







一、实验目的与实验环境
实验目的:熟练运用Python列表、字典、集合、数组等数据结构以及索引和切片等查询操作解决实际问题,熟练掌握Python读写文本文件的方法,熟练使用Python数据分析库函数,通过完成kaggle泰坦尼克之灾这个数据分析的入门项目,即“给出泰坦尼克号上的乘客的信息,预测乘客是否幸存”进行一个简单的数据分析。作为新手初步了解完成一个数据分析项目于的具体流程和实现方式,初步了解机器学习的数据分析。
实验环境: (1)编译器:Jupyter
(2)python版本:3.9
二、实验内容与实验步骤
实验内容:本实验主要以泰坦尼克沉船船员获救预测为背景,通过让学生使用numpy,pandas等python库完成数据读取。并通过让学生使用matplotlib库和seaborn完成数据的可视化分析,在此基础上,通过让学生利用scikit-learn中的工具建立二分类模型(根据与Survived相关的特征判断乘客Survived or not Survived)完成对船员获救情况预测问题的求解,并在测试数据集上对预测结果进行分析。学生在完成分析任务设计过程中可以单纯使用某一算法,也可以融合多种算法以提升预测结果的准确性。
实验步骤:
(1)项目背景问题理解
(2)数据初步探索
(3)缺失值观察
(4)特征分析
(5)特征工程
(6)模型对比
三、实验过程与分析
3.1项目背景
泰坦尼克号:是当时世界上体积最庞大,内部设施最豪华的客运轮船,于1990年3月31日动工建造,1912年4月2日完工试航。于1912年4月10日,在南安普敦港的海洋码头,启程驶往纽约,开始了它的第一次,也是最后一次的航行。泰坦尼克号将乘客分为三个等级:三等舱位于船身较下层也最便宜;二等舱具备与当时其他一般船只的头等舱同样的等级,许多二等舱的乘客原先在其他船只上预定的头等舱,却因为泰坦尼克号的航行,将煤炭能源转移给泰坦尼克号;一等舱是整艘船最为昂贵奢华的部分。
船上时间为1912年4月14日23时40分左右,泰坦尼克号与一座冰山相撞,造成水密舱进水,次日凌晨2时20分左右沉没。2224名船员和乘客中1502人遇难,造成如此巨大的伤亡原因之一是船上没有足够的救生艇供乘客和船员使用,在这次灾难中能否幸存下来难免会有些运气成分,但是有些人比其他人更可能生存下来,比如妇女,儿童和上层阶级。本实验用二分类模型来进行泰坦尼克号乘客生存预测。
3.2 数据初步探索
3.2.1 导入初步的库
首先先导入所需要的库。(后期在不断的补充,由于以下使用的某些库和函数与机器学习相关,较为重要。在本文章中只做简要介绍)
seaborn:可视化库,对matplotlib进行二次封装而来,优于matplotlib
ydata_profiling库:可快速预览数据,生成详细数据报告。
scikit-learn:简称sklearn,机器学习库,建立在numpy,pandas,scipy等数据科学库之上。
from sklearn.ensemble import RandomForestRegressor 随机森林
metrics:sklearn库下度量指标模块。 preprocessing:sklearn库下数据预处理模块
linear_model:线性模型
LabeEencoder:函数,将类别数据数字化,给各种标签一个可数的连续编号。
Logisticregression:逻辑回归,解决二分类问题(0 or 1)的机器学习算法。
warnings.simplefilter(‘ignore’):控制警告输出。
3.2.2 数据来源
Kaggle上即为本项目提供了两份数据:train.csv文件作为训练集构建与生存相关的模型;test.csv文件则用作测试集,用我们构建出的模型预测生存状况。
Kaggle: Your Home for Data Science
3.2.3 读取数据(以训练集为例介绍)
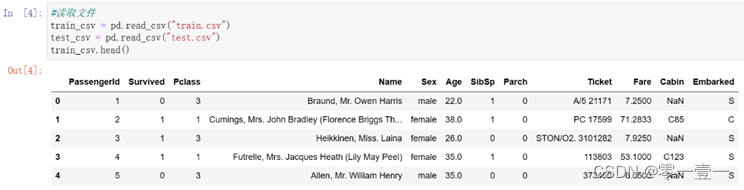
- PassengerID—ID,具有唯一标识的作用,一个人员对应一个ID
- Survived -- 是否幸存,1表示是,0则表示否
- Pclass -- 船舱等级,1:一等舱,2:二等舱,3:三等舱(较为重要)
- Name -- 姓名(可提取出更多信息)
- Sex -- 性别,female女性,male男性(较为重要)
- Age -- 年龄(较为重要)
- SibSp – 旁系亲友
- Parch – 直系亲友
- Ticket -- 船票
- Fare -- 票价
- Cabin -- 舱位
- Embarked -- 登船港口编号
3.3 缺失值观察
我们拿到的数据通常是不干净的,所谓的不干净,就是数据中有缺失值,有一些异常点等,需要经过一定的处理才能做后面的分析和建模,所以拿到数据的第一步是进行数据清洗。
3.3.1 查看数据表整体信息
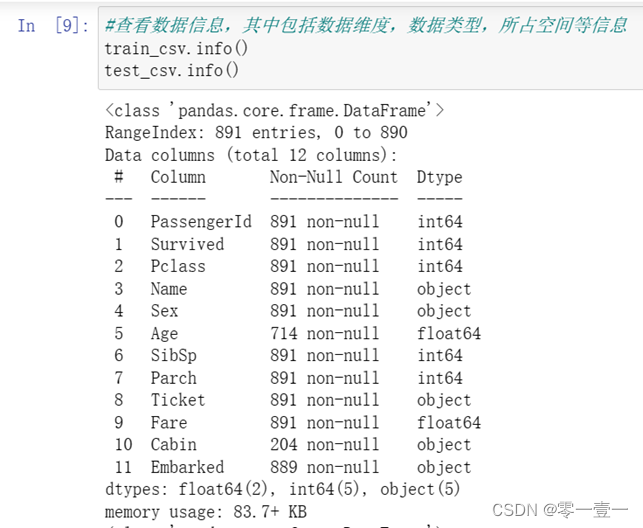
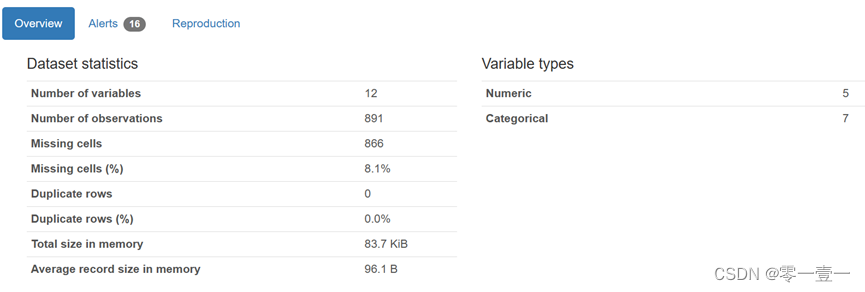
可知:训练集中数据维度:891行ⅹ12列
缺失字段:Age,Cabin,Embarked
数据类型:2个64位浮点型,5个64位整型,5个python对象。
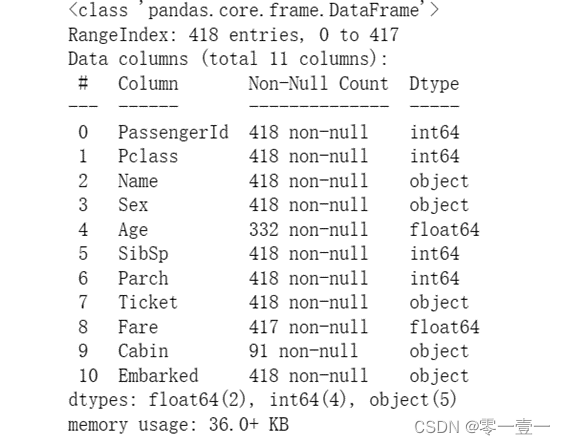
可知:测试集中数据维度:418行ⅹ11列
缺失字段:Age,Fare,Cabin
数据类型:2个64位浮点型,4个64位整型,5个python对象。
根据上述结果和题目初步整理数据到表格如下图:
| 数据 | 训练集train.csv | 测试集test.csv |
| PassengerId 乘客ID | 唯一标识,共891个 | 唯一标识,共418个 |
| Survived 幸存状况 | 0遇难,1幸存,无缺失值 | 最后预测对象,无本项数据 |
| Pclass 船舱等级 | 1:一等舱,2:二等舱,3:三等舱,无缺失值 | 1:一等舱,2:二等舱,3:三等舱,无缺失值 |
| Name 名字 | 无缺失值 | 无缺失值 |
| Sex 性别 | 无缺失值 | 无缺失值 |
| Age 年龄 | 共714个,有缺失值 | 共332个,有缺失值 |
| SibSp 兄妹,配偶等 | 无缺失值 | 无缺失值 |
| Parch 父母,子女等 | 无缺失值 | 无缺失值 |
| Ticket 船票编号 | 无缺失值 | 无缺失值 |
| Fare 船票费用 | 无缺失值 | 共417个,有缺失值 |
| Cabin 船舱编号 | 共204个,有缺失值 | 共91个,有缺失值 |
| Embarked登船港口编号 | S,C,Q三个港口,共889个有缺失值 | 无缺失值 |
3.3.2 描述型统计
生成观察训练集的分析报告,通过观察训练集的分析报告可得:
除了python对象以外的数据类型,均参与了计算。
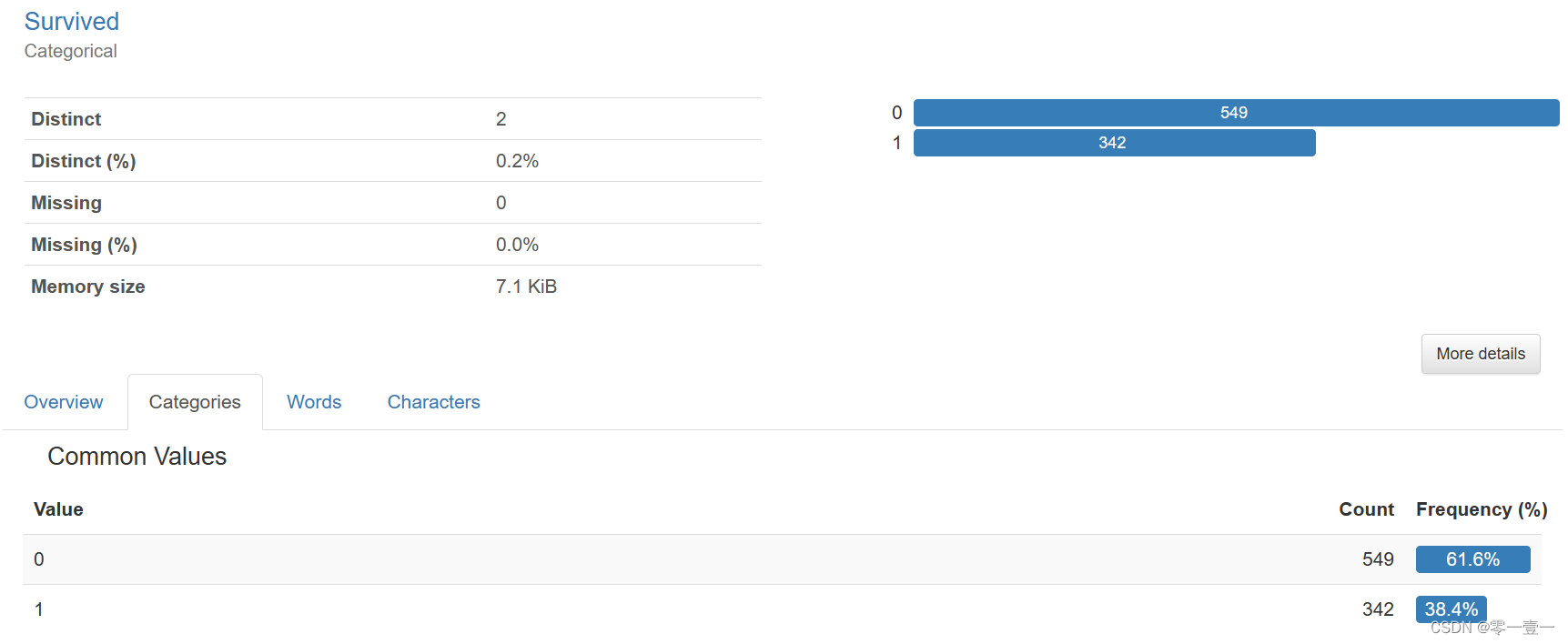
只有38.4%的人幸存,死亡率很高。

年龄现有数据714,缺失占比约为19.9%
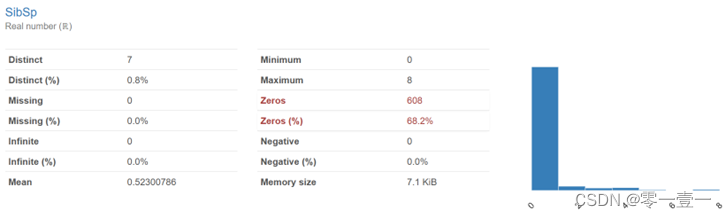

同船同胞兄弟姐妹与配偶人数最大为8,同船父母子女人数最大为6,且两者的最小值都为0,可推断出有大家庭,小家庭(独自一人)之分。
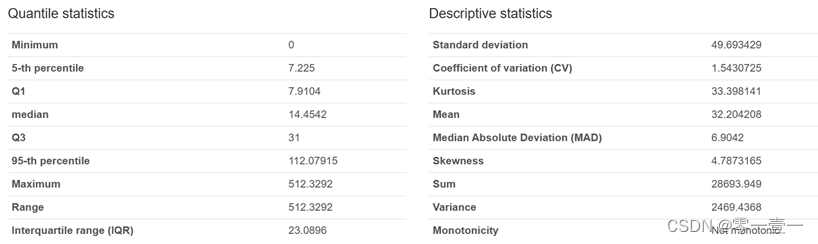
船费最小值为0,最大值为512.3292,均值为32.20420,中位数为14。贫富差距较大。
--以上只显示了数值型变量的基本特征,那与python对象(分类变量)对应的呢?
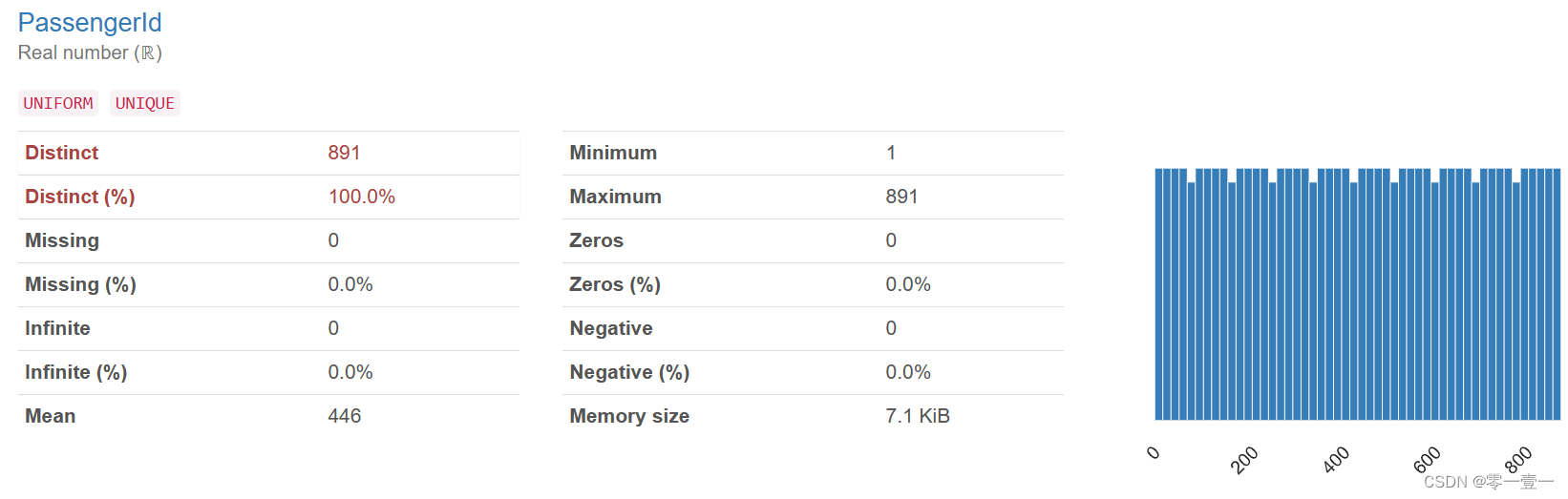
ID是唯一标识。
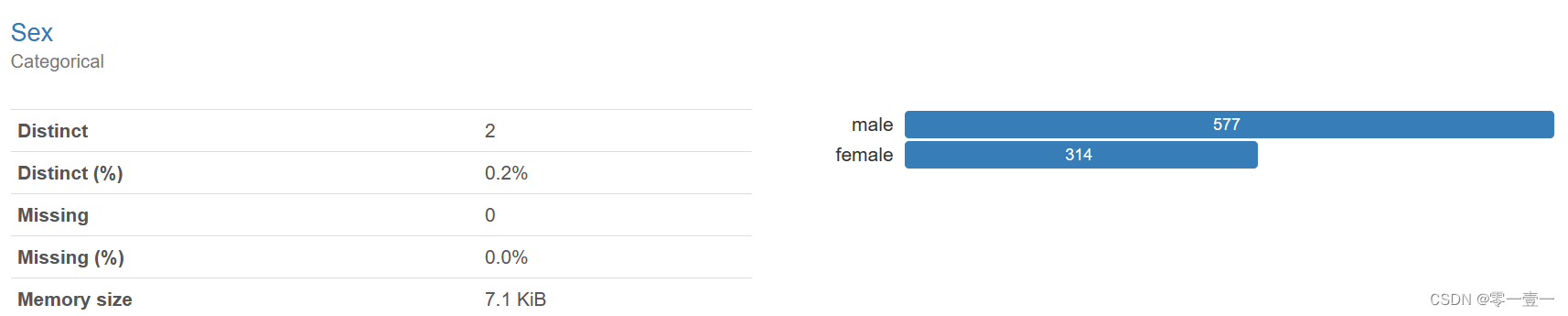
性别中男性最多,达到577人次。
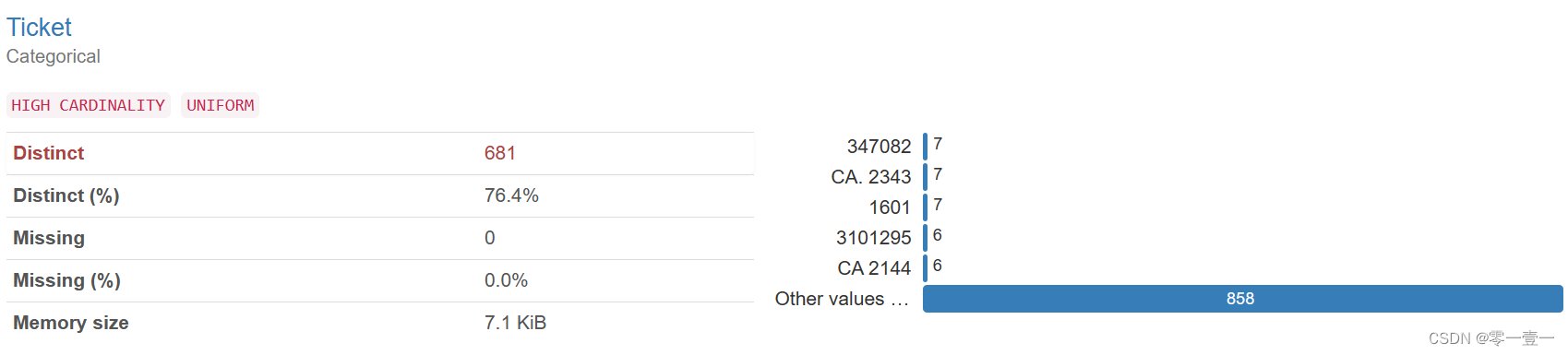
船票只有681种,共计891名乘客,部分乘客共用一张票
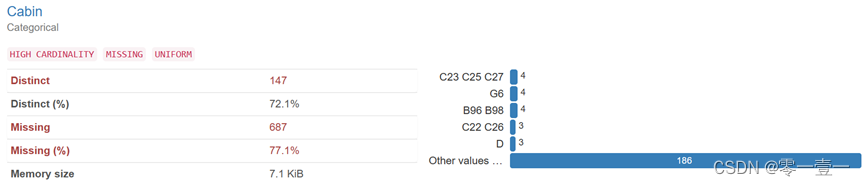
舱位总数204,缺失占比约为77.1%

登船港口共889个,缺失2个,缺失率约为0.2%。其中共有3个类型,S最多,达到644个人次。
--生成训练集中数值型变量的相关性图,这里默认采用皮尔逊相关系数。

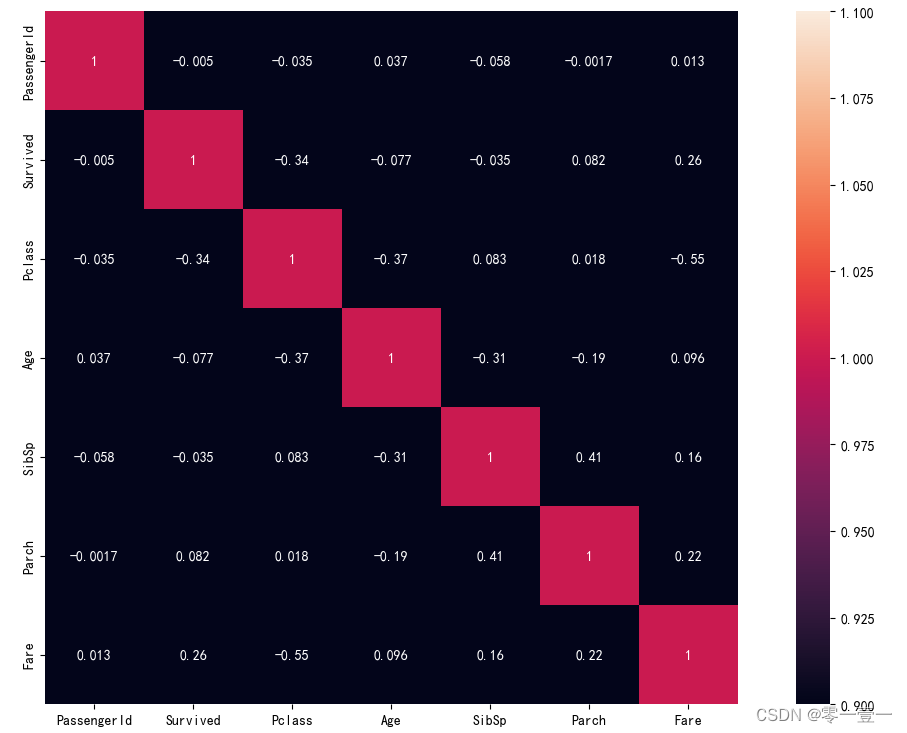
3.4 特征分析
3.4.1 特征分析目的
特征分析的主要目的有两个:
•分析有缺失值的特征和其他特征的关系,填补缺失值。
•分析目标变量Survived与其他特征的关系。
3.4.2 特征观察
首先对训练集中的特征进行观察,可以把特征大概分为两大类:
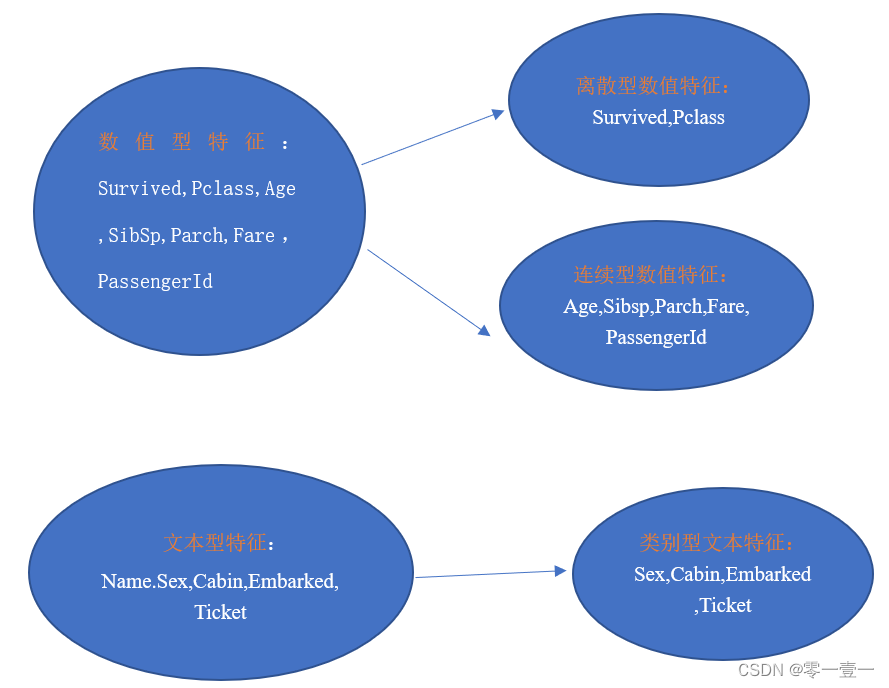
数值型特征一般可以直接用于模型的训练,但有时会为了模型的稳定性对连续变量离散化。
文本型特征往往需要转换成数值型特征才能用于建模分析。
3.4.3 初步特征分析
然后,对这11个特征以此进行分析,哪些是和幸存相关的呢?
(1)PassengerId
ID仅是用来标识乘客的唯一性,必然与幸存无关。
(2)Pclass
船舱等级,一等舱里富人较多,暂认为一等舱内乘客比三等舱乘客容易幸存。


可以看到一等舱的幸存率远大于三等舱,所以幸存率和Pclass相关。
(3)Name
姓名,乘客共有891名,有891个名字,直接拿来讨论无意义。但注意名字中包含称谓,称谓中隐含头衔特征,头衔可分辨不同乘客的身份地位,暂认为身份地位越高的乘客越容易幸存。所以先提取出Name中的头衔特征,新建头衔特征Title。


头衔解读:Mr:未婚男性/已婚男性 Mrs:已婚女性 Miss:未婚女性/年龄较大的妇女
Master:男童/男婴 Don:大学教师 Rev:牧师 Dr:医生/博士
Mme:女士 Ms:已婚女性/未婚女性 Major:陆军少校
Lady:公侯伯爵的女儿 Sir:上级长官 Mlle:小姐 Col:上校
Capt:船长 Countess:伯爵夫人 Jonkheer:乡绅
--头衔种类较多,应先将其归类,那么如何归类呢?先查看下与性别对应的人数。
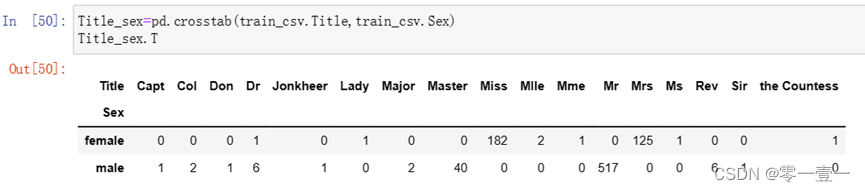
--将特征类似的归为一类,人数比较少的归于‘Rare’;’Mile’’Ms’用‘Miss’代替。
‘Mme’用’Mrs’代替。

那么头衔和幸存相关么?
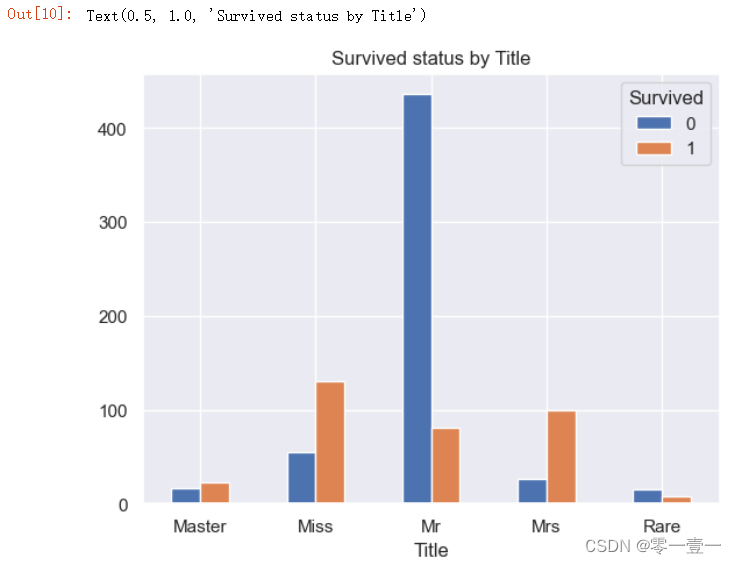
可以明显的看出Title为Master,Miss,Mrs的乘客幸存率比Mr和Rare高。
所以幸存率和Title相关。
(4)Sex
Lady first,但在这种紧急关头,会让女士优先上救生艇吗?通过数据分析。

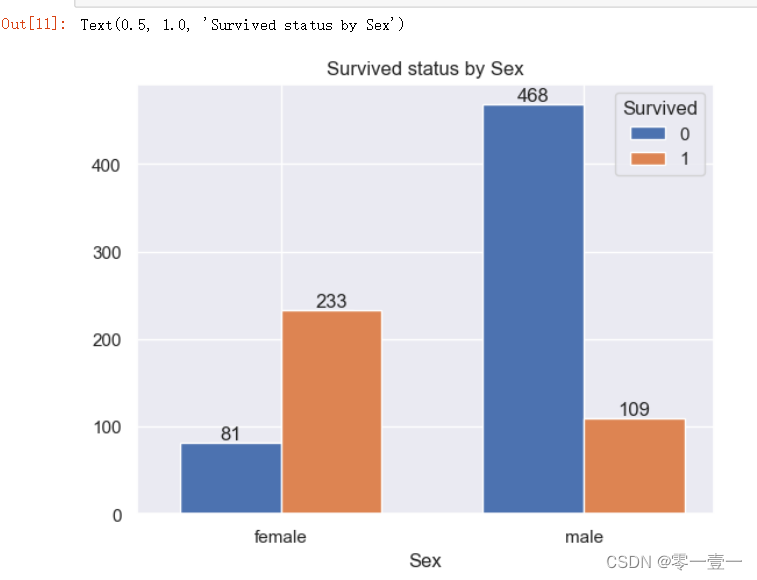
--通过结果可以看出,女性的幸存率远高于男性的幸存率,所以幸存率和Sex相关。
(5)Age
由于Age特征存在缺失值,处理完缺失值,再对其进行分析。
(6)SibSp
--从之前描述型统计得到,兄弟姐妹与配偶人数最大值为8,最小值为0,哪种类型更容易生存呢?通过数据分析:

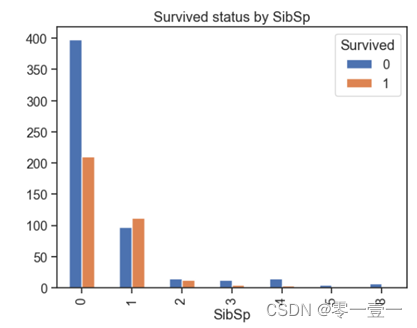
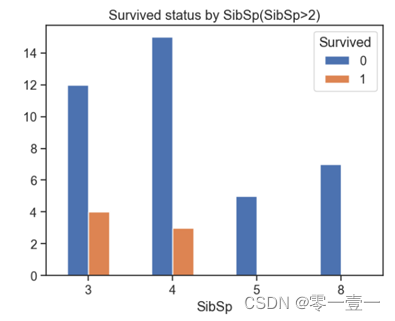
--可以看出,大部分人的SibSp为0,且幸存率也不大;当SibSp数量为1,2时幸存率上升,SibSp值再大时幸存率又降低。所以幸存率和Sibsp相关。
(7)Parch
--从之前描述型统计得到,家庭有大家庭(最多人数为6),小家庭(最少为0)之分,哪种类型更容易生存呢?通过数据分析:

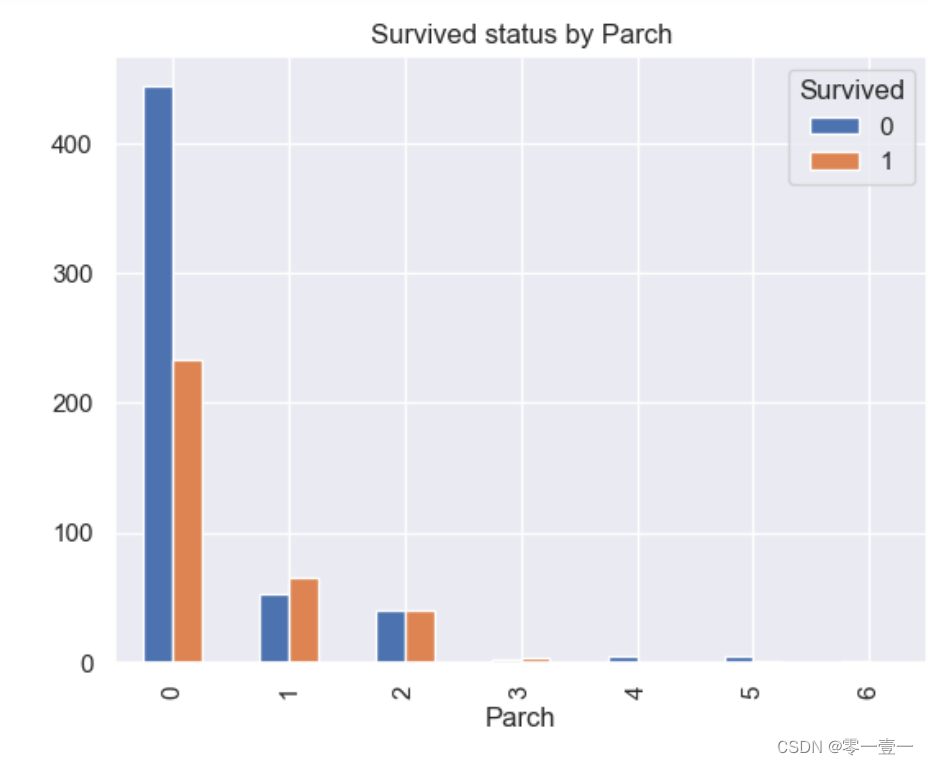
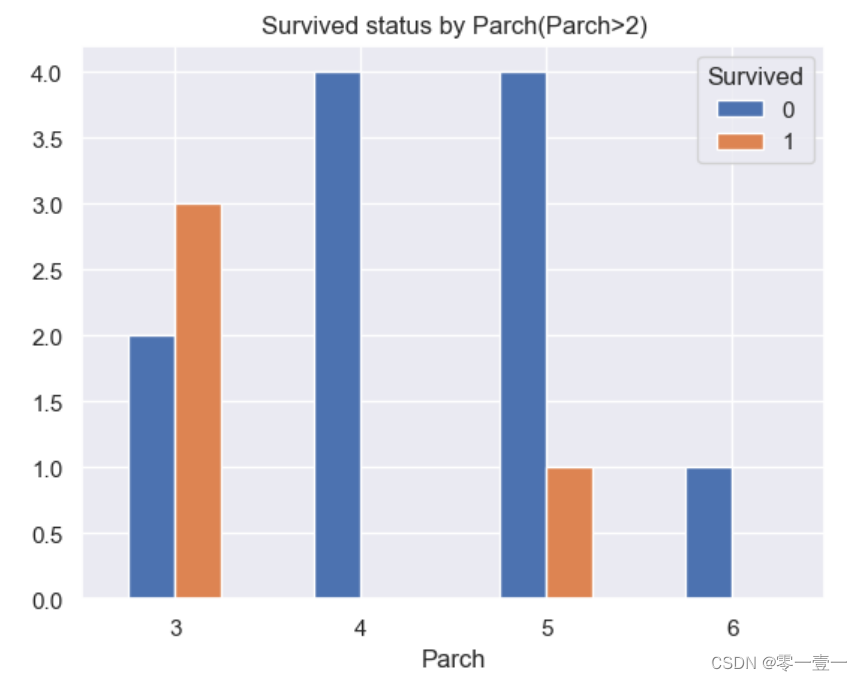
--可以看出,大部分人的Parch也为0,且幸存率也不大;当SibSp数量为1,2,3幸存率上升,SibSp值再大时幸存率又降低。所以幸存率和Parch相关。
(8) Ticket
--乘客总数为891,船票只有681种,说明有部分人共用一张票,初步推测有认识的人共用一张票,像处理Name一样,新建特征GroupTicket,共用票的分为一类,置1;独自使用的分为一类,置0(as_index=False 不以分组类别作为索引)

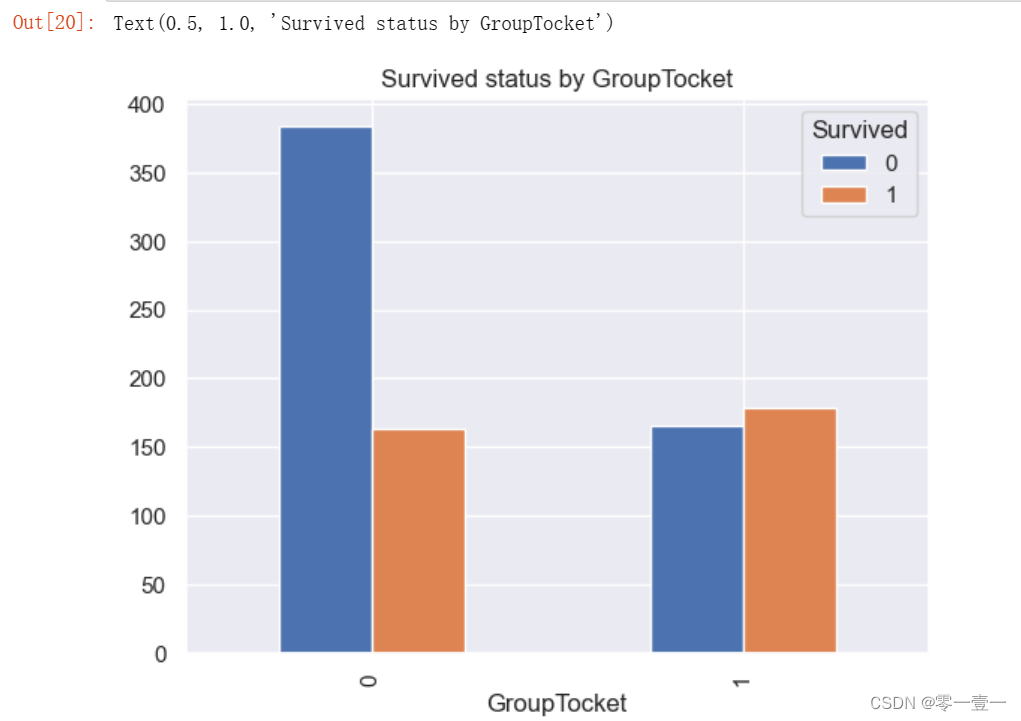
--可以看出,在船上有同伴比孤身一人的幸存率高。
(9)Fare
--由上文的描述型统计可知,船费最小值为0,最大值为512.3292,均值为32.20420,中位数为14。那么票价和生存率有无关系呢?通过数据分析:

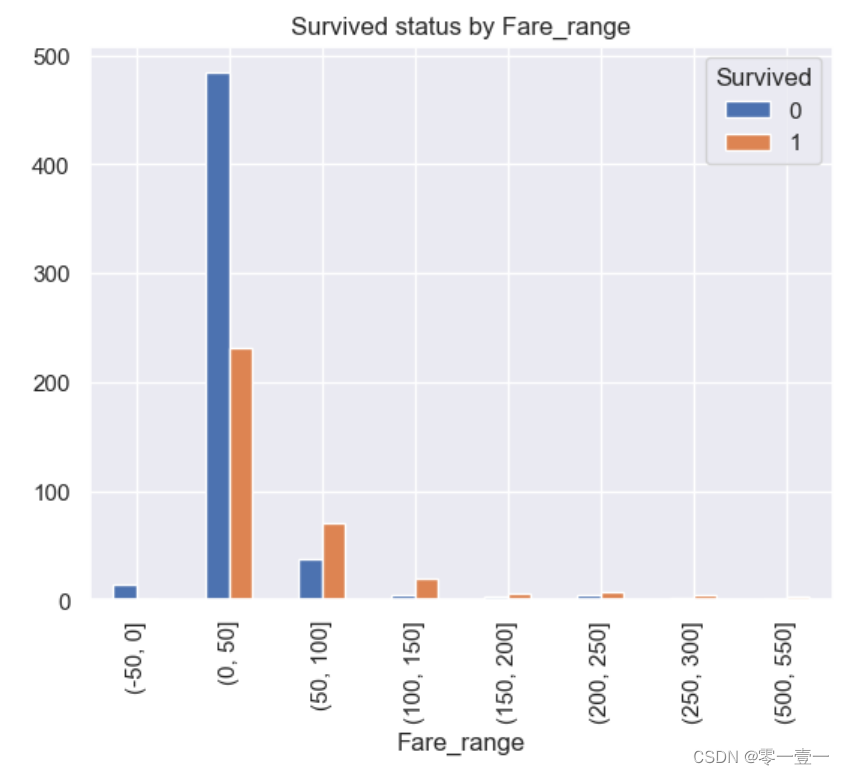

--可以看出,随着票价的增加,幸存率变高。所以幸存率和Fare相关。
(10)Cabin
Cabin特征含有大量缺失值,处理完缺失值再分析。
(11) Embarked
Embarked特征同时也含有缺失值,处理完缺失值再对其分析。
3.5 特征工程
3.5.1 缺失值处理
缺失值主要是由于人为或机械原因造成的数据缺失,在pandas库中用NaN或NaT表示,
缺失值处理方式主要有以下几种:
- 直接删除此特征(缺损数据太多的情况下,防止引入噪声,影响最后结果)
- 直接删除缺损数据的样本(只用于训练数据集,且样本量较大,缺损数据样本较少的情况)
- 直接将有无数字作为新的特征(数据缺失较多,且数据有无本身对预测是一个有用的特征)
- 用某些集中趋势度量(中值,均值,众数等)对缺失值进行填充(缺失数据较多,不想损失较多训练数据,特征又比较重要的情况,是比较常用的方法)
- 参考其他特征,利用与此特征的相关性编写算法回补数据(回归模型,决策树,随机森林等)
- 保留缺失值。
采用何种缺失值,应结合具体场景进行分析。
注意:在缺失值处理之前,应当将数据拷贝一份,以保证原始数据的完整性。

(1)Cabin缺失值处理
Cabin缺失687个,占比约77.1%,缺失数据太多了,是否删除呢?舱位缺失可能代表这些人没舱位,不妨用‘NO’来填充。
(分析:Cabin应该算作类目型的,本来缺失值就多,可它的分布值还很不集中,它如果直接按照类目特征处理的话,太分散了,估计每个因子化后的特征都拿不到什么权重。加上有很多缺失值,所以尝试先把Cabin缺失与否作为条件[虽然这部分信息缺失可能并非未登记,maybe只是丢失了而已,所以这样做不妥当])。

(2)Embarked缺失值处理
Embarked缺失2个,且数据中S最多,达到664个,占比664/891=77%,不妨用众数填充

(3)Age缺失值处理
Age缺失值177个,缺失率约为19.9%。缺失数据较多且在本次分析中Age特征也尤其重要(孩子和老人属于弱势群体,应当更容易获救),所以不能直接删除本特征,也不能保留缺失值,那么到底采用哪种方式处理age缺失值呢?
--在此我尝试了两种针对Age缺失值填充的方法,后续采取了第②种
①采用与头衔相对应的年龄中位数进行填补:
(中位数能反映一个类比人群的平均年龄,不拿均值填补是因为均值易受极个别噪点数据影响)

②采用RandomForest算法来填补缺失的年龄属性:
(RandomForest是一个用在原始数据中做不同采样,建立多颗DesionTree,再进行average等等来降低过拟合现象,提高结果的机器学习算法,具体介绍放到自学内容中)

(4)检查是否存在缺失值
--可以看到,我们已完成了缺失值的处理。
3.5.2 缺失的三个特征的分析
(1)Age

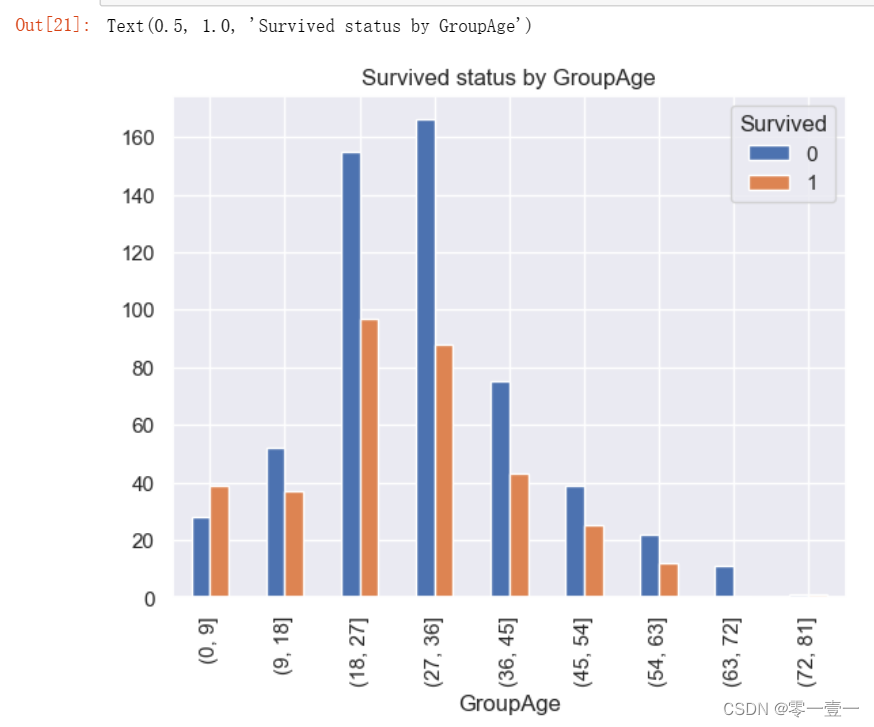
--可以看出,小孩的幸存率确实更大。
(2)Cabin
因为逻辑回归建模时,需要输入的特征都是数值型特征,通常会先对类目型的特征因子化。

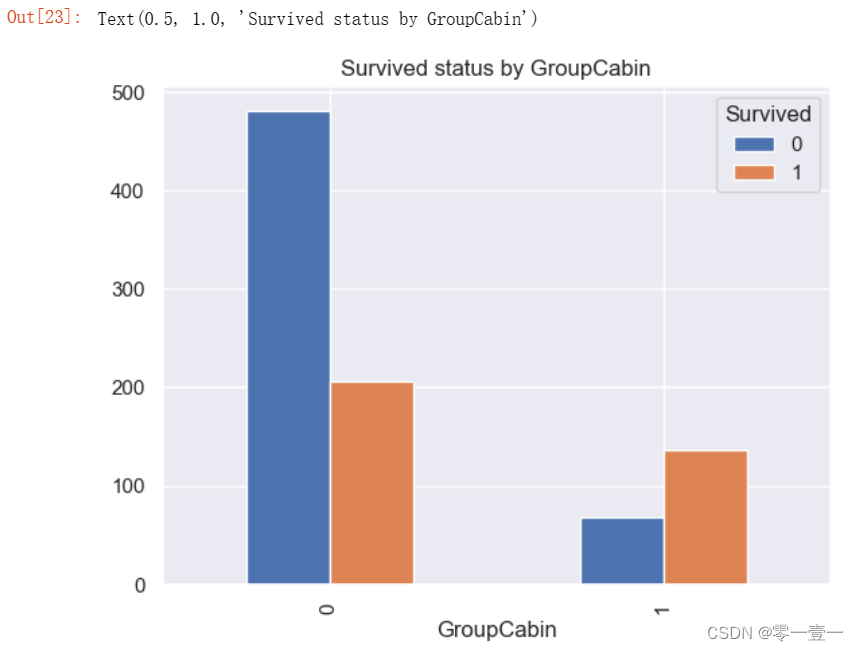
--可以看出,有舱位比没舱位的幸存率高。
(3)Embarked

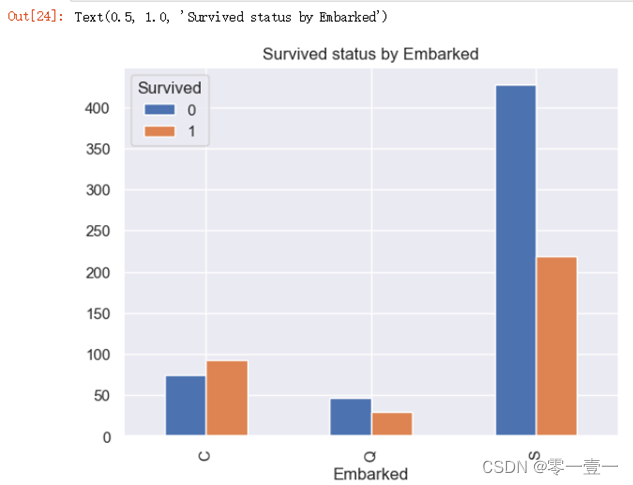
--可以看出,C港的幸存率明显比Q港,S港,这里我没再深究为什么,只是确定Embarked与幸存率相关。
到此我们已完成对所有特征的基本分析,接下来看能否在这些特征的基础上获取新特征,对数据进行进一步更完善的处理。
3.5.3 新特征的提取
通过以上分析,我们已经初步了解与Survived相关的特征:
Pclass|Title(Name中提取)|Sex|GroupAge(把Age分组)|SibSp|Parch|Embarked|
GroupTicket(对Ticket分组)|GroupFare(对Fare分组)|GroupCabin(对Cabin分组)|
在此步骤中,我们除了要提取新特征外,还要完成对类别型特征因子化[逻辑回归建模时,需要输入的特征是数值型特征,因为模型训练函数.fit()只能接收数值类型的数据]和对浮动较大数值的处理。
(1)Pclass和Cabin和Embarked和Sex
对类目型的特征因子化,这里我也学习了两个方法。后续选用了第一种。
第一种方法:Pclass中没有更多信息可供提取,且为数值型变量,这里不做处理。
GroupCabin是数值型特征,这里不做处理。
Embarked和Sex直接由定类变量转为定量变量。
Embarked是类别型特征,转为数值型特征。

Sex
是类别型特征,将其数值化,即用0表示famale,1表示male。

第二种方法:
Cabin转为Cabin_Yes,Cabin_No两个特征。
Embarked特征转为Embarked_C, Embarked_Q, Embarked_S三个特征。
Sex转为Sex_female和Sex_male两个特征。
Pclass转为Pclass_1, Pclass_2, Pclass_3三个特征。
*这里的0和1没有具体意义,只代表某种数据特征。


(2)Title
是文本型特征,将其转换为数值型特征。
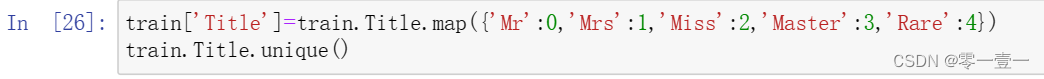
(3)Sibsp和Parch得到新特征IsOne
我们在初步特征分析是分别分析了SibSp特征和Parch特征,可以看出当SibSp和Parch都为0时,幸存率是很低的,我们不妨将SibSp特征和Parch特征组合成一个新特征FamilySize,再通过FamilySize是否为0得到IsOne特征,这样将两个数值很多的特征SibSp和Parch直接转换成‘是否是自己一个人上船’IsOne特征,非常简洁。
首先根据SibSp和Parch两个特征生成一个FamilySize特征
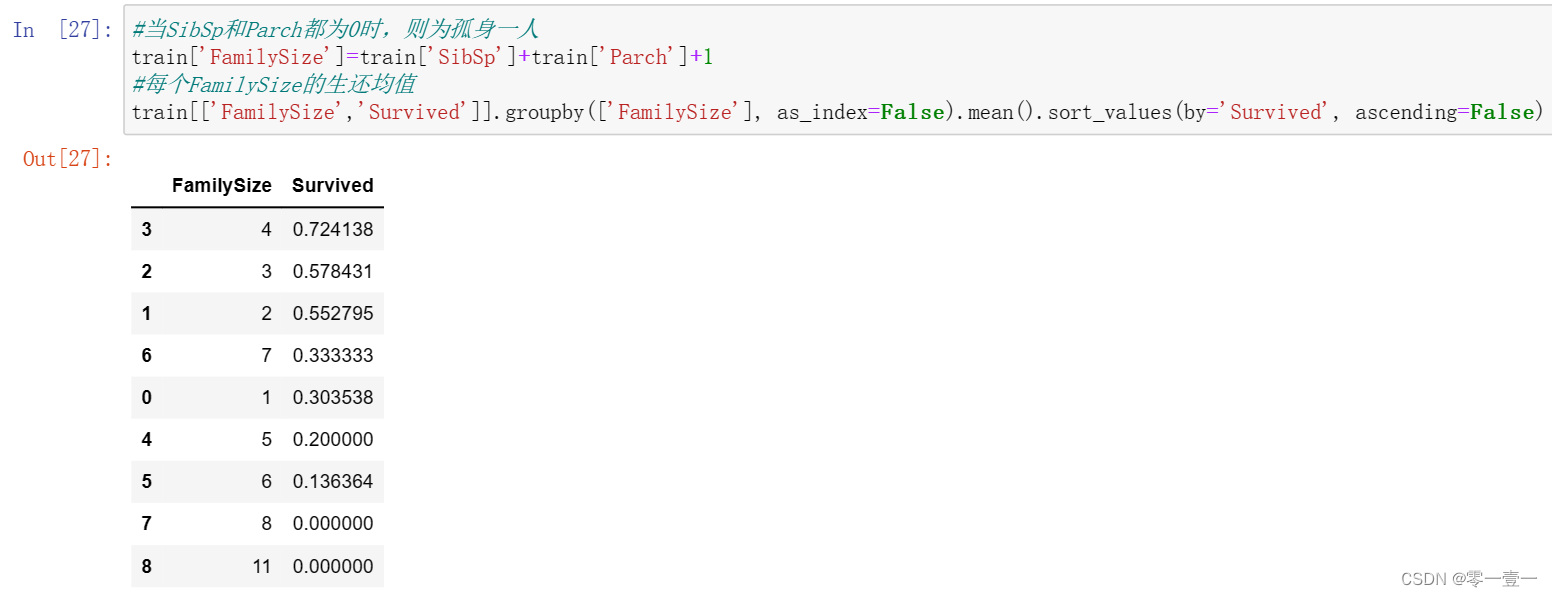
根据FamilySize特征判断是否IsOne:如果FamilySize是1个人,那这个人肯定是IsOne,用1表示,否则用0表示。
 (4)GroupTicket
(4)GroupTicket
是数值型特征,不做处理。
(5)GroupAge和GroupFare
我们之前把Age和Fare分组,是为了方便看这两个特征与Survived的关系,但我们知道这两个特征的数值范围很大,逻辑回归建模中,浮动值极大的数字对收敛速度影响较大,在此我学习了两种方法减小这种影响,
- 是在GroupAge和GroupFare的基础上把每个分组数值化,
- 是用算法把Age和Fare进行scaling,也就是将他们特征化到[-1,1]之间。(后续选用第二种)
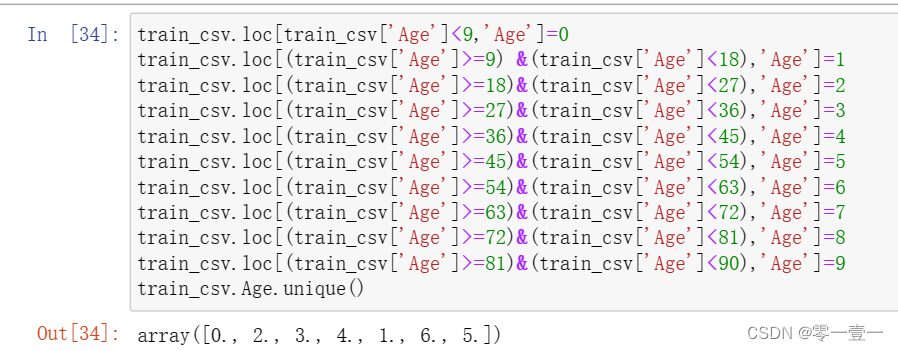
方法①:按照GroupAge特征的范围将Age离散化,我这里的处理是将其分为10组,(因为有891个乘客,2的10次方大于891,年龄的最大值为80,80/10=8,组距设为9)也可分成其它数的组哈
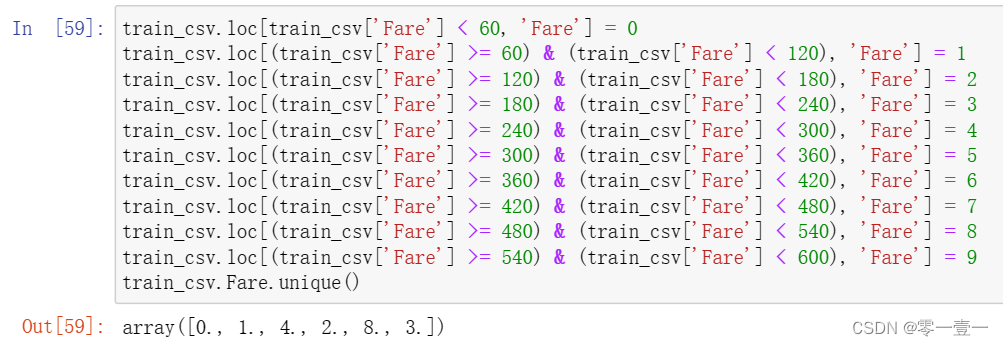
然后类似地也这么处理Fare_range。
方法②:我选择了这种方法
Age和Fare两个属性,乘客的数值幅度变化太大,了解逻辑回归与梯度下降后,我知道了,各属性之间scale差距太大,很影响收敛速度。所以先用scikit-learn里面的preprocessing模块对这两列做一个scaling,其实就是将一些变化幅度较大的特征化到[-1,1]之内。

--以上结束后,就已经把所有类目型特征都转换成数值型特征,并把所有数值型特征都只用少量或小范围数值表示,总结以下现有特征:
PassengerID|Survived|Pclass|Name|Title|Sex|Age|GroupAge|Age_scaled|
SibSp|Parch|FamilySize|IsOne|Ticket|GroupTicket|Fare|Fare_range|Fare_scaled|
Cabin|GroupCabin|Embarked|
删除掉多余重复且与Survived无关的特征:

删除后,现有特征:
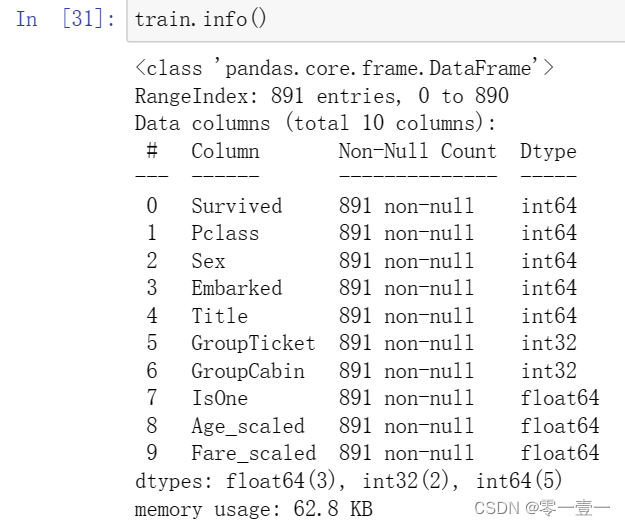
3.6 模型对比(均为默认参数)
3.6.1 测试集数据预处理
建模后不是直接把test.csv丢到由train_csv生成的模型中就能得到结果,需要把test_csv做与train_csv一样的数据预处理。
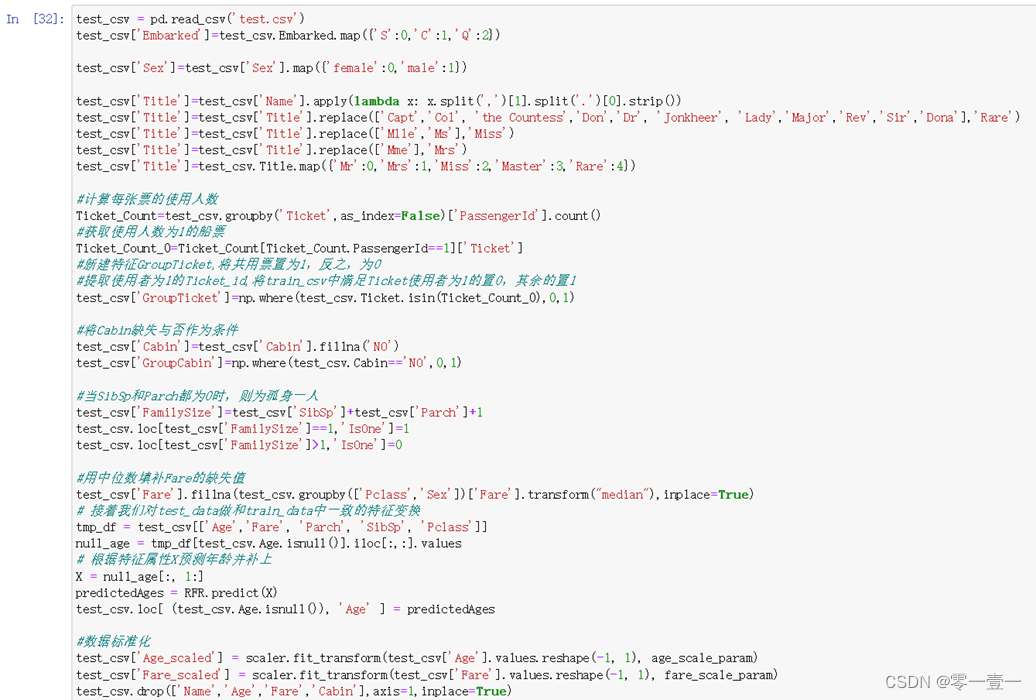
当然,如果开始的时候将训练集和测试集合并后在后面的流程中一起进行分析也可以。
3.6.2 特征选择
主要为以下几个步骤:
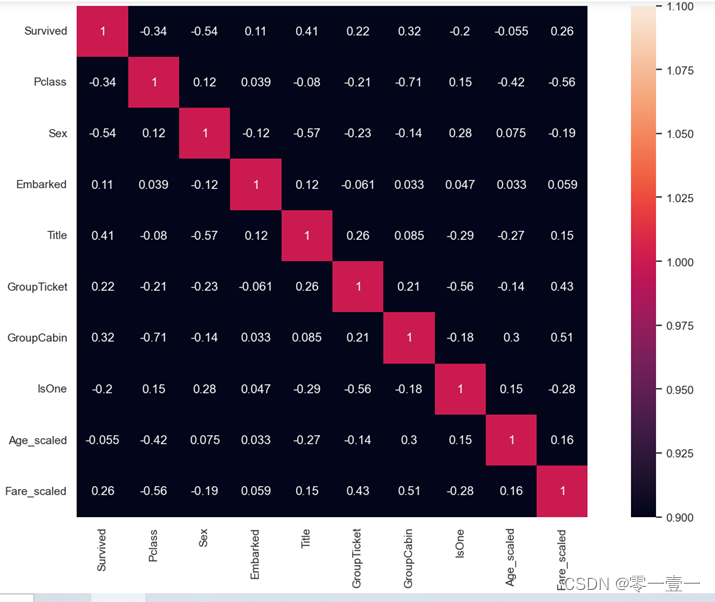
•计算特征之间的相关系数。使用皮尔逊相关系数,将每个特征与目标变量之间的相关性进行计算并量化。
•筛选相关性强的特征。将相关系数绝对值较大的特征作为最终的特征集,可以人工设定一个阈值,只选择那些相关系数超过该阈值的特征,也可以选择前n个相关性最强的特征。
•检查特征之间的共线性。如果多个特征之间存在高度相关的情况,则考虑删除其中某些特征,避免重复建模。

3.6.3 提取训练集与测试集数据

每个模型的具体过程:建立模型实例化对象→拟合训练集→对测试集进行预测→计算准确率
以下是我尝试学习的几种经典模型:
3.6.4 决策树DecisionTreeClassifier()
原理分析:决策树,我的理解是,开始有很多条件,通过if else,一步步筛选,最终得到一个结果,及一个决策。而随机森林是由很多棵决策树产生的森林,集合不同决策树的结果,来通票选出最终的结果,少数服从多数。

3.6.5 随机森林RandomForestClassifier()

3.6.6 支持向量机SVM

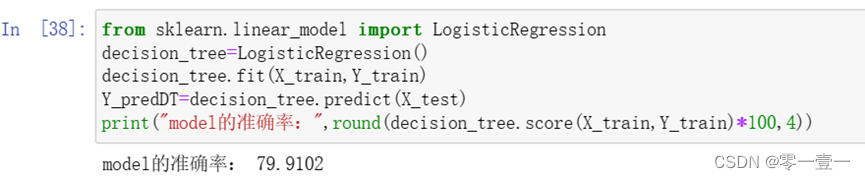
3.6.7 逻辑回归LogisticRegression()
3.6.8 GBDT

3.6.9 KNN最邻近算法

3.6.10 朴素贝叶斯分类
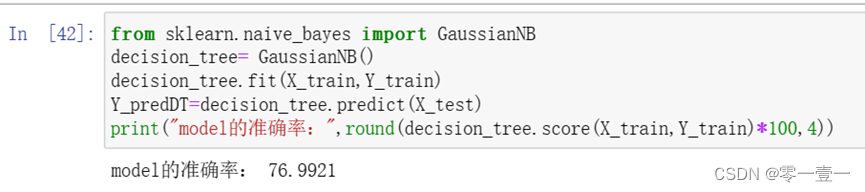
3.6.11 网络搜索模型-调参决策树模型

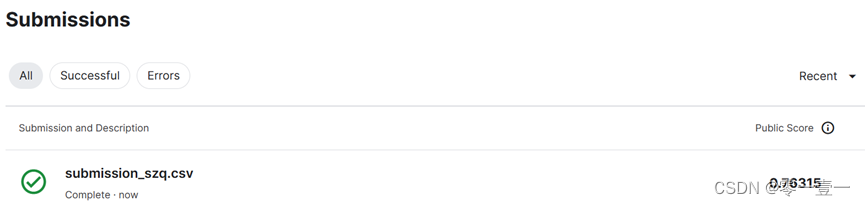
发现准确率下降,分析原因为,默认参数下,决策树模拟Score已经很高了(98.7654),网格搜索最优参数意义不大,而且容易造成过拟合或者欠拟合。
将结果提交到Kaggle后,得分0.76。
四、实验总结
最开始想着做什么python项目当作结课作业时,机缘巧合之下看到了一些和数据分析相关的分享,我十分感兴趣。我就突然想,哎,那一个数据分析的项目它最基本的流程应该是怎样呢?所以最后选择了kaggle上最经典也是入门级的一个machine learning项目—titanic,最开始我看到点赞量很高的大神分享时,心情是我去! 代码这么简洁,效果怎么这么好,怎么想的这种方法处理数据?怎么想的那种方法建模?怎么跑出来的啊!没上手的时候我还觉得这个可能没那么难,真正上手开始按照一个规范化的过程进行一系列处理时我才发现我还是想得太简单。
我做这个大作业的目的就是能够了解数据挖掘到底是什么,一个基本的数据挖掘的项目我们都要干什么。至于机器学习这一块儿,我到最后其实做的还是没有很完善,我只学了这几种模型的大概用法和对比,至于模型优化,我没有涉及到,所以机器学习中像模型训练之类内容我还需要继续学习。最开始做的时候我在对训练集的十几个特征进行分析时,就要进行发散性思维(不发散我觉得它们彼此之间也没啥关系),所以分析的时候看到一大片一大片错误的时候其实挺崩溃的,还有后面找算法模型学模型的时候也基本是从什么也不知道开始学的,但真的完成后成就感真的好高啊。
通过这个大作业,我学到了:
- 一个挖掘数据的小项目的基本流程
- 如何认识一个数据和对数据中的特殊点/离群点进行分析
- 学会如何分析这些特征和缺失值填补,在某些环境下特征工程是比建模还要重要的,要把握住数据本身
- 学会了一些数据挖掘的算法模型
我的不足:
- 没有涉及到模型优化和融合。
- 有些特征的处理方法较为粗糙。
五、参考文章
[1]寒小阳.机器学习系列(3)_逻辑回归应用之Kaggle泰坦尼克之灾.CSDN,2015-11-12.
机器学习系列(3)_逻辑回归应用之Kaggle泰坦尼克之灾-CSDN博客
[2]jingyi130705008.缺失值填充的几种方法.CSDN,2018-9-12.
[3]暮雪成冰.随机森林 n_estimators参数 max_features参数.CSDN,2019-6-19
随机森林 n_estimators参数 max_features参数-CSDN博客
[4]牧风.关于pandas中crosstab的用法.知乎,2020-2-27
[5] 深度讲解Python四大常用绘图库的“绘图原理”,2022-7-31
[6]哪吒敲代码过海.进阶分享|7000字,利用Python分析泰坦尼克数据.CSDN,2022-5-06
进阶分享 | 7000字,利用Python分析泰坦尼克数据_python泰坦尼克号数据分析_哪吒敲代码闹海的博客-CSDN博客
六、问题调试
虽然是边做边写的设计文档但忘记保存很多error了,捡着当时记录的分析吧。
(1)最开始的相关系数图显示不出来。
解决方法:导入库的时候加上%matplotlib inline
(2)导入pandas_profiling时显示不存在
解决方法:这个库更新了,是导入ydata_profiling
3. ValueError: The number of FixedLocator locations (3), usually from a call to set_ticks, does not match the number of ticklabels (4).
解决方法;在生成柱形图时把坐标值的个数设计错了,比组数笑了,把plt.xticks()里的参数设计跟组数一样就行了。
(4)测试集按照最开始数据预处理后显示Title 417 non-null float64
解决方法:查看测试集的头衔,它比训练集多了一个‘Dona’,把这个归到‘Fare’里。
(5)在执行第一个算法模型决策树时显示:
The function name should match the name passed during the fitting process
The order of feature names must be the same as the matching order
解决方法:在最后对测试集做数据预处理时我比较随意,开始就没按照处理训练集的数据的顺序和方法处理测试集里的数据,导致处理完用info()函数时测试集和训练集里的特征功能的种类和个数都不一样,调试时我先是改变了处理测试集的方法,跟训练集一样,还是error,然后我又改了处理测试集数据的顺序,使其和训练集完全相同,这次成功了。
所以最后训练集和测试集里的数据类型应完全相同,否则无法匹配,所以之后再做相关的项目,我会尝试开始把测试集和训练集合并在一起共同处理,再建模试试看。
















 29万+
29万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











