







目录
前言
本期是MySQL进阶篇当中索引的最后一期内容,这里我们主要接着上一期继续讲解前缀索引、单例与联合索引。(上一期链接:MySQL进阶-----SQL提示与覆盖索引-CSDN博客)
一、前缀索引
当字段类型为字符串(
varchar
,
text
,
longtext
等)时,有时候需要索引很长的字符串,这会让
索引变得很大,查询时,浪费大量的磁盘
IO
, 影响查询效率。此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
1. 语法
create index idx_xxxx on table_name(column(n)) ;示例:
为
tb_user
表的
email
字段,建立长度为
5
的前缀索引。
create index index_email on tb_user(email(5));
2. 如何选择前缀长度
可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高则查询效率越高, 唯一索引的选择性是1
,这是最好的索引选择性,性能也是最好的。
下面这里我们看一下案例:
select count(distinct email)/count(*) from tb_user;

可以看到上面显示的是1,也就是说所有的email字段的数据都没有出现重复,下面我们去从email字段数据去截取前5个字符比较试试看:
select count(distinct substring(email,1,5)) / count(*) from tb_user ;

这里我们可以看出出现重复了,但是非重复率还是有0.9583的,如果我们截取前4个或者前6个字符再试试看重复率:
#截取前四个
select count(distinct substring(email,1,4)) / count(*) from tb_user ;

#截取前6个
select count(distinct substring(email,1,6)) / count(*) from tb_user ;

上面这两个对比就知道,截取前4个的话重复率变大了,而截取前6个的话重复率不变 ,故最优解就是截取前面前5个即可。
3. 前缀索引的查询流程
前缀索引的查询流程基本上跟前面讲到过的是差不多的,这里会通过我们选择好的前缀去建立一个辅助索引,在辅助索引上面去找到相对应的索引目标,如果出现重复的话就会先找到第一个重复的索引数据,然后再去进行回表查询,如果确定完整的字段能够匹配成功的话就为当前字段,反正继续遍历下一个重复的结果。

二、单列索引与联合索引
这个的话我们前面几期的内容就接触过了。
单列索引:即一个索引只包含单个列。
联合索引:即一个索引包含了多个列。
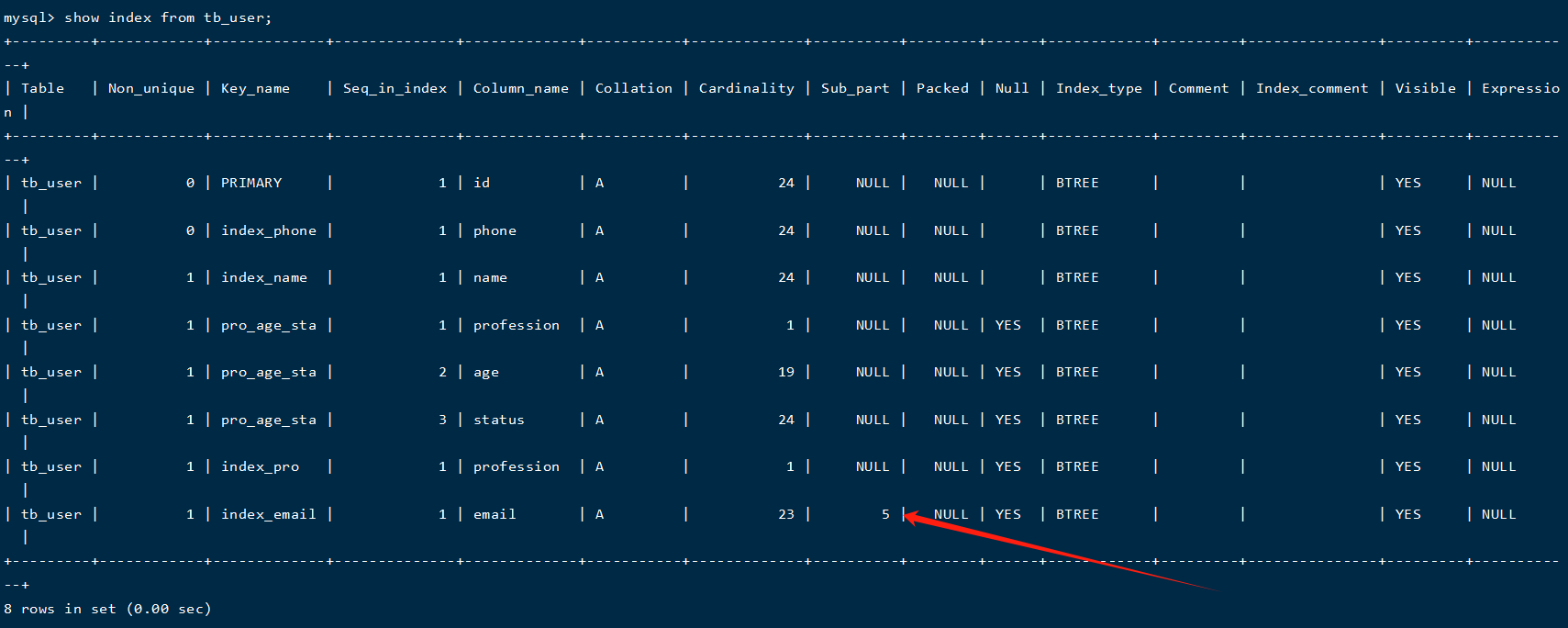
我们先来看看
tb_user 表中目前的索引情况:

在查询出来的索引中,既有单列索引,又有联合索引。
接下来,我们来执行一条SQL语句,看看其执行计划:
explain select id,phone,name from tb_user where phone='17799990000' and name='吕布';

通过上述执行计划我们可以看出来,在
and
连接的两个字段
phone
、
name
上都是有单列索引的,但是最终mysql
只会选择一个索引,也就是说,只能走一个字段的索引,此时是会回表查询的。
紧接着,我们再来创建一个
phone
和
name
字段的联合索引来查询一下执行计划。
create unique index idx_user_phone_name on tb_user(phone,name);

此时,查询时,就走了联合索引,而在联合索引中包含 phone、name的信息,在叶子节点下挂的是对应的主键id,所以查询是无需回表查询的。
如果查询使用的是联合索引,具体的结构示意图如下:
在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时,建议建立联合索引,而非单列索引 。
三、索引设计原则
- 针对于数据量较大,且查询比较频繁的表建立索引。
- 针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索 引。
- 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
- 如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
- 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间, 避免回表,提高查询效率。
- 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
- 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询
以上就是本期的全部内容,我们下次见。
分享一张壁纸: 
















 359
359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











