







目录
(4)*概率算法(Probabilistic Algorithm)
(5)*近似算法(Approximation Algorithm)
一、贪心法(Greedy Algorithm)
- 特点:
- 每一步仅根据当前信息做出局部最优选择,不回溯,不保证全局最优,但通常能得到较好的近似解。
- 关键性质:
- 最优子结构:问题的最优解包含子问题的最优解(与动态规划相同)。
- 贪心选择性质:通过局部最优选择能直接得到全局最优解(区别于动态规划)。
- 应用:
- 部分背包问题:物品可分割,按单位重量价值排序后贪心装入(时间复杂度通常为 O(nlogn),含排序步骤)。
- 消防栓覆盖问题:从左到右贪心选择覆盖点(如文档中例子,覆盖半径20米,时间复杂度 O(n))。
考虑一个部分背包问题的例子,设定参数:物品数量 n=5,背包容量 W=100。给出了5个物品各自的重量(wi)、价值(vi)以及单位重量的价值(vi/wi),并且假设物品已按单位重量的价值从大到小排好序,具体如下:
物品i 1 2 3 4 5 wi 30 10 20 50 40 vi 65 20 30 60 60 vi/wi 2.1 2 1.5 1.2 1 为得到该部分背包问题的最优解,需要把背包放满,使用贪心策略求解时,首先要选出度量的标准,有以下三种:
- 按最大价值先放背包的原则:即优先选择价值高的物品放入背包。
- 按最小重量先放背包的原则:优先选择重量小的物品放入背包。
- 按最大单位重量价值先放背包的原则:优先选择单位重量价值高的物品放入背包,在该示例中物品已按此原则排好序。
二、回溯法(Backtracking)
- 特点:
- 深度优先搜索解空间树,遇到无效解时回溯到上一层尝试其他分支。
- 适用于穷举所有可能解的问题(如迷宫、排列组合)。
- 与分支限界法区别:
- 回溯法是深度优先,分支限界法是广度优先或优先级优先。
- 回溯法可能无法高效找到最优解,分支限界法通过剪枝优化搜索。
真题示例:
考虑一个背包问题,共有n = 5个物品,背包容量为W = 10,物品的重量和价值分别为:w = {2, 2, 6, 5, 4},v = {6, 3, 5, 4, 6},求背包问题的最大装包价值。若此为0 - 1背包问题,分析该问题具有最优子结构,定义递归式为:
其中c(i, j)表示i个物品、容量为j的0 - 1背包问题的最大装包价值,最终要求解c(n, W) 。
采用自底向上的动态规划方法求解,得到最大装包价值为(62),算法的时间复杂度为(63) 。
若此为部分背包问题,首先采用归并排序算法,根据物品的单位重量价值从大到小排序,然后依次将物品放入背包直至所有物品放入背包中或者背包再无容量,则得到的最大装包价值为(64),算法的时间复杂度(65) 。
题目序号 选项A 选项B 选项C 选项D (62) 11 14 15 16.67 (63) Θ(nW) Θ(nlgn) Θ(n2) Θ(nlgnW) (64) 11 14 15 16.67 (65) Θ(nW) Θ(nlgn) Θ(n2) Θ(nlgnW)
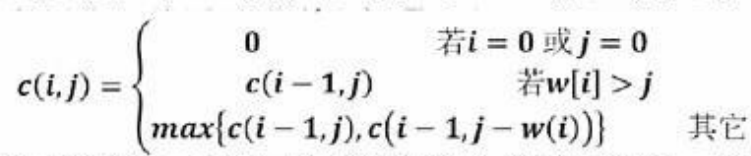
1. 0 - 1背包问题
- 计算最大装包价值: 通过动态规划求解0 - 1背包问题,可构建一个二维数组来存储中间结果c(i,j)。 物品重量w={2,2,6,5,4},价值v={6,3,5,4,6},背包容量W=10。 依次计算不同物品数量和不同背包容量下的最大价值,最终可得最大装包价值为15。
- 计算时间复杂度: 动态规划求解0 - 1背包问题时,需要填充一个大小为(n+1)×(W+1)的二维数组,所以时间复杂度为Θ(nW)。
2. 部分背包问题
- 计算最大装包价值: 先计算每个物品的单位重量价值:
- 物品1:6÷2=3
- 物品2:3÷2=1.5
- 物品3:5÷6≈0.83
- 物品4:4÷5=0.8
- 物品5:6÷4=1.5
按照单位重量价值从大到小排序为物品1、物品2和物品5(单位重量价值相同可任意排)、物品3、物品4。 依次放入背包:
- 先放物品1(重量2,价值6,再放物品2(重量2,价值3),放物品5(重量4,价值6)
- 此时背包还剩容量2,放入物品3的2/6,价值增加2/6×5≈1.67。
总价值为6+3+6+1.67=16.67。
- 计算时间复杂度: 部分背包问题首先要进行排序,采用归并排序算法,其时间复杂度为Θ(nlgn),后续依次放入物品的时间复杂度为Θ(n),总体时间复杂度由排序主导,为Θ(nlgn)。
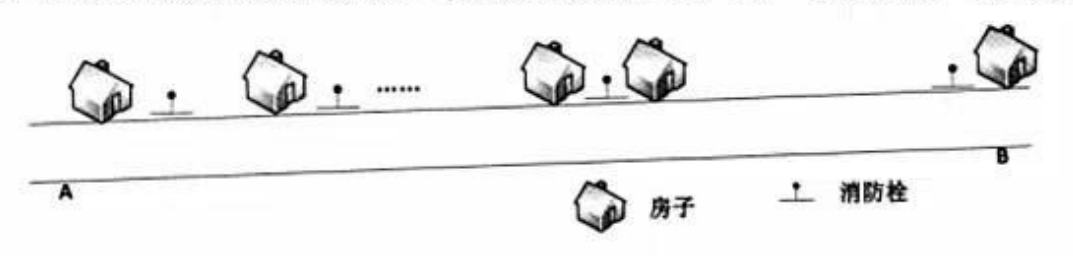
在一条笔直公路的一边有许多房子,现要安装消防栓,每个消防栓的覆盖范围远大于房子的面积,如下图所示。现求解能覆盖所有房子的最少消防栓数和安装方案(问题求解过程中,可将房子和消防栓均视为直线上的点)。
该问题求解算法的基本思路为:从左端的第一栋房子开始,在其右侧m米处安装一个消防栓,去掉被该消防栓覆盖的所有房子。在剩余的房子中重复上述操作,直到所有房子被覆盖。算法采用的设计策略为();对应的时间复杂度为()。假设公路起点A的坐标为0,消防栓的覆盖范围(半径)为20米,10栋房子的坐标为(10,20,30,35,60,80,160,210,260,300),单位为米。根据上述算法,共需要安装()个消防栓。以下关于该求解算法的叙述中,正确的是()。
题目序号 选项A 选项B 选项C 选项D (62) 分治 动态规划 贪心 回溯 (63) O(lgn) O(n) O(nlgn) O(n²) (64) 4 5 6 7 (65) 肯定可以求得问题的一个最优解 可以求得问题的所有最优解 对有些实例,可能得不到最优解 只能得到近似最优解
(62) 算法设计策略
算法从左端第一栋房子开始,在其右侧一定距离安装消防栓以覆盖尽可能多的房子,每一步都做出当下看似最优的选择(覆盖最多房子),符合贪心算法的特点。
- 分治算法是将问题分解为子问题,分别求解子问题再合并结果
- 动态规划是通过记录子问题的解来避免重复计算
- 回溯算法是在搜索过程中,当发现不满足条件时回退重新搜索
(63) 时间复杂度
该算法只需遍历一次房子的坐标,对每个房子判断是否被已安装的消防栓覆盖,进行一次处理,时间复杂度为O(n),n为房子的数量。
(64) 安装消防栓数量
已知消防栓覆盖范围半径为20米,房子坐标为(10,20,30,35,60,80,160,210,260,300)。
- 从坐标为10的房子开始,在其右侧20米(坐标30处)安装一个消防栓,可覆盖10、20、30、35的房子。
- 剩余房子坐标为60、80、160、210、260、300,从60处房子开始,在其右侧20米(坐标80处)安装一个消防栓,可覆盖60、80的房子。
- 剩余房子坐标为160、210、260、300,从160处房子开始,在其右侧20米(坐标180处)安装一个消防栓,可覆盖160的房子。
- 剩余房子坐标为210、260、300,从210处房子开始,在其右侧20米(坐标230处)安装一个消防栓,可覆盖210的房子。
- 剩余房子坐标为260、300,从260处房子开始,在其右侧20米(坐标280处)安装一个消防栓,可覆盖260、300的房子。
总共需要安装5个消防栓。
(65) 算法性质
对有些实例,可能得不到最优解
(3)*分支限界法(Branch and Bound)
- 特点:广度优先搜索(BFS)或优先级队列 + 限界剪枝,用于求解最优化问题。
- 与回溯法的区别:
维度 分支限界法 回溯法 搜索策略 广度优先 / 最佳优先 深度优先 存储方式 活结点表(队列/优先队列) 递归栈 求解目标 最优解 可行解 - 典型应用:整数规划、任务调度、TSP问题。
- 时间复杂度:取决于剪枝效率,可能仍较高(如 O(n!))。
(4)*概率算法(Probabilistic Algorithm)
- 特点:引入随机性,允许小概率错误以换取时间效率。
- 分类:
- 蒙特卡洛算法:可能返回错误解(如素数检测)。
- 拉斯维加斯算法:绝不返回错误解,但可能无法终止(如随机化快速排序)。
- 舍伍德算法:消除最坏情况(如随机化哈希)。
- 典型应用:随机化快速排序、模拟退火、遗传算法。
(5)*近似算法(Approximation Algorithm)
- 特点:放弃精确解,换取多项式时间内的近似解。
- 衡量标准:
- 近似比(解与最优解的比值)。
- 时间复杂度(必须为多项式时间)。
- 典型应用:NP难问题(如TSP的2-近似算法)。
六、数据挖掘算法(了解概念)
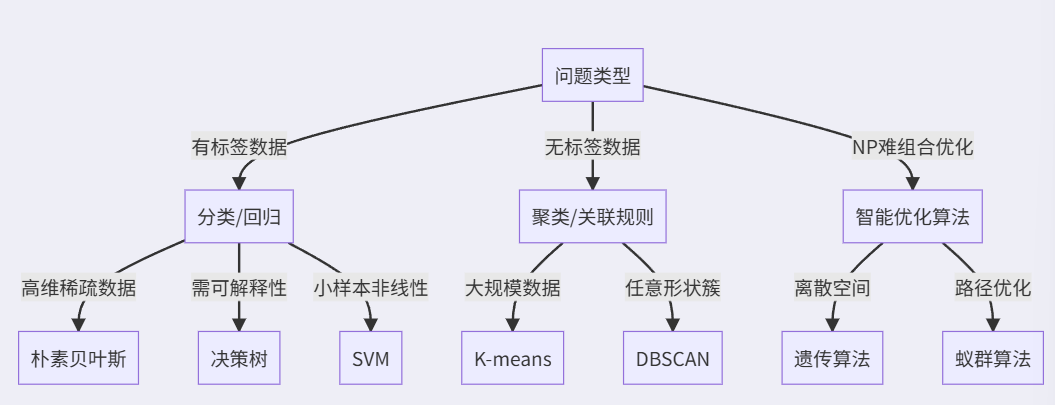
1. 分类算法(有监督学习)
| 算法 | 核心原理 | 特点与适用场景 | 数学基础 |
|---|---|---|---|
| 决策树 | 基于信息增益(ID3)、增益率(C4.5)或基尼指数(CART)递归划分特征空间 | 可解释性强,易过拟合,需剪枝 | 信息熵、条件熵 |
| 朴素贝叶斯 | 基于贝叶斯定理,假设特征条件独立 | 适合高维数据(如文本分类),计算效率高 | 概率密度估计(如高斯分布) |
| SVM | 寻找最大化间隔的超平面,核函数处理非线性问题 | 小样本效果好,对噪声敏感 | 拉格朗日乘子法、核技巧 |
| 随机森林 | 集成多棵决策树,通过投票减少过拟合 | 高准确率,抗噪声,适合并行计算 | Bootstrap采样 |
2. 关联规则挖掘
- Apriori算法:
- 步骤:频繁1项集→生成候选k项集→剪枝(基于向下闭包性)
- 改进:FP-Growth通过前缀树压缩数据,避免候选集生成(时间复杂度:O(n) vs Apriori的O(2n))
- 评估指标:支持度(频繁性)、置信度(规则强度)、提升度(相关性)
3. 聚类算法(无监督学习)
| 算法 | 核心原理 | 优缺点 | 适用场景 |
|---|---|---|---|
| K-means | 最小化簇内平方误差,迭代更新质心 | 需预设K值,对异常值敏感 | 球形簇、大数据量 |
| 层次聚类 | 自底向上(AGNES)或自顶向下(DIANA)合并/分裂 | 无需预设K值,复杂度高(O(n3)) | 小规模数据、可视化分析 |
| DBSCAN | 基于密度连通性,识别任意形状簇 | 抗噪声,需调参(邻域半径、最小点数) | 非凸分布、异常检测 |
4. 应用场景深化
- 金融风控:SVM检测欺诈交易(高维特征处理)
- 推荐系统:协同过滤(关联规则)+ 矩阵分解(隐语义模型)
- 客户分群:RFM模型(K-means聚类)结合PCA降维
七、智能优化算法(了解概念)
1. 算法对比与细节
| 算法 | 核心机制 | 关键参数 | 典型问题 |
|---|---|---|---|
| 遗传算法 | 选择(轮盘赌/锦标赛)、交叉(单点/均匀)、变异(位翻转) | 种群大小、交叉/变异概率 | TSP、函数优化 |
| 蚁群算法 | 信息素更新 | 信息素挥发系数ρ、启发因子 | 路径规划、任务调度 |
| 模拟退火 | 接受劣解概率: | 初始温度、冷却速率、终止条件 | VLSI布局、组合优化 |
| ANN | 反向传播(BP)调整权重,激活函数(ReLU/Sigmoid)引入非线性 | 学习率、隐藏层数、正则化系数 | 图像识别、时序预测 |
2. NP难问题求解策略
- 混合优化:GA + 局部搜索(如爬山法)提升收敛速度
- 并行计算:蚁群算法的信息素更新可分布式处理
- 约束处理:模拟退火通过惩罚函数处理约束条件
3. 前沿扩展
- 深度强化学习:DQN(ANN+Q-learning)解决动态优化问题
- 量子优化算法:量子退火(D-Wave)处理组合爆炸问题


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









