







全文共31554字,18个目录,n个子目录
1.前言
文章制作不易,希望你能点个点赞收藏加关注,我感激不尽
在文章中我参考了许多大佬的博文,不过时间紧急,没有一一整理。在这里表示感谢
在文章中如果有没讲明白的都可以私信我,如果有错的一定要告诉我,让我改进。
这篇文章是专门面向初学者的,将会带你快速精通python。在文章中我会用初学者也听得懂的语言来讲解每个知识点。好了,多说无益。开启我们的学习之路吧!
2.什么是python,学了python有什么用?(略读)
2.1 Python简介
Python由荷兰数学和计算机科学研究学会的吉多·范罗苏姆于1990年代初设计,作为一门叫作ABC语言的替代品。 Python提供了高效的高级数据结构,还能简单有效地面向对象编程。Python语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的编程语言, 随着版本的不断更新和语言新功能的添加,逐渐被用于独立的、大型项目的开发。
Python在各个编程语言中比较适合新手学习,Python解释器易于扩展,可以使用C语言或C++(或者其他可以通过C调用的语言)扩展新的功能和数据类型。 Python也可用于可定制化软件中的扩展程序语言。Python丰富的标准库,提供了适用于各个主要系统平台的源码或机器码。

2.2 Python的由来
Python的前世源自鼻祖“龟叔”。1989年,吉多·范罗苏姆(Guido van Rossum)在阿姆斯特丹为了打发无聊的圣诞节,决心开发一个新的脚本解释程序,自此Python和创始人“龟叔”开始进入公众视野。他希望这个新的叫做Python的语言,能符合他的理想:创造一种C和shell之间,功能全面,易学易用,可拓展的语言。

1991年,第一个Python编译器诞生。它基于C语言实现,并能够调用C语言的库文件。后面历经版本的不断换代革新,Python走到了非常具有里程碑意义的一个节点,即2004的2.4版本诞生了目前最流行的WEB框架Django!六年后Python发展到2.7版本,这是目前为止2.x版本中最新且较为广泛使用版本。
2.7版本的诞生不同于以往2.x版本的垂直换代逻辑,它是2.x版本和3.x版本之间过渡的一个桥梁,以便最大程度上继承3.x版本的新特性,同时尽量保持对2.x的兼容性。
因此3.x版本在2.7版本之前就已经问世,从2008年的3.0版本开始,python3.x系呈迅猛发展之势,版本更新活跃,一直发展到现在最新的3.11版本。3.8~11版本也是目前3.x系列中主流且广泛使用的版本,后续相关程序的demo,默认均基于3.11版本展开。
2.3 Python的优势
简单:Python是一种代表简单主义思想的语言。阅读一个良好的Python程序就感觉像是在读英语一样。它使你能够专注于解决问题而不是去搞明白语言本身。
易学:Python极其容易上手,因为Python有极其简单的说明文档 [8] 。
易读、易维护:风格清晰划一、强制缩进
用途广泛
速度较快:Python的底层是用C语言写的,很多标准库和第三方库也都是用C写的,运行速度非常快。 [7]
免费、开源:Python是FLOSS(自由/开放源码软件)之一。使用者可以自由地发布这个软件的拷贝、阅读它的源代码、对它做改动、把它的一部分用于新的自由软件中。FLOSS是基于一个团体分享知识的概念。
高层语言:用Python语言编写程序的时候无需考虑诸如如何管理你的程序使用的内存一类的底层细节。
可移植性:由于它的开源本质,Python已经被移植在许多平台上(经过改动使它能够工作在不同平台上)。这些平台包括Linux、Windows、FreeBSD、Macintosh、Solaris、OS/2、Amiga、AROS、AS/400、BeOS、OS/390、z/OS、Palm OS、QNX、VMS、Psion、Acom RISC OS、VxWorks、PlayStation、Sharp Zaurus、Windows CE、PocketPC、Symbian以及Google基于linux开发的android平台。
解释性:一个用编译性语言比如C或C++写的程序可以从源文件(即C或C++语言)转换到一个你的计算机使用的语言(二进制代码,即0和1)。这个过程通过编译器和不同的标记、选项完成。
运行程序的时候,连接/转载器软件把你的程序从硬盘复制到内存中并且运行。而Python语言写的程序不需要编译成二进制代码。你可以直接从源代码运行程序。
在计算机内部,Python解释器把源代码转换成称为字节码的中间形式,然后再把它翻译成计算机使用的机器语言并运行。这使得使用Python更加简单。也使得Python程序更加易于移植。
面向对象:Python既支持面向过程的编程也支持面向对象的编程。在“面向过程”的语言中,程序是由过程或仅仅是可重用代码的函数构建起来的。在“面向对象”的语言中,程序是由数据和功能组合而成的对象构建起来的。
Python是完全面向对象的语言。函数、模块、数字、字符串都是对象。并且完全支持继承、重载、派生、多继承,有益于增强源代码的复用性。Python支持重载运算符和动态类型。相对于Lisp这种传统的函数式编程语言,Python对函数式设计只提供了有限的支持。有两个标准库(functools,itertools)提供了Haskell和Standard ML中久经考验的函数式程序设计工具。
可扩展性、可扩充性:如果需要一段关键代码运行得更快或者希望某些算法不公开,可以部分程序用C或C++编写,然后在Python程序中使用它们。
Python本身被设计为可扩充的。并非所有的特性和功能都集成到语言核心。Python提供了丰富的API和工具,以便程序员能够轻松地使用C语言、C++、Cython来编写扩充模块。Python编译器本身也可以被集成到其它需要脚本语言的程序内。因此,很多人还把Python作为一种“胶水语言”(glue language)使用。使用Python将其他语言编写的程序进行集成和封装。在Google内部的很多项目,例如Google Engine使用C++编写性能要求极高的部分,然后用Python或Java/Go调用相应的模块。《Python技术手册》的作者马特利(Alex Martelli)说:“这很难讲,不过,2004年,Python已在Google内部使用,Google 召募许多 Python 高手,但在这之前就已决定使用Python,他们的目的是 Python where we can,C++ where we must,在操控硬件的场合使用C++,在快速开发时候使用Python。”
可嵌入性:可以把Python嵌入C/C++程序,从而向程序用户提供脚本功能。
丰富的库:Python标准库确实很庞大。它可以帮助处理各种工作,包括正则表达式、文档生成、单元测试、线程、数据库、网页浏览器、CGI、FTP、电子邮件、XML、XML-RPC、HTML、WAV文件、密码系统、GUI(图形用户界面)、Tk和其他与系统有关的操作。这被称作Python的“功能齐全”理念。除了标准库以外,还有许多其他高质量的库,如wxPython、Twisted和Python图像库等等。
规范的代码:Python采用强制缩进的方式使得代码具有较好可读性。而Python语言写的程序不需要编译成二进制代码。Python的作者设计限制性很强的语法,使得不好的编程习惯(例如if语句的下一行不向右缩进)都不能通过编译。其中很重要的一项就是Python的缩进规则。一个和其他大多数语言(如C)的区别就是,一个模块的界限,完全是由每行的首字符在这一行的位置来决定(而C语言是用一对大括号来明确的定出模块的边界,与字符的位置毫无关系)。通过强制程序员们缩进(包括if,for和函数定义等所有需要使用模块的地方),Python确实使得程序更加清晰和美观。
高级动态编程:虽然Python可能被粗略地分类为“脚本语言”(script language),但实际上一些大规模软件开发计划例如Zope、Mnet及BitTorrent,Google也广泛地使用它。Python的支持者较喜欢称它为一种高级动态编程语言,原因是“脚本语言”泛指仅作简单程序设计任务的语言,如shellscript、VBScript等只能处理简单任务的编程语言,并不能与Python相提并论。
做科学计算优点多:说起科学计算,首先会被提到的可能是MATLAB。除了MATLAB的一些专业性很强的工具箱还无法被替代之外,MATLAB的大部分常用功能都可以在Python世界中找到相应的扩展库。和MATLAB相比,用Python做科学计算有如下优点:
●首先,MATLAB是一款商用软件,并且价格不菲。而Python完全免费,众多开源的科学计算库都提供了Python的调用接口。用户可以在任何计算机上免费安装Python及其绝大多数扩展库。
●其次,与MATLAB相比,Python是一门更易学、更严谨的程序设计语言。它能让用户编写出更易读、易维护的代码。
●最后,MATLAB主要专注于工程和科学计算。然而即使在计算领域,也经常会遇到文件管理、界面设计、网络通信等各种需求。而Python有着丰富的扩展库,可以轻易完成各种高级任务,开发者可以用Python实现完整应用程序所需的各种功能。
2.4 Python的缺点
单行语句和命令行输出问题:很多时候不能将程序连写成一行,如import sys;for i in sys.path:print i。而perl和awk就无此限制,可以较为方便的在shell下完成简单程序,不需要如Python一样,必须将程序写入一个.py文件。
给初学者带来困惑:独特的语法,这也许不应该被称为局限,但是它用缩进来区分语句关系的方式还是给很多初学者带来了困惑。即便是很有经验的Python程序员,也可能陷入陷阱当中。
运行速度慢:这里是指与C和C++相比。Python开发人员尽量避开不成熟或者不重要的优化。一些针对非重要部位的加快运行速度的补丁通常不会被合并到Python内。所以很多人认为Python很慢。不过,根据二八定律,大多数程序对速度要求不高。在某些对运行速度要求很高的情况,Python设计师倾向于使用JIT技术,或者用使用C/C++语言改写这部分程序。可用的JIT技术是PyPy。
和其他语言区别
对于一个特定的问题,只要有一种最好的方法来解决
这在由Tim Peters写的Python格言(称为The Zen of Python)里面表述为:There should be one-and preferably only one-obvious way to do it。这正好和Perl语言(另一种功能类似的高级动态语言)的中心思想TMTOWTDI(There's More Than One Way To Do It)完全相反。
Python的设计哲学是“优雅”、“明确”、“简单”。因此,Perl语言中“总是有多种方法来做同一件事”的理念在Python开发者中通常是难以忍受的。Python开发者的哲学是“用一种方法,最好是只有一种方法来做一件事”。在设计Python语言时,如果面临多种选择,Python开发者一般会拒绝花俏的语法,而选择明确的没有或者很少有歧义的语法。由于这种设计观念的差异,Python源代码通常被认为比Perl具备更好的可读性,并且能够支撑大规模的软件开发。这些准则被称为Python格言。在Python解释器内运行import this可以获得完整的列表。
更高级的Virtual Machine
Python在执行时,首先会将.py文件中的源代码编译成Python的byte code(字节码),然后再由Python Virtual Machine(Python虚拟机)来执行这些编译好的byte code。这种机制的基本思想跟Java,.NET是一致的。然而,Python Virtual Machine与Java或.NET的Virtual Machine不同的是,Python的Virtual Machine是一种更高级的Virtual Machine。这里的高级并不是通常意义上的高级,不是说Python的Virtual Machine比Java或.NET的功能更强大,而是说和Java 或.NET相比,Python的Virtual Machine距离真实机器的距离更远。或者可以这么说,Python的Virtual Machine是一种抽象层次更高的Virtual Machine。基于C的Python编译出的字节码文件,通常是.pyc格式。除此之外,Python还可以以交互模式运行,比如主流操作系统Unix/Linux、Mac、Windows都可以直接在命令模式下直接运行Python交互环境。直接下达操作指令即可实现交互操作。
2.4 学了python能干什么
-
Web 和 Internet开发
-
科学计算和统计
-
桌面界面开发
-
软件开发
-
后端开发
-
网络接口:能方便进行系统维护和管理,Linux下标志性语言之一,是很多系统管理员理想的编程工具。
- 图形处理:有PIL、Tkinter等图形库支持,能方便进行图形处理。
- 数学处理:NumPy扩展提供大量与许多标准数学库的接口。
- 文本处理:python提供的re模块能支持正则表达式,还提供SGML,XML分析模块,许多程序员利用python进行XML程序的开发。
- 数据库编程:程序员可通过遵循Python DB-API(应用程序编程接口)规范的模块与Microsoft SQL Server,Oracle,Sybase,DB2,MySQL、SQLite等数据库通信。python自带有一个Gadfly模块,提供了一个完整的SQL环境。
- 网络编程:提供丰富的模块支持sockets编程,能方便快速地开发分布式应用程序。很多大规模软件开发计划例如Zope,Mnet 及BitTorrent. Google都在广泛地使用它。
- Web编程:应用的开发语言,支持最新的XML技术。
- 多媒体应用:Python的PyOpenGL模块封装了“OpenGL应用程序编程接口”,能进行二维和三维图像处理。PyGame模块可用于编写游戏软件。
- pymo引擎:PYMO全称为python memories off,是一款运行于Symbian S60V3,Symbian3,S60V5,Symbian3,Android系统上的AVG游戏引擎。因其基于python2.0平台开发,并且适用于创建秋之回忆(memories off)风格的AVG游戏,故命名为PYMO。
- 黑客编程:python有一个hack的库,内置了你熟悉的或不熟悉的函数,但是缺少成就感。
3.准备工作
3.1 Python解释器安装
至于python解释器安装我不推荐大家安装最新的版本,可以安装python3.9,3.10。
安装教程可以查看知乎的一篇文章
Python 详细安装步骤图文教程 - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/231233101安装后win+r打开运行窗口,里面cmd确认打开终端
https://zhuanlan.zhihu.com/p/231233101安装后win+r打开运行窗口,里面cmd确认打开终端 输入cmd
输入cmd
输入python输出如下就成功了

3.2 python编辑器选择
关于IDE常见的有如下选择:
- IDLE(Python自带,不推荐)
- Pycharm(推荐,专门面向python)
- VsCode(推荐)
- Jupyter (推荐)
- Sublime Text(不推荐)
- 文本文档(千万别用!!!)
IDLE是python安装是自带的一个编辑器,可以在菜单中找到

打开后界面如下

由于这个我是不推荐的所以先不讲那么多了。
3.3 编辑器安装
我把这些编辑器的安装教程都整理在下面了
PyCharm安装教程(windows) - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/359897213VSCode详细安装教程 - 知乎 (zhihu.com)
https://zhuanlan.zhihu.com/p/359897213VSCode详细安装教程 - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/264785441化繁从简,优雅编码。——Jupyter notebook_小Y的编程课堂的博客-CSDN博客朱特尔笔记本(Jupyter notebook)是目前用于写数据科学,机器学习最流行的编辑器。朱特尔笔记本与其他主流编辑器不同在于它是基于Web技术实现的。朱特尔笔记本提供的是一个交互环境,且可以编辑富文本格式的内容(包括主流的Markdown、Latex公式等),可以十分方便的编辑文档。朱特尔笔记本最初是只面向Python语言的,现在已经扩展到40余钟语言。
https://zhuanlan.zhihu.com/p/264785441化繁从简,优雅编码。——Jupyter notebook_小Y的编程课堂的博客-CSDN博客朱特尔笔记本(Jupyter notebook)是目前用于写数据科学,机器学习最流行的编辑器。朱特尔笔记本与其他主流编辑器不同在于它是基于Web技术实现的。朱特尔笔记本提供的是一个交互环境,且可以编辑富文本格式的内容(包括主流的Markdown、Latex公式等),可以十分方便的编辑文档。朱特尔笔记本最初是只面向Python语言的,现在已经扩展到40余钟语言。https://blog.csdn.net/m0_73552311/article/details/131510757Sublime Text 4安装使用(完整教程)_sublime test4_今样_swift的博客-CSDN博客
![]() https://blog.csdn.net/weixin_45013646/article/details/119879183大家可以自行选择,这四个我电脑是都有安装。毕竟好事不嫌多嘛
https://blog.csdn.net/weixin_45013646/article/details/119879183大家可以自行选择,这四个我电脑是都有安装。毕竟好事不嫌多嘛
4.初探python
4.1不一样的HelloWorld
经过一段时间的准备工作,我们重于要迎来正题了!熟悉一门语言的最快方法便是通过例子使用它。我们今天就不行经典的HelloWorld了,写个不一样的!

在这张图片上python之父穿着一件印着‘人生苦短,Python是岸’的T恤,那就让我们用python打印这句话来作为我们的第一个编程作品!
print(’人生苦短,Python是岸‘)让我们在终端输入python,然后自己打出该语句

呀!报错了。仔细看应该是输入法的问题

现在又缺了双引号

大功告成了!代码如下,我推荐大家都自己打一遍
print('人生苦短,Python是岸')我在代码中犯得错是为了大家对这些语法跟加深刻,相信大家不会再犯诸如此类的错误了。
恭喜你,你已经踏入了编程世界。
4.2解剖第一个python程序
在 4.1 不一样的HelloWorld 一节课中我们制作了第一个python程序。我们现在就仔细解剖一下第一个程序。代码如下
print('人生苦短,Python是岸')在代码中标黄的部分是一个python内置函数,用于将传入的值输出打终端,我们可以通过help函数获取详细的帮助
help(print)输出如下

参考翻译
关于模块内置的内置函数打印的帮助:
print(…)
print(value,…,sep='',end='n',file=sys.stdout,flush=False)
将值打印到流,或者默认情况下打印到sys.stdout。
可选关键字参数:
file:类似文件的对象(流);默认为当前sys.stdout。
sep:插入值之间的字符串,默认为空格。
end:附加在最后一个值后面的字符串,默认为换行符。
flush:是否强制冲洗流。这样就很明了了,在输出多个值的时候可以用逗号隔开,这样输出的时候就会把所有传参函数用空格隔开输出。例如
print('人生苦短,', 'Python是岸')当然数字也可以

或者用加号拼接字符串。

只有字符串和数字怎么想加我会在后面讲到。
其他参数大家也可以自己尝试
至于里面的字符串会在后面详细讲解。
4.3 有输出没输入怎么行
在python中输出是使用print函数,那没有输入怎么行。
在python中输入当然是使用input函数。
至于input函数这么使用我们也使用内置的help函数。
help(input)
参考翻译
关于模块内置中内置函数输入的帮助:
input(提示=无,/)
从标准输入中读取字符串。尾部换行符被剥去。
提示字符串(如果给定)将打印到标准输出,而不带
在读取输入之前尾随换行。
如果用户点击EOF(*nix:Ctrl-D,Windows:Ctrl-Z+Return),则引发EOFError。
在*nix系统上,如果可用,则使用readline。我们可以使用input函数即可获取输入
 当输入后换行即可,然后函数就会返回输入的值,可以用来给变量赋值, 在input函数中还有一个参数prompt参数,用于在输如入前面添加提示,示例如下:
当输入后换行即可,然后函数就会返回输入的值,可以用来给变量赋值, 在input函数中还有一个参数prompt参数,用于在输如入前面添加提示,示例如下:
input('请输入: ')可以发现输入前多了一个提示符:请输入:
5.变量
Python变量是用于存储数据的标识符。变量可以存储各种类型的数据,例如数字、字符串、列表、字典等。在Python中,变量的定义、赋值、修改、删除等操作非常简单。
以下是Python变量的教程,包括变量的定义、赋值、修改、删除等操作:
5.1变量的定义
在Python中,可以使用任何名称来定义变量,只要满足以下条件:
- 变量名只能包含字母、数字和下划线。
- 变量名必须以字母或下划线开头。
- 变量名不能是Python关键字,如if、while、for等。
变量的定义非常简单,只需要指定变量名,然后使用等号将其赋值给一个值。例如:
x = 5
y = "Hello, world!"在上面的示例中,变量x被赋值为5,变量y被赋值为字符串"Hello, world!"。
5.2变量的赋值
可以通过简单地为变量赋值来修改变量的值。例如:
x = 5
x = 6在上面的示例中,变量x的值由5更改为6。
5.3变量的修改
Python中的变量是可变的,这意味着可以修改变量的值。例如:
x = [1, 2, 3]
x[0] = 4在上面的示例中,变量x的值由[1, 2, 3]更改为[4, 2, 3]。
5.4变量的删除
可以使用del语句删除变量。例如:
x = 5
del x在上面的示例中,变量x被删除了。
5.5变量的类型
Python中的变量不需要事先声明其类型,它们是动态类型的。这意味着变量可以在程序执行期间分配任何类型的值。可以使用type()函数获取变量的类型。例如:
x = 5
y = "Hello, world!"
print(type(x))
print(type(y))在上面的示例中,输出是:
<class 'int'>
<class 'str'>这意味着变量x是整数类型,变量y是字符串类型。
在python中有五大标准类型,如下
(1)Numbers(数字)
数字数据类型用于存储数值。他们是不可改变的数据类型,可简单分为以下四种:(注意这里十六进制,八进制都属于int整形。)
int(整型):
var = 520
print(type(var)) # <class 'int'>float(浮点型):
var = 5.20
print(type(var)) # 输出:<class 'float'>bool(布尔型):
var = True
print(type(var)) # 输出:<class 'bool'>
complex(复数):
var = complex(13,14)
print(type(var)) # 输出:<class 'complex'>
(2)String(字符串)
字符串或串是由数字、字母、下划线组成的一串字符,用‘’,“”,“‘ ’”都可表示。三者的使用可参考这篇文章: python字符串的各种表达方式.
如下方代码所示,获得的类型为str类型。另外也顺便提一个小知识点,要访问字符串可以正向访问也可以反向访问,即正向时,var[0] = ‘p’,var[1] = ‘i’,var[2] = ‘g’;而反向时,var[-1] = ‘g’,var[-2] = ‘i’,var[-3] = ‘p’。
var = “pig”
print(type(var)) # 输出:<class 'str'>
print(var[0:3]) # 正向访问,输出:'pig'
print(var[-1]) # 反向访问,输出:'g'
(3)List(列表)
列表是 Python 中使用最频繁的数据类型,用 [ ] 标识。列表可以完成大多数集合类的数据结构实现。它可以同时包含字符,数字,字符串甚至可以包含列表(即嵌套)。如下方代码所示,列表的处理方式和字符串类似。
var = [ 'pig' , 1 , 2.2 ]
print(type(var)) # 输出:<class 'list'>
print(var[0]) # 获得第一个元素,输出:'pig'
print(var+var) # 打印组合的列表,输出:[ 'pig', 1 , 2.2,'pig', 1 , 2.2 ]
(4)Tuple(元组)
元组类似于 List(列表)。元组用 () 标识。内部元素用逗号隔开。但是元组不能二次赋值,相当于只读列表。
var = ( 'pig', 1 , 2.2 )
print(type(var)) # 输出:<class 'tuple'>
print(var[0]) # 获得第一个元素,输出:'pig'
print(var+var) # 打印组合的元组,输出:( 'pig', 1 , 2.2,'pig', 1 , 2.2 )
var[0] = 'dog' # 出错!不能被二次赋值
(5)Dictionary(字典)
字典的相对于列表来说,列表是有序的对象集合,而字典是无序的对象集合。两者之间的区别在于字典当中的元素是通过键来存取的,而不是通过偏移存取。字典用"{ }"标识,字典由索引key和它对应的值value组成。
dic = {'name':'张三','age':18}
print(dic ['name']) # 得到键为'name' 的值,输出:'张三'
print(dic [age]) # 得到键为'age' 的值,输出:18
print(dic) # 得到完整的字典,输出:{'name':'张三','age':18}
print(dic.keys()) # 得到所有键,输出:dict_keys:(['name','age'])
print(dic.values()) # 输出所有值,输出:dict_values:(['张三',18])在python的五大标准类型中的后两个我们会在后面详细讲解
5.6变量的命名规范
在Python中,有一些命名规范应该遵循:
- 变量名应该是描述性的。
- 变量名应该使用小写字母和下划线。
- 变量名应该以单词之间的下划线分隔,而不是使用驼峰命名法。
- 变量名应该避免使用缩写,除非它们是广泛理解的缩写。
5.7变量的作用域
在Python中,变量的作用域指的是可以访问变量的代码块。Python中有三种类型的变量作用域:
- 局部变量:定义在函数内部,只能在函数内部访问。
- 全局变量:定义在函数外部,可以在整个程序中访问。
- 嵌套作用域变量:定义在一个函数内部的函数中,只能在这个函数内部和嵌套的函数中访问。
以下是一个使用局部变量和全局变量的示例:
python
x = 5 # 全局变量
def my_func():
x = 10 # 局部变量
print("x = ", x)
my_func()
print("x = ", x)在上面的示例中,函数my_func()中的变量x是一个局部变量。当函数被调用时,Python将在函数内部创建一个名为x的新变量,并将其值设置为10。当函数返回时,这个变量将被销毁。在函数外部,变量x仍然是全局变量,并且它的值仍然是5。
5.8变量的多重赋值
在Python中,可以使用多个变量同时赋值。例如:
x, y = 1, 2在上面的示例中,变量x被赋值为1,变量y被赋值为2。这与以下代码
的效果是一样的:
x = 1
y = 2可以在多个变量之间交换它们的值。例如:
x, y = y, x在上面的示例中,变量x和变量y的值被交换了。
5.9变量的命名约定
在Python中,有一些命名约定应该遵循:
- 变量名应该尽量短,但仍然保持描述性。
- 变量名应该使用小写字母和下划线。
- 变量名应该以单词之间的下划线分隔,而不是使用驼峰命名法。
- 变量名应该避免使用单个字符,除非它们是循环计数器或其他简单用途的变量。
- 变量名应该避免使用Python内置函数和关键字的名称。
例如,下面是一些良好的变量名:
name = "John"
age = 30
is_valid = True而下面是一些不好的变量名:
n = "John" # 变量名过短,缺少描述性
a = 30 # 变量名过短,缺少描述性
valid = 1 # 变量名不够描述性
if = True # 变量名使用了Python关键字5.10变量的存储
在高级语言中,变量是对内存及其地址的抽象。
对于python而言,python的一切变量都是对象,变量的存储,采用了引用语义的方式,存储的只是一个变量的值所在的内存地址,而不是这个变量的只本身。
引用语义:在python中,变量保存的是对象(值)的引用,我们称为引用语义。采用这种方式,变量所需的存储空间大小一致,因为变量只是保存了一个引用。也被称为对象语义和指针语义。
值语义:有些语言采用的不是这种方式,它们把变量的值直接保存在变量的存储区里,这种方式被我们称为值语义,例如C语言,采用这种存储方式,每一个变量在内存中所占的空间就要根据变量实际的大小而定,无法固定下来。
由于python中的变量都是采用的引用语义,数据结构可以包含基础数据类型,导致了在python中每个变量中都存储了这个变量的地址,而不是值本身;
对于复杂的数据结构来说,里面的存储的也只只是每个元素的地址而已
抽象的来说变量不是一个存储这数字的盒子,而是在数据上贴上了变量的标签。
5.10.1 id函数
id函数获取变量数据的地址:
x = 3.14
print(id(x))
我们可以通过id函数来验证变量是如何存储的
5.10.2变量存储

我们可以看到变量只是存储了一个引用而已
6.python列表
6.1创建列表
在python中创建列表有两种方式
#第一种方式,直接创建, 用方括号括起来,元素用逗号隔开
l1 = [] #创建一个空列表
l2 = [666, '1024程序员节', True] #创建一个包含3个元素的列表
l3 = [[1, 2, 3]] #创建一个包含一个列表的列表
#第二种方式,使用内置函数 list()
l4 = list() #创建一个空列表
l5 = list([1, 2, 3]) #创建一个包含3个元素的列表在选择列表创建方式时可以自行选择
6.2访问列表元素
使用下标索引来访问列表中的值,同样你也可以使用方括号的形式截取字符,如下所示
list1 = ['physics', 'chemistry', 1997, 2000]
list2 = [1, 2, 3, 4, 5, 6, 7 ]
print("list1[0]: ", list1[0])
print("list2[1:5]: ", list2[1:5])
上面代码的输出是
list1[0]: physics
list2[1:5]: [2, 3, 4, 5]6.3列表添加
在python中,给列表添加函数可以使用内置函数 append() 来添加列表函数。可以用于在列表末尾添加元素。
l1 = [1]
l1.append(2) #在列表末尾添加元素 2,l1现在是[1, 2]。如果在指定位置添加函数可以使用内置函数 insert(index, value)
l1 = [1, 2, 3]
l1.insert(1, 0) #l1现在是[1, 0, 2, 3]6.4 元素修改
l1 = [1, 2, 3]
l1[0] = 3
l1[2] = 1 #现在列表里是 [3, 2, 1]6.5列表操作函数

7.python字典
字典(Dictionary)是Python提供的一种常用的数据结构,由键(key)和值(value)成对组成,键和值中间以冒号:隔开,项之间用逗号隔开,整个字典由大括号{}括起来。
格式如下:
dic = {key1 : value1, key2 : value2 }7.1创建字典
字典也被称作关联数组或哈希表。下面是几种常见的字典创建方式:
# 方法1
dic1 = { 'Author' : 'Python当打之年' , 'age' : 99 , 'sex' : '男' }
# 方法2
lst = [('Author', 'Python当打之年'), ('age', 99), ('sex', '男')]
dic2 = dict(lst)
# 方法3
dic3 = dict( Author = 'Python当打之年', age = 99, sex = '男')
# 方法4
list1 = ['Author', 'age', 'sex']
list2 = ['Python当打之年', 99, '男']
dic4 = dict(zip(list1, list2))字典创建的方式还有很多种,这里不再赘述。
字典由 dict 类代表,可以使用dir(dict)来查看该类包含哪些方法,输入命令,可以看到如下输出结果:
methods = dir(dict)
print('methods = ',methods)
methods = ['__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'clear', 'copy', 'fromkeys', 'get', 'items', 'keys', 'pop', 'popitem', 'setdefault', 'update', 'values']7.2字典操作
字典的方法和属性有很多种,这里我们重点介绍以下11种方法:
['clear', 'copy', 'fromkeys', 'get', 'items', 'keys', 'pop', 'popitem', 'setdefault', 'update', 'values']1、dict.clear()
clear() 用于清空字典中所有元素(键-值对),对一个字典执行 clear() 方法之后,该字典就会变成一个空字典。
list1 = ['Author', 'age', 'sex']
list2 = ['Python当打之年', 99, '男']
dic1 = dict(zip(list1, list2))
# dic1 = {'Author': 'Python当打之年', 'age': 99, 'sex': '男'}
dic1.clear()
# dic1 = {}2、dict.copy()
copy() 用于返回一个字典的浅拷贝。
list1 = ['Author', 'age', 'sex']
list2 = ['Python当打之年', 99, '男']
dic1 = dict(zip(list1, list2))
dic2 = dic1 # 浅拷贝: 引用对象
dic3 = dic1.copy() # 浅拷贝:深拷贝父对象(一级目录),子对象(二级目录)不拷贝,还是引用
dic1['age'] = 18
# dic1 = {'Author': 'Python当打之年', 'age': 18, 'sex': '男'}
# dic2 = {'Author': 'Python当打之年', 'age': 18, 'sex': '男'}
# dic3 = {'Author': 'Python当打之年', 'age': 99, 'sex': '男'}其中 dic2 是 dic1 的引用,所以输出结果是一致的,dic3 父对象进行了深拷贝,不会随dic1 修改而修改,子对象是浅拷贝所以随 dic1 的修改而修改,注意父子关系。
拓展深拷贝:copy.deepcopy()
import copy
list1 = ['Author', 'age', 'sex']
list2 = ['Python当打之年', [18,99], '男']
dic1 = dict(zip(list1, list2))
dic2 = dic1
dic3 = dic1.copy()
dic4 = copy.deepcopy(dic1)
dic1['age'].remove(18)
dic1['age'] = 20
# dic1 = {'Author': 'Python当打之年', 'age': 20, 'sex': '男'}
# dic2 = {'Author': 'Python当打之年', 'age': 20, 'sex': '男'}
# dic3 = {'Author': 'Python当打之年', 'age': [99], 'sex': '男'}
# dic4 = {'Author': 'Python当打之年', 'age': [18, 99], 'sex': '男'}dic2 是 dic1 的引用,所以输出结果是一致的;dic3 父对象进行了深拷贝,不会随dic1 修改而修改,子对象是浅拷贝所以随 dic1 的修改而修改;dic4 进行了深拷贝,递归拷贝所有数据,相当于完全在另外内存中新建原字典,所以修改dic1不会影响dic4的数据
3、dict.fromkeys()
fromkeys() 使用给定的多个键创建一个新字典,值默认都是 None,也可以传入一个参数作为默认的值。
list1 = ['Author', 'age', 'sex']
dic1 = dict.fromkeys(list1)
dic2 = dict.fromkeys(list1, 'Python当打之年')
# dic1 = {'Author': None, 'age': None, 'sex': None}
# dic2 = {'Author': 'Python当打之年', 'age': 'Python当打之年', 'sex': 'Python当打之年'}4、dict.get()
get() 用于返回指定键的值,也就是根据键来获取值,在键不存在的情况下,返回 None,也可以指定返回值。
list1 = ['Author', 'age', 'sex']
list2 = ['Python当打之年', [18,99], '男']
dic1 = dict(zip(list1, list2))
Author = dic1.get('Author')
# Author = Python当打之年
phone = dic1.get('phone')
# phone = None
phone = dic1.get('phone','12345678')
# phone = 123456785、dict.items()
items() 获取字典中的所有键-值对,一般情况下可以将结果转化为列表再进行后续处理。
list1 = ['Author', 'age', 'sex']
list2 = ['Python当打之年', [18,99], '男']
dic1 = dict(zip(list1, list2))
items = dic1.items()
print('items = ', items)
print(type(items))
print('items = ', list(items))
# items = dict_items([('Author', 'Python当打之年'), ('age', [18, 99]), ('sex', '男')])
# <class 'dict_items'>
# items = [('Author', 'Python当打之年'), ('age', [18, 99]), ('sex', '男')]6、dict.keys()
keys() 返回一个字典所有的键。
list1 = ['Author', 'age', 'sex']
list2 = ['Python当打之年', [18,99], '男']
dic1 = dict(zip(list1, list2))
keys = dic1.keys()
print('keys = ', keys)
print(type(keys))
print('keys = ', list(keys))
# keys = dict_keys(['Author', 'age', 'sex'])
# <class 'dict_keys'>
# keys = ['Author', 'age', 'sex']7、dict.pop()
pop() 返回指定键对应的值,并在原字典中删除这个键-值对。
list1 = ['Author', 'age', 'sex']
list2 = ['Python当打之年', [18,99], '男']
dic1 = dict(zip(list1, list2))
sex = dic1.pop('sex')
print('sex = ', sex)
print('dic1 = ',dic1)
# sex = 男
# dic1 = {'Author': 'Python当打之年', 'age': [18, 99]}8、dict.popitem()
popitem() 删除字典中的最后一对键和值。
list1 = ['Author', 'age', 'sex']
list2 = ['Python当打之年', [18,99], '男']
dic1 = dict(zip(list1, list2))
dic1.popitem()
print('dic1 = ',dic1)
# dic1 = {'Author': 'Python当打之年', 'age': [18, 99]}9、dict.setdefault()
setdefault() 和 get() 类似, 但如果键不存在于字典中,将会添加键并将值设为default。
list1 = ['Author', 'age', 'sex']
list2 = ['Python当打之年', [18,99], '男']
dic1 = dict(zip(list1, list2))
dic1.setdefault('Author', '当打之年')
print('dic1 = ',dic1)
# dic1 = {'Author': 'Python当打之年', 'age': [18, 99], 'sex': '男'}
dic1.setdefault('name', '当打之年')
print('dic1 = ',dic1)
# dic1 = {'Author': 'Python当打之年', 'age': [18, 99], 'sex': '男', 'name': '当打之年'}10、dict.update(dict1)
update() 字典更新,将字典dict1的键-值对更新到dict里,如果被更新的字典中己包含对应的键-值对,那么原键-值对会被覆盖,如果被更新的字典中不包含对应的键-值对,则添加该键-值对。
list1 = ['Author', 'age', 'sex']
list2 = ['Python当打之年', [18,99], '男']
dic1 = dict(zip(list1, list2))
print('dic1 = ',dic1)
# dic1 = {'Author': 'Python当打之年', 'age': [18, 99], 'sex': '男'}
list3 = ['Author', 'phone' ]
list4 = ['当打之年', 12345678]
dic2 = dict(zip(list3, list4))
print('dic2 = ',dic2)
# dic2 = {'Author': '当打之年', 'phone': 12345678}
dic1.update(dic2)
print('dic1 = ',dic1)
# dic1 = {'Author': '当打之年', 'age': [18, 99], 'sex': '男', 'phone': 12345678}11、dict.values()
values() 返回一个字典所有的值。
list1 = ['Author', 'age', 'sex']
list2 = ['Python当打之年', [18,99], '男']
dic1 = dict(zip(list1, list2))
values = dic1.values()
print('values = ', values)
print(type(values))
print('values = ', list(values))
# values = dict_values(['Python当打之年', [18, 99], '男'])
# <class 'dict_values'>
# values = ['Python当打之年', [18, 99], '男']8.python元组
python元组和列表十分相似,只是创建方式有所不同。所以我只重点讲述元组的创建,其他不在讲解。
tuple1 = 1, 2, 3
tuple2 = (1, 2, 3)9.Python条件判断
什么是条件判断?
即根据条件,判断真假,其条件要么为真,要么为假,就好比抛硬币,落地要么是正面,要么是反面。
下面给出一张在过年期间经常发生的命案,来带大家了解判断(图片来源于网络)

![]()
9.1 if判断
在python中一般使用if语句来实现条件判断
if 条件表达式:
如果为真这执行我给出一个判断是否是否成年的示例
age = 18
if age >= 18:
print('成年')
if age < 18:
print('未成年')9.1 if .. else...
if... else...语句的一般结构如下
if 条件表达式:
为真代码
else:
上面的条件表达式不为真执行我们可以通过 if...else语句来改善上面的示例
age = 18
if age >= 18:
print('成年')
else:
print('未成年')9.2 if...elif....else...
if...elif..else语句的一般结构如下
if 条件表达式1:
...
elif 条件表达式2: # elif 可以无限叠加
...
elif 条件表达式3:
...
else:
...同样这个表达语句也可以帮助我们改进上面的示例
age = 18
if age >= 18:
print('成年')
elif age < 18:
print('未成年')
else:
print('未知年龄')
9.3 三元表达式
什么是三元运算符
在大部分编程语言中都有三目运算,也称三元运算,Python语言从Python2.5版本开始也引入了三元运算符。
在Python中,三元运算也称为条件表达式,语法如下:
true_expression if condition else false_expression
condition是判断条件,true_expression 和 false_expression 是两个表达式,用 if...else... 连接。
如果 condition 成立(结果为真),就执行 true_expression,并把 true_expression 的结果作为整个表达式的结果。
如果 condition 不成立(结果为假),就执行 false_expression,并把 false_expression 的结果作为整个表达式的结果。
Python中的三元运算符是用 if 和 else 连接,不像Java等语言中是用问号和冒号连接。
例如:
num1 = int(input('请输入第一个数字:'))
num2 = int(input('请输入第二个数字:'))
# 三元运算
max_num = num1 if num1 >= num2 else num2
print(f'最大值是:{max_num}')Output:
请输入第一个数字:15646
请输入第二个数字:464665
最大值是:464665上面的示例中,如果 num1 大于或等于 num2,则 max_num 等于 num1,否则 max_num 等于 num2,通过三元运算符求出了两个数字中的最大值。
三元运算语句与条件语句的区别
1.三元运算语句
numa = 100
numb = 10
max_num = numa if numa >= numb else numb
print(f'最大值是:{max_num}')2.条件语句
numa = 100
numb = 10
if numa >= numb:
max_num = numa
else:
max_num = numb
print(f'最大值是:{max_num}')从上面的对比,三元运算语句和条件语句实现的功能完全一样,但三元运算语句只需要一行代码,而条件语句有四行代码。三元运算语句代码少且可读性更高,所以大部分情况下,可以说三元运算语句是条件语句的简写。
嵌套的三元运算表达式
num = int(input('请输入数字:'))
print('负数') if str(num)[0] == '-' else print('大于等于100') if num >= 100 else print('小于100的正数')上面这行代码是一个嵌套的三元运算表达式,其中第一个 else 后面的语句是一个完整的三元运算语句,被作为一个整体当作外层三元运算表达式中的 false_expression ,如下图所示。

这个表达式相当于下面的条件判断代码:
num = int(input('请输入数字:'))
if str(num)[0] == '-':
print('负数')
else:
if num >= 100:
print('大于等于100')
else:
print('小于100的正数')还可以继续用相同的方法嵌套更多层,不过个人建议不要写太多嵌套,否则代码可读性不增反降,适得其反。
三元运算表达式与列表推导式组合
s = [i if i % 2 == 0 else 10*i for i in range(10)]
print(s)Output:
[0, 10, 2, 30, 4, 50, 6, 70, 8, 90]三元运算表达式还经常与列表推导式结合使用,这两种方式结合,是Python中两个高级的特性强强联合,写出来的代码非常优雅。
当然,还可以举一反三地将三元运算表达式与字典推导式和集合推导式等组合使用,更多推导式可以参考:Python列表推导式
三元运算表达式的优点
Python中的三元运算表达式主要有两个优点:
1.可以用单行的三元运算表达式替换简单的条件语句,减少代码行数。
2.简单的三元运算表达式可以提高代码的可读性,使代码更Pythonic,更优雅。
9.4 表达式的比较符号
| 符号 | 含义 |
| == | 等于 |
| != | 不等于 |
| < | 小于 |
| > | 大于 |
| <= | 小于等于 |
| >= | 大于等于 |
| is | 判断地址是否相同 |
除了上面的一些表达符号,还有一些特别的关键字
| 关键字 | 意义 |
| and | and前后的表达式都为真才返回真,否则返回假 |
| or | or前后的表达是只要有一个为真就返回真 |
10.猜数字游戏
在经过一段时间的学习,我们是时候来一个小试牛刀了。
这里我选择了一个简单的入门案例,猜数字游戏
num = 66
guess = int(input('请输入你猜的数字'))
if guess == num:
print('你猜对了')
elif guess < num:
print('你猜小了')
else:
print('你猜大了')
在这个示例里我们先定义了num变量,并将数字 66 存入变量中作为答案
接着我们使用input函数让玩家输入猜的数字,并使用int函数把输入的类型转换为int类型,最后传入变量guess里
然后就会对guess进行判断。
我推荐大家都敲一敲。
这样我们做的第一个游戏就出来了,不过大家试玩就会发现这个游戏只能猜一次,而且答案也是实先定义好大。不过我们会在后面慢慢改进。
11.python循环
11.1 while循环
while循环用于重复执行代码,下面是一张while的语句(图片来源于网络)
Python 编程中 while 语句用于循环执行程序,即在某条件下,循环执行某段程序,以处理需要重复处理的相同任务。其基本形式为:
while 条件表达式:
代码块执行语句可以是单个语句或语句块。判断条件可以是任何表达式,任何非零、或非空(null)的值均为true。
当判断条件假 false 时,循环结束。
执行流程图如下(来源于网络):

Gif 演示 Python while 语句执行过程

复杂一点:

这里给出一个示例
count = 0
while count < 10:
print("Hello while")
count += 1可以看到屏幕上重复打印了10次“Hello while”
注意:在 python 中,while … else 在循环条件为 false 时执行 else 语句块
11.2 for循环
在python中for循环可以用来遍历任何序列项目
for循环的基本结构如下
for 变量名 in 遍历对象:
...流程图(来源于网络)

还记得上面的while示例吗?打印十个使用for循环也可以
for i in range(10):
print('Hello for')其中的range函数可以用来创建序列对象,python对其的解释是

参考翻译:
关于模块内置类范围的帮助:
类范围(对象)
|范围(停止)->范围对象
|range(start,stop[,step])->range对象
|
|返回一个对象,该对象从开始(包括开始)生成一系列整数
|逐步停止(排他)。范围(i,j)产生i,i+1,i+2。。。,j-1。
|start默认为0,省略stop!范围(4)产生0、1、2、3。
|这些正是4个元素列表的有效索引。
|当给出步长时,它指定增量(或减量)。
|
|此处定义的方法:
|
|__bool__(self,/)
|如果self-else则为True False
|
|__contains__(self,key,/)
|自行返回钥匙。
|
|__eq__(self、value、/)
|返回self-==值。
|
|__ge__(自我、价值、/)
|返回self>=值。
|
|__getattribute__(自我、姓名、/)
|返回getattr(self,name)。
11.3 break和continue
Python break语句,就像在C语言中,打破了最小封闭for或while循环。
break语句用来终止循环语句,即循环条件没有False条件或者序列还没被完全递归完,也会停止执行循环语句。
break语句用在while和for循环中。
如果您使用嵌套循环,break语句将停止执行最深层的循环,并开始执行下一行代码。
Python语言 break 语句语法:
break流程图:
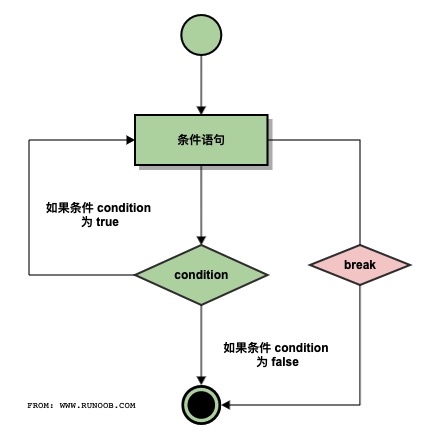
Python continue 语句跳出本次循环,而break跳出整个循环。
continue 语句用来告诉Python跳过当前循环的剩余语句,然后继续进行下一轮循环。
continue语句用在while和for循环中。
Python 语言 continue 语句语法格式如下:
continue
流程图:

12.猜数字游戏完善
我们在学习完python的循环是大家肯定一经想到这么改进了。
这里给出我个人的改进方案
import random
ran = random.randint(1, 100) # python内置库random的randint函数可以生成a~b之间的随机整数
while True:
guess = int(input('请输入1~100的整数: ')
if guess == ran:
print('猜对了')
break # 猜对了就退出循环
elif guess < ran:
print('猜小了')
else:
print('猜大了')这里就不做更多解释了。恭喜大家,完成了第一个游戏!
13.Python注释
不要问我为什么这么晚才讲注释,问就是忘了。
注释有助于提高代码可读性
13.1单行注释
在python中单行注释使用的是#号
#这是注释
a = "#"
print(a) # Ouput:#13.2多行注释
在python中多行注释用"""括起来即可
""" 这是注释 """
s = """
1024
程序员节
""" #这样没有问题14.python导入
python导入有助于提高代码可读性,较大的代码分成多个文件可读性就提高了
14.1 import导入
导入import的一般格式如下
import 库名import会在当前路径和python内置库里搜索文件及第三方库里,如果有即可通过以下方法调用
import 库名
库名.变量或函数、类在导入多个内置库时可以使用
import 库1, 库2这样虽然减少了代码量,但是python不建议这样导入。在python中导入多个库最好是一个一个导入,如:
import 库1
import 库214.2 import...as ...
这样的导入方式是为了避免库名过长而出现的,相对于给库取了一个小名
import 库名 as 小名
小名.元素14.3 from ... improt ...
使用这个方法可以只在库里导入一个函数或多个函数
form 库1 import 函数1
from 库2 import 函数1, 类1
from 库3 import * # 在库3里导入所有元素15.函数
1. 什么是python函数以及定义一个函数
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。你已经知道Python提供了许多内建函数,比如print()。但你也可以自己创建函数,这被叫做用户自定义函数。
# 函数
def function(param):
pass
return 'this is function'
result = function('param')
print(result)2. 函数使用
参数说明:参数 函数里面参数:行参 调用函数里面参数:实参
函数返回多个结果,优雅的接受参数
# 函数返回多个结果,优雅的接受参数
def function1(param1, param2):
param1 = param1 * 3
param2 = param2 * 2 + 20
return param1, param2
param1, param2 = function1(2, 3)
print(param1)
print(param2)指定参数(无参、必须参数、指定实参、默认参数、可变参数)
# 无参
def function1():
print(' 没有参数 ')
print('无参无return返回结果:' ,function1())
# 指定实参
param1,param2 = function1(param2 = 4, param1 = 2)
print(param1, param2)
# 行参默认值
# 行参顺序:默认参数在后
def function1(param1=4, param2=4):
param1 = param1 * 3
param2 = param2 * 2 + 20
return param1, param2
param1,param2 = function1()
print(param1, param2)
# 可变参数
def function2(*param):
print(param)
# 没有*输出结果:((1, 2, 3),)
function2((1,2,3))
function2(*(1,2,3))
# 关键字可变参数
def function3(**param):
# 返回结果:{'x': 1, 'y': 2, 'z': 3}
print(param)
# dict
print(type(param))
function3(x=1, y=2, z=3)
# 什么都不传返回 {}
function3()这里需避坑
# 避坑 必须参数 > 可变参数 > 默认参数
def function3(param1, *param3, param2=2):
print('必须参数:', param1)
print('可变参数:', param3)
print('默认参数:', param2)
# param1 = str,param3 = 1,2,3,param2 = param
function3('str', 1, 2, 3, 'param')
# 输出结果:必须参数: str ,可变参数: (1, 2, 3, 'param') ,默认参数: 2 不符合预期
function3('str', 1, 2, 3, param2='param')3、Python 函数式编程
函数本身可以赋值给变量(即变量可以指向函数)。而其实函数名本身就是指向函数的变量。
一个函数可以接受另一个函数作为参数。这种函数称为高阶函数,例如以下几个例子:
3.1 lambda 表达式 - 匿名函数
# 匿名函数
function = lambda x, y: x + y
print(function(1,2))3.2 map与lambda
map函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
# map 使用
# 求arr每个元素平方
arr = [1, 2, 3, 4, 5, 6, 7, 8]
def square(x):
return x * x
result = map(square, arr)
print(list(result))
# lambda 与 map 一起使用
result1 = map(lambda x: x * x, arr)
print(list(result1))
# lambda 与 map 一起使用 多个参数; 如果arr与arr1个数不同,只计算到最少个数,如下arr1个数比arr少 只会返回 5个元素,反之 arr个数比arr1少 只会计算到arr个数位
arr1 = [1, 2, 3, 4, 5, 6]
result2 = map(lambda x, y: x * x + y, arr, arr1)
print(list(result2))列表推倒式,适用于:list、dict、tuple、set
# 列表推导式 - list
arr = [1, 2, 3, 4, 5, 6, 7, 8]
result = [x * x for x in arr]
print(result)
# 添加条件判断(x指下标)
result1 = [x * x for x in arr if x >=4]
print(result1)
# 列表推导式 - dict
sex = {
0 : '男',
1 : '女',
2 : '中性'
}
result2 = {value:key for key,value in sex.items()}
print(result2)3.3 reduce 连续计算数据
使用reduce 引入functools库
from functools import reduce
# reduce 使用:必须有两个参数
# reduce 作用:连续的计算,只会得到一个结果
arr = [1, 2, 3, 4, 5, 6, 7, 8]
result = reduce(lambda x, y: x + y, arr)
# 计算如下:((((1 + 2) + 3) + 4) + 5)... + 6 + 7 + 8
print(result)
# reduce 第三个参数,起始值
result1 = reduce(lambda x, y: x + y, arr, 14)
# 计算如下:14 +((((1 + 2) + 3) + 4) + 5)... + 6 + 7 + 8
print(result1)3.4 filter 过滤数据
和map()类似,filter()也接收一个函数和一个序列。和map()不同的时,filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
# filter 使用 第一参数必须返回bool
arr = [1, 0, 0, 1, 1, 4, 0, 5]
result = filter(lambda x:True if x==1 else False, arr)
print(list(result))3.5. 装饰器
装饰器本质是一个Python函数,它可以让其它函数在没有任何代码变动的情况下增加额外功能。有了装饰器,我们可以抽离出大量和函数功能本身无关的雷同代码并继续重用。经常用于具有切面需求的场景:包括插入日志、性能测试、事务处理、缓存和权限校验等
# 装饰器
# func指函数
def decorator(func):
def wrapper(*args, **kwargs):
# 执行函数内部逻辑 打印时间
print(time.time(), args, kwargs)
# 执行调用函数中逻辑 打印不同参数
func(*args, **kwargs)
return wrapper
# 一个参数
@decorator
def function(param):
print('function : this is decorator ' + param)
# 两个参数
@decorator
def function1(param1, param2):
print('function1 : this is decorator ' + param1)
print('function1 : this is decorator ' + param2)
# 三个参数(可变参数)
@decorator
def function2(param1, param2, **kwargs):
print('function2 : this is decorator ' + param1)
print('function2 : this is decorator ' + param2)
print(kwargs)
function('param')
function1('param1' , 'param2')
function2('param1' , 'param2', x=1,y=2,z=3)16.python类
很多初学的小伙伴们,在学到“类”的时候,就开始烦迷糊了。“类”到底是个什么东西,是用来干嘛的?然后就疯狂百度搜索,搜出了很多。一看回答,很多都是在扯什么面向对象,还讲了一堆稀奇古怪的概念,看了反而更迷糊了。。
所以,我这篇文章,就是要带大家,用最简单、通俗、暴力的方式理解什么是类,类能干什么,怎么使用。
首先,我们要明白,既然python的作者设计了“类”这个东西,那肯定是在编程的时候有这种需求的。那我们什么时候需要用到类呢?当然,可以用到类的地方有很多很多。但如果大家还没有太多的代码经验,我就直接告诉你们答案了:如果多个函数需要反复使用同一组数据,使用类来处理,会很方便。
举个大家在中学都接触过的例子:解三角形。
我需要做一个模块,实现以下功能:输入三角形的三条边长a,b,c,然后计算并返回该三角形三个角的角度,以及该三角形的面积、周长。
你会说,这很简单啊,我们一般就这么做就行了,假如输入三角形的边长为6,7,8:
def ...: # 参照公式把五个函数定义出来,就不详细写了
...
def ...:
...
# 然后调用定义好的函数,传入边长数据
angleA(6,7,8) # 计算角A
->0.8127555613686607 # 注意返回值为弧度
angleB(6,7,8) # 计算角B
->1.0107210205683146
angleC(6,7,8) # 计算角C
->1.318116071652818
square(6,7,8) # 计算面积
->20.33316256758894
circle(6,7,7) # 计算周长,额,好像有个数字写错了
->20 # 计算结果当然也就错了这不就搞定了嘛,把计算需要用到的五个函数依次定义出来,然后调就好了。但大家仔细观察一下,这样写有什么不太好的地方?相信大家都发现了,这是同一个三角形,每次计算角度、面积、周长的时候,都要把三条边的长度传进去,一方面这很麻烦,另一方面,万一有一个不小心写错了,那么那条结果当然也就错了啊。
我们根据三角形全等的条件可以知道,三角形的三条边确定了,那么它的三个角、面积、周长,也就都确定了。所以对于同一个三角形,最好只需要传一次数据就可以了。
这不也简单嘛,把它们都写在一个函数里不就得了:
def calculate(a,b,c):
angleA = ...
angleB = ...
angleC = ...
square = ...
circle = ...
return {'角A':angleA, '角B':angleB, '角C':angleC, '面积':square, '周长':circle}
result=calculate(6,7,8)
result['角A']
->0.8127555613686607
result['面积']
->20.33316256758894好了,这不又搞定了,看起来没什么问题了吧。看起来当然没有问题了,但大家再仔细想一想,假如我只需要计算“角A”和“面积”,用上面的方法,也只返回了这两个结果,但实际上,那个函数在执行的时候,实际上把五个值都求了一遍。数量少还好,但数量多起来,效率肯定就要大受影响了。
这怎么办呢?聪明的你可能又想到了,在函数里加入第四个参数d,用来标记需要计算哪个,然后函数中插入if语句判断……
得,代码我也不想写了,原来很清晰的逻辑,非得糟蹋成这样。。
这又要使用简便,又要效率高,还要逻辑清晰,这可怎么办呢?我们了想又想,认为函数还是要分开来写的。但我们脑洞一下,最好有一个“大的东西”叫“三角形生成器”,把这些函数包括进来。使用的时候参数直接传给三角形生成器,然后三角形生成器会根据传入的边长生成一个个具体的三角形,生成的三角形除了具有输入进来的边长数据外,还可以自己计算自己的三个角、面积、周长。也就是,我们希望能够实现以下的效果:
# 定义一个“大的东西”,名字就叫triangle
...
...
# 一番神奇的操作,然后
tr1=triangle(6,7,8) # 把三条边长传给这个大的东西,然后就生成一个三角形赋给tr1在这行代码里,我们把边长数值传给了“三角形生成器”triangle(),生成了一个三角形,然后赋值给变量tr1。此时的tr1,就代表着边长为6,7,8的具体三角形。
然后,我们可以很方便地查看这个三角形三边的边长(也就是刚才传进来的数据):
tr1.a
->6
tr1.b
->7
tr1.c
->8计算并查看三个角的角度:
tr1.angleA()
->0.8127555613686607
tr1.angleB()
->1.0107210205683146
tr1.angleC()
->1.318116071652818计算并查看它的面积与周长:
tr1.square()
->20.33316256758894
tr1.circle()
->21又来了一个边长为8,9,10的三角形:
tr2=triangle(8,9,10) # 生成另外一个三角形计算这两个三角形的面积差:
tr2.square()-tr1.square() # tr2是新生成的三角形,原来的tr1还在呢没删掉
->13.863876777945055这种想法很大胆是不是?可应该怎么实现呢?这就要用到类了。
可大家在反思一下,这种想法真的很smart吗?在python中,万物皆对象,我们操作字符串、列表、字典、文件IO等内置对象的时候,用的方法,看起来不是一模一样吗。。只不过那个“三角形”是我们自创的而已。讲到这里,你也许已经明白了,类,其实就是提供了自定义对象的能力。
好了,不多讲了,我们把上面那个“一番神奇的操作”展开看看吧。
import math # 计算反三角函数要用到
class triangle: # 定义类:三角形生成器
def __init__(self,a,b,c): # 成员函数,声明需要与外部交互的参数(类的属性)
self.a=a # 先看着
self.b=b # 这几个东西是干嘛的后面会讲
self.c=c
def angleA(self): # 计算函数(类的方法)
agA=math.acos((self.b**2+self.c**2-self.a**2)/(2*self.b*self.c))
return agA
def angleB(self): # 公式看不懂的回去翻课本去
agB=math.acos((self.c**2+self.a**2-self.b**2)/(2*self.a*self.c))
return agB
def angleC(self):
agC=math.acos((self.a**2+self.b**2-self.c**2)/(2*self.a*self.b))
return agC
def square(self):
p=(self.a+self.b+self.c)/2
s=math.sqrt(p*(p-self.a)*(p-self.b)*(p-self.c))
return s
def circle(self):
cz=self.a+self.b+self.c
return cz其实也简单,就是先声明包含的参数,然后再写包含的函数就行了。具体的写法规则很多文档都有介绍,我就不多讲了。
用的时候也简单,既然类是自定级对象的规则,那我们就先传入数据,根据规则生成具体的对象(称之为实例化):
tr1=triangle(6,7,8)像这个,就是根据三角形的生成规则,传入的三条边长,生成的具体三角形,然后那些边长啊、角度啊、面积啊才会有意义。
print(tr1.a)
print(tr1.b)
print(tr1.c)
print(tr1.angleA())
print(tr1.angleB())
print(tr1.angleC())
print(tr1.square())
print(tr1.circle())
->
6
7
8
0.8127555613686607
1.0107210205683146
1.318116071652818
20.33316256758894
21总结一下,所有的对象,不管是python内置的,还是import第三方包里面的,还是我们自己用类定义然后实例化的,观察总结一下,可以发现,它们都是由两部分组成,一部分是像a、b、c这样的数据,它们决定这个对象是什么,另一部分是像angleA()、angleB()、angleC()这样的函数,他们用来表示用这些数据做什么。在面向对象的编程中,一个对象的数据,称之为对象的属性,一个对象拥有的函数,称之为对象的方法。大家可能经常听说这两个名词,哪怕是其他的编程语言,面向对象作为一种思想,都是相通的。
然后大家可能还有几个问题:
第一个函数def __init()__是干什么的?
顾名思义,init是初始化的意思,init函数,也就是初始化函数,意思就是,当实例化类的时候,自动运行的函数,如果我们实例化的时候给类传了参数,参数也是呈交给这个函数来处理的。所以,你可以在init函数里写上任何你希望实例化的时候就自动执行的函数,比如像print('实例化已完成')什么的都是可以的。
但大部分时候,我们希望实例化的时候干些啥?当然是把数据传给类的属性啊,所以绝大部分情况下,init函数都充当了构造函数的作用,我们可以在这里面写明把传来的数据赋予谁,或经过怎样的预处理后再赋予谁。
就拿那个三角形来说,我们希望在生成三角形(实例化)的时候,就给三角形生成器(类)传入三条边长,而不是实例化完了之后,再tr1.a=6,tr1.b=7这样的一个个赋值。所以我们直接就在init函数里写明了参数的传递规则。
另外再说一句,在传入参数实例化后,除了可以查看,也是可以再次修改的:
tr1.a
->6
tr1.a=7
tr1.a
->7那个self是什么东西,为什么要写self.a?
我们在使用对象的属性的时候,写法是“对象名.属性名”,就像上面的tr1.a。在定义类的时候,为了保持一致,也要采用这种写法。但由于类定义的时候,还没有实例化,并不清楚对象名是什么,所以可以随便写一个(但要前后一致),一般都写self。
17.罚点球游戏
我们直接上代码
from random import choice
class PenaltyShootout:
score = [0, 0]
rest = [5, 5]
direction = ['左', '中', '右']
def kick(self):
print('==== 玩家罚球 ====')
you = input('选择你要踢的方向:(左、中、右)')
print('你踢向了' + you)
com = choice(self.direction)
print('电脑扑向了' + com)
if you != com:
print('进球得分!')
self.score[0] += 1
else:
print('被扑出去了...')
print('比分: %d(you) - %d(com)\n' % (self.score[0], self.score[1]))
if self.rest[0] > 0:
self.rest[0] -= 1
if self.score[0] < self.score[1] and self.score[0] + self.rest[0] < self.score[1]:
return True
if self.score[1] < self.score[0] and self.score[1] + self.rest[1] < self.score[0]:
return True
print('==== 玩家扑救! ====')
you = input('选择你要扑的方向:(左、中、右)')
print('你扑向了' + you)
com = choice(self.direction)
print('电脑踢向了' + com)
if you == com:
print('扑出去了!')
else:
print('丢球了...')
self.score[1] += 1
print('比分: %d(you) - %d(com)\n' % (self.score[0], self.score[1]))
if self.rest[1] > 0:
self.rest[1] -= 1
if self.score[0] < self.score[1] and self.score[0] + self.rest[0] < self.score[1]:
return True
if self.score[1] < self.score[0] and self.score[1] + self.rest[1] < self.score[0]:
return True
return False
def play(self):
i = 0
end = False
while i < 5 and not end:
print('==== 第 %d 轮 ====' % (i + 1))
end = self.kick()
i += 1
while self.score[0] == self.score[1]:
i += 1
print('==== 第 %d 轮 ====' % (i + 1))
self.kick()
if self.score[0] > self.score[1]:
print('玩家获胜!')
else:
print('玩家落败.')
PenaltyShootout = PenaltyShootout()
PenaltyShootout.play()可以看到这段代码用到了我们刚刚学习的函数和类,代码我不需要做过多的解释,相信搭建已经明白了逻辑。

18.接下来干嘛
我们经过了一段时间的学习也是正式踏入了编程世界的大门,对于接下来学习的都是拓展了,本篇讲到已经结束了。
网络爬虫
~~未完待续~~
游戏开发
pygame_小Y的编程课堂的博客-CSDN博客![]() https://blog.csdn.net/m0_73552311/category_12139557.html?spm=1001.2014.3001.5482cocos2d_小Y的编程课堂的博客-CSDN博客
https://blog.csdn.net/m0_73552311/category_12139557.html?spm=1001.2014.3001.5482cocos2d_小Y的编程课堂的博客-CSDN博客![]() https://blog.csdn.net/m0_73552311/category_12174133.html?spm=1001.2014.3001.5482数据分析
https://blog.csdn.net/m0_73552311/category_12174133.html?spm=1001.2014.3001.5482数据分析
~~未完待续~~
深度学习
~~未完待续~~















 4138
4138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









