






1. 原理:
逻辑回归是一种用于解决二分类问题的统计学习方法。它基于一个基本假设:将输入特征的线性组合通过一个特定的函数(称为逻辑函数或Sigmoid函数)映射到一个介于0和1之间的输出,表示样本属于某一类别的概率。
2. 公式:
逻辑回归模型的公式如下所示:
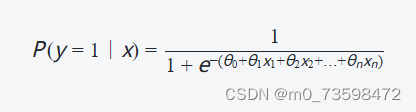
其中,𝑃(𝑦=1∣𝑥)P(y=1∣x)表示给定输入𝑥x时,样本属于类别1的概率;𝑥1,𝑥2,…,𝑥𝑛x1,x2,…,xn表示输入特征;𝜃0,𝜃1,…,𝜃𝑛θ0,θ1,…,θn表示模型参数。
3. 训练过程:
逻辑回归的训练过程通常通过最大似然估计(Maximum Likelihood Estimation,MLE)或梯度下降等优化算法来实现。训练的目标是最大化似然函数,即使得观测到的样本属于其对应类别的概率尽可能大。
4. 预测过程:
在预测阶段,逻辑回归模型会根据输入样本的特征计算出样本属于各个类别的概率,并根据设定的阈值(通常为0.5)来判断样本属于哪个类别。
5. 擅长领域:
逻辑回归在以下情况下表现良好:
- 二分类问题:逻辑回归适用于解决二分类问题,例如垃圾邮件分类、疾病诊断等。
- 线性可分数据:当数据集的特征与标签之间存在线性关系,并且数据集满足逻辑回归的假设时,逻辑回归能够取得较好的效果。
- 快速原型开发:由于其简单的模型结构和训练方式,逻辑回归适用于快速原型开发和简单场景应用。
6. 优缺点总结:
优点:
- 实现简单,易于理解和解释。
- 计算代价低,训练速度快。
- 输出结果具有概率意义,可以对不同类别的预测概率进行解释。
缺点:
- 假设输入特征线性可分,对非线性数据拟合能力有限。
- 无法处理复杂的关系,如特征之间的高阶交互作用。
7.实验部分
实际背景:
糖尿病患病风险预测,假设有一个医学研究项目,希望通过分析患者的生活方式和生理指标来预测他们患糖尿病的风险。随机生成了一批患者的数据,包括年龄、性别、BMI指数、血压、血糖水平等指标,以及是否患有糖尿病的标签信息。
1)随机生成数据集
np.random.seed(42)
X = np.random.rand(100, 2) * 10
y = np.zeros(100)
y[X[:, 0] + X[:, 1] > 10] = 1
2)划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)3)建立逻辑回归模型
clf = LogisticRegression()
clf.fit(X_train, y_train)4)在测试集上进行预测
y_pred = clf.predict(X_test)5)计算模型评估指标
accuracy = clf.score(X_test, y_test)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)6)输出模型评估结果
print("模型评估结果:")
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)
print("F1 Score:", f1)7)完整代码
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_score, recall_score, f1_score
np.random.seed(42)
X = np.random.rand(100, 2) * 10
y = np.zeros(100)
y[X[:, 0] + X[:, 1] > 10] = 1
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
clf = LogisticRegression()
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
accuracy = clf.score(X_test, y_test)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
print("模型评估结果:")
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)
print("F1 Score:", f1)
8)结果展示:
















 1657
1657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









