






文章目录
题目:
请实现一个程序计算f(x)
f(x)和g(x)的定义如下:
x
<
10
x<10
x<10时
{
f
(
x
)
=
1
g
(
x
)
=
1
\begin{cases} \begin{aligned} f(x)&=1\\ g(x)&=1 \end{aligned} \end{cases}
{f(x)g(x)=1=1
x
∈
[
10
,
10000
)
x\in[10,10000)
x∈[10,10000)时
{
f
(
x
)
=
f
(
x
−
1
)
g
(
x
−
2
)
+
f
(
x
−
2
)
g
(
x
−
1
)
g
(
x
)
=
f
(
⌊
x
2
⌋
)
g
(
x
−
1
)
\begin{cases} \begin{aligned} f(x)&=f(x-1)g(x-2)+f(x-2)g(x-1)\\ g(x)&=f(\lfloor \frac x 2\rfloor)g(x-1) \end{aligned} \end{cases}
⎩
⎨
⎧f(x)g(x)=f(x−1)g(x−2)+f(x−2)g(x−1)=f(⌊2x⌋)g(x−1)
因为结果可能会很大,请输出f(x)对10007取余的结果
样例输入:20
样例输出:233
解法1:直接递归求解
#include<iostream>
using namespace std;
using ll = long long;
#define mod 10007
ll g(ll x);
ll f(ll x)//函数f(x)
{
if (x < 10)
return 1;
return f(x - 1) * g(x - 2) + f(x - 2) * g(x - 1);
}
ll g(ll x)//函数g(x)
{
if (x < 10)
return 1;
return f(x / 2) * g(x - 1);
}
int main()
{
int x;
cin >> x;
cout << f(x) % mod << endl;
return 0;
}
这段代码能通过样例测试,但是当x取30时输出了一个负数,很明显是f(30)的值过大导致long long溢出
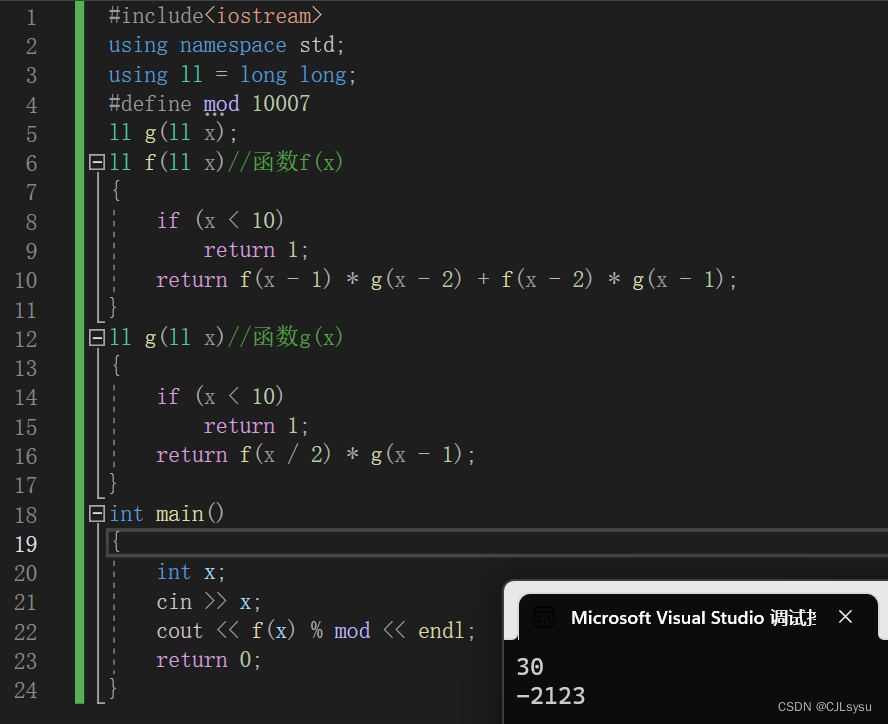
如何处理该问题?要知道long long是C++最长的整数类型,x等于30时就已经越界了,更不必说x=10000
一种思路是实现一个BigInt大整数类,用字符串存储和计算整数,代码比较复杂,因为需要重载实现加法、乘法和取余运算,不知道有没有大佬用这种方法解出此题。
解法2:数学+记忆化递归
递归的过程中f(x)一直在做乘法而快速增长,为了避免f(x)过大,能否在递归f(x)的过程中进行取余运算?
以下先证明两个定理:
注:%为取余运算
引理1: ( a ⋅ b ) % m = ( ( a % m ) ⋅ ( b % m ) ) % m (a\cdot b)\%m=((a\%m)\cdot(b\% m))\%m (a⋅b)%m=((a%m)⋅(b%m))%m
证明:
设
{
a
=
m
a
1
+
a
2
b
=
m
b
1
+
b
2
(
m
,
a
1
,
a
2
,
b
1
,
b
2
∈
N
+
)
\begin{cases} a=ma_1+a_2\\ b=mb_1+b_2\\ \end{cases} (m,a_1,a_2,b_1,b_2\in N^+)
{a=ma1+a2b=mb1+b2(m,a1,a2,b1,b2∈N+)
满足
a
%
m
=
a
2
b
%
m
=
b
2
a\%m=a_2\\ b\%m=b_2
a%m=a2b%m=b2
则
a
⋅
b
=
m
2
a
1
b
1
+
m
(
a
1
b
2
+
a
2
b
1
)
+
a
2
b
2
a\cdot b=m^2a_1b_1+m(a_1b_2+a_2b_1)+a_2b_2
a⋅b=m2a1b1+m(a1b2+a2b1)+a2b2
因为
(
m
2
a
1
b
1
+
m
(
a
1
b
2
+
a
2
b
1
)
)
%
m
=
0
(m^2a_1b_1+m(a_1b_2+a_2b_1))\%m=0
(m2a1b1+m(a1b2+a2b1))%m=0
所以
(
a
⋅
b
)
%
m
=
(
a
2
b
2
)
%
m
=
(
(
a
%
m
)
⋅
(
b
%
m
)
)
%
m
\begin{aligned} (a\cdot b)\%m&=(a_2b_2)\%m\\ &=((a\%m)\cdot(b\% m))\%m \end{aligned}
(a⋅b)%m=(a2b2)%m=((a%m)⋅(b%m))%m
引理2: ( a + b ) % m = ( a % m + b % m ) % m (a+b)\%m=(a\%m+b\%m)\%m (a+b)%m=(a%m+b%m)%m
证明:
{
a
=
m
a
1
+
a
2
b
=
m
b
1
+
b
2
(
m
,
a
1
,
a
2
,
b
1
,
b
2
∈
N
+
)
\begin{cases} a=ma_1+a_2\\ b=mb_1+b_2\\ \end{cases} (m,a_1,a_2,b_1,b_2\in N^+)
{a=ma1+a2b=mb1+b2(m,a1,a2,b1,b2∈N+)
a % m = a 2 b % m = b 2 a\%m=a_2\\ b\%m=b_2 a%m=a2b%m=b2
满足:
a
+
b
=
m
(
a
1
+
b
1
)
+
a
2
+
b
2
a+b=m(a_1+b_1)+a_2+b_2
a+b=m(a1+b1)+a2+b2
( m ( a 1 + b 1 ) ) % m = 0 (m(a_1+b_1))\%m=0 (m(a1+b1))%m=0
所以:
(
a
+
b
)
%
m
=
(
a
2
+
b
2
)
%
m
=
(
a
%
m
+
b
%
m
)
%
m
\begin{aligned} (a+b)\%m&=(a_2+b_2)\%m\\ &=(a\%m+b\%m)\%m \end{aligned}
(a+b)%m=(a2+b2)%m=(a%m+b%m)%m
思路和代码:
(mod=10007)
要求f(x)%mod,等价于
(f(x-1)g(x-2)+f(x-2)g(x-1))%mod
利用上述两个引理,这等价于
(((f(x - 1) % mod) * (g(x - 2) % mod) % mod) + ((f(x - 2) % mod) * (g(x - 1) % mod))%mod) % mod
同理,g(x)%mod等价于
((f(x / 2)%mod) *( g(x - 1)%mod))%mod
这样,可以保证f(x)和g(x)都小于mod,不会溢出
可以这样改进代码:
#include<iostream>
using namespace std;
using ll = long long;
#define mod 10007
ll g(ll x);
ll f(ll x)//函数f(x)
{
if (x < 10)
return 1;
return (((f(x - 1) % mod) * (g(x - 2) % mod) % mod) + ((f(x - 2) % mod) * (g(x - 1) % mod))%mod) % mod;
}
ll g(ll x)//函数g(x)
{
if (x < 10)
return 1;
return ((f(x / 2) % mod) * (g(x - 1) % mod)) % mod;
}
int main()
{
int x;
cin >> x;
cout << f(x) % mod << endl;
return 0;
}
这样就解决了溢出问题,输入30不会出现负数,但输入100时就程序超时了
复杂度分析1:
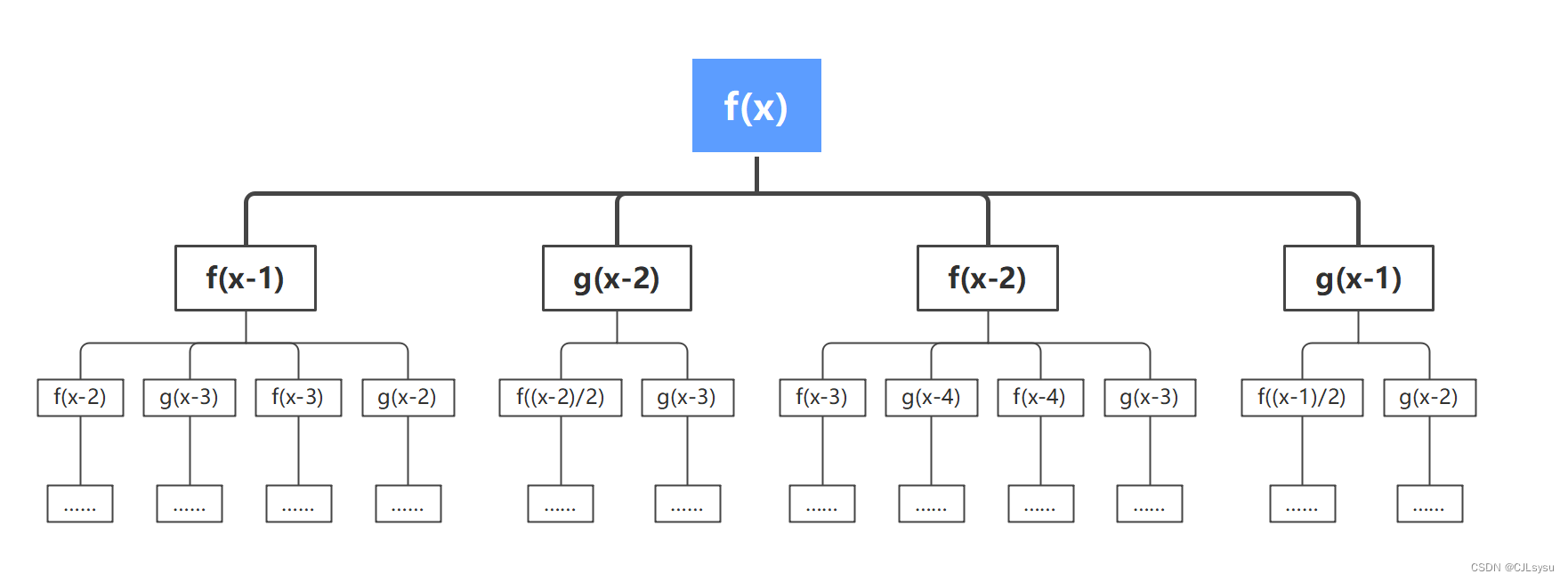
递归的过程相当于一次深度优先搜索DFS,从f(x)递归到f(k)和g(k)满足k<10,每一个元素都会引出常数m个分支,每递归一层,层内元素的个数就会增大m倍,总共递归x-8层(x很大时-8忽略不计),所以时间复杂度
O
(
m
x
)
O(m^x)
O(mx) (m为常数)
由于最大递归x-8层,空间复杂度为
O
(
x
)
O(x)
O(x)。
x很大时,递归层数很高,导致出现大量重复的运算,会消耗大量时间,例如上图中g(x-2)重复出现了三次,采用记忆化递归可以避免重复计算.
记忆化递归
可以用unordered_map<int,int>哈希表hashf和hashg来存储已经计算过的f(x)和g(x)值,利用之前计算过的结果减少递归。
AC代码:
#include<iostream>
#include<unordered_map>
using namespace std;
using ll=long long;
#define mod 10007
unordered_map<int, ll> hashf, hashg;
ll g(ll x);
ll f(ll x)//函数f(x)
{
if (x < 10)
return 1;
ll a, b, c, d;//分别代表(f(x - 1)%mod)、 (g(x - 2)%mod) 、 (f(x - 2)%mod) 、 (g(x - 1)%mod)
if (hashf[x - 1] != 0)
{
a = hashf[x - 1];
}
else
{
a = f(x - 1) % mod;
hashf[x - 1] = a;
}
if (hashg[x - 2] != 0)
{
b = hashg[x - 2];
}
else
{
b = g(x - 2) % mod;
hashg[x - 2] = b;
}
if (hashf[x - 2] != 0)
{
c = hashf[x - 2];
}
else
{
c = f(x - 2) % mod;
hashf[x - 2] = c;
}
if (hashg[x - 1] != 0)
{
d = hashg[x - 1];
}
else
{
d = g(x - 1) % mod;
hashg[x - 1] = d;
}
return ((a * b) % mod + (c * d) % mod) % mod;
}
ll g(ll x)//函数g(x)
{
if (x < 10)
return 1;
ll a, b;
if (hashf[x /2] != 0)
{
a = hashf[x /2];
}
else
{
a = f(x/2) % mod;
hashf[x /2] = a;
}
if (hashg[x - 1] != 0)
{
b = hashg[x - 1];
}
else
{
b = g(x - 1) % mod;
hashg[x - 1] = b;
}
return (a *b)%mod;
}
int main()
{
int x;
cin >> x;
cout << f(x) % mod << endl;
return 0;
}
复杂度分析2:

该过程同为深度优先搜索,不同的是增加了很多递归的终点(黄色和绿色元素)
- 黄色元素为递归到x<10得到结果,结束递归
- 绿色元素因为利用了存储在哈希表中的之前计算过的结果,也是递归的终点
- 红色元素的计算结果存入哈希表,供之后使用.
在递归的每一层,都只用处理常数m个分支,总共递归x-8层,所以时间和空间复杂度为 O ( m ( x − 8 ) ) O(m(x-8)) O(m(x−8))即 O ( x ) O(x) O(x)
用Visual Studio跑这段代码x=10000可能会Stack overflow (VS的函数调用栈比较小,会溢出,不知有没有大佬会解决)
博主考试时这样写,是可以通过的,用devC++或matrix平台都可以正常运行
解法3:数学+循环代替递归
感谢chenwn11提供的思路,可以用数组储存f(x)和g(x)对mod取余后的结果,从小到大循环计算f(x)和g(x),不使用函数调用栈,可以防止爆栈
#include<iostream>
#include<vector>
#define mod 10007
using ll = long long;
using namespace std;
int main()
{
int x;
cin >> x;
if (x < 10)
{
cout << 1 << endl;
return 0;
}
vector<ll> f(x+1), g(x+1);
for (int i = 0; i < 10; ++i)
{
f[i] = 1;
g[i] = 1;
}
for (int i = 10; i <= x; ++i)
{
f[i] = ((f[i - 1] * g[i - 2]) % mod + (f[i - 2] * g[i - 1]) % mod) % mod;
g[i] = (f[i / 2] * g[i - 1]) % mod;
}
cout << f[x] << endl;
return 0;
}
这段代码时间和空间复杂度:
O
(
x
)
O(x)
O(x) ,可以用VS正常运行
各位大佬如果有更好的思路欢迎提出














 549
549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









