






LoRA模型,全称Low-Rank Adaptation of Large Language Models,是一种用于微调大型语言模型的低秩适应技术。它最初应用于NLP领域,特别是用于微调GPT-3等模型。LoRA通过仅训练低秩矩阵,然后将这些参数注入到原始模型中,从而实现对模型的微调。这种方法不仅减少了计算需求,而且使得训练资源比直接训练原始模型要小得多,因此非常适合在资源有限的环境中使用。
在Stable Diffusion(SD)模型的应用中,LoRA被用作一种插件,允许用户在不修改SD模型的情况下,利用少量数据训练出具有特定画风、IP或人物特征的模型。这种技术在社区使用和个人开发者中非常受欢迎。例如,可以通过LoRA模型改变SD模型的生成风格,或者为SD模型添加新的人物/IP。
什么是 LoRA 模型?
LoRA(Low-Rank Adaptation)是一种用于微调Stable Diffusion模型的训练技术。
但我们已经有了其他的训练技术,例如 Dreambooth 和 文本反转。那么 LoRA 有何特别之处呢?LoRA 在文件大小和训练能力之间取得了良好的平衡。Dreambooth 功能强大,但模型文件体积较大(2-7 GB)。文本反转模型很小(约100 KB),但功能有限。
LoRA 位于二者之间:它们的文件大小适中(2-200 MB),而且训练能力还不错。
那些喜欢尝试各种 模型 的Stable Diffusion用户可以告诉你,他们的本地存储很快就会填满。由于文件体积较大,用个人电脑来维护一个模型集合非常困难。LoRA 是解决存储问题的绝佳方案。
与文本反转类似,你不能单独使用 LoRA 模型。它必须与模型检查点文件一起使用。LoRA 通过对附带的模型文件应用小的改动来修改风格。
LoRA 是如何工作的?
LoRA 对Stable Diffusion模型中最关键的部分进行微小改动:交叉注意力层。这是模型中图像和提示相遇的部分。
研究人员发现,仅微调模型的这一部分就足以实现良好的训练效果。交叉注意力层在下方的Stable Diffusion模型架构中以黄色部分表示。
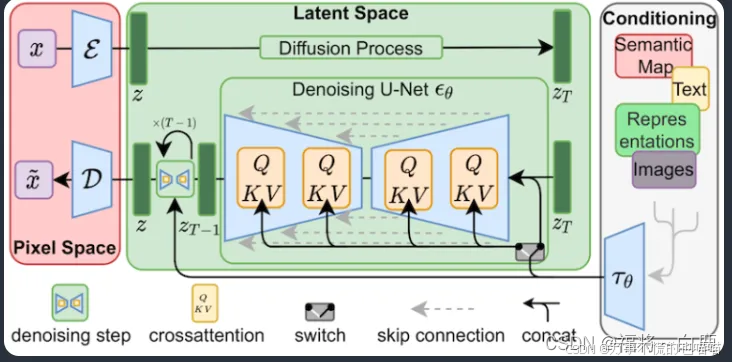
交叉注意力层的权重被排列成矩阵形式。矩阵就像 Excel 电子表格中按列和行排列的一系列数字。LoRA 模型通过将其权重添加到这些矩阵中来对模型进行微调。
LoRA 模型文件如何更小,即使它们需要存储相同数量的权重?LoRA 的技巧在于将矩阵分解为两个较小(低秩)的矩阵。这样可以存储更少的数字。我们通过以下示例来说明这一点。
假设模型有一个具有 1,000 行和 2,000 列的矩阵。这就是要在模型文件中存储的 2,000,000 个数字(1,000 x 2,000)。LoRA 将该矩阵分解为一个 1,000x2 的矩阵和一个 2x2,000 的矩阵。这只需要 6,000 个数字(1,000 x 2 + 2 x 2,000),是原始矩阵大小的 333 倍。这就是 LoRA 文件更小的原因。
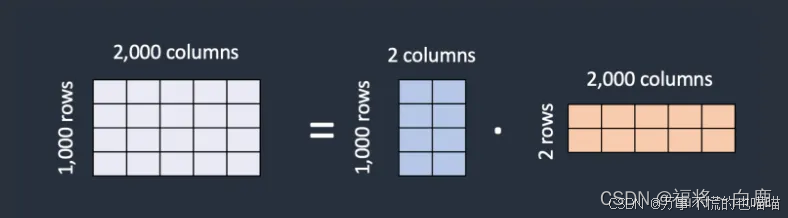
LoRA 将一个大矩阵分解为两个小的低秩矩阵。
在这个示例中,矩阵的秩是 2。它远远低于原始维度,因此被称为低秩矩阵。秩可以低至 1。
但是,这样做是否会产生任何问题?研究人员发现,在交叉注意力层中进行这样的操作并不会对微调的效果产生太大影响。因此,我们是安全的。


















 2331
2331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











