









Java面试 redis 篇
redis的使用场景:
缓存,分布式锁,计数器,保存token 消息队列,延迟队列
 项目中真实使用过的redis
项目中真实使用过的redis
缓存:缓存三兄弟(穿透,击穿,雪崩) 双写一致 ,持久化,数据过期策略,数据淘汰策略,
分布式锁:setnx redisson
消息队列 延迟队列
如果发生了 缓存的穿透 击穿 雪崩 该如何解决
1.搞清楚啥时缓存穿透:

解决方案1.
缓存空数据,查询返回的数据为空,仍然把这个空结果进行缓存
优点是:简单。缺点是消耗内存,会出现数据不一致问题
为何会出现数据不一致问题
如上图当根据id=100来查询,数据库不存在这个数据,然后按照方案一的解决 缓存一个空值,如果后续,这个id=100 的位置上有了数据,就会导致如果还根据id=100 来查询,查询的结果为空,实际数据库有数据,这就造成数据不一致的问题。
解决方案2.

优点:内存占用较少,没有多余的key
缺点;实现较复杂,存在误判
缓存 击穿问题
1.啥是缓存击穿:给一个key 设置了过期时间,当key过期的时候 ,恰好对这个key 有大量的请求发过来,因为此时redis中是没有数据的,这些请求瞬间可能就将数据库压垮。
解决方案:
1.互斥锁
2.逻辑过期


这里在使用逻辑过期中当线程一 走到第三步 要开启新的线程来进行缓存的重建,此时,线程一并不会等待线程2 缓存重建完成,锁释放了之后才返回数据,而是直接返回数据,这个数据为旧数据,在缓存重建过程中,如果有其他的线程过来查询,此时获取锁是失败的,同样是返回旧数据。
缓存雪崩
啥是缓存雪崩:指的是在同一时间段有大量的缓存key同时失效,或者redis服务器宕机,导致大量请求到达数据库,带来巨大压力
解决方案
1.给不同的key过期时间上加一个随机值
2.因为redis服务宕机发生的:利用redis集群提高服务的高可用,如哨兵模式 集群模式
3.给缓存业务添加降级限流策略
4.给业务添加多级缓存
redis作为缓存,mysql的数据如何与redis进行同步呢,(双写一致性)
对于一致性要求高的:
读操作:缓存命中直接返回,缓存为命中,写入缓存,设置超时时间
写操作:延迟双删
无论是先删除缓存还是先修改数据 都会出现问题
先删除缓存,修改数据库,等一段时间,再去删除一次缓存。
两次删除的第二次删除就是为了避免脏数据的出现
为何要延时删除: 因为数据库是主从架构,要等主数据库将数据同步到从数据库之后
使用读写锁来保证数据强一致性(性能低)
共享锁:读锁(readlock) 加锁之后其他线程可以进行读取
排他锁:独占锁(writerlock) 加锁之后,阻塞其他线程读写操作
一般放入缓存中的数据大部分都是读多写少
当去读取数据的时候可以添加共享锁,写数据时加排他锁
具体的代码逻辑
 
面试总结:

redis持久化是如何做的?
RDB
AOF




redis的数据过期策略
问: 假如redis 的key 过期了 会立即删除吗?
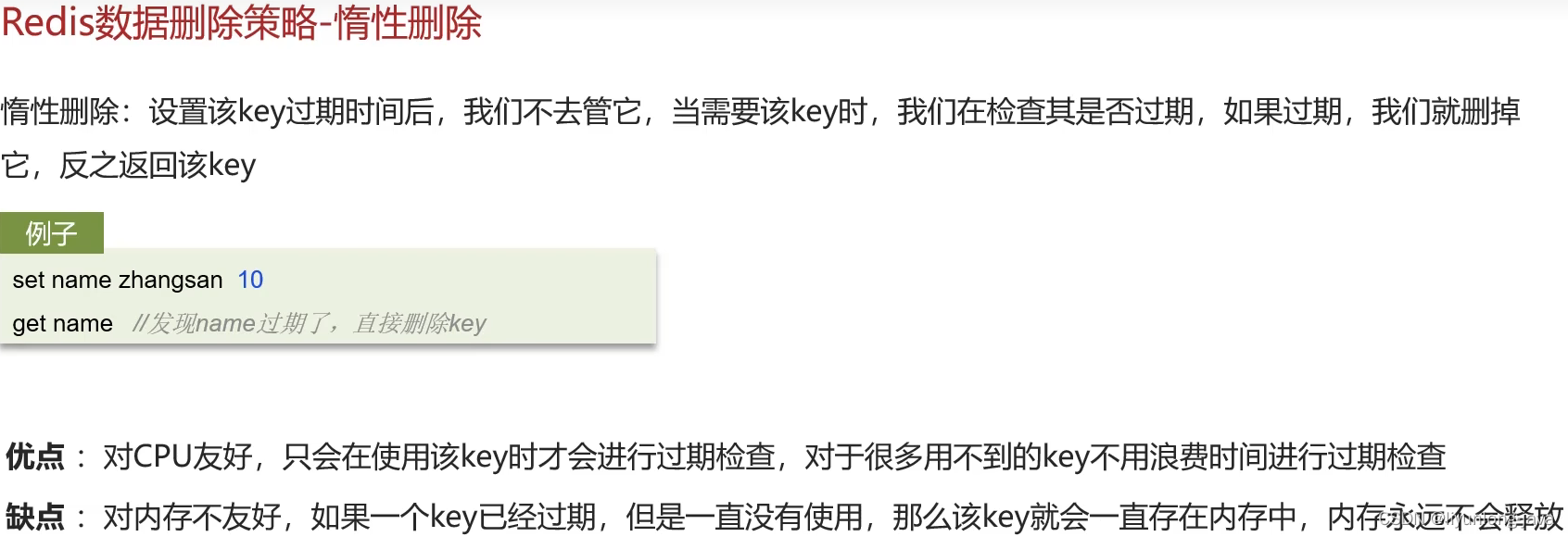

redis数据淘汰策略

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









