与调整。
二、中文情感分类模型构建
3.1 开发环境
模型是在系统WIN10、1TB+256G(SSD)、内存16G 、INTEL酷睿I7-7700HQ的CPU以及英伟达GTX1070(8G)显卡的PC机上通过python3.8版本和Anaconda1.9.12版本来使用pytorch构建深度学习模型。Anaconda是一个开源的python包管理器,包含了python、conda等180多个科学包及其依赖项。它支持Windows、Linux和Mac三种系统。由于它提供了包管理与环境管理的功能,能够很方便地解决多版本python切换、并存以及下载安装各种第三方包等问题。使用自带的jupyter notebooks应用程序,可以直接在谷歌网页页面编写、运行和调试代码。
构建神经网络模型中使用到的python模块的功能介绍:
1、Re—python独有的通过正则表达式对字符串匹配操作的模块。
2、Jieba—一款基于python的强大的分词库,完美支持中文分词。
3、Collections—包括了dict、set、list、tuple以外的一些特殊容器类型。
4、Matplotlib—将数据可视化。
3.2 数据部分
本模型中所使用的用于训练模型的数据均来自于网上的开源数据包,其包括了豆瓣在2018年之前约13万部电影数据以及105万条左右的电影评论。其中评论数据中包含评论者的ID、电影的ID、评论内容、点赞次数、评论时间和评论等级。由于文本信息均为不等长的序列,可能会出现内存不足、无法训练模型的情况,因此我们对电影评价数据做以下预处理,过程保证全随机:
1.抽取5000条评价星级为4~5的评价作为满意度高的评价存放在comment_good.txt文件中。
2. 抽取5000条评价星级为1~2的评价作为满意度低的评价存放在comment_bad.txt文件中。
3.对comment_good.txt和comment_bad.txt中的文本进行去噪处理。
3.3 文本特征提取
3.3.1、过滤标点符号
通过filter_punc函数对文本的标点符号中进行过滤操作,它通过调用正则表达式的相应程序包,替换掉了所有中英文的标点符号。#将文本中的标点符号过滤掉def filter_punc(sentence): sentence = re.sub( “[\s+.!/_,$%^(+"'“”《》?“]+|[+——!,。?、~@#¥%……&():]+”, “”, sentence)
return(sentence)
3.3.2 中文分词、单词过滤
中文分词是对文本数据分析的一种重要环节,主要的目的是将一个连续的中文句子按照汉语语言的规则组合成分开的词组的过程(脚注)。在python中,通过调用“jieba”模块来对原始文本进行分词。jieba模块拥有一个自带的词典,调用jieba.lcut(x)函数就将x中的字符分成若干个词,并存储在列表all_words[]中。x为一条评论文本数据。由于jieba自带的词典不足以满足我们的需求,因此我们根据已知数据的特性,通过调用Python的字典(diction)来建立自己专用的单词表,其中diction中存储了每个单词作为键(key),一对数字分别表示词的编号以及词在整个语料中出现的次数作为值(value)。存储第一个数值的目的是用数字来替换文字,存储第二个数值的目的是方便查看不同词的频率(TF)。根据公式(2-5)、2(6)统计训练集中评价的条数、以及包含某个特征词的评论条数,用于计算IDF。通过“TF-IDF”指标过滤常见无用词语,保留 重要的词语,从而得到更优质的词袋。
三 运行结果与分析
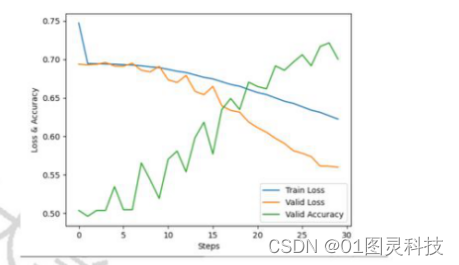
图3-3 优化函数SDG、学习率为0.01下的三条曲线分布
图3-3中蓝色的Train Loss表示训练集上的损失函数,橘色的Valid Loss表示校验集上的损失函数,绿色的Valid Accuracy表示校验集上的分类准确度。可以观察到,随着训练周期的增加,训练数据和校验数据的损失函数曲线并没有发现明显下降趋势,甚至于在第10周期之后训练数据的损失函数一直高于校验数据的损失函数值,且模型准确率一直不超过70%,这说明模型并没有训练成功。将学习率调整为0.001后再次训练模型。
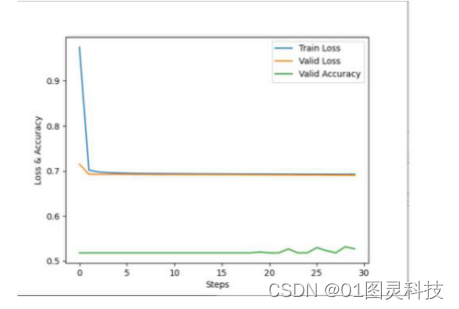
图3-4 优化函数SDG、学习率为0.001下的三条曲线分布
观察图3-4可知,训练数据的损失函数曲线在第一个周期之后与校验数据损失函数曲线持平,也就意味着SGD在学习率为0.001并没有起到做到作用,且模型准确率低达0.53。将学习率调整为0.1后再次训练模型。
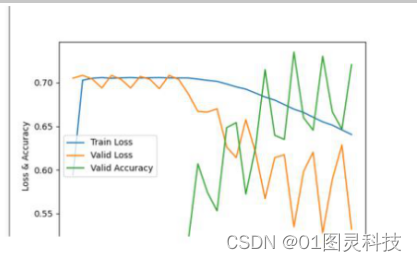
图3-5 优化函数SDG、学习率为0.1下的三条曲线分布
观察图3-5可知,虽然模型的准确率在稳步上升,但训练数据的损失函数值一直高于校验数据的损失函数值,这说明30步训练并没有成功的训练模型。试着将循环调整为15次后对模型进行训练。
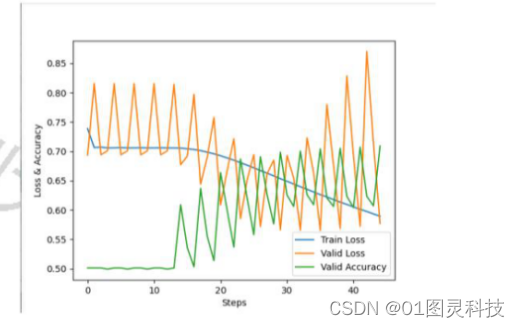
图3-6 优化函数SDG、学习率为0.1下的三条曲线分布
观察图3-6可知,模型准确率一直止步于70%,虽然校验数据的损失函数值一直围绕着训练数据的损失函数进行波动,但是该损失值过大,不足以证明模型被训练好。究其原因,问题可能出现在使用的激活函数为Relu,因为第二章提到的学习率的问题引发了Dead ReLU problem,极大可能由于SGD是固定学习率的缘故。因此我们试着采用之前介绍的学习率不固定的Adam优化算法训练模型,初始设置学习率为0.1。
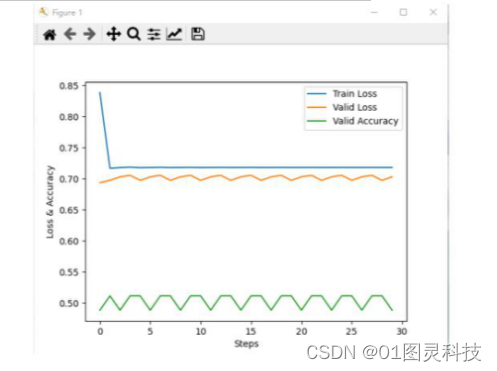
图3-7 优化函数Adam、学习率为0.1下的三条曲线分布
五 结 论
通过利用影视作品的评价数据去训练模型可以得知,对于好作品而言,人们一般不会从电影好的方面去评价一个作品的好坏,更多的是抒发自己看完电影后的感悟,大部分描述的词汇与电影的本身内容没有直接的关联,这也证实了电影评价的数据确实不好用一般的分类模型去分析。此外,模型的精确度还可以通过针对性的对数据清洗来提高。
另一方面“大数据”与“教育”的相结合可能远远的会比我们现在所搭建的神经网络分类器要复杂的许多,我们的分类器暂时也只能做到对文本情绪的好坏进行分类。在情感领域内,情感的分类远远不是非黑即白这么简单,教育工作者会需要评价文本中蕴含的情感建立更加具有针对性的教育方针的改变,所以我们模型还远远达不到这方面的要求。但现在所搭建的神经网络模型,是更加高级的神经网络(RNN模型或者LSTM模型)的基础。路漫漫其修远兮,拥有扎实的基础理论才有可能再往上继续延伸,这是起点,却不是终点。
目录
目录
1 绪论5
1.1 研究背景5
1.2 国内外研究现状5
1.3 研究问题6
1.4 研究方法与手段7
2 相关基础理论8
2.1 主流深度学习框架8
2.2 神经网络8
2.2.1 神经网络基础8
2.2.2 神经网络的分类任务9
2.2.3 激活函数9
2.2.4 损失函数10
2.2.5 过拟合现象11
2.2.6 泛化能力12
2.2.7 超参数12
2.3 词袋模型12
2.4 词频逆文档频率(TF-IDF)13
3 中文情感分类模型构建13
3.1 开发环境13
3.2 数据部分14
3.3 文本特征提取14
3.3.1 过滤标点符号14
3.3.2 中文分词及单词过滤14
3.3.3 文本数据向量化14
3.3.4 数据划分15
3.4 神经网络的搭建15
3.5 运行结果与分析16
3.6 优化与改进模型20
4 方案拓展以及总结21
4.1 方案拓展21
4.2 方案总结22
参考文献23
致谢24


















 6102
6102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









