






最近在学习了muduo库的Buffer类,因为这个编程思想,今后在各个需要缓冲区的项目编程中都可以用到,所以今天来总结一下!
Buffer的数据结构
muduo的Buffer的定义如下,其内部是 一个 std::vector,且还存在两个size_t类型的readerIndex_,writerIndex_标识来表示读写的位置。
std::vector<char> buffer_;
size_t readerIndex_;
size_t writerIndex_;
结构图如下:
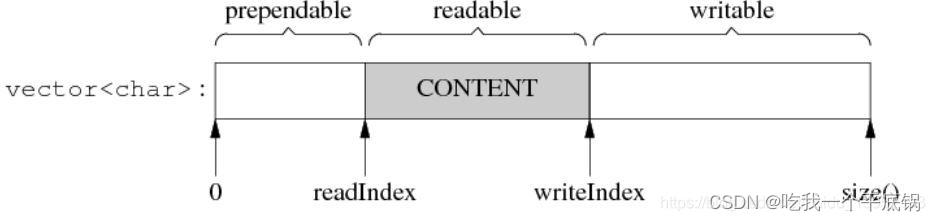
readIndex、writeIndex把整个vector内容分为3块:prependable、readable、writable,各块大小关系:
- prependable = readIndex
- readable = writeIndex - readIndex
- writable = buffer.size() - writeIndex
Buffer设计思路
- 定义了预留的prependable初始大小,以及Buffer的初始大小,代码如下:
static const size_t kCheapPrepend = 8; //缓冲区头部
static const size_t kInitialSize = 1024; //缓冲区读写初始大小
- 构造函数对Buffer进行了初始化,初始时两个标志位都指向kCheapPrepend,代码如下:
explicit Buffer(size_t initialSize = kInitialSize)
: buffer_(initialSize + kCheapPrepend)
, readerIndex_(kCheapPrepend)
, writerIndex_(kCheapPrepend)
{
}
- 利用三个函数,通过标志位,求出了可读可写以及预留区的大小,代码如下:
size_t readableBytes() const { return writerIndex_ - readerIndex_; }
size_t writerableBytes() const { return buffer_.size() - writerIndex_; }
size_t prependableBytes() const { return readerIndex_; }
- 利用peek()函数,求出缓冲区可读数据的起始位置,代码如下:
const char* peek() const
{
return begin() + readerIndex_;
}
- 通过一系列函数,对标志位进行重置操作
void retrieve(size_t len) //len表示已经读了的
{
if(len < readableBytes())
{
//已经读的小于可读的,只读了一部分len
//还剩readerIndex_ += len 到 writerIndex_
readerIndex_ += len;
}
else //len == readableBytes()
{
retrieveAll();
}
void retrieveAll() //都读完了
{
readerIndex_ = writerIndex_ = kCheapPrepend;
}
- 计算数组的起始地址
char* begin()
{
return &*buffer_.begin(); //vector底层数组元素的地址,也就是数组的起始地址
}
const char* begin() const
{
return &*buffer_.begin();
}
- 把onMessage函数上报的Buffer数据,转成string类型的数据返回。
std::string retrieveAllAsString()
{
return retrieveAsString(readableBytes());//应用可读取数据的长度
}
std::string retrieveAsString(size_t len)
{
std::string result(peek(),len); //从起始位置读len长
retrieve(len);
return result;
}
- 计算剩余可写的缓冲区长度,若可写的小于要写入的要进行扩容。
void ensureWriterableBytes(size_t len)
{
if (writerableBytes() < len)
{
makeSpace(len); //扩容
}
}
- 把[data ,data+len]内存上的数据,添加到writeable缓冲区当中,首先会判断以下能不能写入,如果不足,先扩容,代码如下:
void append(const char* data, size_t len) //添加数据
{
ensureWriterableBytes(len);
std::copy(data,data+len,beginWrite());
writerIndex_ += len;
}
char* beginWrite() {return begin() + writerIndex_; }
const char* beginWrite() const {return begin() + writerIndex_; }
如何扩容呢?
void makeSpace(size_t len)
{
if (prependableBytes() + writerableBytes() < len + kCheapPrepend)
{
buffer_.resize(writerIndex_ + len);
}
else
{
size_t readable = readableBytes(); //保存一下没有读取的数据
std::copy(begin()+readerIndex_
, begin()+writerIndex_
, begin()+ kCheapPrepend); //挪一挪
readerIndex_ = kCheapPrepend;
writerIndex_ = readerIndex_+readable;
}
}
扩容巧妙思想在于,因为两个指针的不断移动,导致指向可读数据的指针一直后移,预留区越来越大,如果一味的扩容,会导致前面预留区越来越大,这样造成了浪费,所以muduo库采用了以下思路进行判断,何时需要扩容:
- 利用prependableBytes() + writerableBytes() 判断了整个Buffer上面剩余的可写入的空间,如果这个空间小于要写入的以及预留的8字节位置,那么直接扩容!!
- 如果大于说明目前剩余的位置还足够存放要写入的数据,那么通过vector的数据拷贝,把Buffer里面的数据挪一挪,这时候readerIndex_就指向了初始位置,writerIndex_的位置就是目前可写入的首地址,这样在进行写入,就不需要一味的扩容。
如何从从fd上读取数据?
ssize_t readFd(int fd,int* saveErrno);
整体思路如下:
ssize_t Buffer::readFd(int fd,int* saveErrno)
{
char extrabuf[65536] = { 0 }; //栈上内存空间
struct iovec vec[2];
const size_t writable = writerableBytes(); //buffer底层缓冲区剩余的可写的空间大小
vec[0].iov_base = begin() + writerIndex_;
vec[0].iov_len = writable;
vec[1].iov_base = extrabuf;
vec[1].iov_len = sizeof extrabuf;
const int iovcnt = (writable < sizeof extrabuf) ? 2 : 1;
const ssize_t n = ::readv(fd, vec, iovcnt);
if(n < 0)
{
*saveErrno = errno;
}
else if(n <= writable) //buffer可写的缓冲区已经够存储读取出来的数据
{
writerIndex_ += n;
}
else //extrabufl里面也写入了数据
{
writerIndex_ = buffer_.size();
append(extrabuf,n-writable); //writerIndex_ 开始写n-writable的数据
}
return n;
}
巧妙点在哪里呢?
我们在读数据的时候,不知道数据的最终大小是多少,所以采用了如下的方法:
- 首先定义了一个64K栈缓存extrabuf临时存储,利用栈的好处是可以自动的释放,并计算出目前剩余可写的空间大小;
- 利用结构体 iovec 指定了两块缓冲区,一块是目前剩余的可写的Buffer,一个是临时的缓冲区,指定了起始位置以及缓冲区的大小;
const int iovcnt = (writable < sizeof extrabuf) ? 2 : 1;如果writable < sizeof extrabuf就选2块内存,否则一块就够用;- 读数据
const ssize_t n = ::readv(fd, vec, iovcnt); - 若读取的数据超过现有内部buffer_的writable空间大小时, 启用备用的extrabuf 64KB空间, 并将这些数据添加到内部buffer_的末尾。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









