










 文章探讨了信息熵的概念,解释了事件概率与其对信息熵的影响,以及如何通过支持向量机进行文本分类,包括特征提取、数据预处理、模型训练和调优过程。重点介绍了最优超平面在SVM中的作用以及处理大规模数据的方法。
文章探讨了信息熵的概念,解释了事件概率与其对信息熵的影响,以及如何通过支持向量机进行文本分类,包括特征提取、数据预处理、模型训练和调优过程。重点介绍了最优超平面在SVM中的作用以及处理大规模数据的方法。
信息熵理解
就是说,每个事件都会提供一些信息以确定情况
事件发生的概率越大,意味着频率越大,就有越多的可能性,能缩减的查找范围就越少,所以信息熵就少;
事件发生的概率越小,意味着频率越小,就有更少的情况会发生这样的事件,那么能缩减的查找范围就会增大,所以信息熵就大;
所谓信息熵实际上就是事件发生后用来衡量能缩减多大的查找空间,能缩减多少的情况数。
能缩减(2^信息熵)的情况数

就是说整个空间信息大小为13.66比特,然后经过三次查询,每次查询的信息量分别为4.49,3.39,4.78,缩减的信息大小同样这么大,到最后就剩一比特,就是二选一 



就是说出现了当前这个结果,一共有四种可能,那么这个结果就是2比特的信息

就是说如果只有4种情况的话,每种情况的概率是1/4,那么取倒数后的对数是2
16,
如果都是都可能的话,情况数有n种,那么概率为1/n,取倒数取对数为log2n
信息熵为1/n*n*log2n,
如果每种事件的概率都相同的话,结果是这样的,也就是说每种事件,信息熵最大为log2n 
之所以说是最大,是因为分布是不均匀的,也就是说对应的所有事件里有的发生概率大,有的发生事件概率小,就越可能去倾向于某一些事情,而不是所有可能的结果


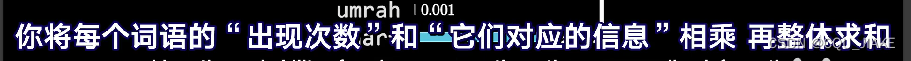
” 对应的信息“指的就是log21/px
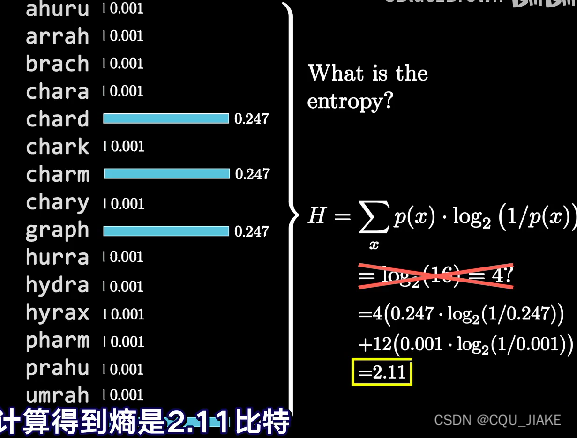


第一种熵的理解是预期某次猜测的信息量有多少
第二种是说衡量剩余的所有可能有多大的不确定性
第一种的话就是说做一件事,然后这个事会产生很多的结果,去计算这个结果的熵![]()

一个好看的图
一个简单的思路是,通过数据去计算平均值,然后依据平均值的情况去打标,
打完标后进行聚类分类,分类≠聚类
支持向量机
对于给定的数据集,可以使用各种文本分类或聚类算法来实现对单词的分类或聚类,以确定其他单词的标签。
1. 文本分类:文本分类的目标是将不同的文本或单词分配到预定义的类别中。常见的文本分类算法包括朴素贝叶斯分类、支持向量机(SVM)、逻辑回归等。这些算法可以使用单词作为特征,并根据其在训练集中的出现频率或其他相关度量进行分类。
2. 聚类:聚类算法的目标是将相似的文本或单词聚集到一起,形成不同的聚类簇。常见的聚类算法包括K均值聚类、层次聚类、DBSCAN等。这些算法可以根据单词之间的相似度或距离,将其分组成簇。
在进行分类或聚类之前,需要对给定的数据集进行预处理,包括文本清洗、分词、特征选择或提取等步骤。然后,可以使用训练集进行模型的训练,并根据模型预测或聚类结果来对其他单词进行分类或确定标签。
需要注意的是,对于文本分类或聚类任务,数据集的质量、特征选择、算法选择等都会对最终结果产生影响。因此,在实际应用中,需要根据具体的问题和数据集特点选择适合的算法和方法,并进行合理的实验和调参。
最优超平面是支持向量机(Support Vector Machine,SVM)算法中的核心概念之一。它是一种能够将数据集在高维空间中进行划分的线性决策边界。
在二分类问题中,最优超平面是一个d-1维的超平面,将d维空间中的两类数据集分开。其中,d是数据集的特征维度。对于二维空间,最优超平面是一条直线,对于三维空间,最优超平面是一个平面。最优超平面的选择是通过求解一个凸优化问题来实现的。SVM的目标是找到一个最优超平面,使得两个不同类别的样本点到该超平面的距离最大化。这个距离可以用支持向量的概念来定义。支持向量是离最优超平面最近的那些样本点。最优超平面的选择是使得这些支持向量到超平面的距离最大化。这样做的目的是为了最大限度地保持超平面与两个类别之间的间隔,以提高分类的准确性和鲁棒性。
在非线性可分的情况下,可以使用核函数将数据映射到高维空间中,从而将线性不可分问题转化为线性可分问题。这样,最优超平面可以在高维空间中找到。这种技术被称为核技巧(Kernel Trick)。
总结起来,最优超平面是通过最大化支持向量到超平面的距离来分离两个不同类别的样本。它是SVM算法的关键概念,用于实现高效的文本分类和其他机器学习任务。
支持向量机(Support Vector Machine,SVM)是一种常用的机器学习算法,可用于文本分类任务。它的核心思想是通过构建一个最优超平面来将文本数据在高维空间中进行划分。
下面是使用支持向量机实现文本分类的一般步骤:
1. 数据准备:首先,需要准备一个用于训练和测试的文本数据集。数据集应包含已经标记好的文本样本和相应的类别标签。
2. 特征提取与向量化:将文本数据转换为向量形式,以便计算机可以处理。常见的特征提取方法包括词袋模型(Bag-of-Words)和词嵌入(Word Embedding)技术(如Word2Vec、GloVe等)。这些方法可以将一个文本表示为一个向量,其中每个维度表示一个特定的特征或词。
3. 数据预处理:对文本进行预处理,包括去除停用词、进行词干提取或词形还原等文本规范化操作。
4. 特征选择:根据需求和数据集的特点,选择一组最具代表性的特征来训练模型,以提高分类性能。常用的特征选择方法包括信息增益、互信息、卡方检验等。
5. 模型训练:使用训练数据集,利用支持向量机算法训练一个分类模型。在训练过程中,SVM通过求解一个凸优化问题来找到最优的超平面,使得不同类别的样本在超平面上的距离最大化。
6. 模型调参:SVM有一些关键的参数需要调整,例如核函数的选择、正则化参数C的设置等。可以使用交叉验证等方法来选择合适的参数,并调整模型的复杂度以达到更好的分类性能。
7. 模型评估:使用测试数据集来评估训练好的SVM模型的分类性能。可以使用一些指标,如准确率、精确率、召回率和F1值等来评估分类结果的准确程度。
需要注意的是,支持向量机算法对于大规模文本数据集可能会面临计算效率和存储空间的挑战。为了应对这些问题,可以采用核技巧(Kernel Trick)来降低计算复杂度,并采用增量学习等方法来处理大规模数据集。
总之,使用支持向量机实现文本分类可以通过选择合适的特征提取方法、数据预处理和参数调优来获得较好的分类效果。















 6695
6695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









