1. 测试 multiset
1.1. 测试代码
#include<set>
#include<stdexcept>
#include<string>
#include<cstdlib>//abort()
#include<cstdio>
#include<iostream>
#include<ctime>
#include<algorithm>
namespace tmultiset
{
void test_multiset()
{
srand((unsigned int)time(NULL));
long value = 0;
cout << "how many element:";
cin >> value;
cout << "\ntest_multiset()............. \n";
multiset<string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; i++)
{
try
{
//将后面的内容 即 " " 内的内容写入缓冲区,写入个数10个
snprintf(buf, 10, "%d", rand());
c.insert(string(buf));
}
catch (exception& p)
{
//当内存溢出时的i
cout << "i =" << i << " " << p.what() << endl;
//abort() 中止程序执行,直接从调用的地方跳出
abort();
}
}
cout << "milli - second : " << (clock() - timeStart) << endl;
cout << "multiset.size() = " << c.size() << endl;
cout << "multiset.amx_size() = " << c.max_size() << endl;
string target = get_a_target_string();
//采用find() 算法
{
timeStart = clock();
//这里的 auto 是迭代器 vector<int>::itertor
auto pItem = ::find(c.begin(), c.end(), target);
cout << "::find(),milli - second : " << (clock() - timeStart) << endl;
if (pItem != c.end())
{
cout << "found," << *pItem << endl;
}
else
{
cout << "not found!" << endl;
}
}
//c.find()
{
timeStart = clock();
auto pItem = c.find(target);
cout << "c.find(),milli - second : " << (clock() - timeStart) << endl;
if (pItem != c.end())
{
cout << "found," << *pItem << endl;
}
else
{
cout << "not found!" << endl;
}
}
}
}
1.2. 测试结果
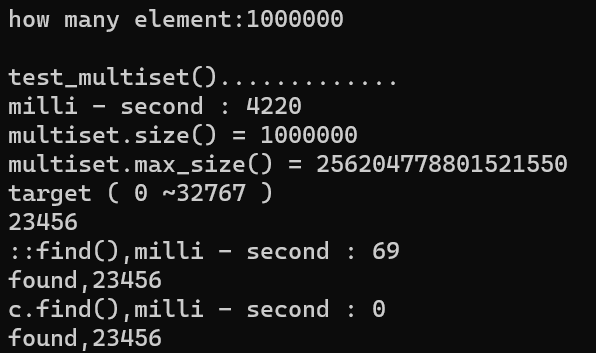
1.3. multiset 解读
-
- multiset 插入元素 insert() 接口
- 数据结构是树,是关联型的,会自动寻找合适位置插入,放进去的时候已经做好排序了
- 由于要排序,所以插入数据耗时长
- 搜索速度快 multiset.find() 的速度明显大于 ::finde(),由于前者对于 multiset 的查找有特殊处理,所以速度要快于泛用的 algorithm 中的 find()
- multiset key可以重复
2. 测试 multimap
2.1. 测试代码
#include<map>
#include<stdexcept>
#include<string>
#include<cstdlib>//abort()
#include<cstdio>
#include<iostream>
#include<ctime>
#include<algorithm>
namespace tmultimap
{
void test_multimap()
{
srand((unsigned int)time(NULL));
long value = 0;
cout << "how many element:";
cin >> value;
cout << "\ntest_multimap()............. \n";
multimap<long,string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; i++)
{
try
{
//将后面的内容 即 " " 内的内容写入缓冲区,写入个数10个
snprintf(buf, 10, "%d", rand());
c.insert(pair<long,string>(i,buf));
}
catch (exception& p)
{
//当内存溢出时的i
cout << "i =" << i << " " << p.what() << endl;
//abort() 中止程序执行,直接从调用的地方跳出
abort();
}
}
cout << "milli - second : " << (clock() - timeStart) << endl;
cout << "multimap.size() = " << c.size() << endl;
cout << "multimap.max_size() = " << c.max_size() << endl;
long target = get_a_target_long();
//c.find()
{
timeStart = clock();
auto pItem = c.find(target);
cout << "c.find(),milli - second : " << (clock() - timeStart) << endl;
if (pItem != c.end())
{
cout << "found," << (*pItem).second << endl;
}
else
{
cout << "not found!" << endl;
}
}
}
}
2.2. 测试结果
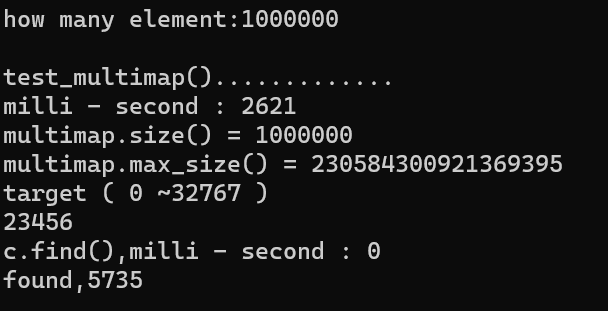
2.3. multimap 解读
-
- 由于 map 存放的是键值对,所以要制定两个数据类型,第一个是 key , 第二个是 value
-
- insert 的时候,要插入键值对时 要用 pair<Type_key,Type_value>(key,value) 的形式插入
- multimap key可以重复
- 搜索速度快
- multimap 不可以用下标做 insertion
- 访问 pair 要用 pair.first 或者 pair.second
3. 测试 unordered_mulitiset
3.1. 测试代码
#include<unordered_set>
#include<stdexcept>
#include<string>
#include<cstdlib>//abort()
#include<cstdio>
#include<iostream>
#include<ctime>
#include<algorithm>
namespace tunordermultiset
{
void test_unordered_mulitiset()
{
srand((unsigned int)time(NULL));
long value = 0;
cout << "how many element:";
cin >> value;
cout << "\ntest_unordered_mulitiset()............. \n";
unordered_multiset<string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; i++)
{
try
{
//将后面的内容 即 " " 内的内容写入缓冲区,写入个数10个
snprintf(buf, 10, "%d", rand());
c.insert(string(buf));
}
catch (exception& p)
{
//当内存溢出时的i
cout << "i =" << i << " " << p.what() << endl;
//abort() 中止程序执行,直接从调用的地方跳出
abort();
}
}
cout << "milli - second : " << (clock() - timeStart) << endl;
cout << "unordered_multiset.size() = " << c.size() << endl;
cout << "unordered_multiset.max_size() = " << c.max_size() << endl;
cout << "unordered_multiset.bucket_count() = " << c.bucket_count() << endl;
cout << "unordered_multiset.load_factor() = " << c.load_factor() << endl;
cout << "unordered_multiset.max_load_factor() = " << c.max_load_factor() << endl;
cout << "unordered_multiset.max_bucket_count() = " << c.max_bucket_count() << endl;
for (unsigned i = 1000; i < 1020; i++)
{
cout << "bucket #" << i << " has " << c.bucket_size(i) << "elements." << endl;
}
string target = get_a_target_string();
//采用find() 算法
{
timeStart = clock();
//这里的 auto 是迭代器 vector<int>::itertor
auto pItem = ::find(c.begin(), c.end(), target);
cout << "::find(),milli - second : " << (clock() - timeStart) << endl;
if (pItem != c.end())
{
cout << "found," << *pItem << endl;
}
else
{
cout << "not found!" << endl;
}
}
//c.find()
{
timeStart = clock();
auto pItem = c.find(target);
cout << "c.find(),milli - second : " << (clock() - timeStart) << endl;
if (pItem != c.end())
{
cout << "found," << *pItem << endl;
}
else
{
cout << "not found!" << endl;
}
}
}
}
3.2. 测试结果
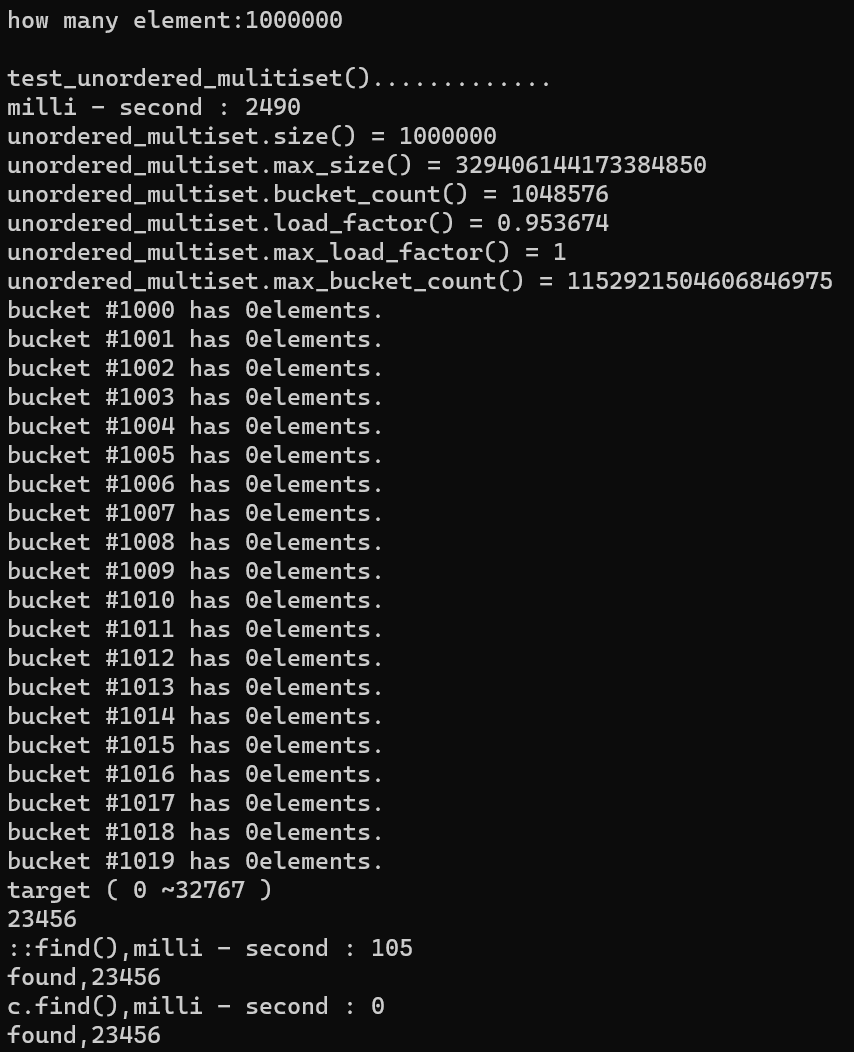
3.3. multiset 解读
- hashtable 实现
- bucket_count() 篮子的数量
- load_factor() 载入因子
- 一个篮子后面的数不能太多,因为定位到每个篮子以后,就要进行遍历,数据太多,遍历数据就慢,所以当篮子后面的数多到一定数量时,就会打乱重新排序
4. 测试 unordered_mulitimap
4.1. 测试代码
#include<unordered_map>
#include<stdexcept>
#include<string>
#include<cstdlib>//abort()
#include<cstdio>
#include<iostream>
#include<ctime>
#include<algorithm>
namespace tunordermultimap
{
void test_unordered_mulitimap()
{
srand((unsigned int)time(NULL));
long value = 0;
cout << "how many element:";
cin >> value;
cout << "\ntest_unordered_mulitimap()............. \n";
unordered_multimap<long,string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; i++)
{
try
{
//将后面的内容 即 " " 内的内容写入缓冲区,写入个数10个
snprintf(buf, 10, "%d", rand());
c.insert(pair<long,string>(i,buf));
}
catch (exception& p)
{
//当内存溢出时的i
cout << "i =" << i << " " << p.what() << endl;
//abort() 中止程序执行,直接从调用的地方跳出
abort();
}
}
cout << "milli - second : " << (clock() - timeStart) << endl;
cout << "unordered_mulitimap.size() = " << c.size() << endl;
cout << "unordered_mulitimap.max_size() = " << c.max_size() << endl;
long target = get_a_target_long();
//c.find()
{
timeStart = clock();
auto pItem = c.find(target);
cout << "c.find(),milli - second : " << (clock() - timeStart) << endl;
if (pItem != c.end())
{
cout << "found, value = " << (*pItem).second << endl;
}
else
{
cout << "not found!" << endl;
}
}
}
}
4.2. 测试结果
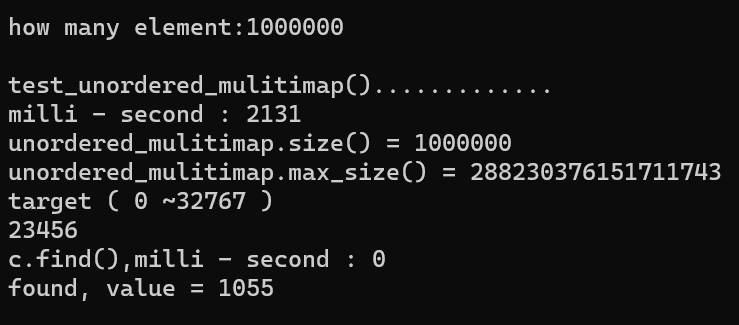
4.3. unordered_mulitimap 解读
- hashtable 实现
- 因为时 k - v 键值对,所以传值要用 pair
5. 测试 set
5.1. 测试代码
#include<set>
#include<stdexcept>
#include<string>
#include<cstdlib>//abort()
#include<cstdio>
#include<iostream>
#include<ctime>
#include<algorithm>
namespace tset
{
void test_set()
{
srand((unsigned int)time(NULL));
long value = 0;
cout << "how many element:";
cin >> value;
cout << "\ntest_set()............. \n";
set<string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; i++)
{
try
{
//将后面的内容 即 " " 内的内容写入缓冲区,写入个数10个
snprintf(buf, 10, "%d", rand());
c.insert(string(buf));
}
catch (exception& p)
{
//当内存溢出时的i
cout << "i =" << i << " " << p.what() << endl;
//abort() 中止程序执行,直接从调用的地方跳出
abort();
}
}
cout << "milli - second : " << (clock() - timeStart) << endl;
cout << "set.size() = " << c.size() << endl;
cout << "set.max_size() = " << c.max_size() << endl;
string target = get_a_target_string();
//采用find() 算法
{
timeStart = clock();
//这里的 auto 是迭代器 vector<int>::itertor
auto pItem = ::find(c.begin(), c.end(), target);
cout << "::find(),milli - second : " << (clock() - timeStart) << endl;
if (pItem != c.end())
{
cout << "found," << *pItem << endl;
}
else
{
cout << "not found!" << endl;
}
}
//c.find()
{
timeStart = clock();
auto pItem = c.find(target);
cout << "c.find(),milli - second : " << (clock() - timeStart) << endl;
if (pItem != c.end())
{
cout << "found," << *pItem << endl;
}
else
{
cout << "not found!" << endl;
}
}
}
}
5.2. 测试结果
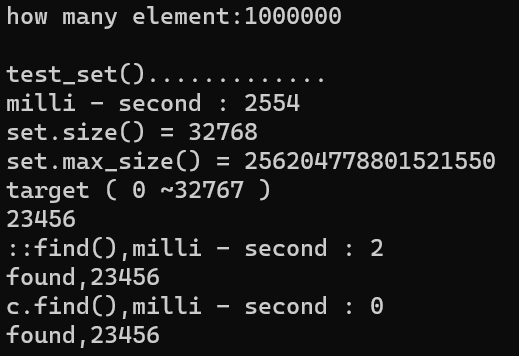
5.3. set 解读
- set 的 key 不能重复
- rand 函数返回从0 到 RAND_MAX (32767)
- 由于样本是1000000,样本大,所以每个数都会被随机到
- 所以这里的 size 是 32768
6. 测试 map
6.1. 测试代码
#include<map>
#include<stdexcept>
#include<string>
#include<cstdlib> //abort()
#include<cstdio>
#include<iostream>
#include<ctime>
#include<algorithm>
namespace tmap
{
void test_map()
{
srand((unsigned int)time(NULL));
long value = 0;
cout << "how many element:";
cin >> value;
cout << "\ntest_map()............. \n";
map<long, string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; i++)
{
try
{
//将后面的内容 即 " " 内的内容写入缓冲区,写入个数10个
snprintf(buf, 10, "%d", rand());
//c.insert(pair<long, string>(i, buf));
c[i] = string(buf);
}
catch (exception& p)
{
//当内存溢出时的i
cout << "i =" << i << " " << p.what() << endl;
//abort() 中止程序执行,直接从调用的地方跳出
abort();
}
}
cout << "milli - second : " << (clock() - timeStart) << endl;
cout << "map.size() = " << c.size() << endl;
cout << "map.max_size() = " << c.max_size() << endl;
long target = get_a_target_long();
//c.find()
{
timeStart = clock();
auto pItem = c.find(target);
cout << "c.find(),milli - second : " << (clock() - timeStart) << endl;
if (pItem != c.end())
{
cout << "found," << (*pItem).second << endl;
}
else
{
cout << "not found!" << endl;
}
}
}
}
6.2. 测试结果
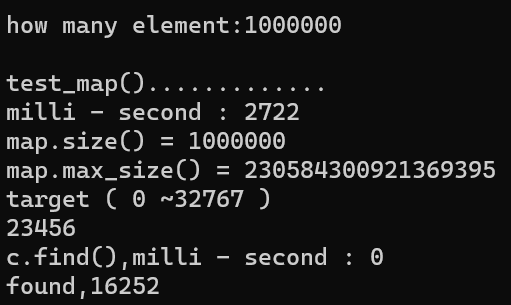
6.3. map 解读
- map 的 key 不能重复
- 由于这里的 key 的值是 i,所以 size 有 1000000,而 set 存放的就是 key 而不是 value,所以会重复
- map 不同于 multimap
- multimap 可以存放相同的 key,所以不能用 [] 访问
- 而 map 可以,所以赋值的时候 可以用

7. 测试 unordered_set
7.1. 测试代码
#include<unordered_set>
#include<stdexcept>
#include<string>
#include<cstdlib>//abort()
#include<cstdio>
#include<iostream>
#include<ctime>
#include<algorithm>
namespace tunorderedset
{
void test_unordered_set()
{
srand((unsigned int)time(NULL));
long value = 0;
cout << "how many element:";
cin >> value;
cout << "\ntest_unordered_set()............. \n";
unordered_set<string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; i++)
{
try
{
//将后面的内容 即 " " 内的内容写入缓冲区,写入个数10个
snprintf(buf, 10, "%d", rand());
c.insert(string(buf));
}
catch (exception& p)
{
//当内存溢出时的i
cout << "i =" << i << " " << p.what() << endl;
//abort() 中止程序执行,直接从调用的地方跳出
abort();
}
}
cout << "milli - second : " << (clock() - timeStart) << endl;
cout << "unordered_set.size() = " << c.size() << endl;
cout << "unordered_set.max_size() = " << c.max_size() << endl;
cout << "unordered_set.bucket_count() = " << c.bucket_count() << endl;
cout << "unordered_set.load_factor() = " << c.load_factor() << endl;
cout << "unordered_set.max_load_factor() = " << c.max_load_factor() << endl;
cout << "unordered_set.max_bucket_count() = " << c.max_bucket_count() << endl;
for (unsigned i = 1000; i < 1020; i++)
{
cout << "bucket #" << i << " has " << c.bucket_size(i) << "elements." << endl;
}
string target = get_a_target_string();
//采用find() 算法
{
timeStart = clock();
//这里的 auto 是迭代器 vector<int>::itertor
auto pItem = ::find(c.begin(), c.end(), target);
cout << "::find(),milli - second : " << (clock() - timeStart) << endl;
if (pItem != c.end())
{
cout << "found," << *pItem << endl;
}
else
{
cout << "not found!" << endl;
}
}
//c.find()
{
timeStart = clock();
auto pItem = c.find(target);
cout << "c.find(),milli - second : " << (clock() - timeStart) << endl;
if (pItem != c.end())
{
cout << "found," << *pItem << endl;
}
else
{
cout << "not found!" << endl;
}
}
}
}
7.2. 测试结果
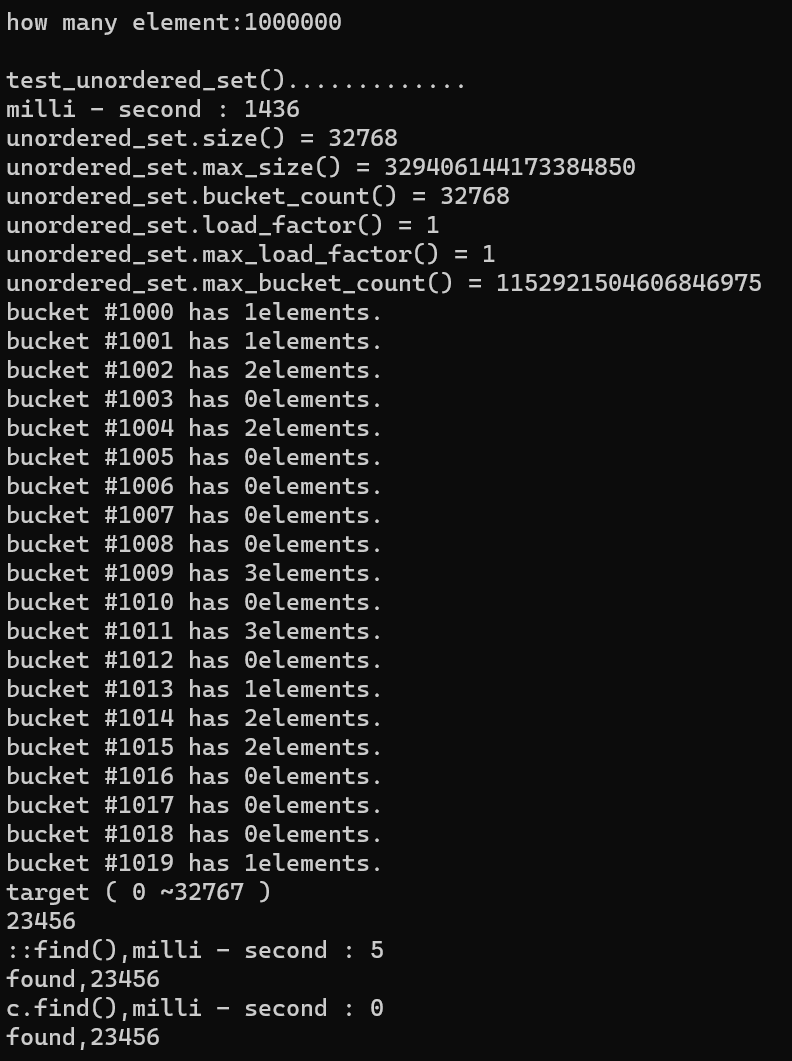
7.3. unordered_set 解读
- 与 set 类似,区别是 unordered_set 用 hashtable 实现
8. 测试 unordered_map
8.1. 测试代码
#include<unordered_map>
#include<stdexcept>
#include<string>
#include<cstdlib>//abort()
#include<cstdio>
#include<iostream>
#include<ctime>
#include<algorithm>
namespace tunorderedmap
{
void test_unordered_map()
{
srand((unsigned int)time(NULL));
long value = 0;
cout << "how many element:";
cin >> value;
cout << "\ntest_unordered_map()............. \n";
unordered_map<long, string> c;
char buf[10];
clock_t timeStart = clock();
for (long i = 0; i < value; i++)
{
try
{
//将后面的内容 即 " " 内的内容写入缓冲区,写入个数10个
snprintf(buf, 10, "%d", rand());
c.insert(pair<long, string>(i, buf));
}
catch (exception& p)
{
//当内存溢出时的i
cout << "i =" << i << " " << p.what() << endl;
//abort() 中止程序执行,直接从调用的地方跳出
abort();
}
}
cout << "milli - second : " << (clock() - timeStart) << endl;
cout << "unordered_map.size() = " << c.size() << endl;
cout << "unordered_map.max_size() = " << c.max_size() << endl;
long target = get_a_target_long();
//c.find()
{
timeStart = clock();
auto pItem = c.find(target);
cout << "c.find(),milli - second : " << (clock() - timeStart) << endl;
if (pItem != c.end())
{
cout << "found," << (*pItem).second << endl;
}
else
{
cout << "not found!" << endl;
}
}
}
}
8.2. 测试结果
8.3. unordered_map 解读
- 与 map 类似,区别是 unordered_map 用 hashtable 实现


























 963
963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









