






目录
一、顺序表与链表简介
概念与结构
顺序表:顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数组存储。在数组上完成数据的增删查改。
物理结构如下
顺序表一般可以分为:
1. 静态顺序表:使用定长数组存储元素。
#define N 100
typedef int ElemType;
typedef struct SeqList{
ElemType data[N];
int size;
int capacity;
}SL;2.动态顺序表:使用动态开辟的数组存储。
typedef int ElemType;
typedef struct SeqList{
ElemType *data;
int size;
int capacity;
}SL;链表概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
物理结构如下:
实际中链表的结构非常多样,以下情况组合起来就有8种链表结构:
1. 单向或双向
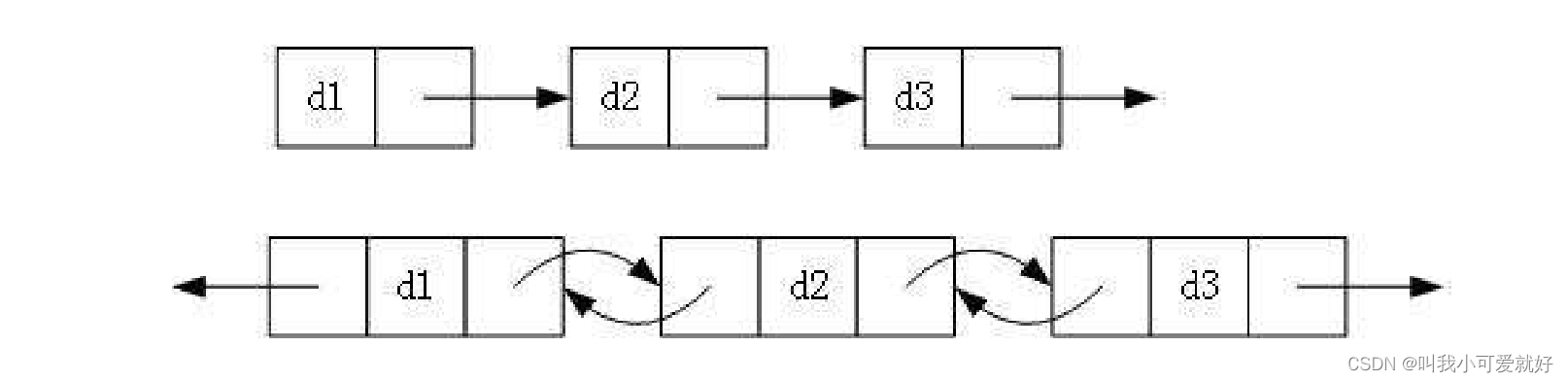
2. 带头或不带头

3. 循环或非循环

虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构:
无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了
二、代码实现
1.顺序表
静态顺序表只适用于确定知道需要存多少数据的场景。静态顺序表的定长数组导致N定大了,空间开多了浪费,开少了不够用。所以现实中基本都是使用动态顺序表,根据需要动态的分配空间大小,所以下面我们实现动态顺序表。
.h文件
#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>
typedef int ElemType;
typedef struct SeqList{
ElemType *data;
int size;
int capacity;
}SL;
void SLInit(SL* p); //顺序表初始化
void SLPushBack(SL *p, ElemType x); //尾插
void SLPushFront(SL *p, ElemType x); //头插
void SLPopBack(SL *p); //尾删
void SLPopFront(SL *p); //头删
int SLFind(SL *p,ElemType x); //查找并返回下标
void SLInsert(SL *p, int pos, ElemType x); //在指定位置插入
void SLErase(SL *p, int pos); //删除pos位置数据
void SLPrintf(SL *p); //打印
int SLSize(SL *p); //返回元素个数
bool SLEmpty(SL *p); //判空
void SLDestroy(SL *p); //销毁.c函数实现文件
#include"SeqList.h"
void SLInit(SL* p){ //顺序表初始化
p->data = (ElemType *)malloc(sizeof(ElemType)* 10);
if (p->data == NULL){
printf("malloc fail\n");
exit(-1);
}
p->size = 0;
p->capacity = 10;
}
void SLCheckCapacity(SL *p){ //判断是否满了
if (p->size == p->capacity){
ElemType *new = realloc(p->data, sizeof(ElemType)*(p->capacity + 5));
if (new == NULL){
printf("realloc fail");
exit(-1);
}
p->data = new;
p->capacity += 5;
}
}
void SLPushBack(SL *p, ElemType x){ //尾插
SLCheckCapacity(p);
p->data[p->size] = x;
p->size++;
}
void SLPushFront(SL *p, ElemType x){ //头插
SLCheckCapacity(p);
for (int i = p->size; i > 0; i--){ //数据后移
p->data[i] = p->data[i - 1];
}
p->data[0] = x;
p->size++;
}
void SLPopBack(SL *p){ //尾删
if (p->size == 0){
printf("该表暂无内容,无法删除\n");
return;
}
p->size--;
}
void SLPopFront(SL *p){ //头删
if (p->size == 0){
printf("该表暂无内容,无法删除\n");
return;
}
for (int i = 0; i < p->size-1; i++){ //数据前移
p->data[i] = p->data[i + 1];
}
p->size--;
}
int SLFind(SL *p,ElemType x){ //查找并返回下标
int i;
for ( i = 0; i < p->size; i++){
if (x == p->data[i]){
return i;
}
}
printf("没找到该元素\n");
}
void SLInsert(SL *p, int pos, ElemType x){ //在指定位置插入
SLCheckCapacity(p); //先判断是否满了
if (pos<0 || pos>p->size+1){ //判断pos的值是否合法
printf("请在合理的范围插入\n");
return;
}
for (int i =p->size; i >pos-1; i--){ //数据后移
p->data[i] = p->data[i-1];
}
p->data[pos-1] = x;
p->size++;
}
void SLErase(SL *p, int pos){ //删除pos位置数据
if (p->size == 0){
printf("该表暂无内容,无法删除\n");
return;
}
if (pos<0 || pos>p->size){ //判断pos的值是否合法
printf("请在合理的范围插入\n");
return;
}
for (int i =pos-1; i<p->size-1; i++){ //数据前移
p->data[i] = p->data[i+1];
}
p->size--;
}
int SLSize(SL *p){ //返回表中元素个数
return p->size;
}
bool SLEmpty(SL *p){ //判空
return p->size == 0;
}
void SLDestroy(SL *p){ //销毁
free(p->data);
p->data = NULL;
p->size = p->capacity = 0;
}
void SLPrintf(SL *p){ //打印
for (int i = 0; i < p->size; i++){
printf("%d ", p->data[i]);
}
printf("\n");
}2.链表
2.1 无头单向非循环链表
.h头文件
#include<stdio.h>
#include<stdlib.h>
typedef int ElemType;
typedef struct SListNode{
ElemType data;
struct SListNode *next;
}SN;
//void SListInit(SN **p); //初始化
void SListPushBack(SN **p, ElemType x); //尾插
void SListPushFront(SN **p, ElemType x); //头插
void SListPopBack(SN **p); //尾删
void SListPopFront(SN **p); //头删
void SListPrintf(SN **p); //打印链表
SN *SListFind(SN **p,ElemType x); //查找
void SListInsert(SN **p, SN *pos, ElemType x); //在pos位置前插入一个结点
void SListInsertAfter(SN **p, SN *pos, ElemType x); //在pos位置后面插入一个结点
void SListErase(SN **p, SN *pos); //删除pos位置结点
void SListDestroy(SN **p); //销毁链表.c各个函数实现文件
#include"SList.h"
SN* newnode(ElemType x){ //生成新结点函数
SN *new = (SN *)malloc(sizeof(SN));
new->data = x;
new->next = NULL;
return new;
}
void SListPrintf(SN **p){ //打印函数
SN *head = *p;
while (head != NULL){
printf("%d ", head->data);
head = head->next;
}
printf("\n");
}
void SListPushBack(SN **p, ElemType x){ //尾插
SN *head = *p;
if (*p == NULL){ //当链表为空时,构造第一个结点
*p = newnode(x);
return;
}
while (head->next != NULL){ //找到尾结点
head = head->next;
}
head->next = newnode(x);
}
void SListPushFront(SN **p, ElemType x){ //头插
SN *head = *p; //将原本头指针指向的结点保存起来
*p = newnode(x);
(*p)->next = head;
}
void SListPopBack(SN **p){ //尾删 当链表只有一个结点,tail为空,会导致越界访问
if (*p == NULL){
printf("该链表为空\n");
return;
}
if ((*p)->next == NULL){ //当只有一个结点时
free(*p);
*p = NULL;
return;
}
SN *head = *p; //有两个及两个以上结点时
SN *tail = NULL; //用来储存倒数第二个结点
while (head->next != NULL){
tail = head;
head = head->next;
}
tail->next = NULL;
free(head);
head = NULL;
}
void SListPopFront(SN **p){ //头删
if (*p == NULL){ //当链表为空时
printf("该链表为空\n");
return;
}
SN *next = (*p)->next;
free(*p);
*p= next;
}
SN *SListFind(SN **p, ElemType x){ //查找
SN *head = *p;
while (head != NULL){
if (head->data == x){
return head;
}
head = head->next;
}
return NULL;
}
void SListInsert(SN **p, SN *pos, ElemType x){ //在pos位置前插入
if (pos == *p){
SListPushFront(p, x); //当只有一个
}
else{
SN *head = *p;
while (head->next != pos){
head = head->next;
}
SN *new = newnode(x);
head->next = new;
new->next = pos;
}
}
void SListInsertAfter(SN **p, SN *pos, ElemType x){ //在pos位置后面插入一个结点
SN *new = newnode(x);
new->next = pos->next;
pos->next = new;
}
void SListErase(SN **p, SN *pos){ //删除pos位置结点
if (*p == pos){
SListPopFront(p);
}
else{
SN *head = *p;
while (head->next != pos){
head = head->next;
}
head->next = pos->next;
free(pos);
pos = NULL;
}
}
void SListDestroy(SN **p){ //销毁链表
SN* head = *p;
while (head != NULL){
SN *next = head->next;
free(head);
head = next;
}
*p = NULL;
}2.2 带头双向循环链表
.h头文件
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int ElemType;
typedef struct ListNode{
ElemType data;
struct ListNode*next;
struct ListNode*prev;
}LN;
void LNInit(LN *p); //初始化
void LNPrintf(LN *p); //打印
void LNPushBack(LN *p, ElemType x); //后插
void LNPushFront(LN *p, ElemType x); //头插
void LNPopBack(LN *p); //尾删
void LNPopFront(LN *p); //头删
LN *LNFind(LN *p,ElemType x); //查找
void LNInsert(LN *pos, ElemType x); //在pos前插入x
void LNErase(LN *pos); //删除pos结点
void LNDestroy(LN *p); //销毁链表.c函数实现文件
#include"DList.h"
LN *newnode(ElemType x){ //创造结点
LN *new = (LN *)malloc(sizeof(LN));
new->data = x;
new->next = new->prev = NULL;
return new;
}
void LNInit(LN **p){ //初始化
LN *phead = (LN *)malloc(sizeof(LN)); //创造一个头结点
phead->next = phead->prev = phead;
*p = phead;
}
void LNPrintf(LN *p){ //打印
if (p->next == p){
printf("该链表为空\n");
return;
}
LN *cur = p->next;
while (cur != p){
printf("%d ", cur->data);
cur = cur->next;
}
printf("\n");
}
void LNPushBack(LN *p, ElemType x){ //后插
LN *new = newnode(x);
LN *tail = p->prev; //尾结点
tail->next = new;
new->prev = tail;
new->next = p;
p->prev = new;
//LNInsert(p, x);
}
void LNPushFront(LN *p, ElemType x){ //前插
LN *new = newnode(x);
LN *frist = p->next; //先保存第一个结点的地址
p->next = new;
new->next = frist;
new->prev = p;
frist->prev = new;
//LNInsert(p->next, x);
}
void LNPopBack(LN *p){ //尾删
assert(p->next != p); //链表空了不能删了
LN *tail = p->prev; //尾结点
LN *last = tail->prev; //倒数第二个结点
last->next = p;
p->prev = last;
free(tail);
tail = NULL;
LNErase(p->prev);
}
void LNPopFront(LN *p){ //头删
assert(p->next != p);
LN *frist = p->next;
p->next = frist->next;
frist->next->prev = p;
free(frist);
frist = NULL;
//LNErase(p->next);
}
LN* LNFind(LN *p,ElemType x){ //查找
LN *cur = p->next;
while (cur != p){
if (cur->data == x){
return cur;
}
cur = cur->next;
}
return NULL;
}
void LNInsert(LN *pos, ElemType x){ //在pos前插入
LN *new = newnode(x);
LN *posprev = pos->prev; //pos前结点
new->next = pos;
new->prev = posprev;
posprev->next = new;
pos->prev = new;
}
void LNErase(LN *pos){ //删除pos结点
LN *posprev = pos->prev;
LN *posnext = pos->next;
posprev->next = posnext;
posnext->prev = posprev;
free(pos);
}
void LNDestroy(LN **p){ //销毁
LN *cur = (*p)->next;
while (cur != (*p)){
LN *next = cur->next;
free(cur);
cur = next;
}
free(*p);
*p = NULL;
}三、顺序表与链表的比较
1.顺序表
优点:
1. 用下标访问,支持随机访问,需要随机访问结构支持的算法可以很好的适用
2. CPU高速缓存命中率更高
缺点:
1.头部中部插入需要大量挪动数据,效率低
2.连续的物理空间,满了需要增容,会造成空间浪费
2.链表
以双向带头循环链表为例.
优点:
1.任意位置插入删除效率高
2.按需申请释放空间
缺点:
1.不支持随机访问(用下标访问),意味着一些算法比如说二分查找无法使用
2.一个结点存储一个值,还要存储下一个节点指针,有一定消耗
3.CPU高速缓存命中率低















 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









