







一、函数
抽象是隐藏多余细节的艺术。忽略一个主题中与当前目标无关的东西,专注的注意与当前目标有关的方面( 就是把现实世界中的某一类东西, 提取出来, 用程序代码表示, 抽象出来的一般叫做类或者接口)。在面向对象的概念中,抽象的直接表现形式通常为类。Python基本上提供了面向对象编程语言的所有元素。
抽象并不打算了解全部问题, 而是选择其中的一部分,暂时不用部分细节。抽象包括两个方面,一个数据抽象,二是过程抽象
- 数据抽象 -->表示世界中一类事物的特征,就是对象的属性.比如鸟有翅膀,羽毛等(类的属性)
- 过程抽象 -->表示世界中一类事物的行为,就是对象的行为.比如鸟会飞,会叫(类的方法)
1.自定义函数
函数指将常用的代码以固定的格式封装(包装)成一个独立的模块并可以重复使用它。函数先定义,后调用,即先将函数体代码保存,然后将内存地址赋值给函数名,函数名是对这段代码的引用。
def 函数名(参数1,参数2,...):
"""文档描述"""
函数体
return 值
- def: 定义函数的关键字
- 函数名:函数名指向函数内存地址,是对函数体代码的引用。函数的命名应该反映出函数的功能
- 括号:括号内定义参数,参数可有可无,且无需指定参数的类型
- 冒号:括号后要加冒号,然后在下一行开始缩进编写函数体的代码
- “”“文档描述”“”: 描述函数功能,参数介绍等信息的文档,非必要,但是建议加上,从而增强函数的可读性。放在函数开头的字符串称为文档字符串(docstring),将作为函数的一部分存储起来。
- 函数体:由语句和表达式组成
- return 值:定义函数的返回值,return可有可无
函数的使用分为定义阶段与调用阶段,定义函数时只检测语法,不执行函数体代码。函数名加括号即函数调用,只有调用函数时才会执行函数体代码。
1)定义
1.无参函数
def 函数名():
函数体
2.有参函数
def 函数名(参数,参数...):
函数体
3.空函数
函数体为pass代表什么都不做,称之为空函数。
def 函数名():
pass
2)调用
#定义阶段
def foo():
print('in the foo')
bar()
def bar():
print('in the bar')
#调用阶段
foo()
按照在程序出现的形式和位置,可将函数的调用形式分为三种
def add(a,b):
print(a+b)
return a+b
# 语句的形式:只加括号调用函数
add(1,2)
# 表达式形式
# 1.赋值表达式
res = add(1,2)
# 2.数学表达式
add(1,2)*10
# 函数调用可以当做参数
add(add(1,2),3)
3)callable()
要判断某个对象是否可调用,可使用内置函数callable。
import math
x = 1
y = math.sqrt
print(callable(x))
# False
print(callable(y))
# True
print(fn) # 其实就是在打印函数对象,也就是内存地址
print(fn()) # 其实就是在打印fn()的返回值
4)返回值
- return将函数执行结果返回给调用者。返回值无类型限制,可将多个返回值放到一个元组内。返回多个值时用逗号分隔,被return返回成一个元祖。
- return是函数结束的标志,函数运行到return会立刻终止运行,将return后的值当做本次运行的结果返回。
- 函数体内没有return,或者return后没有任何东西,就是返回一个None
2.函数参数
函数的参数分为形式参数和实际参数,简称形参和实参。
- 形参:在定义函数时,括号内声明的参数。形参本质就是一个变量名,用来接收外部传来的值
- 实参:在调用函数时,括号内传入的值,值可以是常量、变量、表达式或三者的组合
# 实参是常量
res = my_min(1, 2)
# 实参是变量
a = 1
b = 2
res = my_min(a, b)
# 实参是表达式
res = my_min(10 * 2, 10 * my_min(3, 4))
# 实参可以是常量、变量、表达式的任意组合
a = 2
my_min(1, a, 10 * my_min(3, 4))
在调用阶段,实参(变量值)会绑定给形参(变量名),这种绑定关系只能在函数体内使用,实参与形参的绑定关系在函数体调用时生效,函数调用结束后解除绑定关系
1)位置参数
位置参数指按照从左到右的顺序依次定义的参数
位置形参:按照从左到右的顺序直接定义的“变量名”
特点:必须被传值,多一个少一个都不行
位置实参:在函数调用阶段,按照从左到右的顺序依次传入的值
特点:按照顺序与形参一一对应
2)关键字参数
- 关键字实参:在函数调用阶段,按照key=value的形式传入的值
- 特点:指名道姓的给某个形参传值,可以完全不参照顺序,可以指定默认值。
- 与位置实参混合使用时,位置实参必须在关键字实参前,且不能为同一个形参重复传值
# 给参数指定默认值后,调用函数时可不提供它!可以根据需要,一个参数值也不提供、提供部分参数值或提供全部参数值。
def hello_3(greeting='Hello', name='world'):
print('{}, {}!'.format(greeting, name))
print(hello_3())
# Hello, world!
print(hello_3('Greetings'))
# Greetings, world!
print(hello_3('Greetings', 'universe'))
# Greetings, universe!
# 如果提供参数name,必须同时提供参数greeting。如果只想提供参数name,并让参数greeting使用默认值:
print(hello_3(name='Gumby'))
# Hello, Gumby!
通常不应结合使用位置参数和关键字参数。除非必不可少的参数很少,而带默认值的可选参数很多,否则不应结合使用关键字参数和位置参数
# 如函数hello可能要求必须指定姓名,而问候语和标点是可选的。
def hello_4(name, greeting='Hello', punctuation='!'):
print('{}, {}{}'.format(greeting, name, punctuation))
# 调用函数
hello_4('Mars')
# Hello, Mars!
hello_4('Mars', 'Howdy')
# Howdy, Mars!
hello_4('Mars', 'Howdy', '...')
# Howdy, Mars...
hello_4('Mars', punctuation='.')
# Hello, Mars.
hello_4('Mars', greeting='Top of the morning to ya')
# Top of the morning to ya, Mars!
# 如果给参数name也指定了默认值,最后一个调用就不会引发异常
hello_4()
# 报错
3)默认参数
默认形参:在定义阶段,就已经被赋值的形参,称之为默认参数
特点:在定义阶段就已经被赋值,意味着在调用阶段可以不用为其赋值
注意:与位置形参混用时,位置形参必须在默认形参前
# 默认形参的值是在函数定义阶段被赋值的,准确的说被赋予的是值的内存地址
# 示范1:
m = 2
def func(x, y=m): # y绑定了2的内存地址
print(x, y)
m = 3
func(1)
# 结果还是 1 2
# 示范2:
m = [11, ]
def func(x, y=m):
print(x, y)
m.append(333)
func(1)
# 结果为:1 [11, 333]
# 虽然默认值可以被指定为任意数据类型,但是不推荐使用可变类型(失去了默认的意义,不可预知结果)
4)可变参数
参数长度可变指在调用函数时实参的个数可以不固定。在调用函数时实参的定义常按位置或按关键字两种形式。
-
可变长度的位置实参
*args*形参名:用来接收溢出的位置实参,溢出的位置实参会被*保存成元祖格式,然后赋值给其后的形参名,*后约定俗成是args -
可变长度的关键字实参
**kwargs**形参名:用来接收溢出的关键字实参,溢出的关键字实参会被**保存成字典格式,然后赋值给其后的形参名,**后约定俗成是kwargs -
*,**可以用在实参中,实参中带*,先将*后的值炸开成位置实参。 -
*和**混合使用,*args必须在**kwargs之前
def print_params_4(x, y, z=3, *pospar, **keypar):
print(x, y, z)
print(pospar)
print(keypar)
print_params_4(1, 2, 3, 5, 6, 7, foo=1, bar=2)
# 1 2 3
# (5, 6, 7)
# {'foo': 1, 'bar': 2}
print_params_4(1, 2)
# 1 2 3
# ()
# {}
def add(x, y):
return x + y
params = (1, 2)
print(add(*params))
# 3
使用这些拆分运算符来传递参数无需操心参数个数之类的问题,在调用超类的构造函数时特别有用
def foo(x, y, z, m=0, n=0):
print(x, y, z, m, n)
def call_foo(*args, **kwds):
print("Calling foo!")
foo(*args, **kwds)
5)命名关键字参数
定义函数时,* 后定义的参数称之为命名关键字参数
def func(a,b,*args,x,y): # 其中,x,y称之为命名关键字参数
pass
func(1,2,x=3,y=4) # 命名关键字实参必须按照key=value的形式为其传值
6)组合使用
所有参数可任意组合使用,但定义顺序必须是:位置参数、默认参数、*args、命名关键字参数、**kwargs
# 可变参数*args与关键字参数**kwargs通常组合使用,如果一个函数的形参为*args与**kwargs,那么该函数可以接收任何形式、任意长度的参数
# 在该函数内部还可以把接收到的参数传给另外一个函数
def func(x,y,z):
print(x,y,z)
def wrapper(*args,**kwargs):
func(*args,**kwargs)
wrapper(1,z=3,y=2)
#1 2 3
按照上述写法,为函数wrapper传参时,其实遵循的是函数func的参数规则,调用函数wrapper的过程分析如下:
位置实参1被*接收,以元组形式保存并赋值给args,args=(1,),关键字实参z=3,y=2被**接收,以字典形式保存并赋值给kwargs,kwargs={‘y’: 2, ‘z’: 3},执行func(*args,**kwargs)。
即func(*(1,),** {'y': 2, 'z': 3}),等同于func(1,z=3,y=2)。
def story(**kwargs):
return 'Once upon a time, there was a ' \
'{job} called {name}.'.format_map(kwargs)
def power(x, y, *others):
if others:
print('Received redundant parameters:', others)
return pow(x, y)
# def interval(start, stop=None, step=1):
# """Imitates range() for step > 0"""
# result = []
# if stop is None: # 如果没有给参数stop指定值,
# for j in range(start):
# result.append(j)
# else:
# for i in range(start, stop, step):
# result.append(i)
# return result
def interval(start, stop=None, step=1):
"""Imitates range() for step > 0"""
if stop is None: # 如果没有给参数stop指定值,
start, stop = 0, start # 就调整参数start和stop的值
result = []
i = start # 从start开始往上数
while i < stop: # 数到stop位置
result.append(i) # 将当前数的数附加到result末尾
i += step # 增加到当前数和step(> 0)之和
return result
print(story(job='king', name='Gumby'))
# Once upon a time, there was a king called Gumby.
print(story(name='Sir Robin', job='brave knight'))
# Once upon a time, there was a brave knight called Sir Robin.
params = {'job': 'language', 'name': 'Python'}
print(story(**params))
# Once upon a time, there was a language called Python.
del params['job']
print(story(job='stroke of genius', **params))
# Once upon a time, there was a stroke of genius called Python.
print(power(2, 3))
# 8
print(power(3, 2))
# 9
print(power(y=3, x=2))
# 8
params = (5,) * 2
print(power(*params))
# 3125
print(power(3, 3, 'Hello, world'))
# Received redundant parameters: ('Hello, world',)
# 27
print(interval(10))
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(interval(1, 5))
# [1, 2, 3, 4]
print(interval(3, 12, 4))
# [3, 7, 11]
print(power(*interval(3, 7)))
# Received redundant parameters: (5, 6)
# 81
3.函数使用
1)被引用
def add(x,y):
return x+y
func = add
res = func(1,2)
print(res)
2)作为元素
def add(x,y):
return x+y
dic={'add':add,'max':max}
print(dic)
# {'add': <function add at 0x100661e18>, 'max': <built-in function max>}
res = dic['add'](1,2)
print(res)
# 3
3)作为参数
def add(x,y):
return x+y
def foo(x,y,func):
return func(x,y)
res = foo(1,2,add)
print(res)
# 3
4)作为返回值
def add(x,y):
return x+y
def bar():
return add
func = bar()
res = func(1, 2)
print(res)
# 3
4.闭包函数
1)闭包函数定义
在Python中,闭包函数是指一个函数定义在另一个函数的内部,并且引用了外部函数中的变量。即使外部函数已经执行完毕,这些变量仍然可以被内部函数访问和使用。闭包函数的特点是它能够“记住”外部函数的环境。闭包函数的定义条件:
- 嵌套函数:必须有一个函数定义在另一个函数的内部。
- 引用外部变量:内部函数必须引用外部函数中的变量。
- 返回内部函数:外部函数必须返回这个内部函数。
闭包函数 = 名称空间和作用域+函数嵌套+函数对象(闭包 = 内部函数+定义函数时的环境)
# 闭的意思是,该函数是内嵌函数,在别的函数内部定义出来的函数
def index():
def foo():
pass
# 包的意思指的是该函数包含对外层函数(不是对全局作用域)作用域名字的引用
def index():
x = 1
def foo():
print(x)
# 外部函数必须返回这个内部函数。
def f1():
x = 333
def f2():
print(x)
return f2
在一个内部函数里,对在外作用域(但不是在全局作用域)的变量进行引用,那么内部函数就被认为是闭包。
def f():
x = 10
def g():
print(x)
return g
f()() # f()相当于g f()()相当于g()
# 10
h = f()
h()
# 10
下面不属于闭包函数
# 不是闭包函数,因为y属于g,没有对外部函数进行引用
def f():
x = 10
def g():
y = 5
print(y)
return g
f()() # f()相当于g f()()相当于g()
h = f()
h()
# 也是闭包函数
def f(x):
def g():
print(x)
return g
h = f(1)
h()
2)闭包函数传参方式
闭包函数传参有两种方式:
-
直接传参:把函数体需要的参数定义成形参。
def outer_function(x): def inner_function(): print(x) return inner_function closure_function = outer_function(10) closure_function() # 输出: 10 -
通过闭包传参:在闭包函数中引用外部函数的变量。
def outer_function(x): def inner_function(): print(x) return inner_function closure_function = outer_function(10) closure_function() # 输出: 10
下面是一个完整的闭包函数示例:
def make_counter():
count = 0
def counter():
nonlocal count
count += 1
return count
return counter
counterA = make_counter()
print(counterA()) # 输出: 1
print(counterA()) # 输出: 2
counterB = make_counter()
print(counterB()) # 输出: 1
在这个示例中,make_counter 返回一个闭包函数 counter,该函数可以访问和修改外部函数 make_counter 的局部变量 count。
3)闭包函数应用
闭包函数在以下情况下非常有用:
- 数据隐藏:闭包可以用来隐藏数据,避免使用全局变量。
- 工厂函数:可以用来创建带有特定参数的函数,例如生成不同的乘法器函数。
- 装饰器:Python中的装饰器大量使用了闭包函数。
5.函数递归
递归函数是指在函数内部调用自身的函数。递归函数通常用于解决那些可以通过将问题分解为更小的相同类型的子问题来解决的问题。递归函数的设计和使用需要特别注意以下几个方面:
1)无穷递归
无穷递归是指递归函数在没有适当的终止条件(基线条件)时,会无限制地调用自身,导致程序崩溃或栈溢出错误。例如:
def infinite_recursion():
return infinite_recursion()
这个函数没有任何终止条件,因此会一直调用自身,导致无穷递归。
def recursion():
return recursion()
这个函数中的递归称为无穷递归,理论上永远不会结束。正常的递归函数包含下面两部分:
- 基线条件(针对最小的问题):满足这种条件时函数将直接返回一个值。
- 递归条件:包含一个或多个调用,这些调用旨在解决问题的一部分。
假设计算数字n的阶乘。可使用循环:
def factorial(n):
result = n
for i in range(1, n):
result *= i
return result
使用函数来实现:
def factorial(n):
if n == 1:
return 1
else:
return n * factorial(n - 1)
计算幂:
def power(x, n):
if n == 0:
return 1
else:
return x * power(x, n - 1)
函数的递归调用是函数嵌套调用的特殊形式,指在调用一个函数的过程中又直接或间接的调用本身
递归函数就是函数内部自己调用自己
递归的本质就是循环,最重要的就是找到出口(停止的条件),因为python会一直开辟内存空间
2)基线条件和递归条件
递归函数通常包含两个部分:基线条件和递归条件。
- 基线条件(Base Case):这是递归停止的条件。当满足基线条件时,函数将返回一个值,不再进行递归调用。基线条件是确保递归能够终止的关键。
- 递归条件(Recursive Case):这是函数继续调用自身的条件。在递归条件中,函数将问题分解为更小的子问题,并调用自身来解决这些子问题。
循环运行的方案有两种:while循环,for循环
def f1(n):
if n<5:
print(n)
n +=1
f1(n)
f1(0)
# 0
# 1
# 2
# 3
# 4
# 递归最大的层级是1000层
import sys
1.查看层级
res = sys.getrecursionlimit()
print(res)
2.设置层级
sys.setrecursionlimit(1000) # 虽然可以设置,但不建议去设置
强调:递归调用不应该无限的调用下去,必须在满足某种条件下结束递归调用
递归调用的阶段:
1.两种工作原理
回溯:一层一层调用下去
递推:满足某种结束条件,结束递归调用,然后一层一层返回
2.阶段
data = [1, [2, [3, [4, [5]]]]]
# 通常情况
for x in data:
if type(x) is list: #如果是列表,应该先循环再判断,即重新运行本身的代码
pass
else:
print(x)
# 1
# 用递归
def f1(data):
for x in data:
if type(x) is list:
# 如果是列表,应该再循环,在判断,即重新运行本身的代码
f1(x)
else:
print(x)
f1(data)
# 1
# 2
# 3
# 4
# 5
3)示例
(1)计算阶乘
以下是一个计算阶乘的递归函数示例:
def factorial(n):
if n == 1: # 基线条件
return 1
else:
return n * factorial(n - 1) # 递归条件
# 测试
num = 5
result = factorial(num)
print(f"{num} 的阶乘是: {result}")
在这个例子中,factorial 函数的基线条件是 n == 1,当 n 等于 1 时,函数返回 1。递归条件是 n * factorial(n - 1),函数通过调用自身来计算 n 的阶乘。
(2)斐波那契数列
另一个常见的递归函数示例是计算斐波那契数列:
def fibonacci(n):
if n <= 1: # 基线条件
return n
else:
return fibonacci(n - 1) + fibonacci(n - 2) # 递归条件
# 测试
num = 6
result = fibonacci(num)
print(f"斐波那契数列的第 {num} 项是: {result}")
在这个例子中,fibonacci 函数的基线条件是 n <= 1,当 n 小于或等于 1 时,函数返回 n。递归条件是 fibonacci(n - 1) + fibonacci(n - 2),函数通过调用自身来计算斐波那契数列的第 n 项。
希望这些示例能帮助你更好地理解递归函数的概念和使用方法!如果你有任何问题或需要进一步的解释,请随时告诉我。
6.匿名函数
lambda 参数1,参数2,...: expression
f = lambda x: x * x
print(f(5))
# 25
# 1、定义
lambda x,y,z:x+y+z
#等同于
def func(x,y,z):
return x+y+z
# 2、调用
# 方式一:
res=(lambda x,y,z:x+y+z)(1,2,3)
# 方式二:
func=lambda x,y,z:x+y+z # “匿名”的本质就是要没有名字,所以此处为匿名函数指定名字是没有意义的
res=func(1,2,3)
总结:
1.lambda并不会带来程序运行效率的提高,只会使代码更加的简洁
2.lambda可读性不好,lambda内不要有循环,有就使用标准函数来完成(目的是为了代码有可重用性和可读性)
3.lambda是为了减少单行函数的定义而存在。如果一个函数只有一个返回值,一句代码,就可以使用lambda
匿名函数与有名函数有相同的作用域,但匿名函数引用计数为0,即使用一次就释放,所以匿名函数用于临时使用一次的场景,匿名函数通常与其他函数配合使用
7.常用内置函数
1)help()
特殊的内置函数help很有用。在交互式解释器中,可使用它获取有关函数的信息,其中包含函数的文档字符串
def square(x):
"""Calculates the square of the number x."""
return x * x
print(help(square))
# Help on function square in module __main__:
#
# square(x)
# Calculates the square of the number x.
#
# None
print(square(x=3))
# 9
1)callable()
callable函数是Python内置函数之一,用于判断一个对象是否可调用。如果对象可以被调用,返回True;否则返回False。可调用对象包括函数、方法、类以及实现了__call__方法的对象。
callable(object)
# object为要判断的对象。
2)type()
返回对象类型
print(type(23))
# <class 'int'>
2)abs()
2)sum()
2)round()
abs() 求绝对值
print(abs(-1))
sum() 求和
print(sum([1, 2, 3, 4, 5],2)) # 给列表求和后再加2
print(sum((1, 2, 3, 4, 5),1)) # 给元组求和后再加1
round() 四舍五入
def ab_sum(a,b,f):
return f(a)+f(b)
print(ab_sum(-1, -4,abs))
print(ab_sum(-1, -4.3,round))
def xfs(x):
return -x
def ab_sum(a,b,f):
return f(a)+f(b)
# print(ab_sum(-1, -4,abs))
# print(ab_sum(-1, -4.3,round))
print(ab_sum(-1, -4,xfs)) # 求两个相反数的和
2)map()
map(func,seq)第一个参数是给一个函数,第二个参数是给一个序列类型
list1 = [-1,-2,-3,-4,-5]
list2 = []
for i in list1:
list2.append(i+1)
print(list2)
由于map返回的是一个迭代器,我们想看结果就需要转为list,转成元组也可以
list1 = [-1,-2,-3,-4,-5]
print(list(map(abs,list1)))
list1 = [1,2,3,4,5]
def add1(x):
return x+1
print(list(map(add1,list1)))
list1 = [1,2,3,4,5]
print(list(map(lambda x:x+1,list1)))
总结:
1.map内置函数的作用就是操作序列中的所有元素,并且返回一个迭代器,迭代器要转列表
2.咱们的lambda表达式可以专门配合我们的高阶内置函数来做简单实现
2)filter()
filter(func,seq)第一个参数是给一个函数,第二个参数是给一个序列类型,用于过滤序列,过滤掉不符合条件的元素,结果可以通过list转换
# 保留一个序列中所有的偶数
普通写法:
list1 = [1,2,3,4,5,6,7,8,9,10]
for i in list1:
if i % 2 !=0: # 说明i是一个奇数
list1.remove(i)
print(list1)
高阶写法:
def fn(x):
return x%2==0
print(list(filter(fn,list1)))
lambda写法:
print(list(filter(lambda x:x%2==0,list1)))
2)sorted
sorted(可迭代对象,key=,reverse=True)
排序,返回一个排序后的序列
list1 = [2,4,1,3,5,6,9,7]
print(sorted(list1))
print(sorted(list1,reverse=True))
list1 = ["七零_69","久违_79","乃荣_89","小川_59","阿飞_100"]
def f(x):
arr = x.split("_")
return int(arr[1])
print(sorted(list1,key=f))
print(sorted(list1,key=lambda x:int(x.split("_")[1])))
max(可迭代对象,key=函数):根据函数获取可迭代对象的最大值
min(可迭代对象,key=函数):根据函数获取可迭代对象的最小值
list1 = ["七零_69","久违_79","乃荣_89","小川_59","阿飞_100"]
def f(x):
arr = x.split("_")
return int(arr[1])
print(min(list1,key=f))
print(max(list1,key=lambda x:int(x.split("_")[1])))
python提供的,可以直接拿来使用的
| 常用 | 计算 | 进制转换 | 判断 |
|---|---|---|---|
| type | sum | bin | all |
| 查看类型 | 求和 | 十进制转二进制 | 是否全部为True |
| id | max | oct | any |
| 查看内存地址 | 最大值 | 十进制转八进制 | 是否存在True |
| range | min | hex | |
| 可创建一个整数列表,一般用在 for 循环中 | 最小值 | 十进制转十六进制 | |
| enumerate | divmod | ord | |
| 可以将索引与元素组合为一个元组。 | 求商和余数 | 获取字符对应的unicode码点(十进制) | |
| round | chr | ||
| 小数点后n位(四舍五入) | 根据码点(十进制)获取对应字符 |
二、装饰器
1.定义与用途
- 装饰器定义:装饰器是一个接受其他函数作为参数的函数,它返回一个新的函数。这个新的函数通常会在原函数的基础上添加额外的功能,装饰器本身是一种特殊的函数或类。
- 装饰的含义:装饰器的“装饰”意指为被装饰的函数或方法增加新的功能,而不修改其源代码。它们通常用于增强函数的行为,如日志记录、性能监控、事务管理、缓存机制、权限检查等。
- 开闭原则:在软件设计中,开闭原则强调对扩展开放,对修改封闭。装饰器可以帮助我们在不修改现有代码的情况下扩展功能,从而满足开闭原则的要求。
装饰器非常适合用于需要插入日志、性能测试、事务处理、缓存、权限校验等场景。这些操作通常与业务逻辑无关,但又是必须的,通过装饰器可以将这些横切关注点(cross-cutting concerns)从业务逻辑中分离出来,使代码更加清晰和模块化。
2.实现原理
- 函数嵌套:装饰器的实现通常依赖于函数嵌套,即在一个函数内定义另一个函数。
- 闭包:通过闭包,装饰器可以捕获和存储外部函数的状态,使得内部函数可以访问这些状态。
- 函数对象:在Python中,函数是第一类对象,可以像变量一样传递和操作。装饰器利用这一特性,将原函数替换为增强后的函数。
3.闭包与装饰器
1)闭包
定义: 闭包是一个函数,它可以访问另一个函数的作用域中的变量,即使在外部函数执行完毕之后,这些变量也不会被销毁。
(1)闭包的作用
- 保存外部函数的变量:闭包可以保存外部函数的变量状态,即使外部函数已经执行完毕,内部函数依然可以访问这些变量。
(2)闭包的形成条件
- 函数嵌套:闭包需要有一个外部函数和一个内部函数。
- 内部函数使用外部函数的变量或参数:内部函数必须引用外部函数中的变量或参数。
- 外部函数返回内部函数:外部函数需要返回内部函数,使得内部函数可以在外部使用。这返回的内部函数就是闭包。
2)装饰器
定义: 装饰器是一种特殊的闭包函数,用于在不修改原函数源代码和调用方式的情况下,为函数增加新的功能。
(1)装饰器的作用
- 扩展已有函数的功能:在不改变原函数代码的前提下,为其增加额外的功能。这通常用于日志记录、性能计时、事务处理、权限验证等场景。
(2)装饰器的形成条件
- 不修改已有函数的源代码:装饰器的使用不应直接修改原函数的代码。
- 不修改已有函数的调用方式:使用装饰器后,原函数的调用方式保持不变。
- 增加额外功能:通过装饰器,为已有函数添加新的功能。
3)闭包与装饰器的区别
- 本质上: 装饰器是一种闭包,因为它包含一个内部函数并且能够访问外部函数的变量。
- 特殊性: 装饰器是一个特殊的闭包,其特点是它的参数有且只有一个,并且这个参数必须是一个函数。这个参数函数就是被装饰的对象。
4.装饰器的分类
- 无参装饰器:最简单的装饰器,不接受任何参数,只装饰一个函数。
- 有参装饰器:接受参数的装饰器,这些参数可以用来配置装饰器的行为。
装饰器的作用是在不修改被装饰对象的源代码和调用方式的前提下,为被装饰对象添加额外的功能。这种设计方式允许代码的扩展性更好,同时保证原有功能的稳定性和安全性。
1)无参装饰器
希望在不修改现有函数代码和调用方式的前提下,为函数添加统计执行时间的功能。假设有一个名为 index 的函数,
import time
# 暂停3秒,然后打印一条消息。
def index():
time.sleep(3)
print('Welcome to the index page')
return 200
index() # 调用函数
最直接的方法是在函数调用前后加入计时代码,如下:
import time
def index():
time.sleep(3)
print('Welcome to the index page')
return 200
start_time = time.time()
index()
stop_time = time.time()
print('run time is %s' % (stop_time - start_time))
这种方法需要手动修改每个需要计时的函数的调用方式,不符合不修改函数调用方式的原则。
(1)正常定义
考虑到可能要统计其他函数的执行时间,可将其做成一个单独的工具,函数体需要外部传入被装饰的函数从而进行调用,可使用参数的形式传入
import time
def index():
time.sleep(3)
print('Welcome to the index page')
return 200
def wrapper(func): # 通过参数接收外部的值
start_time=time.time()
res=func()
stop_time=time.time()
print('run time is %s' %(stop_time-start_time))
return res
- 但之后函数的调用方式都需要统一改成
wrapper(index) # wrapper(其他函数)
(2)装饰器定义
或者定义一个 timer 装饰器,timer 函数接受一个函数 func 作为参数,并返回一个新的函数 wrapper。当调用 wrapper 时,它会记录开始时间和结束时间,并打印运行时间。
import time
def timer(func):
def wrapper():
start_time = time.time()
result = func() # 调用传入的函数
stop_time = time.time()
print('run time is %s' % (stop_time - start_time))
return result
return wrapper
这里只需将装饰后的函数重新赋值给 index:
index = timer(index)
index() # 现在调用的是被装饰后的函数
(3)装饰器简化语法糖
在Python中,有一种更简洁的方式使用装饰器,就是用 @ 语法:
@timer
def index():
time.sleep(3)
print('Welcome to the index page')
return 200
index() # 直接调用装饰后的函数
这行 @timer 的代码相当于 index = timer(index),它使得代码更简洁和直观。通过这种方式,原始的 index 函数没有被修改,调用方式也保持不变,但它已经具备了自动统计执行时间的功能。
(4)两种定义区别
上面两种方式的作用都是为了统计被装饰函数的执行时间,但它们在实现上有一些关键的不同之处:
-
函数结构和调用方式的不同:
- 第一个函数
wrapper(func):这个函数直接接收一个函数func作为参数,并在内部立即调用它来统计执行时间。它没有返回新的函数,因此不能直接用作装饰器。 - 第二个函数
timer(func):这个函数接收一个函数func作为参数,并返回一个新的函数wrapper。这个wrapper函数内部调用func并计算执行时间。这样设计的好处是timer函数本身可以作为装饰器使用。
- 第一个函数
-
可复用性和装饰器的使用:
- 第一个
wrapper(func):因为它没有返回新的函数,所以每次调用都需要手动传递被测量的函数,这在使用上不方便,也不能用于装饰器语法@decorator。 - 第二个
timer(func):返回一个新的函数,这个新函数内部包裹了原函数的调用,因此可以很方便地用作装饰器,直接用@timer就能为多个函数添加计时功能。
- 第一个
具体来说:
-
第一个
wrapper(func)的用法是:result = wrapper(index)它会立即执行
index函数并返回结果。 -
第二个
timer(func)的用法是:index = timer(index) index()或者更常见的使用装饰器语法:
@timer def index(): time.sleep(3) print('Welcome to the index page') return 200这种方式
index函数被重新定义为计时版本,使用起来更自然和方便。
因此,虽然它们的核心功能(统计函数执行时间)相同,但第二种方式更符合装饰器的定义和使用方式,使得代码更加模块化和易用。
2)有参装饰器
在第一个例子中创建了一个简单的装饰器timer,用来测量函数的执行时间。最初的实现没有考虑到被装饰函数可能有参数的情况,因此会在调用有参数的函数时抛出错误。
import time
def timer(func):
def wrapper(): # 这个wrapper函数没有接受参数
start_time = time.time()
res = func() # 调用被装饰的函数func
stop_time = time.time()
print('run time is %s' % (stop_time - start_time))
return res
return wrapper
def home(name):
time.sleep(5)
print('Welcome to the home page', name)
home = timer(home)
home('谢大哥') # 这里会抛出TypeError异常
这里的 TypeError 发生是因为 wrapper() 没有接受任何参数,而 home('谢大哥') 调用了 wrapper('谢大哥')。
(1)装饰器接收带参函数
为了使其接受任意数量和类型的参数。使用 *args 和 **kwargs 来捕获所有传递给 wrapper 的位置参数和关键字参数,并将这些参数传递给被装饰的函数 func。
import time
def timer(func):
def wrapper(*args, **kwargs): # 使用*args和**kwargs来接收任意参数
start_time = time.time()
res = func(*args, **kwargs) # 将参数传递给被装饰的函数
stop_time = time.time()
print('run time is %s' % (stop_time - start_time))
return res
return wrapper
def home(name):
time.sleep(5)
print('Welcome to the home page', name)
home = timer(home)
home('谢大哥') # 现在不会抛出异常
(2)装饰器简化语法糖
为了更方便地使用装饰器,Python提供了装饰器语法糖 @decorator_name。在函数定义前加上装饰器名,这个装饰器会自动应用到函数上。
使用装饰器语法糖的代码:
import time
def timer(func):
def wrapper(*args, **kwargs):
start_time = time.time()
res = func(*args, **kwargs)
stop_time = time.time()
print('run time is %s' % (stop_time - start_time))
return res
return wrapper
@timer # 等价于 home = timer(home)
def home(name):
time.sleep(5)
print('Welcome to the home page', name)
home('谢大哥') # 直接调用即可
(3)叠加多个装饰器
多个装饰器可以叠加使用。在这种情况下,装饰器从内到外依次应用。也就是说,最内层的装饰器先应用,然后是外层的装饰器。
叠加装饰器的示例:
@deco3
@deco2
@deco1
def index():
pass
# 等价于以下调用
index = deco3(deco2(deco1(index)))
(4)带参数的装饰器
装饰器本身也可以带参数。此时,需要多一层函数来接受参数。
带参数的装饰器示例:
def outer(mode):
def deco(func):
def wrapper(*args, **kwargs):
if mode == 'QQ':
res = func(*args, **kwargs)
return res
elif mode == '微信':
print('无法登录')
return wrapper
return deco
@outer('QQ') # 这里 outer('QQ') 返回的函数应用到 test 上
def test(name):
print(f'{name}登录成功')
test('老tou') # 打印:老tou登录成功
(5)保留原函数的元数据
使用装饰器时,原函数的名称和文档字符串(docstring)可能会被覆盖。为了保留这些信息,可以使用 functools.wraps 装饰 wrapper 函数。
from functools import wraps
def deco(func):
@wraps(func) # 保留func的元数据
def wrapper(*args, **kwargs):
res = func(*args, **kwargs)
return res
return wrapper
@deco
def test(name):
"""
这是登录的函数
:param name:
:return:
"""
print(f'{name}登录成功')
print(help(test)) # 现在会显示 test 函数的文档字符串
@wraps(func) 的作用是将 func 的元数据复制到 wrapper 上,这样使用 help(test) 时仍然能够看到原 test 函数的文档字符串和其他元信息。
三、名称空间和作用域
在Python中,名称空间(Namespace)是存放与对象映射/绑定关系的名字的地方。例如,当你执行 x = 3 时,Python会申请内存空间存放对象 3,然后将名字 x 与 3 的绑定关系存放于命名空间中。不同的名称空间可以存放相同的名字。
作用域就是一个变量可以使用的范围,主要分为全局作用域和函数作用域(局部作用域),全局作用域是最外层的作用域,函数作用域是通过函数创建的一个独立作用域,函数可以嵌套,所以作用域也可以嵌套。作用域也称命名空间。
- 内置命名空间
- 全局命名空间
- 局部命名空间
1.命名空间分类
命名空间是存放与对象映射/绑定关系的名字的地方
1)内置命名空间
第一个被加载的命名空间,用来存放内置的名字,比如内建函数名
print(max)
# <built-in function max> # built-in内建
存放的名字:存放的python解释器内置的名字
存活周期:伴随python解释器的启动/关闭而产生/回收,解释器启动则产生,关闭则销毁
2)全局命名空间
第二个被加载的命名空间,文件执行过程中产生的名字都会存放于该命名空间中
import sys #模块名sys
x=1 #变量名x
if x == 1:
y=2 #变量名y
def foo(x): #函数名foo
y=1
Class Bar: #类名Bar
pass
存放的名字:只要不是函数内定义,也不是内置的,剩下的都是全局命名空间的名字
存放周期:伴随python文件的开始执行/执行完毕而产生/回收,文件执行则产生,运行完毕后销毁
3)局部命名空间
函数的形参、函数内定义的名字都会被存放于该命名空间中
def foo(x):
y=3 #调用函数时,才会执行函数代码,名字x和y都存放于该函数的局部命名空间中
存放的名字:在调用函数时,运行函数体代码过程中产生的函数内的名字
存活周期:伴随函数的调用/结束而临时产生/回收,在调用函数时存活,函数调用完毕后则销毁
2.顺序
1)加载顺序
内置命名空间>全局命名空间>局部命名空间
2)销毁顺序
局部命名空间>全局命名空间>内置命名空间
3)查找优先级
当前所在的位置向上一层一层查找
查找一个名字,必须从三个命名空间之一找到,
查找顺序为:局部命名空间->全局命名空间->内置命名空间
3.查找
- 内置命名空间——》全局作用域
- 全局命名空间——》全局作用域
- 局部命名空间——》局部作用域
全局作用域范围内的名字全局存活(除非被删除,否则在整个文件执行过程中存活)、全局有效(在任意位置都可以使用)
局部作用域中的名字属于局部范围。该范围内的名字临时存活(即在函数调用时临时生成,函数调用结束后就释放)、局部有效(只能在函数内使用)
1)局部查找
起始位置是局部作用域,先查找局部命名空间,再去全局作用域查找,最后都没有找到就会抛出异常
x=100 #全局作用域的名字x
def foo():
x=300 #局部作用域的名字x
print(x) #在局部找x
foo()#结果为300
2)全局查找
(1)locals()
(2)globals()
起始位置是全局作用域,先查找全局命名空间,再查找内置命名空间,最后都没有找到就会抛出异常
x=100
def foo():
x=300 #在函数调用时产生局部作用域的名字x
foo()
print(x) #在全局找x,结果为100
提示:可以调用内建函数locals()和globals()来分别查看局部作用域和全局作用域的名字,查看的结果都是字典格式。在全局作用域查看到的locals()的结果等于globals()
3)内嵌函数查找
# 在内嵌函数内查找名字时,会优先查找自己局部作用域的名字,然后由内而外层层查找外部嵌套函数定义的作用域,没有找到,则查找全局作用域
x=1
def outer():
x=2
def inner(): # 函数名inner属于outer这一层作用域的名字
x=3
print('inner x:%s' %x)
inner()
print('outer x:%s' %x)
outer()
#结果为
# outer x:1
# inner x:3
# 实参为可变类型时返回原值
num_list=[1,2,3]
def foo():
num_list.append(5)
foo()
print(num_list)
#结果为
# [1, 2, 3, 5]
(1)global()
#函数内无论嵌套多少层,都可查看全局作用域的名字,若在函数内修改全局命名空间中名字的值,当值为不可变类型时,需用到global关键字
x=1
def foo():
global x #声明x为全局命名空间的名字
x=2
foo()
print(x) #结果为2
(2)nonlocal()
# 嵌套多层的函数使用nonlocal关键字可将名字声明为来自外部嵌套函数定义的作用域(非全局)
def f1():
x=2
def f2():
nonlocal x
x=3
f2() #调用f2(),修改f1作用域中名字x的值
print(x) #在f1作用域查看x
f1() # 结果 3
# nonlocal x会从当前函数的外层函数开始一层层去查找名字x,若是一直到最外层函数都找不到,则会抛出异常
四、类与对象
-
面向对象是一种抽象化的编程思想,面向对象作用就是简化代码。面向对象就是将编程当成一种事物,对于外界事物可直接使用而不用管它内部的具体实现步骤,而编程就是设置这个事物可以做什么。
-
面向对象编程中两个重要组成部分:类,对象。
1.类的组成
- 变量:类中叫属性
- 函数:类中叫方法
- 对象:类通过实例化产生对象
- 实例:对象是类的实例
python中一切皆为对象,python类本身也是一种对象,我们可以称其为类对象。对象=属性+方法,对象是类的实例。类是对一系列具有相同特征和行为的事物的统称,是一个抽象化概念,不是真实存在的事物。类主要是定义对象的结构,以类为模板创建对象。类不但包含方法定义,还包含所有实例共享的数据。
确定需要哪些类以及这些类应包含哪些方法时,尝试像下面这样做。
- 将有关问题的描述(程序需要做什么)记录下来,并给所有的名词、动词和形容词加上标记。
- 在名词中找出可能的类。
- 在动词中找出可能的方法。
- 在形容词中找出可能的属性。
- 将找出的方法和属性分配给各个类。
2.类的实现
1)定义类
注意:类名要满足标识符规则,同时遵循大驼峰命名规则。
# 定义函数
def 函数名():
函数体
# 定义类
class 类名():
代码
class Washer: # Washer写成Washer()会显得冗余
def wash(self): # 实例方法
print('洗衣服=====')
2)创建对象
# 语法:
对象名 = 类名()
# 创建类
class Washer:
def wash(self): # 实例方法
print('洗衣服=====')
# 创建对象
haier = Washer()
# print(haier)
# 验证功能
# 使用washer功能 在类中叫实例方法/对象方法 ---- 对象名.实例方法名()
haier.wash()
3)self
self是调用改实例方法的对象。
class Washer:
def wash(self):
print('洗衣服')
print(self) # self指的是调用该方法的对象
haier = Washer() # self = haier
print(haier)
haier.wash()
# <__main__.Washer object at 0x0000025093E1B5B0>
# 洗衣服
# <__main__.Washer object at 0x0000025093E1B5B0>
haier1 = Washer()
print(haier1)
haier1.wash()
# <__main__.Washer object at 0x0000025093E1A0E0>
# 洗衣服
# <__main__.Washer object at 0x0000025093E1A0E0>
3.类的命名空间
在class语句中定义的代码都是在一个特殊的命名空间(类的命名空间)内执行的,而类的所有成员都可访问这个命名空间。在类定义中,并非只能包含def语句。
class MemberCounter:
members = 0
def init(self):
MemberCounter.members += 1
m1 = MemberCounter()
m1.init()
print(MemberCounter.members)
# 1
m2 = MemberCounter()
m2.init()
print(MemberCounter.members)
# 2
# 每个实例都可访问这个类作用域内的变量,就像方法一样。
print(m1.members)
# 2
print(m2.members)
# 2
# 在实例中赋值
m1.members = 'three'
print(m1.members)
# three
print(m2.members)
# 2
4.类属性和实例属性
1)设置和访问类属性
- 类属性就是类对象所拥有的属性,它被该类的所有实例对象所共有。
- 类属性可以使用类对象或者实例对象访问
class People:
def __init__(self, name, sex, age):
self.name = name
self.sex = sex
self.age = age
def print_people(self):
print(self.name + "\n" + self.sex + "\n" + self.age)
class Human(People):
def __init__(self, name, sex, age):
super(Human, self).__init__(name, sex, age)
gril1 = Human("谢大姐", "女", "18")
gril2 = Human("小大夫", "女", "18")
print(id(Human("谢大姐", "女", "18"))) # 2949721638544
print(id(Human("小大夫", "女", "18"))) # 2949721638608
print()
print(id(gril1.print_people()))
# 谢大姐
# 女
# 18
# 140725288004808
print(id(gril2.print_people()))
# 小大夫
# 女
# 18
# 140725288004808
print()
print(id(People("谢大姐", "女", "18"))) # 2949721637456
print(id(People("小大夫", "女", "18"))) # 2949721638608
总结:
- 记录的某项数据始终保持一致的时候,则可以定义类属性
- 实例属性要求每个对象为其开辟一份单独的内存空间用来记录属性值,而类属性为全局所共有,仅占用一份内存空间,更加的节省内存空间。
3)添加对象属性
对象属性可以在类里面添加,也可以在类外面添加和获取。
(1)类外添加
# 语法:
对象名.属性名 = 值
class Washer:
def __init__(self):
self.width = None
self.height = None
def wash(self):
print('洗衣服')
haier = Washer()
haier.wash()
# 添加属性
haier.height = 1000 # 高
haier.width = 500 # 宽
# 获取属性
print("洗衣机的高度是:", haier.height)
print("洗衣机的宽度是:", haier.width)
# 洗衣服
# 洗衣机的高度是: 1000
# 洗衣机的宽度是: 500
(2)类内添加
class Washer:
def __init__(self):
self.width = None
self.height = None
def wash(self):
print('洗衣服')
def print_info(self):
"""获取属性"""
print("洗衣机的高度是:", self.height)
print("洗衣机的宽度是:", self.width)
haier2 = Washer()
haier2.wash() # 洗衣服
# 添加属性
haier2.height = 1000 # 高
haier2.width = 500 # 宽
haier2.print_info()
# 洗衣机的高度是: 1000
# 洗衣机的宽度是: 500
# 获取属性
print("洗衣机的高度是:", haier2.height)
print("洗衣机的宽度是:", haier2.width)
# 洗衣机的高度是: 1000
# 洗衣机的宽度是: 500
2)修改类属性
class Wife(object):
gender = '女'
def __init__(self, name, age):
self.name = name
self.age = age
def print_info(self):
print(self.name)
print(self.age)
fubicheng = Wife('符必程', 18)
xiaogong = Wife('小龚', 20)
# 通过类对象修改类属性
# print(Wife.gender)
# Wife.gender = '中性'
# print(Wife.gender)
# print(fubicheng.gender)
# print(xiaogong.gender)
# 不能通过实例对象修改类属性
fubicheng.gender = '中性'
print(id(fubicheng.gender))
print(id(xiaogong.gender))
print(id(Wife.gender))
类属性只能通过类对象来修改,不能通过实例对象来修改,如果这样操作了,只是重新为此实例对象重新添加了一个实例属性而已。
3)实例属性
class Dog(object):
def __init__(self):
self.age = 2
# def get_age(self):
# return Dog.age
wangcai = Dog()
print(wangcai.age)
# print(Dog.age) # 报错; 实例属性只能通过实例对象访问,不能通过类访问
# print(wangcai.get_age())
4)dir()
dir()查询对象属性方法
dir()传入对象返回对象的属性和方法。比如字符串,可用该函数查询字符串的所有方法。查询字符串,一个双引号就是字符串类,所以以下代码就是查询字符串的所有属性。
print(dir(""))
[’__add__’, ‘__class__’, ‘__contains__’, ‘__delattr__’, ‘__dir__’, ‘__doc__’, ‘__eq__’, ‘__format__’, ‘__ge__’, ‘__getattribute__’, ‘__getitem__’, ‘__getnewargs__’, ‘__gt__’, ‘__hash__’, ‘__init__’, ‘__init_subclass__’, ‘__iter__’, ‘__le__’, ‘__len__’, ‘__lt__’, ‘__mod__’, ‘__mul__’, ‘__ne__’, ‘__new__’, ‘__reduce__’, ‘__reduce_ex__’, ‘__repr__’, ‘__rmod__’, ‘__rmul__’, ‘__setattr__’, ‘__sizeof__’, ‘__str__’, ‘__subclasshook__’, ‘capitalize’, ‘casefold’, ‘center’, ‘count’, ‘encode’, ‘endswith’, ‘expandtabs’, ‘find’, ‘format’, ‘format_map’, ‘index’, ‘isalnum’, ‘isalpha’, ‘isdecimal’, ‘isdigit’, ‘isidentifier’, ‘islower’, ‘isnumeric’, ‘isprintable’, ‘isspace’, ‘istitle’, ‘isupper’, ‘join’, ‘ljust’, ‘lower’, ‘lstrip’, ‘maketrans’, ‘partition’, ‘replace’, ‘rfind’, ‘rindex’, ‘rjust’, ‘rpartition’, ‘rsplit’, ‘rstrip’, ‘split’, ‘splitlines’, ‘startswith’, ‘strip’, ‘swapcase’, ‘title’, ‘translate’, ‘upper’, ‘zfill’]
-
查询元组:print(dir(()))
-
查询列表:print(dir([]))
-
查询字典:print(dir({}))
-
查询非内置类
除了上述内置类可以查询,所有对象都可以查询,所以手动创建的类也可查询,查询方法一样。首先,定义一个类:class DIR_Test: def __init__(self, a): self.a = a self.b = 2 self.c = "hello dir" def train(self): pass def eval(self): pass # 不实例化查询: print(dir(DIR_Test)) # [’__class__’, ‘__delattr__’, ‘__dict__’, ‘__dir__’, ‘__doc__’, ‘__eq__’, ‘__format__’, ‘__ge__’, ‘__getattribute__’, ‘__gt__’, ‘__hash__’, ‘__init__’, ‘__init_subclass__’, ‘__le__’, ‘__lt__’, ‘__module__’, ‘__ne__’, ‘__new__’, ‘__reduce__’, ‘__reduce_ex__’, ‘__repr__’, ‘__setattr__’, ‘__sizeof__’, ‘__str__’, ‘__subclasshook__’, ‘__weakref__’, ‘eval’, ‘train’] # 实例化查询: dir_test = DIR_Test(a=1) print(dir(dir_test)) # [’__class__’, ‘__delattr__’, ‘__dict__’, ‘__dir__’, ‘__doc__’, ‘__eq__’, ‘__format__’, ‘__ge__’, ‘__getattribute__’, ‘__gt__’, ‘__hash__’, ‘__init__’, ‘__init_subclass__’, ‘__le__’, ‘__lt__’, ‘__module__’, ‘__ne__’, ‘__new__’, ‘__reduce__’, ‘__reduce_ex__’, ‘__repr__’, ‘__setattr__’, ‘__sizeof__’, ‘__str__’, ‘__subclasshook__’, ‘__weakref__’, ‘a’, ‘b’, ‘c’, ‘eval’, ‘train’]
不实例化后查询只能看到方法;实例化后再查询可以看到方法和属性。因为只有实例化后才能把属性的值定下来,所以正确的使用方法是先实例化再使用。比如上面查询列表,传入的是"[]"实际上就已经实例化了一个对象。dir查询到的属性是没有值的
5.类方法和静态方法
1)类方法
类方法需要使用装饰器@classmethod来标识其为类方法,对于类方法而言,第一个参数必须是类的对象,一般以cls作为第一个参数。
使用
- 当方法中需要使用到类的对象的时候(比如说私有类属性),定义类方法。
- 类方法一般配合类属性使用
# 定义一个私有类属性,通过类方法获取这个私有类属性
class Dog(object):
__age = 2
@classmethod
def get_age(cls): # cls指的就是我们的类对象 此时 cls==Dog # 类方法
return cls.__age
wangcai = Dog()
print(wangcai.get_age())
2)静态方法
- 需要使用装饰器
@staticmethod来进行装饰,静态方法即不需要传递类对象,也不需要传递实例对象,没有self/cls - 静态方法是可以通过实例对象和类对象来进行访问的。
使用
- 当方法中即不需要使用实例对象,也不需要使用类对象的时候,就定义静态方法
- 取消不必要的参数传递,有利于减少不必要的内存占用和性能消耗
# 定义一个静态方法
class Dog(object):
def info(self):
print("这是info方法")
@staticmethod
def print_info(self): # 方法中不需要使用到实例对象和类对象
print('这是一个静态方法')
print(self)
d = Dog()
d.info()
d.print_info(1)
6.单例模式
举个常见的单例模式例子,我们日常使用的电脑上都有一个回收站,在整个操作系统中,回收站只能有一个对象,整个系统都使用这个唯一的对象,而且回收站自行提供自己的对象。因此回收站是单例模式的应用。
确保某一个类只有一个对象,而且自行实例化并向整个系统提供这个对象,这个类称为单例类,单例模式是一种对象创建型模式。
1)非单例模式
class Singleton(object):
__instance = None
def __new__(cls, age, name):
if not cls.__instance:
cls.__instance = object.__new__(cls)
return cls.__instance
return cls.__instance
def __init__(self, age, name):
self.age = age
self.name = name
a = Singleton(18, "wk")
b = Singleton(8, "mm")
print(id(a) == id(b))
print(a.age, a.name)
print(b.age, b.name) # a,b共用一个类对象,最后赋值的会覆盖之前赋值的
a.size = 19 # 给a指向的对象添加一个属性
print(b.size) # 获取b指向的对象的size属性,因为a,b共用一个类对象,a.size = 19是对类对象赋值,对于共用该类对象的对象通用。
# True
# 8 mm
# 8 mm
# 19
2)单例模式
# 只执行一次__init__()方法。
class Singleton(object):
__instance = None
__first_init = False # 实例化一个单例
def __new__(cls, age, name):
if not cls.__instance:
cls.__instance = object.__new__(cls)
return cls.__instance
return cls.__instance
def __init__(self, age, name):
if not self.__first_init:
self.age = age
self.name = name
Singleton.__first_init = True
a = Singleton(18, "wk")
b = Singleton(8, "mm")
print(id(a) == id(b))
print(a.age, a.name) # 一旦创建该类的对象,则以该对象为主,再创建该类其他对象视为无效
print(b.age, b.name)
a.size = 19 # 给a指向的对象添加一个属性
print(b.size) # 获取b指向的对象的size属性
b.size = 17
print(a.size) # 获取a指向的对象的size属性,因为a,b共用一个类对象,b.size = 17是对类对象赋值,对于共用该类对象的对象通用。同时改变size = 19为size = 17
# True
# 18 wk
# 18 wk
# 19
# 17
7.property属性
# 基本语法
class property([fget[, fset[, fdel[, doc]]]])
# fget – 获取属性值的函数
# fset – 设置属性值的函数
# fdel – 删除属性值函数
# doc – 属性描述信息
property会返回一个新式类属性,先看一个例子:
class C:
def __init__(self):
self._x = None
def getx(self):
return self._x
def setx(self, value):
self._x = value
def delx(self):
del self._x
a = property(getx, setx, delx, "I'm the 'x' property.")
if __name__ == "__main__":
A = C()
print("获取属性值")
print(A.a)
A.a = 1
print(A.a)
del A.a
print(A.a)
# 获取属性值
# None
# 1
# Traceback (most recent call last):
# File "G:\python_project\Text\main.py", line 24, in <module>
# print(A.a)
# ^^^
# File "G:\python_project\Text\main.py", line 6, in getx
# return self._x
# ^^^^^^^
# AttributeError: 'C' object has no attribute '_x'
- property中getx对应获取属性值的函数既c.x的返回值,所以尽管x在C中匿名(_x)但还可被c.x调用
- property中setx对应设置属性值的函数既c.x = value的返回值,所以尽管x在C中匿名,但还可被设置
- 同理property中的第三个参数代表了删除C属性x的函数
- 在没有property时不能从外表调用._x属性
1)参数args
python builtins文件中对类BaseException中参数args的定义
args = property(lambda self: object(), #获取值
lambda self, v: None, #设置值
lambda self: None) #删除值
2)装饰器的方式
class Person:
def __init__(self):
self.__age = 1
@property
def age(self):
return self.__age
@age.setter
def age(self, new_age): # new_age用来接受外部给p.age赋值的这个参数
if 0 < new_age < 200:
self.__age = new_age
else:
print('年龄设置错误,回去改改')
p = Person()
print(p.age)
p.age = 300
print(p.age)
p.age = 150
print(p.age)
# 1
# 年龄设置错误,回去改改
# 1
# 150
3)类属性
property(参数1,参数2)
第一个参数表示获取属性时会执行的方法名
第二个参数表示设置属性时会执行的方法名
class Person(object):
def __init__(self):
self.__age = 1
def get_age(self):
return self.__age
def set_age(self, new_age):
if 0 < new_age < 200:
self.__age = new_age
else:
print('年龄设置错误,回去改改')
age = property(get_age, set_age)
p = Person()
print(p.age)
p.age = 10
print(p.age)
8.上下文管理器
普通打开文件的隐患:
f = open('1.txt', 'w')
f.write('hello world')
f.close()
with open('1.txt', 'w') as f:
f.write("hello world")
with语句之所以这么强大,就是因为背后是上下文管理器作为支撑的。
一个类中只要实现了__enter__()和 __exit__()这两个魔法方法,通过该类创建的对象就是上下文管理器对象。
__enter__(): 表示的是上文方法, 需要返回一个操作文件对象
__exit__():表示的是下文方法,with语句会自动执行下文方法,即使代码出现异常也会被调用。
"""
需求:定义一个上下文管理器类,模拟文件操作
定义一个File类
实现__enter__()和 __exit__()
然后用with语句调用来完成文件操作,观察现象。
"""
class File(object):
def __init__(self, file_name, file_model):
self.file_name = file_name
self.file_model = file_model
def __enter__(self):
"""上文方法"""
print('这是上文方法')
self.file = open(self.file_name, self.file_model)
return self.file
def __exit__(self, exc_type, exc_val, exc_tb):
"""这是下文方法"""
print('这是下文方法')
self.file.close()
with File("1.txt", 'r') as f:
data = f.read()
1/0
print(data)
五、面向对象
- 封装
- 将属性和方法书写到类里面的操作即是封装
- 封装可以为我们的属性和方法添加私有权限
- 继承
- 子类默认继承父类的所有属性和方法
- 子类可以重写父类同名属性和方法
- 多态
- 传入不同的对象,产生不同的效果
1.继承
Python面向对象中的继承就是指的是多个类之间一个从属关系,即子类默认继承父类的所有方法和属性。慎用继承,尤其是多重继承。继承有时很有用,但在有些情况下可能带来不必要的复杂性。要正确地使用多重继承很难,要排除其中的bug更难。
继承的特点:子类默认拥有父类的所有属性和方法,除了私有属性和私有方法。
-
经典类
不由任意内置类型派生出的类,称之为经典类
class 类名: 代码 -
新式类
class 类名(object): 代码 # 在Python中,所有类默认继承自object类,object类是顶级类或者说是基类;其他子类叫派生类。
# 定义父类
class A(object): # "(object)"通常省略
def __init__(self):
self.age = 1
def print_info(self):
print(self.age)
# 定义子类
class B(A):
pass
res = B()
res.print_info() # 1
print(res.age) # 1
1)超类
超类是指 2层以上的继承关系,假如C类继承B类,B类由继承A类,那么A类就是C类的超类
指定超类:子类可以扩展超类的定义,将其他类名写在class语句后的圆括号内可以指定超类,此时圆括号内的类即为超类。
# 在指定列表中过滤掉self.blocked中的元素
class Filter:
def init(self):
self.blocked = []
def filter(self, sequence):
return [x for x in sequence if x not in self.blocked]
# 指定列表的值
class SPAMFilter(Filter): # SPAMFilter是Filter的子类
def init(self): # 重写超类Filter的方法init
self.blocked = ['SPAM']
2)方法
(1)self
-
在类中self代表实例本身,既该实例内存地址。调用实例的方法时把实例变量传给类的函数中的self。
-
self不是关键字,可用其它合法变量名替换self,但规范和标准建议一致使用self。
上述代码定义一个类A,self为参数变量,在类A实例化得到实例res时自动调用
__init__,执行res.print_info(),该self可接收实例res的内存地址,从而self代表了实例本身。所以self变量无需手动传值。
self的使用场景:
- self为类中的函数的第一个参数
如果类的函数的第一个参数不是代表实例的self,则调用实例的方法时,该方法没有参数接收解释器自动传入的实例变量,从而程序会产生异常。和普通的函数相比在类中定义的函数第一个参数永远是实例变量self,且调用时不用传递该参数。之外类的方法和普通函数没有什么区别,所以仍然可以用默认参数、可变参数、关键字参数和命名关键字参数。self通常代指子类的实例对象。
- 在类中引用实例的属性
self.变量名(如self.val())。引用实例的属性的目的是为实例绑定属性、写入或读取实例的属性。例如,在上述代码中,在类的函数__init__中,“self.age = 1”将属性age绑定到了实例self(类实例化成res后,self就代表实例res了)上,并且将变量age的值赋给了实例的属性res。
- 在类中调用实例的方法
类是抽象的模板,而实例是根据类创建出来的一个个具体的“对象”,每个对象都拥有相同的方法,但各自的数据可能不同。既然,self代表实例,则可以“self.函数名”的方式表示实例的方法地址,以“self.函数名()”的方式,调用实例的方法。在类的定义中,以及实例化后对实例方法的调用,都可以这样做。
(2)issubclass()
确定一个类是否是另一个类的子类,可使用内置方法issubclass。
print(issubclass(SPAMFilter, Filter))
# True
print(issubclass(Filter, SPAMFilter))
# False
(3)__bases__
了解一个类的基类可访问其特殊属性__bases__。
print(SPAMFilter.__bases__)
# (<class '__main__.Filter'>,)
print(Filter.__bases__)
# (<class 'object'>,)
(4)isinstance()
确定对象是否是特定类的实例,可使用isinstance,返回True表示含有但不一定完全相同,既无法验证是否有相同的作用。
s = SPAMFilter()
print(isinstance(s, SPAMFilter))
# True
print(isinstance(s, Filter))
# True
print(isinstance(s, str))
# False
3)继承方式
(1)单继承
# 定义父类
class Master:
def __init__(self):
self.name = "师傅"
self.skill = "师傅的第一个技能"
def teach(self):
print(f"{self.name}展示了{self.skill}。")
# 定义子类
class Prentice(Master):
pass
son = Prentice() # 用子创建对象,调用父类的属性和方法
print(son.skill) # 子类对象调用父类的属性
son.teach() # 子类对象调用父类方法
# 师傅的第一个技能
# 师傅展示了师傅的第一个技能。
print(son.teach()) # print()为函数需要返回值。son.teach()无返回值,所以执行完son.teach()后打印None
# 师傅展示了师傅的第一个技能。
# None
- 总结:
- 子类在继承的时候,在定义类的时候,小括号中写的就是父类的名字
- 父类的方法,属性都会被子类继承
(2)多继承
所谓多继承就是指一个类同时继承多个类。
# 定义父类
class Master:
def __init__(self):
self.name = "师傅"
self.skill = "师傅的技能"
def teach(self):
print(f"{self.name}展示了{self.skill}。")
# 定义另一个父类类
class MasterBrother:
def __init__(self):
self.name = '师傅的兄弟'
self.skill = '师傅兄弟的技能'
def teach(self):
print(f"{self.name}展示了{self.skill}。")
# 定义子类
class Prentice(Master, MasterBrother):
pass
son = Prentice() # 用子类创建对象,调用父类的属性和方法
print(son.skill) # 子类对象调用父类的属性
son.teach() # 子类对象调用父类方法
print(son.name)
# 师傅的技能
# 师傅展示了师傅的技能。
# 师傅
说明:
- 多继承可以继承多个父类,也继承了所有父类的属性和方法
- 注意:如果多个父类中有同名的属性和方法,则默认使用第一个父类的属性和方法(根据类中魔法属性mro的顺序来查找的)
- 多个父类中,不同名的属性和方法,不会有任何影响。
(3)多层继承
既父类继承给子类,子类再继承给下一个子类。
class Master:
def __init__(self):
self.name = "师傅"
self.skill = "师傅的技能"
def teach(self):
print(f"{self.name}展示了{self.skill}。")
class MasterBrother:
def __init__(self):
self.name = '师傅的兄弟'
self.skill = '师傅兄弟的技能'
def teach(self):
print(f"{self.name}展示了{self.skill}。")
class Prentice(Master, MasterBrother):
def __init__(self):
self.name = '徒弟'
self.skill = '徒弟的技能'
def teach(self):
print(f"{self.name}展示了{self.skill}。")
def master_skill(self):
Master.__init__(self)
Master.teach(self) # 一旦出现"类名.__init__(self)",则同名方法优先使用此类
MasterBrother.teach(self)
def master_brother_skill(self):
MasterBrother.__init__(self)
MasterBrother.teach(self)
Master.teach(self)
class PrenticeSon(Prentice):
pass
son = PrenticeSon()
son.master_skill()
# 师傅展示了师傅的技能。
# 师傅展示了师傅的技能。
son.teach()
# 师傅展示了师傅的技能。
print(son.name)
# 师傅
print()
son.master_brother_skill()
# 师傅的兄弟展示了师傅兄弟的技能。
# 师傅的兄弟展示了师傅兄弟的技能。
son.teach()
# 师傅的兄弟展示了师傅兄弟的技能。
print(son.name)
# 师傅的兄弟
print()
son.__init__()
son.teach()
# 徒弟展示了徒弟的技能。
print(son.name)
# 徒弟
(4)多重继承
class Calculator:
def __init__(self):
self.value = None
def calculate(self, expression):
self.value = eval(expression)
class Talker:
def __init__(self):
self.value = None
def talk(self):
print('Hi, my value is', self.value)
# 子类TalkingCalculator所有行为都从超类继承。
class TalkingCalculator(Calculator, Talker):
pass
tc = TalkingCalculator()
tc.calculate('1 + 2 * 3')
tc.talk()
# Hi, my value is 7
应避免使用多重继,在有些情况下可能会带来意外的“并发症”。使用多重继承务必注意:如果多个超类以不同的方式实现了同一个方法(即有多个同名方法 ),必须在class语句中小心排列这些超类,因为位于前面的类的方法将覆盖位于后面的类的方法。
如果Calculator类包含方法talk,那么这个方法将覆盖Talker类的方法talk(导致它不可访问 )。如果像下面这样反转超类的排列顺序:
class TalkingCalculator(Talker, Calculator):
pass
将导致Talker的方法talk是可以访问的。多个超类的超类相同时,查找特定方法或属性时访问超类的顺序称为方法解析顺序(MRO)。
# 在指定列表中过滤掉self.blocked中的元素
class Filter:
def init(self):
self.blocked = []
def filter(self, sequence):
return [x for x in sequence if x not in self.blocked]
# 指定列表的值
class SPAMFilter(Filter): # SPAMFilter是Filter的子类
def init(self): # 重写超类Filter的方法init
self.blocked = ['SPAM']
4)重写
class A:
def hello(self):
print("Hello,I'm A.")
class B(A):
pass
# 如果找不到该方法(或属性),将在其超类A中查找
a = A()
b = B()
a.hello()
# Hello,I'm A.
b.hello()
# Hello,I'm A.
如果子类和父类具有同名方法和属性则认为子类重写父类同名方法和属性,但默认使用子类的同名方法和属性:
class A:
def hello(self):
print("Hello,I'm A.")
class B(A):
def hello(self):
print("Hello,I'm B.")
# 这样修改定义后,b.hello()的结果将不同。
b = B()
b.hello()
# Hello,I'm B.
5)调用
class Bird:
def __init__(self):
self.hungry = True
# 进食
def eat(self):
if self.hungry:
print('Aaaah...')
self.hungry = False
else:
print('No,thanks!')
# 鸟进食后就不再饥饿
b = Bird()
b.eat()
# Aaaah...
b.eat()
# Squawk!
# 新增鸣叫功能
class SongBird(Bird):
# 缺少对超类 __init__ 的调用
def __init__(self):
self.sound = 'Squawk!'
def sing(self):
print(self.sound)
sb = SongBird()
sb.sing()
# Squawk!
sb.eat()
# Traceback (most recent call last):
# File "text2.py", line 34, in <module>
# sb.eat()
# File "text2.py", line 7, in eat
# if self.hungry:
# ^^^^^^^^^^^
# AttributeError: 'SongBird' object has no attribute 'hungry'
异常指出SongBird没有属性hungry。因为在SongBird中重写了构造函数,但新的构造函数没有包含任何初始化属性hungry的代码。要消除这种错误,SongBird的构造函数必须调用其超类(Bird)的构造函数,以确保基本的初始化得以执行。为此有两种方法:调用未关联的超类构造函数,以及使用函数super。
(1)未关联调用
将未关联方法的self参数设置为当前实例,会使用超类的构造函数来初始化子类对象。
class SongBird(Bird):
def __init__(self):
Bird.__init__(self)
self.sound = 'Squawk!'
def sing(self):
print(self.sound)
sb = SongBird()
sb.sing()
# Squawk!
sb.eat()
# Aaaah...
(2)super()
super()用于调用父类(超类)。调用super()会将当前类和当前实例作为参数。对其返回的对象调用方法时,调用的将是超类(而不是当前类)的方法。另外可调用方法__init__。通常不提供任何参数。
# 语法:
super(type[, object-or-type])
# type – 类。
# object-or-type – 类,一般是 self
# 可以使用直接使用 super().xxx 代替 super(Class, self).xxx :
可通过super() 来调用父类的__init__构造方法:
class SongBird(Bird):
def __init__(self):
super().__init__()
self.sound = 'Squawk!'
def sing(self):
print(self.sound)
sb = SongBird()
sb.sing()
# Squawk!
sb.eat()
# Aaaah...
sb.eat()
# No,thanks!
class C:
def __init__(self):
print('我是C的__init__构造方法')
class A:
def __init__(self):
print('我是A的__init__构造方法')
class B(A):
def __init__(self):
super(B, self).__init__() # super(B, self).__init__()
super(A, self).__init__()
print('我是B的__init__构造方法')
D = B()
# 我是A的__init__构造方法
# 我是B的__init__构造方法
super().__init__()指调用B类的父类A类,优点在于更改A类时不用更改B类。适用于单继承的情况。对于多继承则默认继承于第一个父类。多层继承时仅调用含super().__init__()类的上一个父类。super(B, self).__init__()指调用B类的父类A类,在同一个类中与super().__init__()用法相同super(A, self).__init__()指调用A类的父类C类,在同一个类中可以调用括号中类的父类。
在多继承中,会涉及到一个__mro__(继承父类方法时的顺序表) 的调用排序问题。即严格按照该顺序执行super方法
class A:
def __init__(self):
self.n = 2
def add(self, m):
print('self is {0} @A.add'.format(self))
self.n += m
class B(A):
def __init__(self):
self.n = 3
def add(self, m):
print('self is {0} @B.add'.format(self))
super().add(m)
self.n += 3
class C(A):
def __init__(self):
self.n = 4
def add(self, m):
print('self is {0} @C.add'.format(self))
super().add(m)
self.n += 4
class D(B, C):
def __init__(self):
self.n = 5
def add(self, m):
print('self is {0} @D.add'.format(self))
super().add(m)
self.n += 5
d = D()
d.add(2)
print(d.n)
# self is <__main__.D object at 0x0000014E1D2E4450> @D.add
# self is <__main__.D object at 0x0000014E1D2E4450> @B.add
# self is <__main__.D object at 0x0000014E1D2E4450> @C.add
# self is <__main__.D object at 0x0000014E1D2E4450> @A.add
# 19
同样,不管往上调用几次,调用父类方法中 self 并不是父类的实例而是子类的实例,在上例中都是D的实例化对象
D.mro() == [D,B, C, A, object] ,多继承的执行顺序会严格按照mro的顺序执行。整体的调用流程图如下:
d = D()
d.n == 5
d.add(2)
class D(B, C): class B(A): class C(A): class A:
def add(self, m): def add(self, m): def add(self, m): def add(self, m):
super().add(m) 1.---> super().add(m) 2.---> super().add(m) 3.---> self.n += m
self.n += 5 <------6. self.n += 3 <----5. self.n += 4 <----4. <--|
(14+5=19) (11+3=14) (7+4=11) (5+2=7)
super().__init__相对于类名.init,在单继承上用法基本无差别- 但在多继承上有区别,super方法能保证每个父类的方法只会执行一次,而使用类名的方法会导致方法被执行多次。
- 多继承时,使用super方法,对父类的传参数,应该是由于python中super的算法导致的原因,必须把参数全部传递,否则会报错
- 单继承时,使用super方法,则不能全部传递,只能传父类方法所需的参数,否则会报错
子类调用父类同名方法和属性:
class Master:
def __init__(self):
self.name = "师傅"
self.skill = "师傅的技能"
def teach(self):
print(f"{self.name}展示了{self.skill}。")
class MasterBrother:
def __init__(self):
self.name = '师傅的兄弟'
self.skill = '师傅兄弟的技能'
def teach(self):
print(f"{self.name}展示了{self.skill}。")
class Prentice(Master, MasterBrother):
def __init__(self):
self.name = '徒弟'
self.skill = '徒弟的技能'
def teach(self):
print(f"{self.name}展示了{self.skill}。")
def master_skill(self):
Master.__init__(self)
Master.teach(self)
def master_brother_skill(self):
MasterBrother.__init__(self)
MasterBrother.teach(self)
son = Prentice()
son.master_skill() # 调用第一个父类
son.teach()
print(son.name)
print()
son.master_brother_skill() # 调用第二个父类
son.teach()
print(son.name)
print()
son.__init__() # 调用子类
son.teach()
print(son.name)
# 师傅展示了师傅的技能。
# 师傅展示了师傅的技能。
# 师傅
# 师傅的兄弟展示了师傅兄弟的技能。
# 师傅的兄弟展示了师傅兄弟的技能。
# 师傅的兄弟
# 徒弟展示了徒弟的技能。
# 徒弟
无论何时何地,self都表示的是子类的对象,在调用父类方法时,通过传递self参数,来控制方法和属性的访问和修改。
Maid().battle() # 这种方法不推荐使用,因为相当于重新创建了一个新的父类对象,占用不必要的内存。
a = Maid()
a.battle()
2.封装
1)定义
定义私有属性和方法。在Python中,可以为实例方法和属性设置私有权限,即设置某个实例属性和实例方法不继承给子类。设置私有属性和私有方法:在属性和方法前面加上两个下划线。
class Master:
def __init__(self):
self.name = "师傅"
self.__skill = "师傅的技能" # self.skill = "师傅的技能"
class Prentice(Master):
def __init__(self):
super().__init__()
def teach(self):
super().__init__()
print(f"{self.name}展示了{self.__skill}。") # print(f"{self.name}展示了{self.skill}。")
son = Prentice()
son.teach()
# 结果保错
总结:对象不能访问私有属性和私有方法,子类无法继承父类的私有属性和私有方法。
# 以两个下划线打头幕后的处理手法并不标准:在类定义中,对所有以两个下划线打头的名称都进行转换,即在开头加上一个下划线和类名。
print(Secretive._Secretive__inaccessible)
# <unbound method Secretive. inaccessible>
# 知道幕后处理手法就能从类外访问私有方法,然而不应这样做。
print(s._Secretive__inaccessible())
# 总之无法禁止别人访问对象的私有方法和属性,但这种名称修改方式让他们不要这样做。如果不希望名称被修改,又想发出不要从外部修改属性或方法的信号,可用一个下划线打头。这虽然只是一种约定,但也有些作用。如from module import *不会导入以一个下划线打头的名称”。
2)获取修改
获取修改私有属性值。Python中一般定义方法名为get_xxxx用来表示获取私有属性,定义set_xxxx 用来表示修改私有属性值,这是约定俗称的命名方法,不是强制要求。
class Master:
def __init__(self):
self.__name = "师傅"
self.__skill = "师傅的技能"
def get_name(self):
return self.__name
def set_name(self, name):
self.__name = name
def get_skill(self):
return self.__skill
def set_skill(self, skill):
self.__skill = skill
class Prentice(Master):
def start(self):
super().__init__()
print(super().get_name())
print(super().get_skill())
super().set_name("乔峰")
super().set_skill("乔峰的第二个技能")
print(super().get_name())
print(super().get_skill())
son = Prentice()
son.start()
# 师傅
# 师傅的技能
# 乔峰
# 乔峰的第二个技能
3.多态
多态指的是一类事物有多种形态(一个抽象类有多个子类,因而多态的概念依赖于继承)
- 定义:多态是一种使用对象的方式,子类重写父类方法,调用不同的子类对象的同一父类方法时,产生不同的对象。
- 实现步骤:
- 定义父类,并提供公共方法
- 定义子类,并重写父类方法
- 传递子类对象给调用者,可以看到不同的子类的执行结果
class Hero:
def __init__(self):
self.__name = "英雄"
self.__skill = "英雄的技能"
def get_name(self):
return self.__name
def set_name(self, name):
self.__name = name
def get_skill(self):
return self.__skill
def set_skill(self, skill):
self.__skill = skill
class BaiLiShouYue(Hero):
def start(self):
super().__init__()
super().set_name("百里守约")
super().set_skill("狂风之息")
print(f"{super().get_name()}施展{super().get_skill()}")
class TheMonkeyKing(Hero):
def start(self):
super().__init__()
super().set_name("孙悟空")
super().set_skill("护身咒法")
print(f"{super().get_name()}施展{super().get_skill()}")
role1 = BaiLiShouYue()
role1.start()
# 百里守约施展狂风之息
role2 = TheMonkeyKing()
role2.start()
# 孙悟空施展护身咒法
1)接口
接口与多态有关,处理多态对象时只考虑接口(协议)——对外暴露的方法和属性。在Python中,不显式地指定对象必须包含哪些方法才能用作参数。通常要求对象遵循特定的接口(即实现特定的方法),
class Calculator:
def __init__(self):
self.value = None
def calculate(self, expression):
self.value = eval(expression)
class Talker:
def __init__(self):
self.value = None
def talk(self):
print('Hi, my value is', self.value)
class TalkingCalculator(Calculator, Talker):
pass
hasattr()
检查所需的方法是否存在
tc = TalkingCalculator()
print(hasattr(tc, 'talk'))
# True
print(hasattr(tc, 'fnord'))
# False
getattr()
检香属性是否是可调用
# getattr()能指定属性不存在时使用的默认值,这里为None,然后对返回的对象调用callable。
print(callable(getattr(tc, 'talk', None)))
# True
print(callable(getattr(tc, 'fnord', None)))
# False
setattr()
setattr与getattr功能相反,可用于设置对象的属性
setattr(tc, 'name', 'Mr. Gumby')
print(tc.name)
# 'Mr. Gumby
delattr()
删除对象属性
delattr(对象名, '对象属性名')
2)抽象基类
使用模块abc可创建抽象基类。抽象基类(Abstract Base Classes,简称abc)用于定义一组必须在子类中重写实现的抽象方法。抽象基类本身不能被实例化(不能创建对象),而是用于定义子类所需实现的接口。抽象基类就是定义各种方法而不做具体实现的类,任何继承自抽象基类的类必须实现这些方法,否则无法实例化。
from abc import ABC, abstractmethod
class Talker(ABC):
@abstractmethod # 装饰器,将方法标记为抽象的——在子类中必须实现的方法
def talk(self):
pass
不能实例化
抽象类(即包含抽象方法的类)最重要的特征是不能实例化
# Talker()
# 报错
# 派生的子类没有重写方法talk时子类也是抽象的,不能实例化,否则报错。可重新编写子类,使其实现要求的方法。
class Knigget(Talker):
def talk(self):
print("Ni!")
# 现在即可实例化。这是抽象基类的主要用途,最后只在这种情形下使用isinstance:
k = Knigget()
# 先检查给定实例确实是Talker对象,就能知道这个实例在需要时有方法talk。
print(isinstance(k, Talker))
# True
只要实现方法talk,即便不是Talker的子类,依然能够通过类型检查。
class Herring:
def talk(self):
print("Blub.")
# 这个类的实例能够通过是否为Talker对象的检查,但它不是Talker对象。
h = Herring()
print(isinstance(h, Talker))
# False
可将一个类注册成talk,这个类所有对象都将被视为Talker对象,但直接从抽象类派生提供的保障消失了
class Clam:
pass
print(Talker.register(Clam))
# <class '__main__.Clam'>
print(issubclass(Clam, Talker))
# True
c = Clam()
print(isinstance(c, Talker))
# True
c.talk()
# 报错
应用场景
检查某个类中是否有某种方法。如判断Demo中是否含有__len__魔法方法
from collections.abc import Sized # 导入模块collections.abc的Sized类
# Sized源码如下:
# class Sized(metaclass=ABCMeta):
# __slots__ = ()
#
# @abstractmethod
# def __len__(self):
# return 0
#
# @classmethod
# def __subclasshook__(cls, C):
# if cls is Sized:
# return _check_methods(C, "__len__")
# return NotImplemented
class Demo(object):
def __init__(self, list1):
self.list = list1
def __len__(self):
return len(self.list)
d = Demo(["CW", "ls", 'age'])
print(hasattr(Sized, "__len__")) # 判断d的内部 是否含有__len__ ,返回值为布尔值,结果为true
print(isinstance(d, Sized)) # 检查d是否Sized类型 结果为:True
强制子类必须实现父类的方法
- 主动抛出异常。如下实例,子类RedisBase中未重写crea方法,在实例化子类RedisBase,没有报错,在调用crea()方法时报错
class CacheBase(object):
def dele(self):
# raise NotImplementedError意思是如果这个方法没有被子类重写,但是调用了就会报错。
raise NotImplementedError
def crea(self):
raise NotImplementedError
class RedisBase(CacheBase):
def dele(self):
print('I will delete')
# def crea(self):
# print('I will create')
r = RedisBase()
r.dele()
# I will delete
r.crea()
# raise NotImplementedError
- 子类RedisBase中未重写crea方法,在实例化子类RedisBase时就报错
import abc
class BaseClass(metaclass=abc.ABCMeta):
@abc.abstractmethod
def dele(self):
pass
@abc.abstractmethod
def crea(self):
pass
class SubClass(BaseClass):
def dele(self):
print('I will delete')
# def crea(self):
# print('I will create')
r = SubClass()
# TypeError: Can't instantiate abstract class SubClass with abstract methods crea
r.dele()
r.crea()
六、魔法方法
python中的魔法方法(magic methods)是指方法名以两个下划线开头并以两个下划线结尾的方法,因此也叫Dunder Methods (Double Underscores)。常用于运算符重载。魔法方法会在对类的某个操作时后端自动调用,而不需要自己直接调用。例如当使用+将两个数字相加时,在类内部会调用__add__()方法,再比如创建一个类A的对象,a=A(),python就会自动调用__new__和__init__。
1.构造函数
__init__
构造函数(constructor)就是初始化方法,只是命名为__init__。构造函数在对象创建后自动调用它们。
# 无需采用这种做法
f = FooBar()
f.init()
# 效果与上述代码相同
f = FooBar()
注意:__init__()方法,在创建对象的时候就会被默认调用,不需要手动调用,self参数不需要传递,Python解释器会自动把当前对象引用传递过去。
class Washer: # Washer写成Washer()会显得冗余
def __init__(self): # 初始化魔法方法
# 添加属性
self.width = 500 # 也可以写None,类外赋值
self.height = 1000
def print_info(self):
print('洗衣机的高度是:', self.height) # 类 'Washer' 的未解析的特性引用 'height'
print("洗衣机的宽度是:", self.width) # 类 'Washer' 的未解析的特性引用 'width'
hai1 = Washer()
hai1.print_info()
# 洗衣机的高度是: 1000
# 洗衣机的宽度是: 500
hai2 = Washer()
hai2.print_info()
# 洗衣机的高度是: 1000
# 洗衣机的宽度是: 500
带参数的__init__魔法方法:
一个类中有多个对象,对多个对象设置不同的属性值,可通过传参方式
class Washer():
def __init__(self, width, height): # 初始化魔法方法
# 添加属性
self.width = width
self.height = height
def print_info(self): # 实例方法,对象方法
print('洗衣机的高度是:', self.height)
print('洗衣机的宽度是:', self.width)
hai1 = Washer(500, 1000)
hai1.print_info()
# 洗衣机的高度是: 1000
# 洗衣机的宽度是: 500
hai2 = Washer(600, 1500)
hai2.print_info()
# 洗衣机的高度是: 1500
# 洗衣机的宽度是: 600
2.元素访问
基本的序列/映射协议
- Python中协议指规范行为的规则,类似接口。协议指定应实现哪些方法以及这些方法应做什么。
- Python中多态仅仅基于对象行为而不基于祖先(如属于哪个类或其超类等),只要对象遵循特定的协议。如要成为序列只需遵循序列协议。
- 序列和映射基本上是元素(item)的集合,要实现它们的基本行为(协议),不可变对象需要实现2个方法,而可变对象需要实现4个。
__len__
__len__(self)方法应返回集合包含的项数,对序列来说为元素个数,对映射来说为键-值对数。如果__len__返回零(且没有实现覆盖这种行为的__nonzero__),对象在布尔上下文中将被视为假(就像空的列表、元组、字符串和字典一样)。
__getitem__
__getitem__(self, key)方法返回与指定键相关联的值。对序列来说,键应该是0~n-1的整数(也可以是负数,这将在后面说明),其中n为序列的长度。对映射来说键可以是任何类型。
__setitem__
__setitem__(self, key, value)方法与键相关联的方式存储值,能够使用__getitem__获取。仅当对象可变时使用。
__delitem__
__delitem__(self, key)在对对象的组成部分使用__del__语句时被调用,删除与key相关联的值。同样仅当对象可变(且允许其项被删除)时使用。
以上方法额外的要求:
- 对于序列,如果键为负整数,应从末尾往前数。换而言之,x[-n]应与x[len(x)-n]等效。
- 如果键的类型不合适(如对序列使用字符串键 ),可能引发TypeError异常。
- 对于序列,如果索引的类型是正确的,但不在允许的范围内,应引发IndexError异常。
# 实现一个算术序列,其中任何两个相邻数字的差都相同。第一个值是由构造函数的参数start(默认为0)指定的,而相邻值之间的差是由参数step(默认为1)指定的。允许用户修改某些元素,这是通过将不符合规则的值保存在字典changed中实现的。如果元素未被修改,就使用公式self.start + key * self.step来计算它的值。
def check_index(key):
"""
指定的键是否是可接受的索引?
键必须是非负整数,才是可接受的。如果不是整数,
将引发TypeError异常;如果是负数,将引发Index
Error异常(因为这个序列的长度是无穷的)
"""
if not isinstance(key, int):
raise TypeError
if key < 0:
raise IndexError
class ArithmeticSequence:
def __init__(self, start=0, step=1):
"""
初始化这个算术序列
start -序列中的第一个值
step -两个相邻值的差
changed -一个字典,包含用户修改后的值
"""
self.start = start # 存储起始值
self.step = step # 存储步长值
self.changed = {} # 没有任何元素被修改
def __getitem__(self, key):
"""
从算术序列中获取一个元素
"""
check_index(key)
try:
return self.changed[key] # 修改过?
except KeyError: # 如果没有修改过,
return self.start + key * self.step # 就计算元素的值
def __setitem__(self, key, value):
"""
修改算术序列中的元素
"""
check_index(key)
self.changed[key] = value # 存储修改后的值
类没有方法__len__,因为其长度是无穷的。
s = ArithmeticSequence(1, 2)
print(s[4])
# 9
s[4]=2
print(s[4])
# 2
print(s[5])
# 11
类没有设置__delitem__,无法删除元素
s = ArithmeticSequence(1, 2)
del s[4]
# Traceback (most recent call last):
# File "text2.py", line 46, in <module>
# del s[4]
# ~^^^
# AttributeError: __delitem__
如果所使用索引的类型非法,将引发TypeError异常;如果索引的类型正确,但不在允许的范围内(即为负数),将引发IndexError异常。索引检查由函数check_index负责
s = ArithmeticSequence(1, 2)
print(s['four'])
# Traceback (most recent call last):
# File "text2.py", line 46, in <module>
# print(s['four'])
# ~^^^^^^^^
# File "text2.py", line 31, in __getitem__
# check_index(key)
# File "text2.py", line 9, in check_index
# raise TypeError
# TypeError
s = ArithmeticSequence(1, 2)
print(s[-42])
# Traceback (most recent call last):
# File "text2.py", line 46, in <module>
# print(s[-42])
# ~^^^^^
# File "text2.py", line 31, in __getitem__
# check_index(key)
# File "text2.py", line 11, in check_index
# raise IndexError
# IndexError
只想定制某种操作的行为可利用继承。标准库中模块collections提供了抽象和具体的基类,也可继承内置类型。如实现一种行为类似于内置列表的序列类型可直接继承list,一个带访问计数器的列表
class CounterList(list):
def __init__(self, *args):
super().__init__(*args)
self.counter = 0
# 重写__getitem__并不能保证一定会捕捉用户的访问操作,因为还有其他访问列表内容的方式,如通过方法pop。
def __getitem__(self, index):
self.counter += 1
return super(CounterList, self).__getitem__(index)
CounterList类依赖超类list的行为。CounterList没有重写的方法(如append、extend、index等)都可直接使用。在两个被重写的方法中,使用super来调用超类的相应方法,并添加了必要的行为:初始化属性counter(在__init__中)和更新属性counter(在__getitem__中)。
c1 = CounterList(range(10))
print(c1)
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
c1.reverse()
print(c1)
# [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
del c1[3:6]
print(c1.counter)
# 0
print(c1[4] + c1[2])
# 9
print(c1.counter)
# 2
CounterList在大多数方面都类似列表,但有一个counter属性(其初始值为0)。每当访问列表元素时,这个属性的值都加1。执行加法运算cl[4] + cl[2]后,counter的值递增两次,变成了2。
3.其他
在Python中,__xx__()的函数就叫魔法方法,指的是具有特殊功能的函数
__doc__
描述类信息
在def语句后面添加函数字符串描述很有用。放在函数开头的字符串称为文档字符串(docstring),将作为函数的一部分存储起来。下面的代码演示了如何给函数添加文档字符串
def square(x):
"""Calculates the square of the number x."""
return x * x
# 访问文档字符串:
print(square.__doc__)
# Calculates the square of the number x.
# __doc__是函数的一个属性。属性将在第7章详细介绍。属性名中的双下划线表示这是一个特殊的属性。特殊(“魔法”)属性将在第9章讨论。
__str__
对对象的描述信息。如果类中定义了__str__方法,那么在打印对象时,默认输出该方法的返回值。__str__方法必须返回一个字符串
__module__
表示当前操作的对象在那个模块
__class__
表示当前操作对象的类是什么
__str__
当print输出一个对象的时候,默认打印的是对象的内存空间地址,如果在类中定义__str__魔法方法之后,那么此时在打印对象就是打印的这个方法的返回值。
class Washer:
def wash(self):
print('洗衣服')
def __str__(self): # 类的说明或者类的状态
return '这是洗衣机类的使用说明'
haier = Washer()
print(haier)
# 这是洗衣机类的使用说明
__del__
当删除对象时,Python解释器会自动调用__del__()魔法方法。__del__也称析构函数(destructor),在对象被销毁(作为垃圾被收集)前被调用,但有时无法知道准确调用时间,建议尽可能不要主动使用__del__。
class Washer():
def wash(self):
print('洗衣服')
def __del__(self):
"""删除对象"""
print(f"{self}对象已经删除")
haier = Washer()
del haier
print(haier)
# <__main__.Washer object at 0x00000215C823B5E0>对象已经删除
# Traceback (most recent call last):
# File "E:\pythonProjectText\text\__init__.py", line 12, in <module>
# print(haier)
# NameError: name 'haier' is not defined. Did you mean: 'aiter'?
注意:
-
如果一个类有多个对象,每个对象的属性是各自独立保存的,都是独立的地址。
-
但是实例方法是所有对象所共享的,只占用一份内存空间,类会通过self参数来判断是那个对象调用了该实例方法。
class Washer(): def __init__(self, width, height): # 初始化魔法方法 # 添加属性 self.width = width self.height = height def print_info(self): # 实例方法,对象方法 print('洗衣机的高度是:', self.height) print('洗衣机的宽度是:', self.width) hai1 = Washer(500, 1000) # print(id(hai1.width)) print(id(hai1.print_info())) # 洗衣机的高度是: 1000 # 洗衣机的宽度是: 500 # 140721883916280 hai2 = Washer(600, 1500) # print(id(hai2.width)) print(id(hai2.print_info())) # 洗衣机的高度是: 1500 # 洗衣机的宽度是: 600 # 140721883916280
__mro__
子类的魔法属性__mro__决定了属性和方法的查找顺序
class X: pass # 相当于class X(object): pass
class Y: pass # 相当于class X(object): pass
class A(X, Y): pass
class B(Y): pass
class C(A, B): pass
print(C.__mro__)
#(<class '__main__.C'>, <class '__main__.A'>, <class '__main__.X'>, <class '__main__.B'>, <class '__main__.Y'>, <class 'object'>)
__mro__ 是method resolution order,主要用于在对继承是判断方法、属性的调用路径【顺序】,其实也就是继承父类方法时的顺序表。在搜索方法时,是按照__mro__的输出结果从左到右的顺序查找的
- 如果当前类中找到方法,就直接执行,不再搜索
- 如果没有找到,就查找下一个类中是否有对应的方法,如果找到,就直接执行,不再搜索
- 如果找到最后一个类,还是没有找到方法,程序报错
__new__
__new__()需传递一个参数cls,__init__()需要传递一个参数self,self代表实例对象本身,cls代表类对象本身。__new__至少要有一个参数cls,代表要实例化的类,此参数在实例化时解释器自动提供,后面参数直接传给__init__。__new__()必须要有返回值,返回实例化出来的实例对象。__new__对当前类进行了实例化,并将实例返回,传给__init__的self。但执行__new__不一定执行__init__,仅__new__返回当前类cls的实例,当前类的__init__才会执行。若__new__没有正确返回当前类cls的实例,那__init__是不会被调用的,即使是父类的实例也不行,将没有__init__被调用。__new__方法主要继承一些不可变的class(比如int, str, tuple), 提供一个自定义这些类的实例化过程的途径。一般不去重写__new__()方法,它作为构造函数用于创建对象,是一个工厂函数,专用于生产实例对象。单例模式可以通过此方法来实现。在写框架级的代码时,可能会用到它,也可以从开源代码中找到它的应用场景,例如微型 Web 框架 Bootle 就用到了。
__init__()的第一个参数一定是self,__init__()方法负责对象的初始化,系统执行该方法前,该实例对象已经存在。
class A:
def __new__(cls, *args, **kwargs):
print("执行new方法")
return object.__new__(cls) # return super(A,cls).__new__(cls) 两条return语句作用相同
# object.__new__(cls)既调用父类(object)的__new__()
def __init__(self):
print("执行init方法")
print(self)
print(self.__class__)
a = A()
# 执行new方法
# 执行init方法
# <__main__.A object at 0x000001CF7F3A4150>
# <class '__main__.A'>
- 实例化A类对象时,调用
__init__初始化前首先调用类对象的__new__()方法,若该对象无__init__()方法则去父类中依次查找,直到object类。 - `
- 类开始实例化时,
__new__()方法会返回cls(cls指代当前类)的实例,然后该类的__init__()方法会接收这个示例(即self)作为自己的第一个参数,然后依次转入__new__()方法中接收的位置参数和命名参数。如果__new__()返回了其他类的实例,那么只会调用被返回的那个类的构造方法。例:
class A:
def __new__(cls, *args, **kwargs):
print("A的new方法")
return object.__new__(B)
def __init__(self):
print("A的init方法")
class B:
def __new__(cls, *args, **kwargs):
print("B的init方法")
return object.__new__(cls)
def __init__(self):
print("B的new方法")
a = A()
print(type(a))
print()
b = B()
print(type(b))
# A的new方法
# <class '__main__.B'>
#
# B的init方法
# B的new方法
# <class '__main__.B'>
__dict__
__dict__是用来存储对象属性的一个字典,其键为属性名,值为属性的值。
class A():
def __init__(self):
self.name="liming"
def save_data(self,dicts):
self.__dict__.update(dicts)#添加字典元素
if isinstance(self.__dict__, dict):
print(True)
# 获取字典独有的属性
print(set(dir(self.__dict__))-set(dir(self)))
return self.__dict__
if __name__ == '__main__':
dicts={"a":1,"b":2,"c":3}
a=A()
print(a.save_data(dicts))
输出结果:
True
{'__delitem__', 'keys', 'update', '__len__', '__getitem__', 'get', 'clear', 'copy', 'popitem', '__iter__', 'items', '__contains__', 'pop', '__setitem__', 'fromkeys', 'values', 'setdefault'}
{'name': 'liming', 'a': 1, 'b': 2, 'c': 3}
isinstance() 函数,是Python中的一个内置函数,用来判断一个函数是否是一个已知的类型,类似 type()。
# 语法
isinstance(object,classinfo)
# 参数:
# object : 实例对象。
# classinfo : 可以是直接或者间接类名、基本类型或者由它们组成的元组。
# 返回值:如果对象的类型与参数二的类型(classinfo)相同则返回 True,否则返回 False。
下面来一个比较实用的例子来大大的减少你的代码,做到真正的pythonic。
我们在使用给对象的属性赋值的时候:
class A():
def __init__(self,dicts):
self.name=dicts["name"]
self.age=dicts["age"]
self.sex=dicts["sex"]
self.hobby=dicts["hobby"]
if __name__ == '__main__':
dicts={"name":"lisa","age":23,"sex":"women","hobby":"hardstyle"}
a=A(dicts)
上面代码简化为:
class A():
def __init__(self,dicts):
self.__dict__.update(dicts)
print(self.__dict__)
if __name__ == '__main__':
dicts={"name":"lisa","age":23,"sex":"women","hobby":"hardstyle"}
a=A(dicts)
__dict__在单例模式中共享同一状态。拓展:部分内建函数不包含__dict__属性比如list,查看list的属性用dir(list),dir方法也是查看对象的属性,包括内建对象的属性,但是它的输出形式为列表,而__dict__是列表。
__getattr__
使用.获取属性的时候,如果该属性存在就输出其值,如果不存在则会去找_getatrr_,我们可以通过重写该方法可以实现动态属性的操作。(如果只允许添加指定的属性需要用__solts__函数控制)。先来一段比较有意思的代码:
from requests_html import HTMLSession
class UrlGenerator(object):
def __init__(self, root_url):
self.url = root_url
self.session=HTMLSession()
def __getattr__(self, item):
if item == 'get':
self.get_html()
return UrlGenerator('{}.{}'.format(self.url, item))
def get_html(self):
req = self.session.get(self.url)
print(req.text)
url_gen = UrlGenerator('https://www')
url_gen.baidu.com.get
充分利用__getattr__会在没有查找到相应实例属性时被调用的特点,方便的通过链式调用生成对应的url,在碰到get方法的时候调用函数获取其网页源码。
可调用的对象更加的优雅,链式的操作不仅优雅而且还能很好的说明调用的接口的意义。
下面展示一个__getattr__经典应用的例子,可以通过获取属性值的方式获取字典的键值。
class ObjectDict(dict):
def __init__(self, *args, **kwargs):
super(ObjectDict, self).__init__(*args, **kwargs)
def __getattr__(self, name):
value = self[name]
if isinstance(value, dict):
value = ObjectDict(value)
return value
if __name__ == '__main__':
od = ObjectDict(asf={'a': 1}, d=True)
print(od.asf,od.asf.a) # {'a': 1} 1
print(od.d) *# True*
__slots__
new-style class要求继承Python中的一个内建类型, 一般继承object,也可继承list或者dict等其他内建类型。在python新式类中定义变量__slots__的作用是阻止在实例化类时为实例分配dict(默认情况下每个类都会有一个dict,通过__dict__访问,这个dict维护了这个实例的所有属性)举例如下:
class base(object):
var = 9 # 类变量
def __init__(self):
pass
b = base()
print(b.__dict__)
b.x = 2 # 添加实例变量
print(b.__dict__)
# { }
# {‘x’: 2}
实例dict只保存实例的变量,对于类的属性(变量和函数)不保存,由于每次实例化一个类都要分配一个新的dict,因此存在空间的浪费,因此有了__slots__。__slots__是一个元组,包括了当前能访问到的属性。当定义了slots后,slots中定义的变量变成了类的描述符,类的实例只能拥有slots中定义的变量,不能再增加新的变量。注意:定义了slots后,就不再有dict。如下:
class Base(object):
__slots__ = 'x'
var = 8
def __init__(self):
pass
b = Base()
b.x = 88 # 添加实例变量
print(b.x)
b.y = 99
# 88
# Traceback (most recent call last):
# File "G:\python_project\Text\main.py", line 12, in <module>
# b.y = 99 # 无法添加slots之外的变量 (AttributeError: 'base' object has no attribute 'y')
# ^^^
# AttributeError: 'Base' object has no attribute 'y'
如果类变量与slots中的变量同名,则该变量被设置为read only!!!如下:
class Base(object):
__slots__ = 'y' # __slots__ 中的 'y' 与类变量冲突
y = 22 # y是类变量,y与__slots__中的变量同名
var = 11
def __init__(self):
pass
b = Base()
print(b.y)
print(Base.y)
# Traceback (most recent call last):
# File "G:\python_project\Text\main.py", line 1, in <module>
# class Base(object):
# ValueError: 'y' in __slots__ conflicts with class variable
Python为动态语言可在运行过程中修改实例的属性和增删方法。一般类的实例包含一个字典__dict__,Python通过这个字典可以将任意属性绑定到实例上。若只想使用固定的属性而不想任意绑定属性,就可定义一个属性名称集合,只有在这个集合里的名称才可绑定。__slots__就是这个"集合"。
class test_slots(object):
__slots__='x','y'
def printHello(self):
print 'hello!'
class test(object):
def printHello(self):
print 'hello'
print dir(test_slots) #可以看到test_slots类结构里面包含__slots__,x,y
print dir(test)#test类结构里包含__dict__
print '**************************************'
ts=test_slots()
t=test()
print dir(ts) #可以看到ts实例结构里面包含__slots__,x,y,不能任意绑定属性
print dir(t) #t实例结构里包含__dict__,可以任意绑定属性
print '***************************************'
ts.x=11 #只能绑定__slots__名称集合里的属性
t.x=12 #可以任意绑定属性
print ts.x,t.x
ts.y=22 #只能绑定__slots__名称集合里的属性
t.y=23 #可以任意绑定属性
print ts.y,t.y
#ts.z=33 #无法绑定__slots__集合之外的属性(AttributeError: 'test_slots' object has no attribute 'z')
t.z=34 #可以任意绑定属性
print t.z
运行结果:
[‘class’, ‘delattr’, ‘doc’, ‘format’, ‘getattribute’, ‘hash’, ‘init’, ‘module’, ‘new’, ‘reduce’, ‘reduce_ex’, ‘repr’, ‘setattr’, ‘sizeof’, ’ slots’, ‘str’, ‘subclasshook’, ‘printHello’, ’ x’, ‘y’]
[‘class’, ‘delattr’, ’ dict’, ‘doc’, ‘format’, ‘getattribute’, ‘hash’, ‘init’, ‘module’, ‘new’, ‘reduce’, ‘reduce_ex’, ‘repr’, ‘setattr’, ‘sizeof’, ‘str’, ‘subclasshook’, ‘weakref’, ‘printHello’]
[‘class’, ‘delattr’, ‘doc’, ‘format’, ‘getattribute’, ‘hash’, ‘init’, ‘module’, ‘new’, ‘reduce’, ‘reduce_ex’, ‘repr’, ‘setattr’, ‘sizeof’, ’ slots’, ‘str’, ‘subclasshook’, ‘printHello’, ’ x’, ‘y’]
[‘class’, ‘delattr’, ’ dict’, ‘doc’, ‘format’, ‘getattribute’, ‘hash’, ‘init’, ‘module’, ‘new’, ‘reduce’, ‘reduce_ex’, ‘repr’, ‘setattr’, ‘sizeof’, ‘str’, ‘subclasshook’, ‘weakref’, ‘printHello’]
11 12
22 23
34
正如上面所说的,默认情况下,Python的新式类和经典类的实例都有一个
dict来存储实例的属性。这在一般情况下还不错,而且非常灵活,
乃至在程序中可以
随意设置新的属性。但是,对一些在”编译”前就知道有几个固定属性的小class来说,这个dict就有点浪费内存了。
当需要创建大量实例的时候,这个问题变得尤为突出。一种解决方法是在
新式类中定义一个__slots__属性。
__slots__声明中包含若干实例变量,并为每个实例预留恰好足够的空间来保存每个变量;这样Python就不会再使用dict,从而节省空间。
【使用memory_profiler模块,memory_profiler模块是在逐行的基础上,测量代码的内存使用率。尽管如此,它可能使得你的代码运行的更慢。使用装饰器@profile来标记哪个函数被跟踪。】
下面,我们看一个例子:
from memory_profiler import profile
class A(object): #没有定义__slots__属性
def __init__(self,x):
self.x=x
@profile
def main():
f=[A(523825) for i in range(100000)]
if __name__=='__main__':
main()
1234567891011
运行结果,如下图:
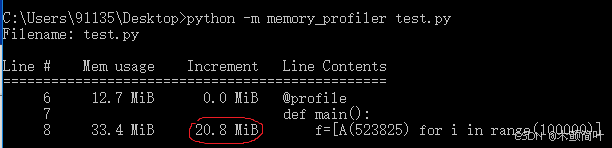
第2列表示该行执行后Python解释器的内存使用情况,
第3列表示该行代码执行前后的内存变化。
在没有定义__slots__属性的情况下,该代码共使用了20.8MiB内存。
从结果可以看出,内存使用是以MiB为单位衡量的,表示的mebibyte(1MiB = 1.05MB)
from memory_profiler import profile
class A(object):#定义了__slots__属性
__slots__=('x')
def __init__(self,x):
self.x=x
@profile
def main():
f=[A(523825) for i in range(100000)]
if __name__=='__main__':
main()
123456789101112
运行结果,如下图:
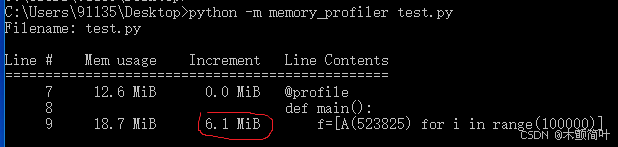
可以看到,在定义了__slots__属性的情况下,该代码共使用了6.1MiB内存,比上面的20.8MiB节省了很多内存!
综上所述,在确定了
类的属性固定的情况下,可以
使用__slots__来优化内存。
提醒:不要贸然进行这个优化,把它用在所有地方。这种做法不利于代码维护,而且只有生成数以千计的实例的时候才会有明显效果。
七、实例:学员管理系统
-
了解面向对象开发过程中内部功能实现的分析方法
-
了解常用系统的功能
- 添加
- 删除
- 修改
- 查询
-
系统要求:学员的学员信息需要存储在文件中
-
系统功能:添加学员,删除学员,修改学员信息,查询学员信息,显示学员信息,保存学员信息,以及退出系统等功能。
1.程序文件准备
- 角色分析
- 管理系统
- 学员
工作过程中需要注意的地方:
1.为了方便维护代码,一般一个角色一个程序文件
2.项目要有主程序入口,习惯命名为main.py
2.程序文件创建
创建项目目录:比如说: StudentManageSystem
程序文件:
- 程序入口文件:main.py
- 学员文件:students.py
- 管理系统文件:managersystem.py
3.书写程序
1)students.py
需求:
- 学员信息:姓名,性别,手机号
- 添加str魔法方法,方便查看学员信息
class Student(object):
def __init__(self, name, gender, tel):
self.name = name
self.gender = gender
self.tel = tel
def __str__(self):
return f"{self.name}, {self.gender}, {self.tel}"
if __name__ == '__main__':
tongxue = Student('8280同学', '男', 3247953)
print(tongxue)
tongxue2 = Student('7179同学', '女', 3453643)
print(tongxue2)
2)managersystem.py
需求:
- 系统功能
- 添加学员
- 删除学员
- 修改学员
- 查询学员
- 显示所有学员
- 保存学员
- 退出系统
- 存储数据文件的位置:文件(student.data)
- 加载文件数据
- 修改数据后保存在文件中
- 存储数据的形式:在系统中列表存储学员对象,数据文件中字典加列表组合。
(1)定义类
class StudentManager(object):
def __init__(self):
# 存储数据的列表
self.student_list = []
(2)管理系统的框架
需求:系统功能循环使用,用户输入不同的功能序号执行不同的功能。
- 步骤:
- 定义程序入口
- 加载学员信息
- 显示功能菜单
- 用户输入功能序号
- 根据用户输入的不同的序号执行不同的功能
- 定义系统功能函数,例如增删改查等
- 定义程序入口
def run(self):
"""程序的入口函数,也就是程序运行之后的函数"""
# 加载学员信息
self.load_student()
while True:
# 显示功能菜单
self.show_menu()
# 用户输入功能序号
menu_num = int(input('请输入您要执行的功能的序号:'))
# 根据用户输入的序号执行对应的不同方法
if menu_num == 1:
# 添加学员
self.add_student()
elif menu_num == 2:
# 删除学员
self.del_student()
elif menu_num == 3:
# 修改学员
self.modify_student()
elif menu_num == 4:
# 查询学员
self.search_student()
elif menu_num == 5:
# 显示所有学员
self.show_student()
elif menu_num == 6:
# 保存学员
self.save_students()
elif menu_num == 7:
# 退出系统
break
def add_student(self):
pass
def del_student(self):
pass
def modify_student(self):
pass
def search_student(self):
pass
def show_student(self):
pass
def save_students(self):
pass
@staticmethod
def show_menu():
print('请输入如下功能序号:')
print("1:添加学员")
print("2:删除学员")
print("3:修改学员")
print("4:查询学员")
print("5:显示所有学员")
print("6:保存学员信息")
print("7:退出系统")
def load_student(self):
# 加载学员信息
pass
3)main.py
# 导入managersystem模块
import managersystem
if __name__ == '__main__':
# 启动学员管理系统
students_manager = managersystem.StudentManager()
students_manager.run()
定义系统功能函数
(1)添加功能
- 需求:用户输入学员信息,将用户输入的学员信息添加到系统模块中。
- 步骤:
- 用户输入姓名,性别,电话
- 创建学员对象
- 将学员对象添加到系统中。
- 代码
def add_student(self):
# - 用户输入姓名,性别,电话
name = input('请输入学员姓名:')
gender = input('请输入学员性别:')
tel = input('请输入学员电话:')
# - 创建学员对象
student = Student(name, gender, tel)
# - 将学员对象添加到系统中。
self.student_list.append(student)
# 打印学员信息
print(self.student_list)
print(student)
(2)删除学员信息
- 步骤:
- 用户输入学员姓名
- 遍历学员列表,如果存在即删除,如果不存在即提示学员不存在
- 代码
def del_student(self):
# - 用户输入学员姓名
del_name = input('请输入您要删除学员的姓名:')
# - 遍历学员列表,如果存在即删除,如果不存在即提示学员不存在
for i in self.student_list:
if del_name == i.name:
self.student_list.remove(i)
break
else:
print('您要删除的学员不存在')
(3)修改学员信息
- 用户输入姓名
- 遍历列表,如果存在即修改姓名性别电话,如果不存在就提示不存在
def modify_student(self):
# - 用户输入姓名
modify_name = input('请输入您要修改的学员姓名:')
# - 遍历列表,如果存在即修改姓名性别电话,如果不存在就提示不存在
for i in self.student_list:
if modify_name == i.name:
i.name = input('姓名:')
i.gender = input("性别:")
i.tel = input("电话:")
print(f"修改学员信息成功,姓名{i.name},性别{i.gender},电话{i.tel}")
break
else:
print('您要修改的学员信息不存在。')
(4)保存学员信息
- 需求:将学员信息保存到存储数据的文件中
- 步骤:
- 打开文件
- 写入数据
- 关闭文件
思考:
文件写入的时候,写入的数据是学员具体信息还是对象地址
文件数据要求的数据类型是什么?
- 代码
def save_student(self):
# - 打开文件
f = open('student.data', 'w')
# - 写入数据
# 注意1:文件写入不能是学员对象的内存地址,必须是具体学员信息,需要把学员信息转换成字典再存储
new_list = [i.__dict__ for i in self.student_list]
print(new_list)
# 文件内的数据要求为字符串儿类型,故存入数据前需要强转
f.write(str(new_list))
# - 关闭文件
f.close()




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











