







1. 测试 Vector
1.1. 测试代码
#include<vector>
#include<stdexcept>
#include<string>
#include<cstdlib> //abort()
#include<cstdio>
#include<iostream>
#include<ctime>
#include<algorithm>
namespace tvector
{
void test_vector()
{
srand((unsigned int)time(NULL));
long value = 0;
cout << "how many element:";
cin >> value;
cout << "\ntest_vector()............. \n";
vector<string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; i++)
{
try
{
//将后面的内容 即 " " 内的内容写入缓冲区,写入个数10个
snprintf(buf, 10, "%d", rand());
c.push_back(string(buf));
}
catch (exception& p)
{
//当内存溢出时的i
cout << "i =" << i << " " << p.what() << endl;
//abort() 中止程序执行,直接从调用的地方跳出
abort();
}
}
cout << "milli - second : " << (clock() - timeStart) << endl;
cout << "vector.size() = " << c.size() << endl;
cout << "vector.front() = " << c.front() << endl;
cout << "vector.back() = " << c.back() << endl;
cout << "vector.data() = " << c.data() << endl;
cout << "vector.capacity() = " << c.capacity() << endl;
string target = get_a_target_string();
//采用find() 算法
{
timeStart = clock();
//这里的 auto 是迭代器 vector<int>::itertor
auto pItem = ::find(c.begin(), c.end(), target);
cout << "::find(),milli - second : " << (clock() - timeStart) << endl;
if (pItem != c.end())
{
cout << "found," << *pItem << endl;
}
else
{
cout << "not found!" << endl;
}
}
//采用sort() + bsearch()
{
timeStart = clock();
//这里的 auto 是迭代器 vector<int>::itertor
sort(c.begin(), c.end());
string* pItem = (string*)bsearch(&target, c.data(), c.size(), sizeof(string), compareStrings);
cout << "sort() + bsearch(),milli - second : " << (clock() - timeStart) << endl;
if (pItem != NULL)
{
cout << "found," << *pItem << endl;
}
else
{
cout << "not found!" << endl;
}
}
}
}PS:
- 将每个不同的测试模块放在不同的 namespace 下
- 这里是 tvector
- 便于管理,这样也不会出现要将不同的测试放在同一文件,而导致变量名冲突的情况
补充函数
string get_a_target_string()
{
long target = 0;
char buf[10];
cout << "target ( 0 ~" << RAND_MAX << " )" << endl;
cin >> target;
snprintf(buf, 10, "%d", target); //把target的前十位数写入缓冲区
return string(buf);
}
int compareStrings(const void* a, const void* b)
{
if (*(string*)a > *(string*)b)
{
return 1;
}
else if (*(string*)a < *(string*)b)
{
return -1;
}
else
{
return 0;
}
}1.2. 测试结果
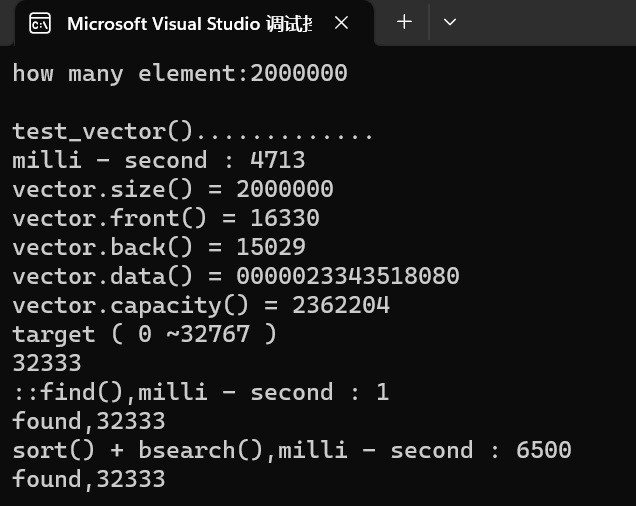
这里可以看到
size 就是我们所输入的大小
而capacity 是他的容量,要大于当前的 size
用两种不同的方法进行查询,其中 find 要快于先排序 后二分查找
由于数据太大了,所以 sort 会很慢,这样效率就会低于 find 了















 1709
1709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









