






 本文介绍了KNN算法的基本原理,包括步骤、距离计算方法和K值的选择标准。通过实例演示了如何使用Python实现KNN算法,并讨论了模型评估指标,如准确率、精确率、召回率和AUC-ROC等。
本文介绍了KNN算法的基本原理,包括步骤、距离计算方法和K值的选择标准。通过实例演示了如何使用Python实现KNN算法,并讨论了模型评估指标,如准确率、精确率、召回率和AUC-ROC等。
1.KNN算法的简单实践
1)KNN算法的介绍:
K最近邻(K-Nearest Neighbors,简称KNN)是一种基本的分类和回归方法,它的原理简单而直观。在KNN算法中,对于一个未知样本,通过测量它与训练集中的所有样本的距离,然后选择距离最近的K个样本,根据它们的标签来确定该样本的类别。
2)KNN算法步骤:
-
选择K值:确定邻居的数量K,这是KNN算法中的一个超参数,需要通过交叉验证或其他技术来选择。
-
计算距离:对于未知样本,计算它与训练集中所有样本的距离。常用的距离度量方法包括欧氏距离、曼哈顿距离、闵可夫斯基距离等。
-
确定邻居:选取距离最近的K个样本作为邻居。
-
进行分类/回归:对于分类问题,采用投票法(统计K个邻居中各类别出现的频率)确定样本的类别;对于回归问题,采用平均法确定样本的输出。
3)距离计算方法:
-
欧氏距离(Euclidean Distance):
- 定义:欧氏距离是空间中两点之间的直线距离。
- 公式:对于两个n维向量( \mathbf{p} = (p_1, p_2, ..., p_n) )和( \mathbf{q} = (q_1, q_2, ..., q_n) ),它们之间的欧氏距离为: [ d(\mathbf{p}, \mathbf{q}) = \sqrt{\sum_{i=1}^{n}(p_i - q_i)^2} ]
-
曼哈顿距离(Manhattan Distance):
- 定义:曼哈顿距离是空间中两点在各个坐标轴上的距离总和。
- 公式:对于两个n维向量( \mathbf{p} = (p_1, p_2, ..., p_n) )和( \mathbf{q} = (q_1, q_2, ..., q_n) ),它们之间的曼哈顿距离为: [ d(\mathbf{p}, \mathbf{q}) = \sum_{i=1}^{n} |p_i - q_i| ]
-
闵可夫斯基距离(Minkowski Distance):
- 定义:闵可夫斯基距离是欧氏距离和曼哈顿距离的一般化。
- 公式:对于两个n维向量( \mathbf{p} = (p_1, p_2, ..., p_n) )和( \mathbf{q} = (q_1, q_2, ..., q_n) ),它们之间的闵可夫斯基距离为: [ d(\mathbf{p}, \mathbf{q}) = \left( \sum_{i=1}^{n} |p_i - q_i|^p \right)^{\frac{1}{p}} ] 其中,( p ) 是一个参数,当( p = 2 )时,为欧氏距离;当( p = 1 )时,为曼哈顿距离。
4)K值的决定标准:
-
经验法则:常见的选择K的方法是使用经验法则,如取样本数量的平方根,但这可能会过于简单化。
-
交叉验证:通过交叉验证(如K折交叉验证)来选择最优的K值,找到在验证集上表现最好的K值。
-
网格搜索:在一定范围内对K值进行搜索,使用网格搜索来找到在验证集上表现最好的K值。
-
基于特定问题的调整:根据具体问题的特点和数据的分布情况来调整K值,有时需要尝试不同的K值来达到最佳效果。
KNN算法的优点是简单易懂,对于小规模数据集表现良好,但在大规模数据集上效率低下。此外,KNN算法对于特征的尺度和噪声敏感,需要对数据进行预处理和归一化处理。
5)KNN简单实践:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
# 生成训练数据集
np.random.seed(0)
num_samples_train = 20
num_samples_test = 10
# 颜色和大小的随机值
color_train = np.random.randint(0, 256, size=num_samples_train)
size_train = np.random.randint(1, 11, size=num_samples_train)
# 随机生成标签:0代表梨,1代表苹果
labels_train = np.where(size_train * (255 - color_train) > 1275, 1, 0)
# 将颜色和大小合并为特征向量
X_train = np.column_stack((color_train, size_train))
# 生成测试数据集
color_test = np.random.randint(0, 256, size=num_samples_test)
size_test = np.random.randint(1, 11, size=num_samples_test)
labels_test = np.where(size_test * (255 - color_test) > 1275, 1, 0)
X_test = np.column_stack((color_test, size_test))
# 创建KNN分类器
k = 4
knn_classifier = KNeighborsClassifier(n_neighbors=k)
# 训练模型
knn_classifier.fit(X_train, labels_train)
# 测试模型
accuracy = knn_classifier.score(X_test, labels_test)
print("模型在测试数据集上的准确率:", accuracy)
# 画出可视化统计图
# 绘制训练数据集
plt.figure(figsize=(10, 6))
plt.scatter(color_train[labels_train == 0], size_train[labels_train == 0], color='red', label='梨')
plt.scatter(color_train[labels_train == 1], size_train[labels_train == 1], color='green', label='苹果')
# 绘制测试数据集
plt.scatter(color_test[labels_test == 0], size_test[labels_test == 0], color='orange', label='梨', marker='x')
plt.scatter(color_test[labels_test == 1], size_test[labels_test == 1], color='blue', label='苹果', marker='x')
plt.xlabel('颜色')
plt.ylabel('大小')
plt.title('苹果和梨的分类')
plt.legend()
plt.grid(True)
plt.show()
分类结果:
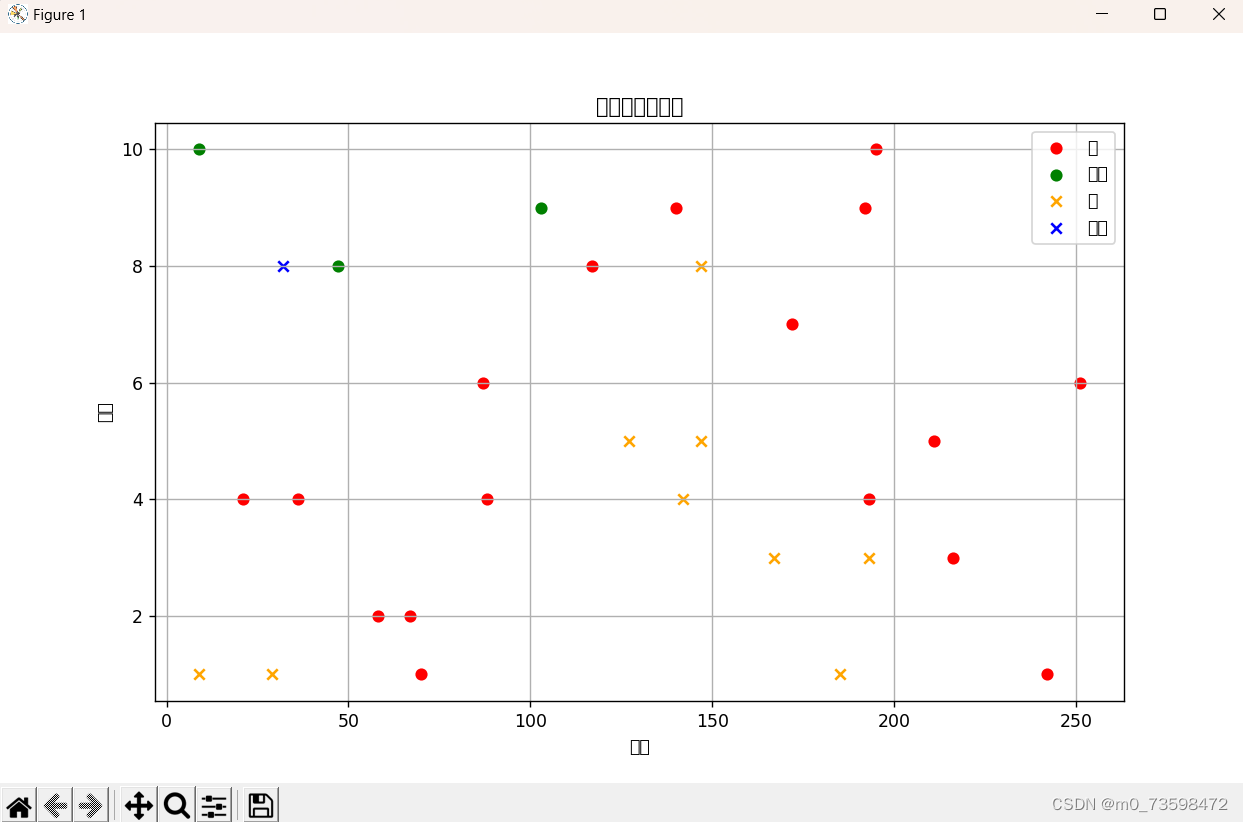 由图可知:
由图可知:
红色圆点是训练集苹果,绿色圆点是梨
黄色叉是检验集苹果,蓝色叉叉是检验集梨
2.分类模型评估指标
当评估机器学习模型时,了解不同评估指标及其适用范围是至关重要的。下面我将更详细地介绍每个指标及其适用范围。
-
准确率(Accuracy):
- 定义:准确率是指模型正确分类的样本数量与总样本数量的比例。
- 适用范围:适用于类别平衡的分类问题,且各个类别的重要性相同的情况下。
-
精确率(Precision):
- 定义:精确率是指模型在预测为正类别的样本中,实际为正类别的比例。
- 适用范围:适用于关注模型预测为正类别的准确性,对于假正例的情况较为敏感。
-
召回率(Recall):
- 定义:召回率是指模型在所有实际正类别样本中,成功预测为正类别的比例。
- 适用范围:适用于关注模型对于正类别的覆盖程度,对于假负例的情况较为敏感。
-
F1 分数(F1 Score):
- 定义:F1 分数是精确率和召回率的调和平均,用于综合考虑模型的准确性和覆盖率。
- 适用范围:特别适用于处理类别不平衡的情况,对于精确率和召回率的平衡较为关注。
-
混淆矩阵(Confusion Matrix):
- 定义:混淆矩阵是一个 N × N 的矩阵,用于可视化模型的分类性能,包括真正例、假正例、真负例和假负例。
- 适用范围:适用于直观地了解模型的分类表现,特别是在多类别分类问题中。
-
AUC-ROC:
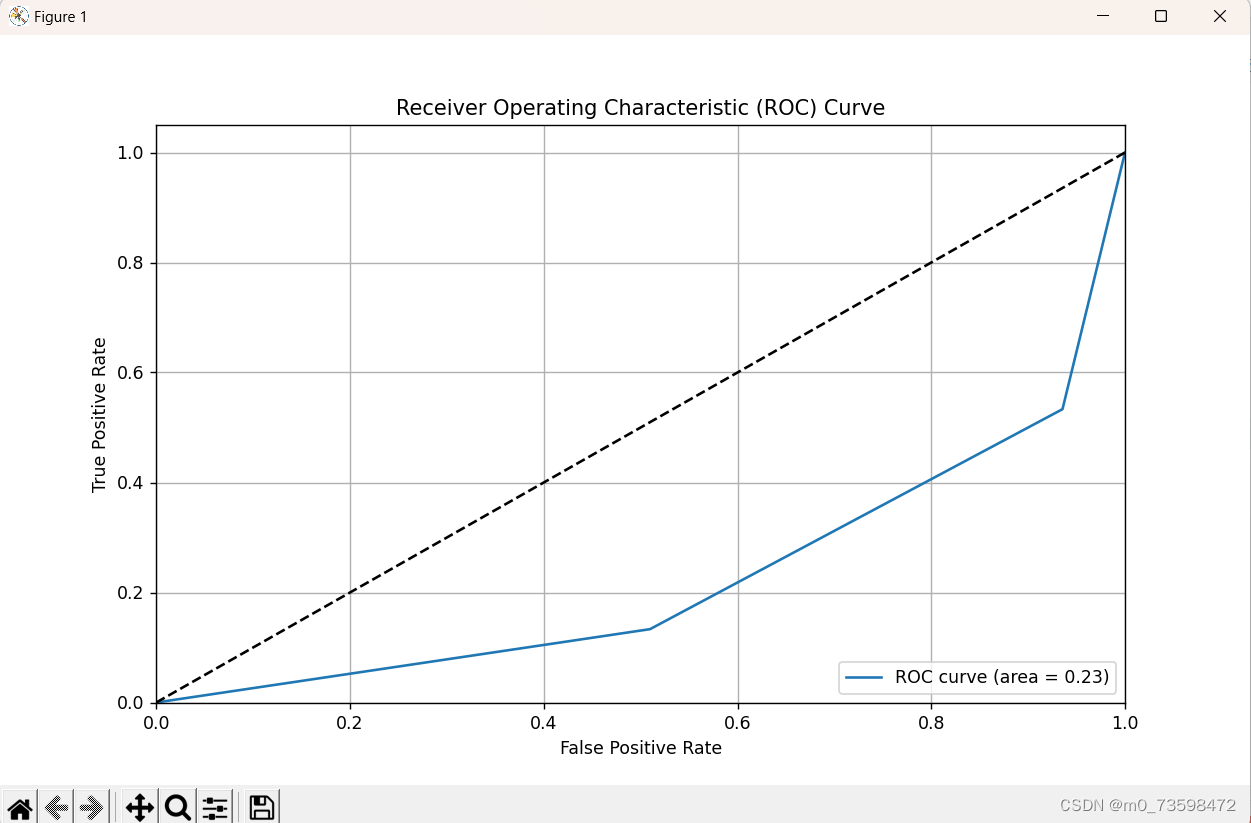
- 定义:ROC 曲线以真正例率(召回率)为纵轴,假正例率为横轴,AUC 表示 ROC 曲线下的面积。
- 适用范围:适用于二分类问题,并且可以衡量模型对于不同阈值的整体性能。
-
AUC-PR:
- 定义:PR 曲线以精确率为纵轴,召回率为横轴,AUC-PR 衡量 PR 曲线下的面积。
- 适用范围:适用于类别不平衡的情况,对于正类别的准确性和覆盖程度均较为关注。
-
平均绝对误差(Mean Absolute Error,MAE):
- 定义:MAE 衡量了模型预测值与真实值之间的平均绝对差。
- 适用范围:适用于回归问题,并且对于异常值不敏感。
-
均方误差(Mean Squared Error,MSE):
- 定义:MSE 衡量了模型预测值与真实值之间的平均平方差。
- 适用范围:适用于回归问题,并且对于异常值更为敏感。
-
R^2(R-Squared):
- 定义:R^2 统计量衡量了模型对于数据的拟合程度,取值范围为 0 到 1。
- 适用范围:适用于回归问题,用于评估模型拟合数据的程度。
结合分析:
数据集特性:不同的数据集和分类任务可能对ROC曲线和PR曲线的形状有不同的影响。例如,在类别不平衡的情况下,PR曲线可能更能反映分类器的性能,因为它更关注正例的预测情况。
模型比较:如果你有多个分类器的结果,可以通过比较它们的ROC曲线、AUC值和PR曲线、平均精确率来评估哪个模型性能更好。通常,这些指标越高,模型性能越好。
阈值选择:ROC曲线和PR曲线还可以帮助你选择合适的分类阈值。根据具体需求(例如,更看重精确率还是召回率),你可以选择曲线上的一个点作为操作点,并确定相应的分类阈值。
实现部分:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import roc_curve, auc
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
# 生成训练数据集和扩充后的测试数据集
np.random.seed(0)
num_samples_train = 20
num_samples_test = 200 # 将测试数据集扩充到200
color_train = np.random.randint(0, 256, size=num_samples_train)
size_train = np.random.randint(1, 11, size=num_samples_train)
labels_train = np.where(size_train * (255 - color_train) > 1275, 1, 0)
X_train = np.column_stack((color_train, size_train))
color_test = np.random.randint(0, 256, size=num_samples_test)
size_test = np.random.randint(1, 11, size=num_samples_test)
labels_test = np.where(size_test * (255 - color_test) > 1275, 1, 0)
X_test = np.column_stack((color_test, size_test))
# 训练KNN模型
k = 4
knn_classifier = KNeighborsClassifier(n_neighbors=k)
knn_classifier.fit(X_train, labels_train)
# 获取测试集的概率估计
y_score = knn_classifier.predict_proba(X_test)
# 将标签二值化
labels_test_binarized = label_binarize(labels_test, classes=[0, 1])
n_classes = labels_test_binarized.shape[1]
# 计算ROC曲线和AUC
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(labels_test_binarized[:, i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# 绘制ROC曲线
plt.figure(figsize=(10, 6))
for i in range(n_classes):
plt.plot(fpr[i], tpr[i], label='ROC curve (area = %0.2f)' % roc_auc[i])
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc="lower right")
plt.grid(True)
plt.show()
ROC曲线:

















 1505
1505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









