



正则表达式
一、介绍
正则表达式(Regular Expression,简称 regex 或 regexp)是一种用于描述字符串模式的特殊语法,是用于匹配字符串中字符组合的模式,主要用于匹配、查找、替换或提取字符串中符合特定规则的内容。
它不是某一种编程语言特有的功能,而是被大多数编程语言(如 Java、Python、JavaScript、PHP 等)和工具(如文本编辑器、命令行工具)广泛支持的通用技术。
有一个网站可以上手练习操作正则表达式:RegExr: Learn, Build, & Test RegEx
二、使用场景
在日常开发中,我们经常会遇到使用正则表达式的场景,比如一些常见的表单校验,手机号或者身份信息是否规范,字符串替换与清洗,等这就可以用正则表达式去匹配。
例如:
- 判断一个字符串中是否包含有某个字符或者某个字符串
找出字符串 ‘0000000O0000000’ 中是否有大写字母 O - 手机号:
^1[3-9]\d{9}$(验证 11 位手机号,以 1 开头,第二位 3-9) - 邮箱:
^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$(匹配标准邮箱格式) - 身份证号:
^\d{17}[\dXx]$(18 位身份证,最后一位可能是 X) - 密码强度:
^(?=.*[A-Z])(?=.*[a-z])(?=.*\d).{8,}$(至少 8 位,包含大小写字母和数字)
三、基本语法
正则表达式格式为/ /g在斜号中书写语法即可,但是有时候无需斜号包裹,可以直接书写语句。
以下是语句总结
\\表示将\转义为字符;(以此类推)
^表示字符串的开始;
$表示字符串的结束;
()表示捕获组;
(?:)表示非捕获组;
\n表示引用第n个捕获组已匹配到的内容;
.表示任意字符;
\s表示空字符;
\S表示非空字符;
\d表示数字;
\D表示非数字;
\w表示字母、数字和下划线;
\W表示非字母、数字和下划线;
xyz表示xyz;
x|y表示x或y;(|优先匹配字符)
【xyz】表示x或y或z;
【^xyz】表示非x,非y,非;
【x-z】表示x~z;
\bxyz表示以xyz为前缀的单词;
\Bxyz表示不以xyz为前缀的单词;
x+表示x重复了1次或n次;
x*表示x重复了0次或n次;
x?表示x重复了0次或1次;
x{n}表示x重复了n次;
x{n,}表示x重复了≥n次;
x{n,n+1}表示x重复了n~n+1次;
&(?=x)表示当&后的字符为x时,匹配&;
&(?!x)表示当&后的字符不为x时,匹配&;
(?<=&)x表示当x前的字符为&时,匹配x;
(?<!&)x表示当x前的字符不为&时,匹配x。
转义符号:
.表示除换行符外任意一个字符,如果直接.$会表示匹配所有结尾位置,只有使用转义符号才能正确表达意思\.$匹配所有结尾处的
.
(1)字符类匹配
常用符号
①字符:我们直接输入a,就表示匹配所有的a
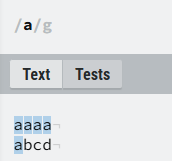
②[]:表示匹配方括号中的每一个字符,注意,方括号中字符即使没有隔离,依旧是表示单个字符,且无需转义符号,如图1。
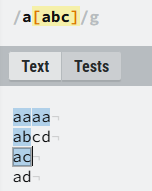
如果接在一个单元后面的话,表示该单元后有方括号中的任意元素即可匹配,如图2。
图1:
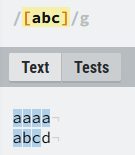
图2:
[]方括号内常用符号:
1.
^:取反符号,表示匹配除了在方括号内的所有元素^取反在方括号[]内部表示取反,在[]外部表示匹配每一行开头:
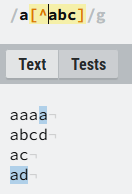
2.
-:[]方括号中可以用-短横杠表示范围区间,如A-Z等
③预定义字符:因为要匹配多个字符使用[]会比较繁琐,使用就出现了预定义字符集。比如\d表示所有数字,等同于[0-9]
像这样的预定义字符集还有:
\d:表示所有数字
\D:表示除数字外的所有字符,包含空字符。
\w:表示所有所有的字符;大小写字母,数字,下划线;
\W:表示除去该字符集外的所有字符
\s:表示所有空白字符;比如空格,制表符,换行符等
\S:出去空白字符外的所有字符
(2)位置和边界匹配
①^:表示匹配开头为指定字符的位置;
多行匹配:
如果不开启多行匹配就会只匹配全文的开头为a的字符,其余匹配规则同理。
未开启多行匹配:

开启多行匹配:
!
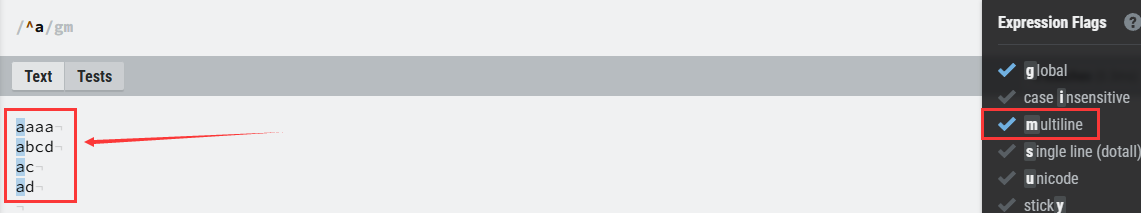
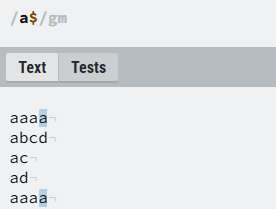
②$:表示匹配结尾为指定字符的位置;
使用位置与^不同,该符号是放在指定字符后面的
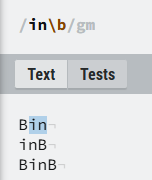
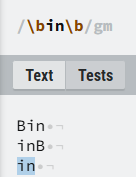
③\b:表示一个边界,以例子说明
\b放在in后面,表示匹配in结尾单词位置;
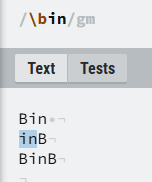
\b放前面表示匹配in开头单词位置;
- 前后都加上的话就是匹配单独的in。
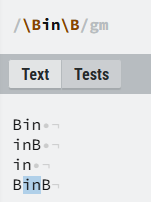
- 如果前后都换成
\B大写的就表示in在中间的位置
!
(3)量词
①{}:指定一个范围,表示该字符数量必须在这个区间,有四种表达方式:
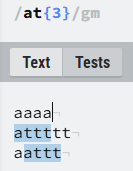
假设有个正则表达式:/at{}/gm
1.{3},表示匹配a后跟3个t的位置。
2.{3,5},表示 “a” 后面跟 3到5个t的位置。
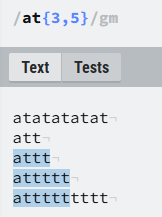
如果你先表达的意思是:匹配出现3-5次at字符串,你就需要将at用括号括起来形成一个组
(at){3,5}
3.{3,},表示 “a” 后面跟 3个及以上t的位置。
这是一个贪婪匹配,尽管atttttt满足了最小t为3的条件,但是还是会匹配3个以上的字符,尽可能多的匹配。
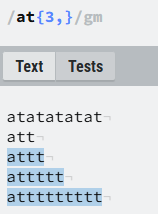
4.{3,}?:加上?问号之后就会只匹配3个字符,就不会出现贪婪匹配,意思是至少满足3个t。
要区别{3}和{3,}?
前者表示精确匹配3位,后者表示满足匹配位数后尽量取少的位数。
字符串:
"aaaab"(前 4 个a后接1个b)
正则 1:a{3}b
- 匹配结果:
"aaab"(a必须恰好 3 次,然后跟b,正确匹配)正则 2:
a{3,}?b
- 匹配结果:
"aaaab"( “至少 3 次a后跟b”)
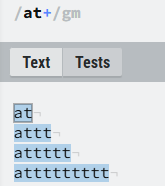
②+:表示匹配前方字符重复出现1次或多次的位置,等效于:{1,}
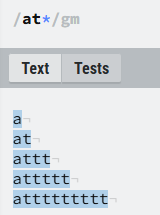
③*:表示匹配前方字符重复出现0次或多次的位置,等效于:{0,}
只要出现了0,重复0次的,重复单元前一个单元会保持匹配状态,例如下图
at*,a一直为匹配状态
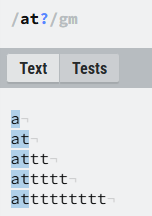
④?:匹配前面的字符重复0次或者1次的位置,等效于:{0,1}
(4)分组和捕获
分组就是用括号将字符包装成一个组来操作()
而捕获就是使用分出来的组。
①():分组我们就使用案例来理解吧。
假设我们需要获取一个单词pattern,且不区分首字母大小写,我们表达式会这样写:
Pattern|pattern或[Pp]ttern
但是我们利用分组就可以这样写:
(P|p)ttern
②捕获:当我们分组之后,默认会赋予每一个组组号,我们可以利用组号来获取指定的组进而操作它。
$n:n为组号,用于在替换字符串中引用第 n 个捕获分组的内容。
\n :n为组号,在正则表达式本身中引用第 n 个捕获分组的内容
下面用两个案例告诉你两个符号的不同用处
案例1
将:年-月-日 变为 日-月-年
2025-01-01
2025/01/01
2025_01_01
2025.01.01
20250101
我们的思路就是先分组捕获到年月日:
1.分组
年月日分别是年为4位的数字,月为1到2位的数字,日为1到2位的数字
(\d{4})(\d{1,2})(\d{1,2})
然后使用[]补充分隔符即可;
但是有一行数据20250101没有字符,我们就可以使用量词?修饰分隔符集合,表示出现0次或1次
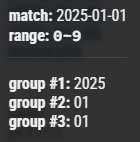
(\d{4})[-/_.]?(\d{1,2})[-/_.]?(\d{1,2})

捕获分组为:
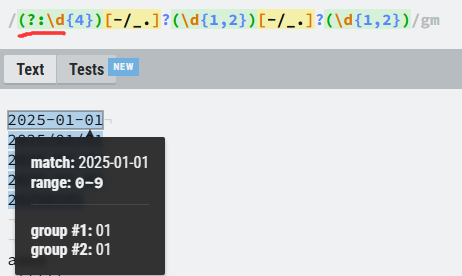
设置非捕获分组:有时候我们不需要捕获分组,只是单纯表达式需要加括号,我们可以使用:
?::放在括号内即可
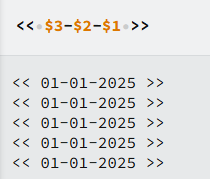
2.捕获
上述分组后,默认有个组号,年为1,月为2从左向右分。
我们在替换窗口处,使用$利用组,交换位置即可
案例2
假设我们需要匹配前后字母相同的单词
我们可以先将第一个字母分为一个组,后面只要能拿到这个组就相当于能拿到这个字母了。
我们可以用到\在正则表达式用使用
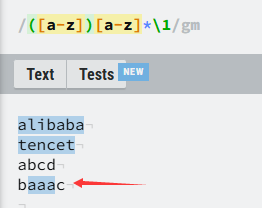
\b([a-z])[a-z]*\1\b
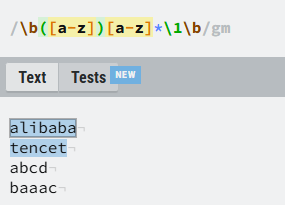
逻辑就是:
([a-z])拿到任一字符的组,[a-z]*匹配单词中间所有的字符,\1拿到组也就是拿到开头字符最后使用
\b边界包裹单词,表示这是一个完整的单词,否则baaac中的’aaa‘也会匹配到
(5)前瞻和后顾
前瞻和后顾分为:正向前瞻和负向前瞻,正向后顾和负向后顾。
正向前瞻就是只匹配到符合条件的前面部分,正向后顾就是只匹配到符合条件的后面部分,
负向就是除了正向匹配到的所有部分。
以一个案例解释:
有如下数据
$100
$200
$abc
$def
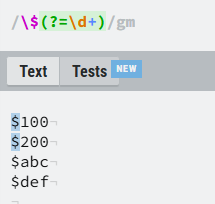
1.正向前瞻
目的:我们只需要匹配到数字前面的$符号,不匹配到数字。
?=:我们将$符号和数字分成两组,利用某种表达式使得只匹配后为数字的符号部分的操作,就叫正向前瞻
此时表达式为:\$(?=\d+)
\d+匹配所有的数字
\$\d+这样就匹配到类似$100的数字金额了
$美元符号需要使用转义字符\
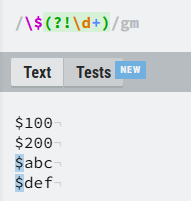
2.负向前瞻
?!:正向前瞻匹配的是后面为数字的
符号
∗
∗
,负向前瞻就是匹配
∗
∗
后面不为数字的
符号**,负向前瞻就是匹配**后面不为数字的
符号∗∗,负向前瞻就是匹配∗∗后面不为数字的符号,就叫负向前瞻
此时表达式为:\$(?!\d+)
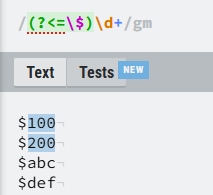
3.正向后顾
?<=:我们将
符号和数字分成两组,利用某种表达式使得
∗
∗
只匹配前面为
符号和数字分成两组,利用某种表达式使得**只匹配前面为
符号和数字分成两组,利用某种表达式使得∗∗只匹配前面为符号的数字部分**部分的操作,就叫正向后顾
此时表达式为:(?<=\$)\d+
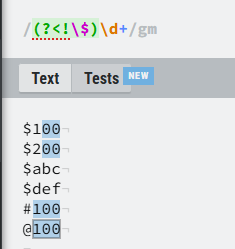
4.负向后顾
?<!:正向后顾匹配的是前面符号为
的数字部分,负向就是
∗
∗
匹配前面符号不为
的数字部分,负向就是**匹配前面符号不为
的数字部分,负向就是∗∗匹配前面符号不为的数字**部分,操作符为
表达式为:(?<!\$)\d+


















 7317
7317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











