







目录
一、包装类
在 Java 中,由于基本类型不是继承自 Object 类,为了在泛型代码中可以支持基本类型,Java 给每个基本类型都对应了一个包装类型。
1.1 基本数据类型和对应的包装类
| 基本数据类型 | 包装类 |
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Character |
| boolean | Boolean |
由此可以看出,除了 Integer 和 Character, 其余基本类型的包装类都是首字母大写。
1.2 装箱和拆箱
【介绍】
装箱:新建一个包装类型对象,将基本类型变量的值放入对象的某个属性中。
拆箱:将包装类变量对象中的值取出,放到一个基本数据类型中。
例如下方代码中,我们实现了装箱和拆箱操作:
public static void main(String[] args) {
//装箱
int a = 10;
Integer i = Integer.valueOf(a);
//拆箱
Integer ii = new Integer(10);
int b = ii.intValue();
System.out.println(i); //10
System.out.println(b); //10
}由此可以看出在使用过程中,装箱和拆箱带来不少的代码量,所以为了减少开发者的负担,Java 提供了自动机制。例如:
public static void main(String[] args) {
int a = 10;
Integer i = a;//自动装箱
Integer ii = new Integer(10);
int b = ii;//自动拆箱
System.out.println(i); //10
System.out.println(b); //10
}比对上述两种代码,我们可以明确感受到自动机制给我们节省了很多负担,那自动机制具体是怎么是怎么实现装箱和拆箱操作呢?这需要我们打开 out 目录中生成的字节码文件,进入其终端进行反汇编查看。进入文件夹找到类名.class文件,在其路径中输入 cmd 进入终端。然后输入 javap -c 类名 ,由此即可查看到自动机制是如何实现的。
![]()
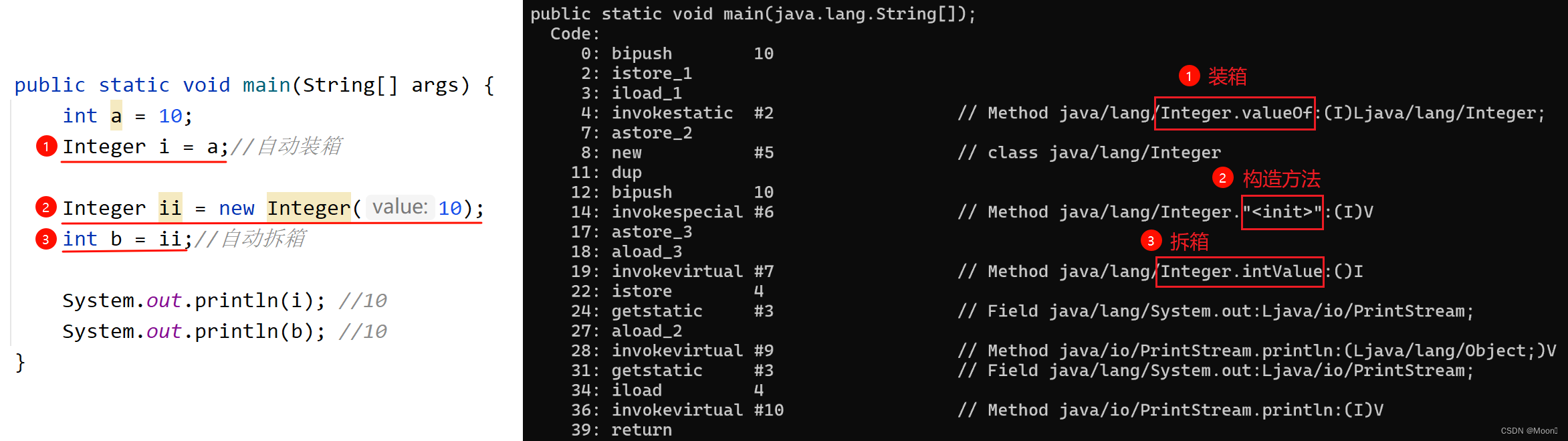 如上图,我们发现自动装箱和拆箱操作中,系统所调用的方法与我们手动装箱和拆箱一模一样, 所以我们由此发现 Java 所提供的自动机制与我们手动装拆箱本质没有任何区别。
如上图,我们发现自动装箱和拆箱操作中,系统所调用的方法与我们手动装箱和拆箱一模一样, 所以我们由此发现 Java 所提供的自动机制与我们手动装拆箱本质没有任何区别。
1.3 拓展
通过我们上述对包装类有了初步的了解,我们来看下方的一段代码:
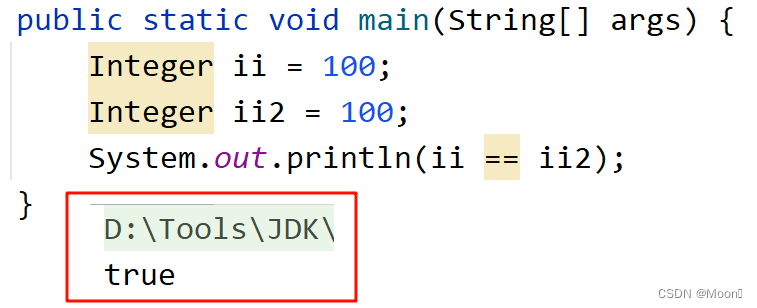
这段代码最后输出结果为 ture,相信大家也都能够理解。但是要是我们将两个变量的值从 100 改为 200,大家是不是还觉得结果为 ture,那真的是这样的吗?我们来试一下。
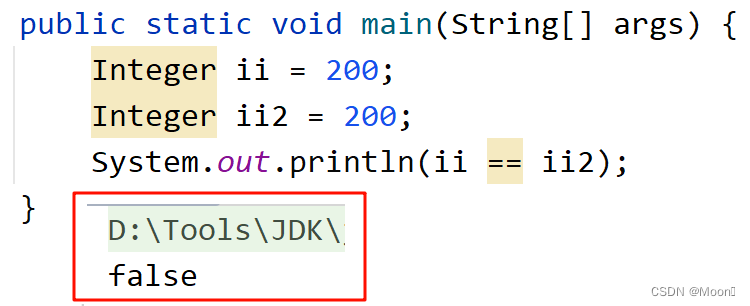
最后我们会发现,变量的值改成 200 后,输出的竟然是 false,这是为什么呢?由上述代码可以看出,两段代码除了值不同,其他都相同,而且它们都只发生了唯一的动作--装箱。同时,装箱也只调用了 valueOf() 方法,那我们来看看 valueOf 方法究竟是怎么实现的呢?首先我们进入 Integer 类的源码。

找到 Integer 类中的 valueOf() 方法,我们发现其中变量 i 被限制在一个范围内,边界为 low 和 high,而如果在范围内,返回值是 cache 数组中的元素;若不在范围内,则会返回一个新对象。那我们可以找找 Integer 类中 low 和 high 的取值。
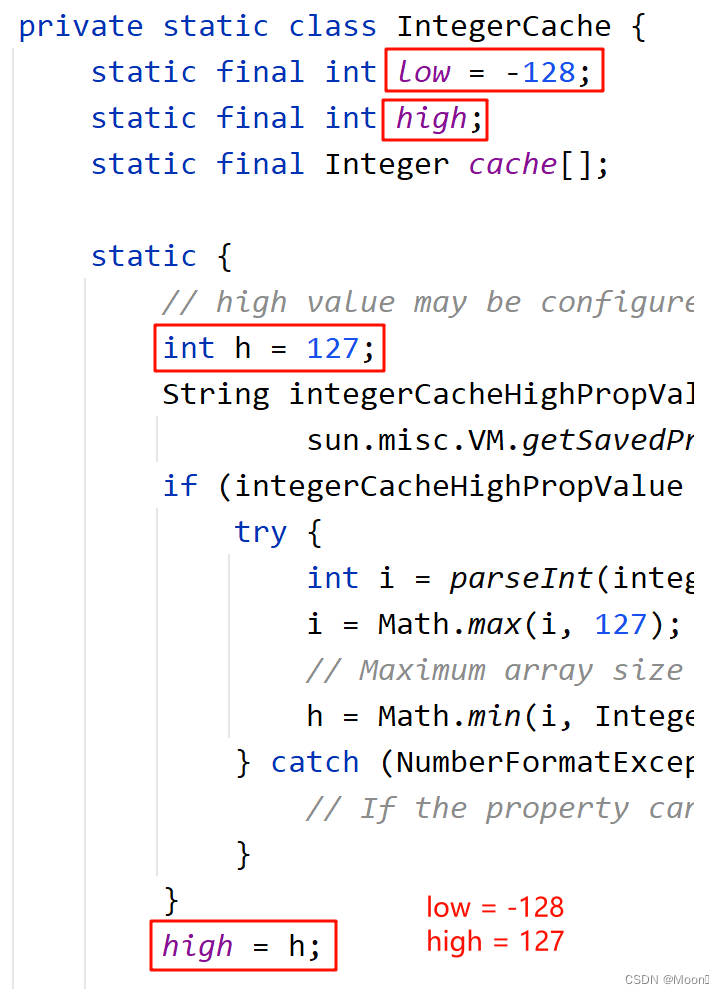
由上图可以看出,low 和 high 的值分别为 -128 和 127。那就是说只有在 -128 <= i <= 127 的情况下,才会返回 cache 数组中的元素。此时我们将 low 和 high 的值带入数组下标算式中看看 cache 数组的大小。
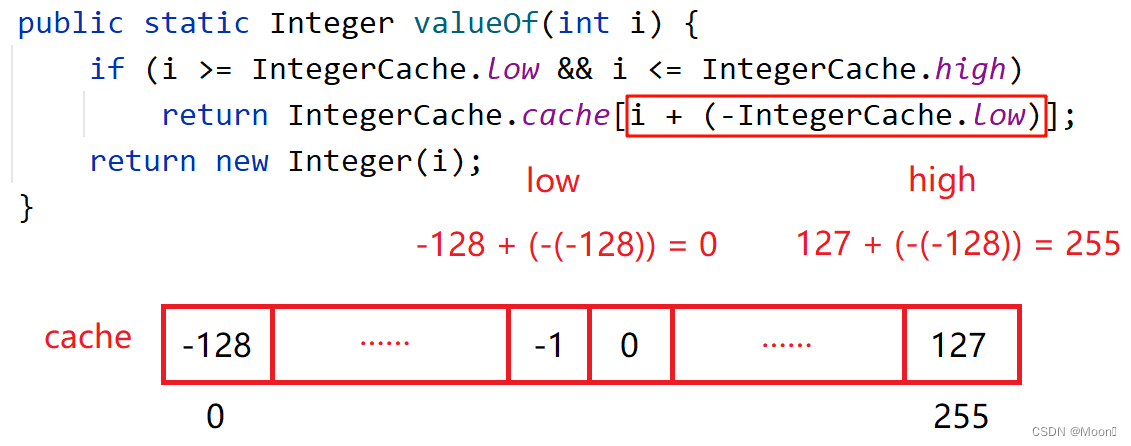
我们可以发现,low 和 high 的下标分别为 0 和 255,即 cache 中含有 256 个元素。这也就说明了上述两段代码为何输出不一样,就是因为值为 100 时,可以在 cache 数组中找到该元素,两个引用指向同一个对象,自然输出 true;而值为 200 时,数组中并没有该元素,两次引用都会产生新对象,自然就输出 false。
【装拆箱总结】
1、在进行装箱和拆箱操作时,我们可以利用 Java 所提供的自动机制,快速完成装拆箱操作。
2、在装箱时,变量只能装成自己的包装类;而拆箱时,想拆成什么类型就拆成什么类型。
3、装箱时利用 包装类型.valueOf(基本类型变量) 来装箱;拆箱时利用 包装类型变量.基本类型+Value() 来拆箱。其中基本类型根据自身需求来编写,例如想拆成 double 类型,即 变量.doubleValue()。
【泛型前言】
一般的类和方法,只能使用具体的类型:要么是基本类型,要么是自定义的类。如果要编写可以应用于多种类型的代码,这种刻板的限制对代码的束缚就会很大。----- 来源《Java编程思想》对泛型的介绍。
二、泛型
通俗点讲,泛型就是适用于许多许多类型。从代码上讲,就是对类型实现了参数化。
2.1 引出泛型
要求:
实现一个类,类中包含一个数组成员,使得数组中可以存放任何类型的数据,也可以根据成员方法返回数组中某个下标的值。
思路:
1、我们以前学过的数组,只能存放指定类型的元素,例如:int[] array = new int[10]。
2、Object 类是所有类的父类,那数组是否可以创建为 Object 类型?
有了思路以后,我们就写出了一段代码:
class MyArray {
public Object[] array = new Object[10];
public void setValue(int pos, Object val) {
array[pos] = val;
}
public Object getValue(int pos) {
return array[pos];
}
}既然数组中可以存放任何类型的数据,那我们是不是可以同时放两种类型的数据?

当然不能同时放两种类型的数据,如果非要放入两种类型的数据,那访问数组元素时就会发现系统报错。

此时我们发现 getValue() 的返回值为 Object 类型,子类类型要接收父类类型我们需要强转元素类型。但原来就是 String 类的数据,还要再强转为 String 类,这不是多此一举吗?
虽然在这种情况下,当前数组任何数据都可以存放,但是,更多情况下,我们还是希望他只能够持有一种数据类型,而不是同时持有这么多类型。所以,泛型的主要目的:就是指定当前的容器,要持有什么类型的对象,让编译器去做检查。我们所要的是:指定 int 类型时,数组中全放入 int 类型的数据;若是 String 类型,数组中全放入 String 类型的数据。此时,就需要把类型作为参数传递。需要什么类型,就传入什么类型。
2.2 泛型的语法及使用
【泛型类语法】
class 泛型类名称<类型形参列表> {
//可以使用类型参数
}
class ClassName<T1, T2, ..., Tn> {
}
class 泛型类名称<类型形参列表> extends 继承类/* 可以使用类型参数 */ {
//可以使用类型参数
}
class ClassName<T1, T2, ..., Tn> extends ParentClass<T1> {
//可以只使用部分类型参数
}
了解泛型类的语法后,我们来改写一下上文中的 MyArray 类:
class MyArray<T> { //加上了 <T>,表示当前类是一个泛型类
public T[] array = (T[])new Object[10]; //由于不能直接实例化泛型类型数组,
//故实例化 Object类型数组后强转骗过编译器
public void setValue(int pos, T val) { // val的类型改为 T
array[pos] = val;
}
public T getValue(int pos) { //返回值变为 T
return array[pos];
}
}上述代码中,<T> 代表占位符,表示当前类是一个泛型类,T 即 Type,常用的还有 E,即 Element。
【泛型使用语法】
泛型类<类型实参> 变量名; // 定义一个泛型类引用
new 泛型类<类型实参>(构造方法实参); // 实例化一个泛型类对象
例如:MyArray<Integer> myArray = new MyArray<Integer>();
【注意事项】
1、泛型只能接受类,所有的基本数据类型必须使用包装类。
2、当编译器可以根据上下文推导出类型实参时,可以省略类型实参的填写。例如:MyArray<Integer> list = new MyArray<>(); // 可以推导出实例化需要的类型实参为 Integer
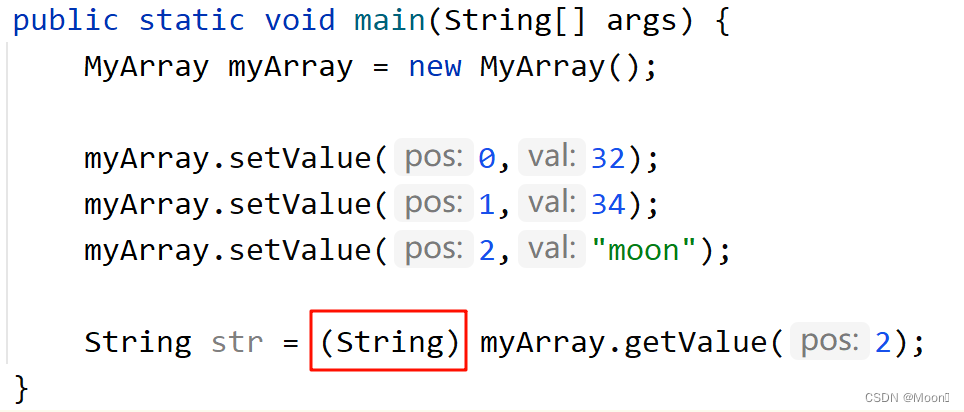
学会使用泛型后,我们尝试创建两个数组对象,分别存放 String 类型和 int 类型的数据:
public static void main(String[] args) {
//new 一次就有一个新数组
//<String> 意味着 myArray 数组中只能存放 String 类型的元素
MyArray<String> myArray = new MyArray<>();
myArray.setValue(0,"hello");
myArray.setValue(1,"world");
myArray.setValue(2,"moon");
String str = myArray.getValue(2);
System.out.println(str); //moon
// <Integer>
MyArray<Integer> myArray2 = new MyArray<>();
myArray2.setValue(0,99);
myArray2.setValue(1,20);
int val = myArray2.getValue(0);
System.out.println(val); //99
}我们发现成功实现了一个类中有一个数组成员可以存放任何类型的数据,需要何种类型,只需在类名后的 <> 中输入指定数据类型,但不能是基本数据类型,只能是引用类型。由此我们初步认识了泛型的语法,其实泛型的意义就是在编译的时候检查数据类型是否正确以及帮助我们进行类型转化。
2.3 泛型是如何编译的
2.3.1 擦除机制
泛型是存在于编译时期的一种机制,我们把这种机制叫做擦除机制。那我们该怎么理解擦除机制呢?就是在编译的过程当中,将所有的 T 替换为 Object 这种机制,我们称为擦除机制。我们通过 javap -c 命令查看字节码文件,就会发现所有的 T 都变成了 Object。
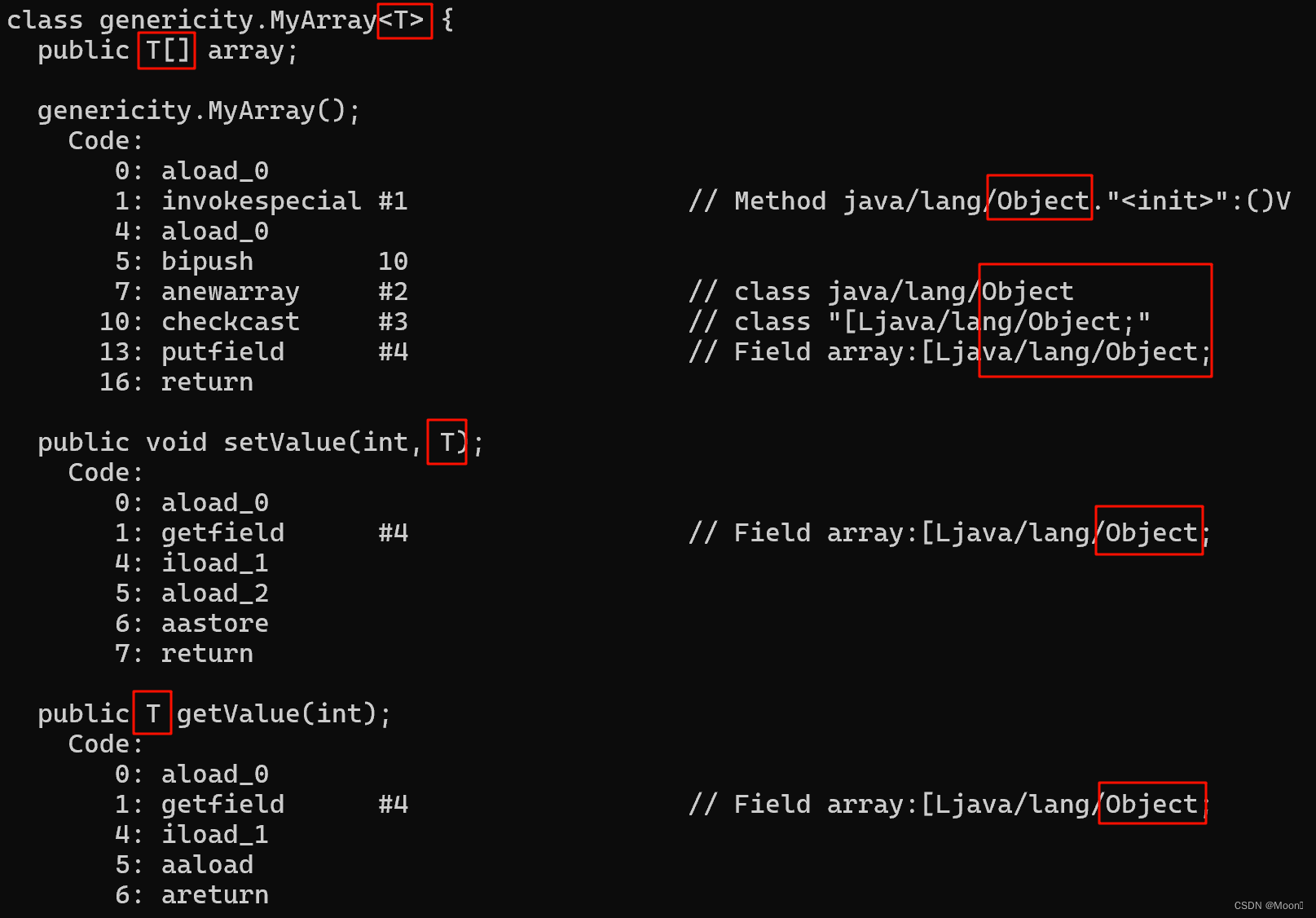
那既然编译的时候,T 会替换为 Object,那 T[] t = new T[5]; 不是相当于 Object[] t = new Object[5]; 吗,那为什么 T[] t = new T[5]; 是不对的呢?我们来举个例子。
class MyArray<T> {
public T[] array = (T[])new Object[10];
public T[] getArray() {
return array; //返回T类型的数组
}
}
public class Main {
public static void main(String[] args) {
//定义一个String类型的数组
MyArray<String> myArray = new MyArray<>();
//用String类型的ret来接收T类型的数组
String[] ret = myArray.getArray();
}
}上述代码中 T[] 类型即 String[] 类型,使用 String[] 类型的 ret 来接收 T[] 类型的数组,从实例化到返回再到接收,似乎都没有任何问题。但是在运行程序时,就会发生类型转换异常。

这是为什么呢?上文说到,编译时所有的 T 都会被替换成 Object,那么就意味着 getArray() 的返回值其实是 Object[] 类型的数组,那将 Object[] 类型的数组交给 String[] 类型的 ret 接收,自然是不行的。那我们试试将返回的数组进行一下强转:
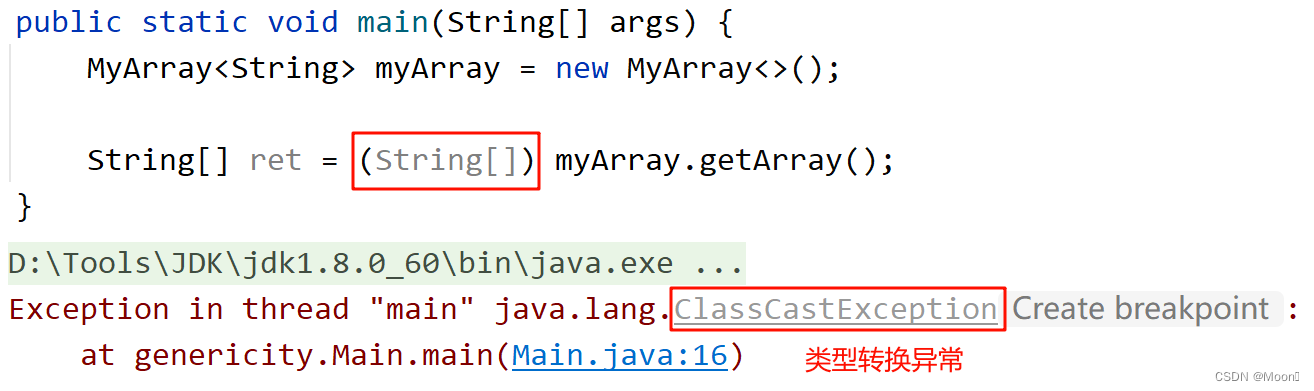
尽管强转返回的数组,还是会发生类型转换异常。这是因为返回的数组被替换成 Object[] 类型的数组后,里面就可以放入任何类型的元素,这就说明并不是数组中所有的元素都可以强转为 String[] 类型,所以才会报错。并且对于 Java 来说,不支持数组的整体强转。这时只有将接收的 ret 改为 Object[] 类型,才可以正常接收。

综上所述,我们知道了为什么不能实例化泛型类型数组,那上文 MyArray 类中的数组实例化就足够好吗?其实未必,上文中的 public T [] array = (T[])new Object[10]; 只是骗过了编译器,那我们来进行最后的改进。
class MyArray<T> {
// public T[] array = new T[10]; //不能实例化一个泛型类型的数组
// public T[] array = (T[])new Object[10]; //骗过编译器
public Object[] array = new Object[10];
public void setValue(int pos, T val) {
array[pos] = val;
}
public T getValue(int pos) {
return (T) array[pos];
}
}事实上,实例化一个泛型数组应该写为:public Object[] array = new Object[10];,返回值为 T 的方法,只需给返回值强制转换为 T 类型即可。
【泛型语法总结】
1、<T> 代表占位符,表示当前类是一个泛型类。
2、<> 中输入指定类型,不能是基本数据类型。
3、在泛型类中:
(1)实例化泛型数组应写为:public Object[] 数组名 = new Object[数组大小]; 。
(2)放入元素时,应放入 T 类型的元素。
(3)返回元素时,应给返回值强制转换为 T 类型。
2.4 泛型的上界
在定义泛型类时,有时需要对传入的类型变量做一定的约束,可以通过类型边界来约束。
【语法】
class 泛型类名称<类型形参 extends 类型边界> {
……
}
例如:
public class MyArray<E extends Number> {
……
}
<> 中 E extends Number 意思是:只接受 Number 的子类型作为 E 的类型实参,即 E 一定是 Number 或 Number 的子类。
2.5 泛型方法
【语法】
方法限定符 <类型形参列表> 返回值类型 方法名称(形参列表) {
……
}
例如:
public class Test {
//静态的泛型方法 需要在static后用<>声明泛型类型参数
public static <E> void swap(E[] array, int i, int j) {
E temp = array[i];
array[i] = array[j];
array[j] = temp;
}
}总结
1、除了 Integer 和 Character, 其余基本类型的包装类都是首字母大写。
2、泛型只能接受类,所有的基本数据类型必须使用包装类。
3、泛型的意义就是在编译的时候检查数据类型是否正确以及帮助我们进行类型转化。
4、<T> 代表占位符,表示当前类是一个泛型类。
5、<> 中输入指定类型,不能是基本数据类型。















 213
213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









