







本系列讨论的话题是一致性哈希,主要分为两篇:
- 第一篇:讲解一致性哈希技术原理,以及应用场景
- 第二篇:带大家从0到1实现一致性哈希,相应代码也会开源到github上
1.为什么要有一致性哈希
1.1 服务状态
首先我们应该明确两个概念,有状态服务和无状态服务
-
无状态服务:一般指得就是我们平常所写的增删查改业务代码,不需要存储数据,只需要向数据库或者消息队列发送请求即可
对于这种无状态服务,请求到哪个节点并不是很重要,扩展节点规模也并不难,只需要注意客户端的请求发送就好,比较难的问题是你如何实现这笔业务,这并不在我们本文讨论范围之内 -
有状态服务:与无状态服务相反,就是我们在工作中真正存储数据的组件,一般是数据库或者消息队列
对于有状态服务来说,由于有状态服务是真正存储数据的,所以我们在进行防止单点故障增加备份机器的横向扩展中,需要注意数据一致性的问题;在增加提高性能的纵向扩展中,要注意数据和节点的映射功能(后文会详细讲解)
为了大家更好的理解这两种服务,作者画了张图(比较抽象,凑活着看)

1.2.我该访问谁呢
这个问题本质就是,节点应该如何分配读写任务。
要知道一个集群的节点肯定是要进行纵向扩展来提高系统性能的,当然,在真实场景中,这种纵向分治的策略无法在性能上带来这种线性的提升效率,因为在多人协作时,难免在边界分配、交接工作、结果聚合等环节会存在效率的损耗. 但即便如此,这种纵向扩容分治的思路也能在很大程度上减轻每个独立节点所需要承担的工作强度,因此能够提高整个系统的性能上限。
一般来说我们是通过哈希来分配,原因就是哈希具有离散性,我们能把数据请求正确的分配到不同节点,保证数据请求分配尽可能平均
• 在写数据的流程中:
• 计算key的hash值
• hash 值对节点数量取模,(防止越界)得到其所属的节点 index
• 将数据写入到对应 index 的节点中
• 在读数据的流程中:
• 计算key的hash值
• hash 值对节点数量取模(防止越界),得到其所属的节点 index
• 从 index 对应的节点中读取数据
1.3.带权负载
这里涉及到一个问题,每个机器的处理能力不可能是相同的,所以我们肯定希望能力强的节点多干一点,能力弱的少干一点,就像我们的工作(dog)
如何简单的实现呢,很简单,就是把所有节点按照能力划分百分比值,然后节点根据其权重值大小在轴上占据对应的比例分区. 接下来每当有数据到来,我们都会根据数据的 key 取得 hash 值并对水平轴的总长度取模,找到其在水平轴上的刻度位置,再根据该刻度所从属的分区,推断出这笔数据应该从属于哪一个节点。
看起来可能有点抽象,那作者简单画个抽象的图(

1.4.数据迁移
看似已经完美了,已经实现了数据的负载分配和请求,但显然不是的,如果节点增加或者减少怎么办?
一旦集群需要执行扩缩容流程,集群节点数量变更后,原有的映射关系就会被破坏. 为了继续维护这份映射规则,我们需要执行数据迁移操作,将旧数据迁移到能够满足新映射关系的对应位置. 这必然会是一个很重的迁移流程,涉及影响的范围是全量的旧节点.
全量复制或者更改显然是难以接受的,如何实现增量复制或者更改,就是本文第二章主要探讨内容。
2.一致性哈希
2.1.应该采用怎样的哈希结构呢
一般哈希主要有链状,离散状,或者环状。
显然离散状不行,就不讨论了。
链状的哈希还是有相同的问题,节点变更时,依旧是全量复制。
所以我们一致性哈希选择的是环状,也就是哈希环。
2.2.哈希环
2.2.1 哈希环构造
现在,我们需要打破固有的数据与节点之间的点对点映射关系.
我们首先构造出一个哈希环(Hash Ring):
• 哈希环是一个首尾衔接的环
• 起点位置数值为 0
• 终点位置数值为 2^32,与 0 重合
• 环上每个刻度对应一个 0~2^32 - 1 之间的数值

2.2.2 如何进行数据请求
计算节点/机器(通常使用节点的名称、编号和 IP 地址)的哈希值,放置在环上。
计算 key 的哈希值,放置在环上,顺时针寻找到的第一个节点,就是应选取的节点/机器,值得注意的是,哈希环在寻找到2的32次方也就是环的起点时会继续从头开始寻找。
2.2.3 数据倾斜问题
一般来说,我们的节点数量并不会特别多(当然也不少),大约在2的8次方这个数量级,这样就有一个问题,大量的数据分配可能过多的分配到了一个节点上去,所以我们提出虚拟节点的概念
虚拟节点策略:
• 我们定义出“真实节点”和“虚拟节点”两个概念:
• 真实节点:集群中的各个节点,是物理意义上存在的服务器节点
• 虚拟节点:真实节点进入哈希环时使用的一系列代理节点,是逻辑意义上的代理节点
• 对于各个真实节点,我们指定一个策略,确定其虚拟节点的个数,比如放大一定的倍数. 需要注意的是,虚拟节点越多,那么未来可能抢占到的数据量就越大
• 我们需要维护好一个路由表,建立好每个虚拟节点与真实节点的映射关系
• 我们使用虚拟节点作为真实节点的代理,将所有虚拟节点添加到哈希环中
• 在数据出、入哈希环时,使用虚拟节点进行数据的抢占和关联,流程同 2.1.3 小节
• 每当找到一笔数据所从属的虚拟节点时,通过路由表,找到其所映射的真实节点,然后返回真实节点的 index
截一张小徐先生的编程世界的图
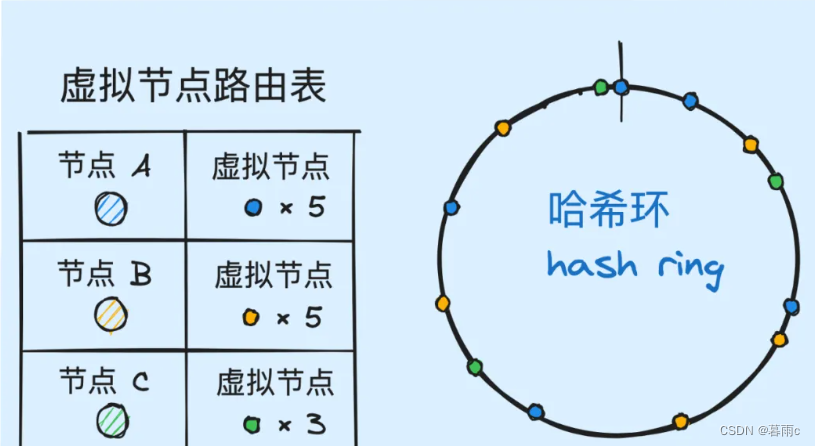
举个例子
假设 1 个真实节点对应 3 个虚拟节点,那么 peer1 对应的虚拟节点是 peer1-1、 peer1-2、 peer1-3(通常以添加编号的方式实现),其余节点也以相同的方式操作。
第一步,计算虚拟节点的 Hash 值,放置在环上。
第二步,计算 key 的 Hash 值,在环上顺时针寻找到应选取的虚拟节点,例如是 peer2-1,那么就对应真实节点 peer2。
虚拟节点扩充了节点的数量,解决了节点较少的情况下数据容易倾斜的问题。而且代价非常小,只需要增加一个字典(map)维护真实节点与虚拟节点的映射关系即可。
2.3.变更节点
在此仅以增加节点为例,删除节点大致逻辑一样
以下图对应的新增节点的场景为例,我们对集群扩容的流程加以梳理:
背景: 原本集群存在存在 A、B、C、D、E、F 六个节点,已分别添加到哈希换中,位置如下图所示.
变量: 此时需要新增一个节点 G,经过哈希散列和取模运算后,节点 G 在哈希环上的位置位于 B 与 C 之间,我们把位置关系记为 B-G-C
下面是对新增节点流程的梳理:
• 找到节点 G 顺时针往下的第一个节点 C
• 检索节点 C 中的数据,将从属于 (B,G] 范围的这部分数据摘出来,迁移到节点 G
• 节点 G 添加入环
至此,新增节点场景下的数据迁移动作完成。
2.4 按能力负载均衡
如何实现负载均衡呢?这就又提到我们之前说过的虚拟节点。
我们在2.2说过,虚拟节点收到的请求会发送到真实节点,所以我们只需要增加一个真实节点对应的虚拟节点的数量,即可实现能者多劳
3.一致性哈希用途
我们写业务可能用到的比较少,就是在发送请求时可能会有所借鉴
在各种中间件中一致性哈希算法用途非常多,比如nginx就是用一致性哈希来实现负载均衡的
4.文章总结
• 一致性哈希算法是一种适用于有状态服务的负载均衡策略,数据结构由一个首尾衔接的哈希环组成
• 节点入环时,通过取哈希并对环长度取模,确定节点所在的位置 数据入环时,通过取哈希并对环长度取模,然后找到顺时针往下的第一个节点,作为操作的目标节点
• 一致性哈希最大的优势是,在集群节点数量发生变更时,只需要承担局部小范围的数据迁移成本
• 一致性哈希中可以通过虚拟节点路由的方式,提高负载均衡程度,并能很好地支持带权分治的诉求
下一篇文章将会从0到1实现一致性哈希算法















 93
93

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









