







一、行结构
1.注释
注释以井号 (#) 开头,在物理行末尾截止。注意,井号不是字符串字面值。除非应用隐式行拼接规则,否则,注释代表逻辑行结束。句法不解析注释。
1)种类
-
含义:注释是对代码的解释说明,注释的内容不会被当作代码运行
-
作用:增强代码的可读性
-
种类:单行注释:开头用
#号,可以跟在代码的正上方或者正后方 快捷键 :Ctrl+?
多行注释:用三对引号 ‘’‘多行注释’’’ “”“多行注释”“”
- 代码注释的原则:注释可用中文或英文,但不要用拼音
- 在#后跟TODO,可用于标记需要去做的工作
2)编码声明
Python 脚本第一或第二行的注释匹配正则表达式 coding[=:]\s*([-\w.]+) 时,该注释会被当作编码声明;这个表达式的第一组指定了源码文件的编码。编码声明必须独占一行,在第二行时,则第一行必须也是注释。编码表达式的形式如下:
# -*- coding: <encoding-name> -*-
这也是 GNU Emacs 认可的形式,此外,还支持如下形式:
# vim:fileencoding=<encoding-name>
这是 Bram Moolenaar 的 VIM 认可的形式。
如果没有找到编码格式声明,则默认编码格式为 UTF-8。 如果文件的隐式或显式编码格式为 UTF-8,则初始的 UTF-8 字节序标志(b’xefxbbxbf’)将被忽略而不会报告语法错误。
如果声明了编码格式,该编码格式的名称必须是 Python 可识别的 (参见 标准编码)。 编码格式会被用于所有的词法分析,包括字符串字面值、注释和标识符等。
2.行
1)逻辑行
Python 程序可以拆分为多个 逻辑行。
NEWLINE 形符表示结束逻辑行。语句不能超出逻辑行的边界,除非句法支持 NEWLINE (例如,复合语句中的多行子语句)。根据显式或隐式 行拼接 规则,一个或多个 物理行 可组成逻辑行。
2)物理行
物理行是一序列字符,由行尾序列终止。源文件和字符串可使用任意标准平台行终止序列 - Unix ASCII 字符 LF (换行)、 Windows ASCII 字符序列 CR LF (回车换行)、或老式 Macintosh ASCII 字符 CR (回车)。不管在哪个平台,这些形式均可等价使用。输入结束也可以用作最终物理行的隐式终止符。
嵌入 Python 时,传入 Python API 的源码字符串应使用 C 标准惯例换行符(\n,代表 ASCII 字符 LF, 行终止符)。
3)拼接行
(1)显式拼接行
两个及两个以上的物理行可用反斜杠(\)拼接为一个逻辑行,规则如下:以不在字符串或注释内的反斜杠结尾时,物理行将与下一行拼接成一个逻辑行,并删除反斜杠及其后的换行符。例如:
if 1900 < year < 2100 and 1 <= month <= 12 \
and 1 <= day <= 31 and 0 <= hour < 24 \
and 0 <= minute < 60 and 0 <= second < 60: # Looks like a valid date
return 1
以反斜杠结尾的行,不能加注释;反斜杠也不能拼接注释。除字符串字面值外,反斜杠不能拼接形符(如,除字符串字面值外,不能用反斜杠把形符切分至两个物理行)。反斜杠只能在代码的字符串字面值里,在其他任何位置都是非法的。
(2)隐式拼接行
圆括号、方括号、花括号内的表达式可以分成多个物理行,不必使用反斜杠。例如:
month_names = ['Januari', 'Februari', 'Maart', # These are the
'April', 'Mei', 'Juni', # Dutch names
'Juli', 'Augustus', 'September', # for the months
'Oktober', 'November', 'December'] # of the year
隐式行拼接可含注释;后续行的缩进并不重要;还支持空的后续行。隐式拼接行之间没有 NEWLINE 形符。三引号字符串支持隐式拼接行(见下文),但不支持注释。
4)空白行
只包含空格符、制表符、换页符、注释的逻辑行会被忽略(即不生成 NEWLINE 形符)。交互模式输入语句时,空白行的处理方式可能因读取 - 求值 - 打印循环(REPL)的具体实现方式而不同。标准交互模式解释器中,完全空白的逻辑行(即连空格或注释都没有)将结束多行复合语句。
3.缩进
逻辑行开头的空白符(空格符和制表符)用于计算该行的缩进层级,决定语句组块。
制表符(从左至右)被替换为一至八个空格,缩进空格的总数是八的倍数(与 Unix 的规则保持一致)。首个非空字符前的空格数决定了该行的缩进层次。缩进不能用反斜杠进行多行拼接;首个反斜杠之前的空白符决定了缩进的层次。
源文件混用制表符和空格符缩进时,因空格数量与制表符相关,由此产生的不一致将导致不能正常识别缩进层次,从而触发 TabError。
跨平台兼容性说明: 鉴于非 UNIX 平台文本编辑器本身的特性,请勿在源文件中混用制表符和空格符。另外也请注意,不同平台有可能会显式限制最大缩进层级。
行首含换页符时,缩进计算将忽略该换页符。换页符在行首空白符内其他位置的效果未定义(例如,可能导致空格计数重置为零)。
连续行的缩进层级以堆栈形式生成 INDENT 和 DEDENT 形符,说明如下。
读取文件第一行前,先向栈推入一个零值,该零值不会被移除。推入栈的层级值从底至顶持续增加。每个逻辑行开头的行缩进层级将与栈顶行比较。如果相等,则不做处理。如果新行层级较高,则会被推入栈顶,并生成一个 INDENT 形符。如果新行层级较低,则 应当 是栈中的层级数值之一;栈中高于该层级的所有数值都将被移除,每移除一级数值生成一个 DEDENT 形符。文件末尾,栈中剩余的每个大于零的数值生成一个 DEDENT 形符。
4.形符间的空白字符
除非在逻辑行开头或字符串内,空格符、制表符、换页符等空白符都可以分隔形符。要把两个相连形符解读为不同形符,需要用空白符分隔(例如,ab 是一个形符,a b 则是两个形符)。
二、形符
除 NEWLINE、INDENT、DEDENT 外,还有 标识符、关键字、字面值、运算符 、分隔符 等形符。 空白符(前述的行终止符除外)不是形符,可用于分隔形符。存在二义性时,将从左至右,读取尽量长的字符串组成合法形符。
1.标识符(Identifiers)
在Python中,标识符是用于命名变量、函数、类、模块或其他对象的名称。标识符的命名规则如下:
- 首字符:必须是字母(a-z,A-Z)或下划线(_)。
- 后续字符:可以是字母、数字(0-9)或下划线。
- 区分大小写:Python区分大小写,即
myVariable和myvariable是不同的标识符。 - 长度:标识符的长度没有限制,但过长的标识符不建议使用。
- 保留字:标识符不能与Python的关键字相同。
python复制代码myVariable = 10
_my_variable = 20
myVariable2 = 30
1)变量
-
含义:变量是可以变化的量,量指的是事物的状态,比如人的年龄、性别,游戏角色的等级、金钱等等。变量(Variable)有独一无二的名字,通过变量的名字就能找到变量中的数据。从底层看,程序中的数据最终都要放到内存(内存条)中,变量就是这块内存的名字
-
作用:任何编程语言都需要处理数据,比如数字、字符串、字符等,我们可以直接使用数据,也可以将数据保存到变量中,方便以后使用。
-
使用变量
原则:先定义,后使用
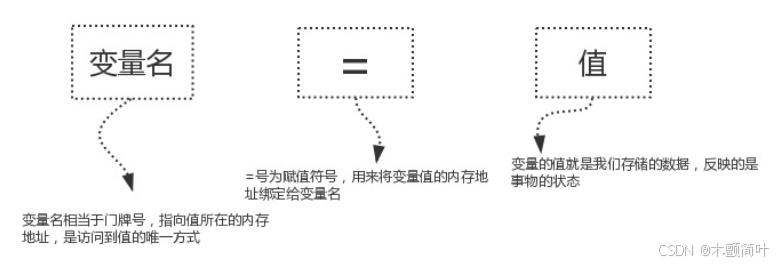
变量的定义由三部分组成
- 变量名:是指向等号右侧值的内存地址的,用来访问等号右侧的值
- 赋值符号:将变量值的内存地址绑定给变量名
- 变量值:代表记录的事物的状态
解释器执行到变量定义的代码时会申请内存空间存放变量值,然后将变量值的内存地址绑定给变量名,通过变量名即可引用到对应的值
-
变量名的命名规范(变量名的命名应该见名知意,不建议使用中文,拼音)
1.变量名只能是字母、数字或下划线的任意组合
2.变量名的第一个字符不能是数字
3.关键字不能声明为变量名,常用关键字如下'False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield' -
变量名的命名风格
-
驼峰体
AgeOfTony = 56
-
纯小写下划线连接法(在python中,变量名的命名推荐使用该风格)
age_of_tony = 56
-
-
变量值的三大特性
-
id
反应的是变量在内存中的唯一编号,内存地址不同id肯定不同
print(id())
-
type
变量值的类型,不同类型的值用来表示记录不同的状态
print(type())
-
value
变量值本身
-
-
is和==的区别
is:比较左右两个值身份id(内存地址)是否相等==:比较左右两个值是否一样
id不同的情况下,值有可能相等,即两块不同的内存空间里可以存相同的值
id相同的情况下,值一定相同, x is y成立,那么x == y也必然成立
-
小整数池:[-5,256]
小整数池目的:节省内存,提高执行效率
原因:Python实现int的时候有小整数池。为了避免因创建相同的值而重复申请内存空间所带来的效率问题, Python解释器会在启动时创建出小整数池,范围是[-5,256],该范围内的小整数对象是全局解释器范围内被重复使用,永远不会被垃圾回收机制回收。
假设:
# 文件1中 # 文件2中 # 文件3中 # 文件4中
a=-5 a=-6 a=256 a=257
b=-5 b=-6 b=256 b=257
a is b a is b a is b a is b
#True #False #True #False
大整数对象池:
超出小整数的范围即为大整数,每次都会创建一个新的对象。但是处于一个代码块的大整数是同一个对象。
# 代码块1
class 1:
a=100
b=100
c=1000
d=1000
# 代码块2
class 2:
a=100
b=1000
结果
# 相同代码块中的小整数使用同一个地址处的值
A.a is A.b
# True
# 相同代码块中的大整数不会再次申请内存存放相同数字
A.c is A.d
# False
# 不同代码块中的小整数使用同一个地址处的值
A.a is B.a
# True
# 不同代码块中的大整数相同的值会再次申请内存储存
A.c is B.b
# False
在pycharm中情况有所不同:在pycharm中运行python程序时,出于对性能的考虑,会扩大小整数池的范围,其他字符串等不可变类型也都包含在内采用相同的方式处理了,这是一种优化机制,范围无需细究。
a = 1000
b = 1000
print(a is b)
# True
2)常量
-
含义:常量指在程序运行过程中不会改变的量
-
作用:在程序运行过程中,有些值是固定的、不应该被改变,如圆周率 3.141592653…
-
使用常量
用全部大写的变量名表示常量。如:PI=3.14159。从语法层面常量的使用与变量完全一致
-
Python是弱类型的语言
在强类型的编程语言中,定义变量时要指明变量的类型,而且赋值的数据也必须是相同类型C语言、C++、Java 是强类型语言的代表
和强类型语言相对应的是弱类型语言,Python、JavaScript、PHP 等脚本语言一般都是弱类型的
弱类型语言有两个特点:
变量无须声明就可以直接赋值,对一个不存在的变量赋值就相当于定义了一个新变量
变量的数据类型可以随时改变,比如,同一个变量可以一会儿被赋值为整数,一会儿被赋值为字符串
注意,弱类型并不等于没有类型!弱类型是在书写代码时不用刻意关注类型,但在编程语言的内部仍然是有类型的。我们可以使用 type() 内置函数类检测某个变量或者表达式的类型
3)保留的标识符类
某些标识符类(除了关键字)具有特殊含义。这些类的命名模式以下划线字符开头,并以下划线结尾:
-
_*不会被
from module import *所导入。 -
_在
match语句内部的case模式中,_是一个 软关键字,它表示 通配符。在此之外,交互式解释器会将最后一次求值的结果放到变量_中。 (它与print等内置函数一起被存储于builtins模块。)在其他地方,_是一个常规标识符。 它常常被用来命名 “特殊” 条目,但对 Python 本身来说毫无特殊之处。备注_常用于连接国际化文本;详见gettext模块文档。它还经常被用来命名无需使用的变量。 -
__*__系统定义的名称,通常简称为 “dunder” 。这些名称由解释器及其实现(包括标准库)定义。现有系统定义名称相关的论述详见 特殊方法名称 等章节。Python 未来版本中还将定义更多此类名称。任何情况下,任何 不显式遵从
__*__名称的文档用法,都可能导致无警告提示的错误。 -
__*类的私有名称。类定义时,此类名称以一种混合形式重写,以避免基类及派生类的 “私有” 属性之间产生名称冲突。详见 标识符(名称)。
2.关键字(Keywords)
关键字是Python中保留用于特殊语法功能的词,不能用作标识符。Python的关键字可以通过 keyword 模块查看:
import keyword
print(keyword.kwlist)
以下标识符为保留字,或称 关键字,不可用于普通标识符。关键字的拼写必须与这里列出的完全一致:
False await else import pass
None break except in raise
True class finally is return
and continue for lambda try
as def from nonlocal while
assert del global not with
async elif if or yield
某些标识符仅在特定上下文中被保留。 它们被称为 软关键字。 match, case, type 和 _ 等标识符在特定上下文中具有关键字的语义,但这种区分是在解析器层级完成的,而不是在分词的时候。
作为软关键字,它们能够在用于相应语法的同时仍然保持与用作标识符名称的现有代码的兼容性。
match, case 和 _ 是在 match 语句中使用。 type 是在 type 语句中使用。
type 现在是一个软关键字。
3.字面值(Literals)
字面值是代码中直接表示的固定值。常见的字面值类型有:
- 整数(Integers):如
10,-5 - 浮点数(Floats):如
3.14,-0.001 - 字符串(Strings):如
"hello",'world' - 布尔值(Booleans):
True,False - None:表示空值
integer_literal = 42
float_literal = 3.14159
string_literal = "Hello, World!"
boolean_literal = True
none_literal = None
1)字符串与字节串
两种类型的字面值都可用成对的单引号 (') 或双引号 (") 括起来。 它们还可以用成对的连续三个单引号或双引号括起来 (这通常被称为 三重引号字符串)。 反斜杠 (\) 字符被用来给予普通的字符特殊含义例如 n,当用斜杠转义时 (\n) 表示 ‘换行’。 它还可以被用来对具有特殊含义的字符进行转义,例如换行符、反斜杠本身或者引号等。 请参阅下面的 转义序列 查看示例。
字节串字面值要加前缀 'b' 或 'B';生成的是类型 bytes 的实例,不是类型 str 的实例;字节串只能包含 ASCII 字符;字节串数值大于等于 128 时,必须用转义表示。
字符串和字节串都可以加前缀 'r' 或 'R',称为 原始字符串,原始字符串把反斜杠当作原义字符,不执行转义操作。因此,原始字符串不转义 '\U' 和 '\u'。
4.分隔符(Delimiters)
分隔符用于分隔代码中的不同部分,包括括号、逗号、冒号等。常见的分隔符有:
- 小括号:
() - 中括号:
[] - 大括号:
{} - 逗号:
, - 冒号:
: - 分号:
; - @符号:
@ - 等号:
= - 点号:
. - 箭头:
-> - 运算符赋值:
+=,-=,*=,/=
句点也可以用于浮点数和虚数字面值。三个连续句点表示省略符。列表后半部分是增强赋值操作符,用作词法分隔符,但也可以执行运算。
以下 ASCII 字符具有特殊含义,对词法分析器有重要意义:
' " # \
以下 ASCII 字符不用于 Python。在字符串字面值或注释外使用时,将直接报错:
$ ? `
示例:
def my_function(a, b):
return a + b
my_list = [1, 2, 3]
my_dict = {'key': 'value'}
通过这些基本元素,Python能够提供灵活且强大的编程能力。每一个元素都有其特定的用途和规则,了解并掌握这些元素有助于更好地编写和理解Python代码。
二、运算符
1.运算符分类
1)算术运算符
假设有两个变量:a=10, b=20
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加——>两个数相加 | a + b 输出结果 30 |
| - | 减——>得到负数或是一个数减去另一个数 | a - b 输出结果 -10 |
| * | 乘——>两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 200 |
| / | 除——>b 除以 a | b / a 输出结果 2 |
| % | 取模(取余数)——>返回除法的余数 | b % a 输出结果 0 |
| ** | 幂——>返回a的b次幂 | a**b为10的20次方,输出结果100000000000000000000 |
| // | 取整数——>返回商的整数部分(向下取整) | 9 // 2 ——>4 |
| () | 小括号 | 提高运算符优先级,比如(1+2)*3 |
2)赋值运算符
a = 20 b = 10 c = 200
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | 把 = 号右边的结果 赋给 左边的变量 如:num = 1 + 2 * 3 |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c * *= a 等效于 c = c ** a |
| //= | 取整数赋值运算符 | c //= a 等效于 c = c // a |
3)比较运算符
a = 10 b = 20
注意:True和False 的首字母为大写
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于 – 比较对象是否相等 | (a == b) 返回 False |
| != | 不等于–比较两个对象是否不相等 | (a != b) 返回 True |
| > | 大于–返回x是否大于y | (a > b) 返回 False |
| < | 小于–返回x是否小于y | (a < b) 返回True |
| >= | 大于或者等于–返回x是否大于等于y | (a >= b) 返回 False |
| <= | 小于或者等于–返回x是否小于等于y | (a <= b) 返回 True |
# 所有的比较运算符返回1表示真,返回0表示假,这分别与True和False等价
与赋值一样,Python也支持链式比较:可同时使用多个比较运算符,如0 < age < 100。
4)逻辑运算符
p为真命题,q为假命题,那么p且q为假,p或q为真,非q为真。and 、or、not全部都是小写字母。
| 逻辑运算符 | 含义 | 基本格式 | 说明 |
|---|---|---|---|
| and | 逻辑与运算,”且“ | a and b | 当a和b两个表达式都为真时结果才为真,否则为假 |
| or | 逻辑或运算,”或“ | a or b | 当 a 和 b两个表达式都为假时结果才是假,否则为真 |
| not | 逻辑非运算,”非“ | not a | 如果 a 为真,那么not a的结果为假;如果 a 为假,那么not a的结果为真,相当于对 a 取反 |
a = 14 > 6 # True
b = 45 > 90 # False
print(a and b) # False
print(a or b) # True
print(not a) # False 相当于对a取反
逻辑运算符的本质
对于and运算符,两边的值都为真时结果才为真,其中有一个值为假,结果就是假
- 如果左边表达式的值为假,不计算右边表达式的值,and会把左边表达式的值作为最终结果
- 如果左边表达式的值为真,最终值不能确定,and会继续计算右边表达式的值并将其作为最终结果
对于or运算符,两边值都为假时结果才为假,只要有一个值为真,那么结果就是真
- 如果左边表达式的值为真,最终结果都是真,此时or会把左边表达式的值作为最终结果
- 如果左边表达式的值为假,最终值不能确定,or会继续计算右边表达式的值,并将其作为最终结果
5)位运算符
用于对整数类型进行二进制位的操作。
- 按位与(&):例如
a & b - 按位或(|):例如
a | b - 按位异或(^):例如
a ^ b - 按位取反(~):例如
~a - 左移(<<):例如
a << b - 右移(>>):例如
a >> b
5)成员运算符
用于判断对象是某个集合的元素之一,返回结果是bool类型
| 运算符 | 描述 |
|---|---|
| in | 指定序列中找到值返回True,否则返回False |
| not in | 指定的序列中没有找到值返回True,否则返回False |
a = 'dog'
b = 'rabbit'
animals = ["dog","elephant","snake"]
print(a in animals) # True
print(b in animals) # False
print(a not in animals) # False
print(b not in animals) # True
6)身份运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 判断两个标识符是否引用自一个对象 | a is b,类似id(a) == id(b),如果引用的是同一个对象则返回True,否则返回False |
| is not | is not 判断两个标识符是否引用自不同的对象 | a is not b,类似id(a) ! = id(b),如果引用的不是同一个对象则返回结果True,否则返回False |
注意is和==两者有根本上的区别
- is用于判断两个变量的引用是否为同一个对象,is比较的是本质(也就是内存地址)
- ==用于判断变量引用的对象的值是否相等,==比较的是表面(也就是数值)
a=1
b=1.0
print(a == b)
print(a is b)
True
False
同一对象认定方法:查看某个变量或对象的内存地址 id(),两个相同的内存地址的对象被认为是同一对象
a=1
b=1.0
print(id(a))
print(id(b))
1647214704
1647997751656
2.运算符的优先级
| 运算符 | 描述 |
|---|---|
| ** | 指数(最高优先级) |
| ~ + - | 按位翻转,一元加号和减号(最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整数 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 “AND” |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is,is not | 身份运算符 |
| in,not in | 成员运算符 |
| not or and | 逻辑运算符 |
优先级高的运算符优先计算或处理,同级别按从左往右的顺序计算(赋值运算符除外,它从右往左)
- 算术运算符 优先级大于 比较运算符
- 比较运算符 优先级大于 逻辑运算符
- 逻辑运算符的内部有三个优先级:not>and>or
按照执行流程划分,Python 程序可分为 3 大结构,即顺序结构、选择(分支)结构和循环结构:
- 顺序结构是让程序从头到尾依次执行每一条 Python 代码,不重复执行任何代码,也不跳过任何代码
- 选择结构也称分支结构,有选择性的执行代码;可以跳过没用的代码,只执行有用的代码
- 循环结构就是让程序“杀个回马枪”,不断地重复执行同一段代码
三、结构语句
1.分支语句 if else
分支结构就是根据条件判断的真假去执行不同分支对应的子代码
# if 语句
if 表达式:
代码块
# if else 语句
if 表达式:
代码块1
else:
代码块2
# if elif else 语句
if 表达式1:
代码块1
elif 表达式2:
代码块2
elif 表达式3:
代码块3
else:
代码块n
1)注意事项
-
if、elif、else 语句的最后都有冒号
: -
elif 和 else 都不能单独使用必须和 if 一起出现,且要正确配对
-
表达式可以是单一的值或者变量,也可以是由运算符组成的复杂语句,但执行结果必须为布尔类型
-
一旦某个表达式成立就会执行它后面对应的代码块;如果所有表达式都不成立,就执行 else 后面的代码块;如果没有 else 部分,那就什么也不执行
-
在if判断中所有数据类型都会自动转换成布尔类型,用作布尔表达式(如用作if语句中的条件)时,下面的值都将被解释器视为假,但它们并不相等:
False None 0 “” () [] {}
-
换而言之,标准值False和None、各种类型(包括浮点数、复数等)的数值0、空序列(如空
字符串、空元组和空列表)以及空映射(如空字典)都被视为假,而其他各种值都被视为真,
包括特殊值True
2)缩进要求
- 不要忘记缩进
if、elif 和 else 后面的代码块一定要缩进,而且缩进量要大于 if、elif 和 else 本身
- 缩进1 个 Tab 键
Python 要求代码块必须缩进,缩进量不限,建议缩进 1 个 Tab 键的位置或缩进 4 个空格;两者等价
- 所有语句都要缩进,且同一代码块缩进量要相同
一个代码块的所有语句都要缩进,而且缩进量必须相同。
- 不要随便缩进
不需要使用代码块的地方千万不要缩进,一旦缩进就会产生一个代码块
3)语句嵌套
if、if else 和 if elif else,这 3 种条件语句间可相互嵌套
# 在最简单的 if 语句中嵌套 if else 语句
if 表达式1:
if 表示式2:
代码块1
else:
代码块2
# 在 if else 语句中嵌套 if else 语句
if 表示式 1:
if 表达式2:
代码块1
else:
代码块2
else:
if 表达式3:
代码块3
else:
代码块4
if、if else 和 if elif else 之间可相互嵌套。开发程序时根据场景需要选择合适的嵌套方案。在相互嵌套时,一定要严格遵守不同级别代码块的缩进规范
number = int(input('Enter a number between 1 and 10: '))
if number <= 10:
if number >= 1:
print('Great!')
else:
print('Wrong!')
else:
print('Wrong!')
# 这有点笨拙,因为输入了print('Wrong!')两次。
number = int(input('Enter a number between 1 and 10: '))
if number <= 10 and number >= 1:
print('Great!')
else:
print('Wrong!')
# 通过使用链式比较1 <= number <= 10可进一步简化示例。
number = int(input('Enter a number between 1 and 10: '))
if 1 <= number <= 10:
print('Great!')
else:
print('Wrong!')
4)三目(元)运算符(表达式)
# 语法:条件为真时的结果 if 判断的条件 else 条件为假时的结果
a if a>b else c if c>d else d
# 应该理解为
a if a>b else ( c if c>d else d )
三元表达式是一种简化代码的解决方案,语法如下
res = 条件成立时返回的值 if 条件 else 条件不成立时返回的值
def max2(x,y):
if x > y:
return x
else:
return y
res = max2(1,2)
# 用三元表达式可以一行解决
x=1
y=2
res = x if x > y else y # 三元表达式
2.循环语句
python中有while与for两种循环机制,其中while循环称之为条件循环
1)while
while 条件表达式:
代码块
# 此代码块指缩进格式相同的多行代码,在循环结构中,代码块又称为循环体
-
while 语句执行流程:
首先判断条件表达式的值,其值为真(True)时执行代码块中的语句,执行完毕后,再回来重新判断条件表达式的值是否为真,若仍为真,则继续重新执行代码块…如此循环,直到条件表达式的值为假(False)才终止循环
注意:使用 while 循环时要保证循环条件有变假时(循环结构中至少有一个位置能让循环条件为 False 或让 break 语句得以执行),否则将成为死循环(无法结束循环)。纯计算无IO的死循环会导致致命的效率问题
2)for
循环结构的第二种方式for循环可做的while循环都可实现,但在循环取值(即遍历值)时for循环比while循环更为简洁。它常用于遍历字符串、列表、元组、字典、集合等序列类型,逐个获取序列中的各个元素。只要能够使用for循环,就不要使用while循环。
# for 循环的语法格式
for 变量名 in 可迭代对象:
代码一
代码二
...
for item in ['a','b','c']:
print(item) # a b c
# 步骤1:从列表['a','b','c']中读出第一个值赋值给item(item=‘a’),然后执行循环体代码
# 步骤2:从列表['a','b','c']中读出第二个值赋值给item(item=‘b’),然后执行循环体代码
# 步骤3: 重复以上过程直到列表中的值读尽
3)else
while 循环和 for 循环其后都可紧跟着一个 else 代码块,当循环正常执行完且中间没有被break 中止就会执行else后面的语句,所以可用else来验证循环是否正常结束。
如果执行过程中被break,就不会执行else的语句
count = 0
while count <= 5 :
count += 1
print("Loop",count)
else:
print("循环正常执行完啦")
print("-----out of while loop ------")
# 输出
# Loop 1
# Loop 2
# Loop 3
# Loop 4
# Loop 5
# Loop 6
# 循环正常执行完啦 #没有被break打断,所以执行了该行代码
# -----out of while loop ------
# 如果执行过程中被break,就不会执行else的语句
count = 0
while count <= 5 :
count += 1
if count == 3:
break
print("Loop",count)
else:
print("循环正常执行完啦")
print("-----out of while loop ------")
# 输出
# Loop 1
# Loop 2
# -----out of while loop ------ #由于循环被break打断了,所以不执行else后的输出语句
4)循环嵌套
while 和 for 循环结构也支持嵌套。当 2 个(甚至多个)循环结构相互嵌套时,位于外层的循环结构常简称为外层循环或外循环,位于内层的循环结构常简称为内层循环或内循环。
循环嵌套结构的代码,Python 解释器执行的流程为:
- 当外层循环条件为 True 时,则执行外层循环结构中的循环体;
- 外层循环体中包含了普通程序和内循环,当内循环的循环条件为 True 时会执行此循环中的循环体,直到内循环条件为 False,跳出内循环;
- 若外层循环的条件仍为 True,则返回第 2 步继续执行外层循环体,直到外层循环的循环条件为 False;
- 当内层循环的循环条件为 False,且外层循环的循环条件也为 False,则整个嵌套循环才算执行完毕
嵌套循环执行的总次数 = 外循环执行次数 * 内循环执行次数
- if 语句和循环(while、for)结构之间,也可以相互嵌套
i = 0
if i<10:
for j in range(5):
print("i=",i," j=",j)
- if、while、for 之间支持多层( ≥3 )嵌套
if ...:
while ...:
for ...:
if ...:
...
4.语句关键字
1)pass
在实际开发中,有时会先搭建起程序的整体逻辑结构,但暂时不去实现某些细节。程序有时需要占一个位置或放一条语句,但又不希望这条语句做任何事情,此时可以通过 pass 语句来实现。pass 是 Python 中的关键字,用来让解释器跳过此处,什么都不做。
if name == 'Ralph Auldus Melish':
print('Welcome!')
elif name == 'Enid':
# 还未完成……
elif name == 'Bill Gates':
print('Access Denied')
# 这些代码不能运行,因为在Python中代码块不能为空。要修复这个问题,只需在中间的代码块中添加一条pass语句即可。
if name == 'Ralph Auldus Melish':
print('Welcome!')
elif name == 'Enid':
# 还未完成……
pass
elif name == 'Bill Gates':
print('Access Denied')
也可不使用注释和pass语句,而是插入一个字符串。这种做法尤其适用于未完成的函数和类,因为这种字符串将充当文档字符串
2)assert
assert 语句又称断言语句,用于判断某个表达式的值,若值为真,则程序继续向下执行;反之主动报错,执行可用 if 语句表示。assert 在错误条件出现时直接让程序崩溃。常用于检查用户的输入是否符合规定,还常用作程序初期测试和调试过程中的辅助工具
if 表达式==True:
程序继续执行
else:
程序报 AssertionError 错误
assert 的检查可以关闭,在命令行模式下运行 Python 程序时,加入 -O 选项可以使程序中的 assert 失效。一旦 assert 失效,其包含的语句也就不会被执行
3)break
在执行 while 循环或者 for 循环时,Python提供了 2 种强制离开当前循环体的办法
- 使用 continue 语句,可以跳过执行本次循环体中剩余的代码,转而执行下一次的循环
- 只用 break 语句,可以完全终止当前循环
break用法
- break 语句可立即终止当前循环的执行,跳出当前所在的循环结构。无论是 while 循环还是 for 循环,只要执行 break 语句,就会直接结束当前正在执行的循环体。
- break 语句的语法只需要在相应 while 或 for 语句中直接加入即可
- break 语句一般结合 if 语句进行搭配使用,表示在某种条件下跳出循环体
username = "jason"
password = "123"
# 记录错误验证的次数
count = 0
while count < 3:
inp_name = input("请输入用户名:")
inp_pwd = input("请输入密码:")
if inp_name == username and inp_pwd == password:
print("登陆成功")
break # 用于结束本层循环
else:
print("输入的用户名或密码错误!")
count += 1
循环嵌套+break
如果循环嵌套了很多层,要想退出每一层循环则需要在每一层循环都有一个break
username = "jason"
password = "123"
count = 0
while count < 3: # 第一层循环
inp_name = input("请输入用户名:")
inp_pwd = input("请输入密码:")
if inp_name == username and inp_pwd == password:
print("登陆成功")
while True: # 第二层循环
cmd = input('>>: ')
if cmd == 'quit':
break # 用于结束本层循环,即第二层循环
print('run <%s>' % cmd)
break # 用于结束本层循环,即第一层循环
else:
print("输入的用户名或密码错误!")
count += 1
针对嵌套多层的while循环,若很明确要在某一层直接退出所有层的循环,其实就让所有while循环的条件都用同一变量,该变量的初始值为True,一旦在某一层将该变量的值改成False,则所有层的循环都结束
username = "jason"
password = "123"
count = 0
tag = True
while tag:
inp_name = input("请输入用户名:")
inp_pwd = input("请输入密码:")
if inp_name == username and inp_pwd == password:
print("登陆成功")
while tag:
cmd = input('>>: ')
if cmd == 'quit':
tag = False # tag变为False, 所有while循环的条件都变为False
break
print('run <%s>' % cmd)
break # 用于结束本层循环,即第一层循环
else:
print("输入的用户名或密码错误!")
count += 1
4)continue
和 break 语句相比,continue 语句只会终止执行本次循环中剩下的代码,直接从下一次循环继续执行。continue 语句的用法和 break 语句一样,只要 while 或 for 语句中的相应位置加入即可
# 打印1到10之间,除7以外的所有数字
number=11
while number>1:
number -= 1
if number==7:
continue
# 结束掉本次循环,即本次循环continue之后的代码都不会运行了,而是直接进入下一次循环
print(number)
四、输出print
print() 函数可同时输出多个变量,print函数具有打印功能,打印时去掉了引号且输出值没有类型。
print (value, ..., sep='', end='\n', file=sys.stdout, flush=False)
1.value
value可接受任意多个变量或值,打印时默认以空格隔开多个变量。
user_name = 'Charlie'
user_age = 8
# 同时输出多个变量和字符串
print("读者名:", user_name, "年龄:", user_age)
# 读者名: Charlie 年龄: 8
2.sep
可通过 sep 参数进行设置以改变默认的分隔符。
# 同时输出多个变量和多个字符串,指定分隔符
user_name = "Charlie"
user_age = "8"
print("读者名:", user_name, "年龄:", user_age, sep='|')
# 读者名:|Charlie|年龄:|8
3.end=‘\n’
默认下print()输出完后换行,因为end参数默认值是"\n"。不换行则重设 end 参数即可
#设置end 参数,指定输出之后不再换行
print(40,'\t',end="")
print(50,'\t',end="")
print(60,'\t',end="")
# 40 50 60
4.file
file参数指定 print() 函数的输出目标,默认值为 sys.stdout,代表系统标准输出,既屏幕。可改变该参数让 print() 输出到特定文件中
f = open("demo.txt","w")#打开文件以便写入
print('沧海月明珠有泪',file=f)
print('蓝回日暖玉生烟',file=f)
f.close()
# open()函数用于打开demo.txt文件,接连2个print函数会将这2段字符串依次写入此文件,最后调close()函数关闭文件
5.flush=False
print() 函数的 flush 参数用于控制输出缓存,该参数一般保持为 False 即可,这样可以获得较好的性能
五、迭代器(Iterator)
- 迭代器是迭代取值的工具,迭代器基于索引迭代取值的局限性,能够不依赖于索引的取值方式
- 迭代是一个重复的过程,每次重复都基于上一次的结果而继续。单纯的重复不是迭代。
- 可多个值循环列举的类型有:列表,字符串,元祖,字典,集合,文件
l = [1,2,3]
i = 0
while i<len(l):
print(l[i])
i+=1
#上述索引迭代取值的方式只适用于有索引的数据类型:列表,字符串,元祖
1.迭代器对象
| 语法 | 说明 |
|---|---|
可迭代对象() | 可以转换成迭代器的对象,内置有__iter__方法的对象都是可迭代对象,字符串、列表、元组、字典、集合、打开的文件都是可迭代对象。 |
迭代器对象 | 迭代器对象(Iterator)是调用obj.iter()方法返回的结果,是内置有iter和next方法的对象,打开的文件是迭代器对象。 |
可迭代对象.__iter__() | 得到迭代器对象 |
迭代器对象.__next__() | 得到迭代器的下一个值 |
迭代器对象.__iter__() | 得到迭代器的本身 |
d = {'a': 1, 'b': 2}
d_iter = iter(d)
count = 0
while count < len(d):
print(next(d_iter))
count += 1
print('%' * 20)
# a
# b
# %%%%%%%%%%%%%%%%%%%%
d = {'a':1,'b':2}
d_iter = iter(d)
print(d_iter is iter(d_iter))
# True
迭代器优点
- 为序列和非序列类型提供了一种统一的迭代取值方式
- 惰性计算:节省内存。迭代器对象表示的是一个数据流,可以只在需要时去调用next来计算出一个值
- 就迭代器本身,同一时刻在内存中仅有一个值,因而可存放无限大的数据流
- 其他容器类型如列表,需把所有元素都存放于内存中,受内存大小的限制,可存放值的个数有限
迭代器缺点
- 除非取尽,否则无法获取迭代器的长度(只有在next完毕才知道到底有几个值)。
- 只能取下一个值,不能回到开始,一次性的只能往后走而不能往前退。
- 迭代器产生后唯一目标就是重复执行next方法直到值取尽,否则会停留在某位置等待下一次调用next
- 再次迭代同个对象,只能重新调用iter方法创建新迭代器对象,若有两个或者多个循环使用同一迭代器,只有一个循环能取到值
2.生成器(generator)
生成器就是自定义的迭代器
__next__ 不建议使用
next() 使用这种
def func():
print('第一次')
yield 1
print('第二次')
yield 2
g = func()
print(g)
# <generator object func at 0x00000233F90F4580>
# g 就是生成器,就是自定义的迭代器,会触发函数体代码的运行,然后遇到yield停下来,将yield后的值当做本次调用的结果返回
res = next(g)
print(res)
# 第一次
# 1
函数体内若存在yield关键字,调用函数不会执行函数体代码,而是返回生成器对象,即自定义的迭代器
# 应用案例
def my_range(start, stop, step=1):
while start < stop:
yield start
start += step
a = my_range(1, 7, 2)
print(next(a))
print(next(a))
print(next(a))
print(next(a))
# 1
# 3
# 5
# Traceback (most recent call last):
# File "C:\Users\14978\PycharmProjects\pythonProject\练习.py", line 9, in <module>
# print(next(a))
# StopIteration
for x in my_range(1, 7, 2):
print(x)
# 1
# 3
# 5
yield关键字是自定义迭代器的实现方式。不同于return,yield可用于返回值,但函数一旦遇到return就结束,而yield可以保存函数的运行状态挂起函数,用来返回多次值
def dog(name):
print('狗准备吃东西')
while True:
x = yield # x 拿到的是yield接收的值,yield可以接收到外部send传过来的数据并赋值给x
print('狗哥%s吃了%s' % (name, x))
yield # 针对表达式形式的yield,生成器对象必须事先被初始化一次,让函数挂起在food=yield的位置,等待调用g.send()方法为函数体传值,g.send(None)等同于next(g)
g = dog('旺旺')
g.send(None) # 等同于next(g)
g.send('一根骨头')
# 狗准备吃东西
# 狗哥旺旺吃了一根骨头
- 普通函数顺序执行,遇到return语句或者最后一行函数语句就返回
- generator函数在每次调用next()的时候执行,遇到yield语句暂停并返回数据到函数外,再次被next()调用时从上次返回的yield语句处继续执行
创建生成器对象有两种方式:
- 调用带yield关键字的函数
- 生成器表达式,与列表生成式的语法格式相同,只需要将[]换成()
(expression for item in iterable if condition)
# expression为新变量对旧变量的手段,item1为新变量,iterable1为旧变量,condition1为对新变量要求
对比列表生成式返回的是一个列表,生成器表达式返回的是一个生成器对象
# 对比列表生成式,生成器表达式的优点是节省内存(一次只产生一个值在内存中)
a=[x*x for x in range(3)]
print(a)
# a=[0, 1, 4]
g=(x*x for x in range(3))
print(g)
# <generator object <genexpr> at 0x101be0ba0>
next(g)
# 0
next(g)
# 1
next(g)
# 4
next(g) #抛出异常StopIteration
# 如果我们要读取一个大文件的字节数,应该基于生成器表达式的方式完成
with open('db.txt','rb') as f:
nums=(len(line) for line in f)
total_size=sum(nums) # 依次执行next(nums),然后累加到一起得到结果
3.for 高级用法
for循环原理是迭代器使用while循环的简化
- 迭代器使用while循环的实现方式如下
goods=['mac','lenovo','acer','dell','sony']
i=iter(goods) #每次都需要重新获取一个迭代器对象
while True:
try:
print(next(i))
except StopIteration: #捕捉异常终止循环
break
# mac
# lenovo
# acer
# dell
# sony
- for循环又称为迭代循环,in后可以跟任意可迭代对象,上述while循环可以简写为
goods=['mac','lenovo','acer','dell','sony']
for item in goods:
print(item)
- for 循环首先会调用可迭代对象goods内置的iter方法拿到一个迭代器对象,然后再调用该迭代器对象的next方法将取到的值赋给item,执行循环体完成一次循环,周而复始,直到捕捉StopIteration异常,结束迭代
# for循环可以称之为迭代循环
d = {'a':1,'b':2}
for k in d:
print(k)
# 1. d.__iter__()得到一个迭代器对象
# 2. 迭代器对象.__next__()拿到一个返回值,然后将该返回值赋值给k
# 3. 循环往复步骤2,直到抛出异常,for循环户捕捉异常然后结束循环
- for循环的本质就是调用next()
1)列表推导(生成)式
列表推导是一种从其他列表创建列表的方式,类似于数学中的集合推导。列表推导的工作原理非常简单,有点类似于for循环。
print([x * x for x in range(10)])
# [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
# 这个列表由range(10)内每个值的平方组成。只打印能被3整除的平方值,可使用求模运算符:
# 如果y能被3整除,y 3 % 将返回0(请注意,仅当x能被3整除时,x*x才能被3整除)。
# 可在列表推导中添加一条if语句。
print([x * x for x in range(10) if x % 3 == 0])
# [0, 9, 36, 81]
# 还可添加更多的for部分。
print([(x, y) for x in range(3) for y in range(3)])
# [(0, 0), (0, 1), (0, 2), (1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2)]
# 作为对比,下面的两个for循环创建同样地列表:
result = []
for x in range(3):
for y in range(3):
result.append((x, y))
print(result)
# [(0, 0), (0, 1), (0, 2), (1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2)]
使用多个for部分时,也可添加if子句。
# 这些代码将名字的首字母相同的男孩和女孩配对。
girls = ['alice', 'bernice', 'clarice']
boys = ['chris', 'arnold', 'bob']
print([b + '+' + g for b in boys for g in girls if b[0] == g[0]])
# ['chris+clarice', 'arnold+alice', 'bob+bernice']
# 前述男孩/女孩配对示例的效率不太高,因为它要检查每种可能的配对。
girls = ['alice', 'bernice', 'clarice']
boys = ['chris', 'arnold', 'bob']
letterGirls = {} # 创建一个名为letterGirls的字典
for girl in girls: # 字典键为girls中每个名字首字母,值为该名字
letterGirls.setdefault(girl[0], []).append(girl)
print([b + '+' + g for b in boys for g in letterGirls[b[0]]]) # 用boys中名字首字母作为键在letterGirls字典中查找,找的则返回键对应的值
# ['chris+clarice', 'arnold+alice', 'bob+bernice']
使用圆括号代替方括号并不能实现元组推导,而是将创建生成器,可使用花括号来执行字典推导。
# 在列表推导中for前面只有一个表达式,而在字典推导中,for前面有两个用冒号分隔的表达式。这两个表达式分别为键及其对应的值
squares = {i: "{} squared is {}".format(i, i ** 2) for i in range(10)}
print(squares[8])
# 8 squared is 64
列表生成式是一种简化代码的解决方案,用来快速生成列表
[expression for item1 in iterable1 if condition1]
或者:
[expression for item1 in iterable1]
# expression为新变量对旧变量的手段,item1为新变量,iterable1为旧变量,condition1为对新变量要求
l = ['muyi_nb', 'yimu_nb', 'lao_nb']
1.将所有小写字母转为大写
new_l = [x.upper() for x in l]
print(new_l)
# ['MUYI_NB', 'YIMU_NB', 'LAO_NB']
2.取出所有的_nb
new_l = [x.split('_')[0] for x in l]
print(new_l)
new_l = [x.replace('_nb', '') for x in l if x=='yimu_nb']
print(new_l)
# ['muyi', 'yimu', 'lao']
# ['yimu']
(1)列表生成式
# 列表推导式语法:
[ 表达式 for 变量 in range(起始位置, 结束位置, 步长) ]
# 根据需求快速生成一个列表
a = [i for i in range(4)]
print(a) #输出结果:[0, 1, 2, 3]
a = [x for x in range(3, 4)] #结果:a = 3
# 在循环的过程中使用if
a = [x for x in range(3, 10) if x % 2 == 0] #结果:a = [4,6,8]
# 普通方式创建列表
a = []
for i in range(100):
a.append(i)
print(a)
# 推导式创建列表
a = [value for value in range(100)]
print(a)
# 创建⼀个包含10个随机数的列表
import random
my_list = [random.randint(1, 10) for _ in range(10)]
print(my_list)
# 将上⾯列表中的元素, 加 10
new_list = [value + 10 for value in my_list]
print(new_list)
# 序列中所有的偶数组合成列表
my_list = [value for value in range(10) if value % 2 == 0]
print(my_list)
# 输出:
# [1, 2, 9, 5, 10, 3, 9, 7, 2, 6]
# [11, 12, 19, 15, 20, 13, 19, 17, 12, 16]
# [0, 2, 4, 6, 8]
(2)字典生成式
items = [('name','muyi'),('age',18),('sex','man')]
res = {k:v for k,v in items if k!='sex'}
print(res)
# {'name': 'muyi', 'age': 18}
(3)集合生成式
keys = ['name','age','sex']
set1 = {key for key in keys}
print(set1,type(set1))
# {'age', 'sex', 'name'} <class 'set'>
2)获取索引 enumerate()
在迭代对象序列的同时获取当前对象的索引
# 如替换一个字符串列表中所有包含子串'xxx'的字符串。假设:
for string in strings:
if 'xxx' in string:
index = strings.index(string) # 在字符串列表中查找字符串
strings[index] = '[censored]'
# 上面替换前的搜索没有必要。如果没有替换,搜索返回的索引(即返回的是该字符串首次出现处的索引)就为-1,下面的语句会报错。下面是一种更佳的解决方案:
index = 0
for string in strings:
if 'xxx' in string:
strings[index] = '[censored]'
index += 1
能够迭代索引-值对,其中的索引是自动提供的
# 无需设置index变量,直接获取索引和索引对应的值
for index, string in enumerate(strings):
if 'xxx' in string:
strings[index] = '[censored]'
3)常用迭代
(1)字典迭代
d = {'x': 1, 'y': 2, 'z': 3}
for key in d:
print(key, 'corresponds to', d[key])
# x corresponds to 1
# y corresponds to 2
# z corresponds to 3
# 也可使用keys等字典方法来获取所有的键。如果只对值感兴趣,可使用d.values。你可能还记得,d.items以元组的方式返回键值对。for循环的优点之一是,可在其中使用序列解包。
for key, value in d.items():
print(key, 'corresponds to', value)
# x corresponds to 1
# y corresponds to 2
# z corresponds to 3
# 字典元素的排列顺序是不确定的。换而言之,迭代字典的键或值时,一定会处理所有的键或值,但不知道处理的顺序。
(2)并行迭代 zip()
# 同时迭代两个序列:
names = ['anne', 'beth', 'george', 'damon']
ages = [12, 45, 32, 102]
# 打印名字和对应的年龄,i是用作循环索引的变量的标准名称。
for i in range(len(names)):
print(names[i], 'is', ages[i], 'years old')
# anne is 12 years old
# beth is 45 years old
# george is 32 years old
# damon is 102 years old
并行迭代工具是内置函数zip,它将两个序列“缝合”起来,并返回一个由元组组成的序列。返回值是一个适合迭代的对象,要查看其内容,可使用list将其转换为列表。
print(list(zip(names, ages)))
# [('anne', 12), ('beth', 45), ('george', 32), ('damon', 102)]
# “缝合”后,可在循环中将元组解包。
for name, age in zip(names, ages):
print(name, 'is', age, 'years old')
# anne is 12 years old
# beth is 45 years old
# george is 32 years old
# damon is 102 years old
record_sum.sort(reverse=True)
# 函数zip可用于“缝合”任意数量的序列。需要指出的是,当序列的长度不同时,函数zip将在最短的序列用完后停止“缝合”。
print(list(zip(range(5), range(100000000))))
# [(0, 0), (1, 1), (2, 2), (3, 3), (4, 4)]
(4)反向迭代
reversed和sorted类似于列表方法reverse和sort(sorted接受的参数也与sort类似),但可用于任何序列或可迭代的对象,且不就地修改对象,而是返回反转和排序后的版本
# sorted返回一个列表,而reversed像zip返回可迭代对象,不能对可迭代对象执行索引或切片操作,也不能直接对可迭代对象调用列表的方法。要执行这些操作,可先使用list对返回的对象进行转换。
print(list(reversed('Hello, world!')))
# ['!', 'd', 'l', 'r', 'o', 'w', ' ', ',', 'o', 'l', 'l', 'e', 'H']
print(''.join(reversed('Hello, world!')))
# !dlrow ,olleH
(5)排序迭代
要按字母表排序,可先转换为小写。为此,可将sort或sorted的key参数设置为str.lower。例如,sorted(“aBc”, key=str.lower)返回[‘a’, ‘B’, ‘c’]
print(sorted([4, 3, 6, 8, 3]))
# [3, 3, 4, 6, 8]
print(sorted('Hello, world!'))
# [' ', '!', ',', 'H', 'd', 'e', 'l', 'l', 'l', 'o', 'o', 'r', 'w']
4)常用迭代函数
函数map、reduce、filter都支持迭代器协议,用来处理可迭代对象
# 设可迭代对象array为例来介绍它们三个的用法
array=[1,2,3,4,5]
1)map()
map函数平方可迭代对象的每个元素
# map函数可以接收两个参数,一个是函数,另外一个是可迭代对象,具体用法如下
array=[1,2,3,4,5]
res=map(lambda x:x**2,array)
print(res)
print(list(res))
# <map object at 0x00000262D0FD5D80>
# [1, 4, 9, 16, 25]
解析:map会依次迭代array,得到的值依次传给匿名函数(也可以是有名函数),而map函数得到的结果仍然是迭代器
2)reduce()
reduce函数合并可迭代对象
注意:reduce在python3中被集成到模块functools中,需要导入才能使用
# reduce函数可以接收三个参数,一个是函数,第二个是可迭代对象,第三个是初始值
from functools import reduce
array=[1,2,3,4,5]
res=reduce(lambda x,y:x+y,array)
print(res)
# 15
# 解析:没有初始值时reduce函数会先迭代一次array得到值1作为初始值传给第一个值x,然后继续迭代一次array得到值2传给第二个值y,运算的结果为3,将上一次reduce运算的结果作为第一个值传给x,然后迭代一次array得到的结果3作为第二个值传给y,依次类推,迭代完array的所有元素得到最终结果15
# 也可以为reduce指定初始值
from functools import reduce
array=[1,2,3,4,5]
res = reduce(lambda x,y:x+y,array,100)
print(res)
# 115
3)filter()
filter函数过滤可迭代对象
array=[1,2,3,4,5]
res = filter(lambda x: x > 3, array)
print(list(res))
# [4, 5]
# 解析:filter函数会依次迭代array,得到的值依次传给匿名函数,如果匿名函数的返回值为真,则过滤出该元素,而filter函数得到的结果仍然是迭代器
提示:实际开发中,可以用列表生成式或生成器表达式来实现三者的功能
六、赋值魔法
1.序列解包
序列解包(或可迭代对象解包):将一个序列(或任何可迭代对象)解包,并将得到的值存储到一系列变量中。在使用返回元组(或其他序列或可迭代对象)的函数或方法时很有用。
# 可同时(并行)给多个变量赋值
x, y, z = 1, 2, 3
print(x, y, z)
# 1 2 3
# 还可交换多个变量的值
x, y = y, x
print(x, y, z)
# 2 1 3
values = 1, 2, 3
print(values)
# (1, 2, 3)
x, y, z = values
print(x)
# 1
使用方法popitem从字典中随机获取(或删除)一个键-值对以元组的方式返回,直接将返回的元组解包到两个变量中。这让函数能返回被打包成元组的多个值,通过一条赋值语句轻松访问这些值。要解包的序列包含的元素个数必须与等号左边列出的目标个数相同,否则Python将引发异常。
scoundrel = {'name': 'Robin', 'girlfriend': 'Marion'}
key, value = scoundrel.popitem()
print(key)
# girlfriend
print(value)
# Marion
可使用星号运算符(*)来收集多余的值,这样无需确保值和变量的个数相同
a, b, *rest = [1, 2, 3, 4]
print(rest)
# [3, 4]
# 还可将带星号的变量放在其他位置。
name = "Albus Percival Wulfric Brian Dumbledore"
first, *middle, last = name.split()
print(middle)
# ['Percival', 'Wulfric', 'Brian']
# 赋值语句的右边可以是任何类型的序列,但带星号的变量最终包含的总是一个列表。在变量和值的个数相同时亦如此。
a, *b, c = "abc"
print(a, b, c)
# 'a', ['b'], 'c'
# 这种收集方式也可用于函数参数列表中
2.链式赋值
链式赋值是一种快捷方式,用于将多个变量关联到同一个值。只涉及一个值
x = y = somefunction()
# 上述代码与下面的代码等价:
y = somefunction()
x = y
# 请注意,上面两条语句可能与下面的语句不等价:
x = somefunction()
y = somefunction()
3.增强赋值
可以不编写代码x = x + 1,而将右边表达式中的运算符(这里是+)移到赋值运算符(=)的前面,从而写成x += 1。这称为增强赋值,适用于所有标准运算符,如*、/、%等
x = 2
x += 1
x *= 2
print(x)
# 6
增强赋值也可用于其他数据类型(只要使用的双目运算符可用于这些数据类型)
fnord = 'foo'
fnord += 'bar'
fnord *= 2
print(fnord)
通过使用增强赋值,可让代码更紧凑、更简洁,同时在很多情况下的可读性更强




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











