







第三章 处理数据
为何需要cout.put()?
Unicode和ISO 10646之间有什么区别?它们如何协调一致?
为什么要将char类型与硬件属性匹配?这有什么好处?
为什么需要新增char16_t和char32_t类型?
为什么使用const限定符比使用#define语句更好?
什么是作用域规则?
什么是舍入误差?
如何查找系统支持的其他头文件?
C++中如何避免溢出和下溢?
C++引入的四个强制类型转换运算符分别是什么,它们有什么区别和用途?
什么情况下需要使用强制类型转换?
auto关键字和decltype关键字有什么区别和联系?
如何使用auto关键字来遍历容器或数组?
3.1 简单变量
程序通常都需要存储信息,为把信息存储在计算机中,程序必须记录3个基本属性:
- 信息将存储在哪里;
- 要存储什么值;
- 存储何种类型的信息。
采取的策略都是声明一个变量。声明中使用的类型描述了信息的类型和变量名。
int braincount;
braincount = 5;
这些语句告诉程序,它正在存储整数,并使用名称braincount来表示该整数的值(这里为5)。实际上,程序将找到一块能够存储整数的内存,将该内存单元标记为braincount,并将5复制到该内存单元中;然后,您可在程序中使用braincount来访问该内存单元。
3.1.1 变量名
C++提倡使用有一定含义的变量名。但必须遵循几种简单的C++命名规则。
- 在名称中只能使用字母字符、数字和下划线(_)。
- 名称的第一个字符不能是数字。
- 区分大写字符与小写字符。
- 不能将C++关键字用作名称。
- 以两个下划线打头或以下划线和大写字母打头的名称被保留给实现(编译器及其使用的资源)使用。以一个下划线开头的名称被保留给实现,用作全局标识符。
- C++对于名称的长度没有限制,名称中所有的字符都有意义,但有些平台有长度限制。
倒数第二点与前面几点有些不同,因为使用像_time_stop或_Donut这样的名称不会导致编译器错误,而会导致行为的不确定性,换句话说,不知道结果将是什么。
如果想用两个或更多的单词组成一个名称,通常的做法是用下划线字符将单词分开,如my_onions;或者从第二个单词开始将每个单词的第一个字母大写,如myEyeTooth。
在C++所有主观的风格中,一致性和精度是最重要的。请根据自己的需要、喜好和个人风格来使用变量名
3.1.2 整型
整数就是没有小数部分的数字,如2、98、−5286和0。整数有很多,如果将无限大的整数看作很大,则不可能用有限的计算机内存来表示所有的整数。因此,语言只能表示所有整数的一个子集。
不同C++整型使用不同的内存量来存储整数。使用的内存量越大,可以表示的整数值范围也越大。
另外,有的类型(符号类型)可表示正值和负值,而有的类型(无符号类型)不能表示负值。术语宽度(width)用于描述存储整数时使用的内存量。使用的内存越多,则越宽。
3.1.3 整型 short、 int、 long 和long long
计算机内存由一些叫作位(bit)的单元组成。
C++提供了一种灵活的标准,它确保了最小长度(从C语言借鉴而来),如下所示:
- short至少16位;
- int至少与short一样长;
- long至少32位,且至少与int一样长;
- long long至少64位,且至少与long一样长。
位与字节
计算机内存的基本单元是位(bit)。可以将位看作电子开关,可以开,也可以关。关表示值0,开表示值1。
8位的内存块可以设置出256种不同的组合,因为每一位都可以有两种设置,所以8位的总组合数为2×2×2×2×2×2×2×2,即256。因此,8位单元可以表示0~255或者−128~127。每增加一位,组合数便加倍。这意味着可以把16位单元设置成65 536个不同的值,把32位单元设置成4 294 967 296个不同的值,把64位单元设置为18 446 744 073 709 551 616个不同的值。相较之下,unsigned long存储不了地球上当前的人数和银河系的星星数,而long long则可以。
字节(byte)通常指的是8位的内存单元。
字节指的就是描述计算机内存量的度量单位,1KB等于1024字节,1MB等于1024KB。然而,C++对字节的定义与此不同。C++字节由至少能够容纳实现的基本字符集的相邻位组成,也就是说,可能取值的数目必须等于或超过字符数目。
可以像使用int一样,使用这些类型名来声明变量:
short score;
int temperature;
long position;
实际上,short是short int的简称,而long是long int的简称。
运算符sizeof和头文件limits
sizeof运算符指出,在使用8位字节的系统中,int的长度为4个字节。可对类型名或变量名使用sizeof运算符。对类型名(如int)使用sizeof运算符时,应将名称放在括号中;但对变量名(如n_short)使用该运算符,括号是可选的:
cout << "int is " << sizeof (int) << " bytes.\n";
cout << "short is " << sizeof n_short << " bytes.\n";
头文件climits定义了符号常量(参见本章后面的旁注“符号常量——预处理器方式”)来表示类型的限制。如前所述,INT_MAX表示类型int能够存储的最大值
| 符号常量 | 表示 |
|---|---|
| CHAR_BIT | char的位数 |
| CHAR_MAX | char的最大值 |
| CHAR_MIN | char的最小值 |
| SCHAR_MAX | signed char的最大值 |
| SCHAR_MIN | signed char的最小值 |
| UCHAR_MAX | unsigned char的最大值 |
| SHRT_MAX | short的最大值 |
| SHRT_MIN | short的最小值 |
| USHRT_MAX | unsigned short的最大值 |
| INT_MAX | int的最大值 |
| INT_MIN | int的最小值 |
| UINT_MAX | unsigned int的最大值 |
| LONG_MAX | long的最大值 |
| LONG_MIN | long的最小值 |
| ULONG_MAX | unsigned long的最大值 |
| LLONG_MAX | long long的最大值 |
| LLONG_MIN | long long的最小值 |
| ULLONG_MAX | unsigned long long的最大值 |
符号常量——预处理器方式
climits文件中包含与下面类似的语句行:
#define INT_MAX 32767
在C++编译过程中,首先将源代码传递给预处理器。在这里,#define和#include一样,也是一个预处理器编译指令。该编译指令告诉预处理器:在程序中查找INT_MAX,并将所有的INT_MAX都替换为32767。然而,#define编译指令是C语言遗留下来的。C++有一种更好的创建符号常量的方法(使用关键字const,将在后面的一节讨论),所以不会经常使用#define。然而,有些头文件,尤其是那些被设计成可用于C和C++中的头文件,必须使用#define。
初始化
初始化将赋值与声明合并在一起。
int n_int = INT_MAX;
警告:
如果不对函数内部定义的变量进行初始化,该变量的值将是不确定的。这意味着该变量的值将是它被创建之前,相应内存单元保存的值。
C++11初始化方式
还有另一种初始化方式,这种方式用于数组和结构,但在C++98中,也可用于单值变量:
int hamburgers = {24};
将大括号初始化器用于单值变量的情形还不多,采用这种方式时,可以使用等号(=),也可以不使用:
int emus{7}; // set emus to 7
int rheas = {12}; // set rheas to 12
其次,大括号内可以不包含任何东西
int rocs = {}; // set rocs to 0
int psychics{}; // set psychics to 0
3.1.4 无符号类型
前面介绍的4种整型都有一种不能存储负数值的无符号变体,其优点是可以增大变量能够存储的最大值。例如,如果short表示的范围为−32768到+32767,则无符号版本的表示范围为0-65535。
要创建无符号版本的基本整型,只需使用关键字unsigned来修改声明即可:
unsigned short change; // unsigned short type
unsigned int rovert; // unsigned int type
unsigned quarterback; // also unsigned int
unsigned long gone; // unsigned long type
unsigned long long lang_lang; // unsigned long long type
注意,unsigned本身是unsigned int的缩写。
如果超越了限制,其值将为范围另一端的取值。C++确保了无符号类型的这种行为;但C++并不保证符号整型超越限制(上溢和下溢)时不出错,而这正是当前实现中最为常见的行为。

3.1.5 选择整型类型
C++提供了大量的整型,应使用哪种类型呢?通常,int被设置为对目标计算机而言最为“自然”的长度。自然长度(natural size)指的是计算机处理起来效率最高的长度。
如果知道变量可能表示的整数值大于16位整数的最大可能值,则使用long。即使系统上int为32位,也应这样做。这样,将程序移植到16位系统时,就不会突然无法正常工作(参见下图)。如果要存储的值超过20亿,可使用long long。

由于short比int小,使用short可以节省内存。通常,仅当有大型整型数组时,才有必要使用short。
3.1.6 整型字面值
整型字面值(常量)是显式地书写的常量,如212或1776。与C相同,C++能够以三种不同的计数方式来书写整数:基数为10、基数为8(老式UNIX版本)和基数为16(硬件黑客的最爱)
3.1.7 C++如何确定常量的类型
程序的声明将特定的整型变量的类型告诉了C++编译器,但编译器是如何知道常量的类型呢?
cout << "Year = " << 1492 << "\n";
程序将把1492存储为int、long还是其他整型呢?答案是,除非有理由存储为其他类型(如使用了特殊的后缀来表示特定的类型,或者值太大,不能存储为int),否则C++将整型常量存储为int类型。
首先来看看后缀。后缀是放在数字常量后面的字母,用于表示类型。整数后面的l或L后缀表示该整数为long常量,u或U后缀表示unsigned int常量,ul(可以采用任何一种顺序,大写小写均可)表示unsigned long常量(由于小写l看上去像数字1,因此应使用大写L作后缀)
接下来考察长度。对于不带后缀的十进制整数,将使用下面几种类型中能够存储该数的最小类型来表示:int、long或long long。对于不带后缀的十六进制或八进制整数,将使用下面几种类型中能够存储该数的最小类型来表示:int、unsigned int、long、unsigned long、long long或unsigned long long。
在将40000表示为long的计算机系统中,十六进制数0x9C40(40000)将被表示为unsigned int。这是因为十六进制常用来表示内存地址,而内存地址是没有符号的,因此,unsigned int比long更适合用来表示16位的地址。
3.1.8 char类型:字符和小整数
下面介绍最后一种整型:char类型。顾名思义,char类型是专为存储字符(如字母和数字)而设计的。很多系统支持的字符都不超过128个,因此用一个字节就可以表示所有的符号。因此,虽然char最常被用来处理字符,但也可以将它用做比short更小的整型。
最常用的符号集是ASCII字符集
Enter a character:
M
Hola! Thank you for the M character.
77是存储在变量中的值。这种神奇的力量不是来自char类型,而是来自cin和cout,这些工具为您完成了转换工作。输入时,cin将键盘输入的M转换为77;输出时,cout将值77转换为所显示的字符M;cin和cout的行为都是由变量类型引导的。
成员函数cout.put()
cout.put()成员函数提供了另一种显示字符的方法,可以替代**<<运算符**。现在读者可能会问,为何需要cout.put()。
我们继续往下走。
char字面值
在C++中,书写字符常量的方式有多种。对于常规字符(如字母、标点符号和数字),最简单的方法是将字符用单引号括起。这种表示法代表的是字符的数值编码。
- 'A’为65,即字符A的ASCII码;
- 'a’为97,即字符a的ASCII码;
- '5’为53,即数字5的ASCII码;
- ’ '为32,即空格字符的ASCII码;
- '!'为33,即惊叹号的ASCII码。
有些字符不能直接通过键盘输入到程序中。C++提供了一种特殊的表示方法——转义序列,例如,转义序列\n表示换行符,\”将双引号作为常规字符,而不是字符串分隔符。
| 字符 名称 | ASCII符号 | C++代码 | 十进制ASCII码 | 十六进制ASCII码 |
|---|---|---|---|---|
| 换行符 | NL (LF) | \n | 10 | 0xA |
| 水平制表符 | HT | \t | 9 | 0x9 |
| 垂直制表符 | VT | \v | 11 | 0xB |
| 退格 | BS | \b | 8 | 0x8 |
| 回车 | CR | \r | 13 | 0xD |
| 振铃 | BEL | \a | 7 | 0x7 |
| 反斜杠 | \ | \ | 92 | 0x5C |
| 问号 | ? | ? | 63 | 0x3F |
| 单引号 | ’ | ’ | 39 | 0x27 |
| 双引号 | " | " | 34 | 0x22 |
- 字符常量是用单引号括起的单个字符,它们代表了字符的数值编码,通常是ASCII码或EBCDIC码。
- 转义序列是一种特殊的表示方法,用于表示无法直接从键盘输入或具有特殊含义的字符。转义序列以反斜杠开头,后跟一个或多个字符,如\n表示换行符,\”表示双引号。
- 转义序列可以用在字符串或字符常量中,它们的作用与常规字符相同。例如,cout << "\n"和cout << endl都可以换行。
- 除了符号转义序列外,还可以使用基于字符的八进制和十六进制编码来表示转义序列。例如,\032和\0x1a都表示Ctrl+Z字符。
通用字符名
- C++支持一个基本的源字符集(可用来编写源代码的字符集)和一个基本的执行字符集,它们由标准美国键盘上的字符和一些其他字符组成。
- C++还允许实现提供扩展源字符集和扩展执行字符集,它们可以包含其他语言中的字符,如德语、法语等。
- C++有一种表示这些特殊字符的机制,它独立于任何特定的键盘,使用的是通用字符名(universal character name),它们以\u或\U打头,后面跟着十六进制位,表示字符的ISO 10646码点。
- ISO 10646是一种国际标准,为大量的字符提供了数值编码,它与Unicode保持同步,Unicode是一种表示各种字符集的解决方案,为每个字符指定一个编号——码点。那么,Unicode和ISO 10646之间有什么区别?它们如何协调一致?
我们继续往下走。
signed char和unsigned char
- char类型在默认情况下既不是有符号的,也不是无符号的,它由C++实现决定,这样可以与硬件属性匹配。但是,为什么要将char类型与硬件属性匹配?这有什么好处?
我们继续往下走。
- 如果要使用char类型作为数值类型,则可以显式地将其设置为signed char(-128~127)或unsigned char(0~255),以确保其表示范围符合预期。
char fodo;
unsigned char bar;
signed char snark;
- 如果要使用char类型来存储标准ASCII字符,则无论其是否有符号都没有影响,可以直接使用char。
wchar_t
这是一种用于表示扩展字符集的整数类型。可以处理一些无法用8位char表示的字符,如日文汉字。
- wchar_t类型的长度和符号属性取决于实现,它可以表示系统使用的最大扩展字符集。
- wchar_t类型可以用来处理日文汉字等无法用一个8位字节表示的字符集。
- wchar_t类型可以通过加上前缀L来指示宽字符常量和宽字符串。
- wchar_t类型可以使用wcin和wcout来进行输入和输出,而不是cin和cout。
- wchar_t类型在进行国际编程或使用Unicode或ISO 10646时很有用。
C++11新增的类型:char16_t和char32_t
- C++11新增了类型char16_t和char32_t,用于表示Unicode字符和字符串。
- char16_t是无符号的,长16位,而char32_t也是无符号的,但长32位。
- C++11使用前缀u表示char16_t字符常量和字符串常量,如u‘C’和u“be good”;并使用前缀U表示char32_t常量,如U‘R’和U“dirty rat”。
- char16_t和char32_t的底层类型是一种内置的整型,但可能随系统而异。
- char16_t与\u00F6形式的通用字符名匹配,而char32_t与\U0000222B形式的通用字符名匹配。
为什么需要新增char16_t和char32_t类型?
我们继续往下走。
3.1.9 bool类型
bool类型是C++中用来表示布尔值(真或假)的数据类型,它使用关键字bool来声明,只能取值true或false。bool类型的值可以用于条件测试,也可以与其他类型进行转换。下面是一些关于bool类型的重要点和问题:
- bool类型的字面值true和false是C++的关键字,它们分别对应数值1和0。
- bool类型的变量可以用于数学表达式中,例如int x = false + true + 6;,这个表达式的值是7,因为false等于0,true等于1。
- bool类型的变量也可以用于逻辑运算符(&&, ||, !)和关系运算符(<, >, ==, !=等)中,例如bool b1 = x1 == x2;,这个表达式的值取决于x1和x2是否相等。
- 任何非零的数值或指针值都可以隐式转换为bool类型的值,转换后的值为true,而零转换后的值为false。
- bool类型的变量可以用于控制流语句(如if, while, for等)中,例如if (b3) cout << “Yes” << “\n”;,这个语句会在b3为true时输出"Yes",否则不输出。
3.2 const限定符
符号名称指出了常量表示的内容。另外,如果程序在多个地方使用同一个常量,则需要修改该常量时,只需修改一个符号定义即可。
- const限定符可以指定变量的类型,限制变量的作用域,以及用于更复杂的类型,如数组和结构。
- const限定符比#define语句更好,因为它能够提供更多的信息和控制。为什么使用const限定符比使用#define语句更好?
我们继续往下走。
- const限定符在C++和ANSI C中有一些区别,如作用域规则和数组长度声明。什么是作用域规则?
我们继续往下走。
3.3 浮点数
- 浮点类型:C++的第二组基本类型,可以表示带小数部分的数字,如2.5、3.14159和122442.32,它们的值范围也更大。
- 浮点数的内部表示:浮点数被分成两部分存储,一部分表示基准值,另一部分表示缩放因子。缩放因子的作用是移动小数点的位置,使得浮点数可以表示非常大或非常小的值。C++内部使用二进制数来表示浮点数,但程序员不必详细了解。
- 浮点类型的种类:C++有三种浮点类型:float、double和long double。它们的精度和大小各不相同,具体取决于编译器和计算机硬件。
3.3.1 书写浮点数
-
浮点数的书写方式:C++有两种书写浮点数的方式,一种是标准小数点表示法,如12.34和8.0,另一种是E表示法,如3.45E6和8.33E-4,它们可以表示非常大或非常小的数。
-
E表示法的含义:E表示法是指用一个基数和一个指数来表示一个浮点数,如d.dddE+n,其中d.ddd是基数,n是指数。指数为正时,表示将小数点向右移n位;指数为负时,表示将小数点向左移n位。E表示法可以用大写或小写的E,也可以用正负号来修饰指数。
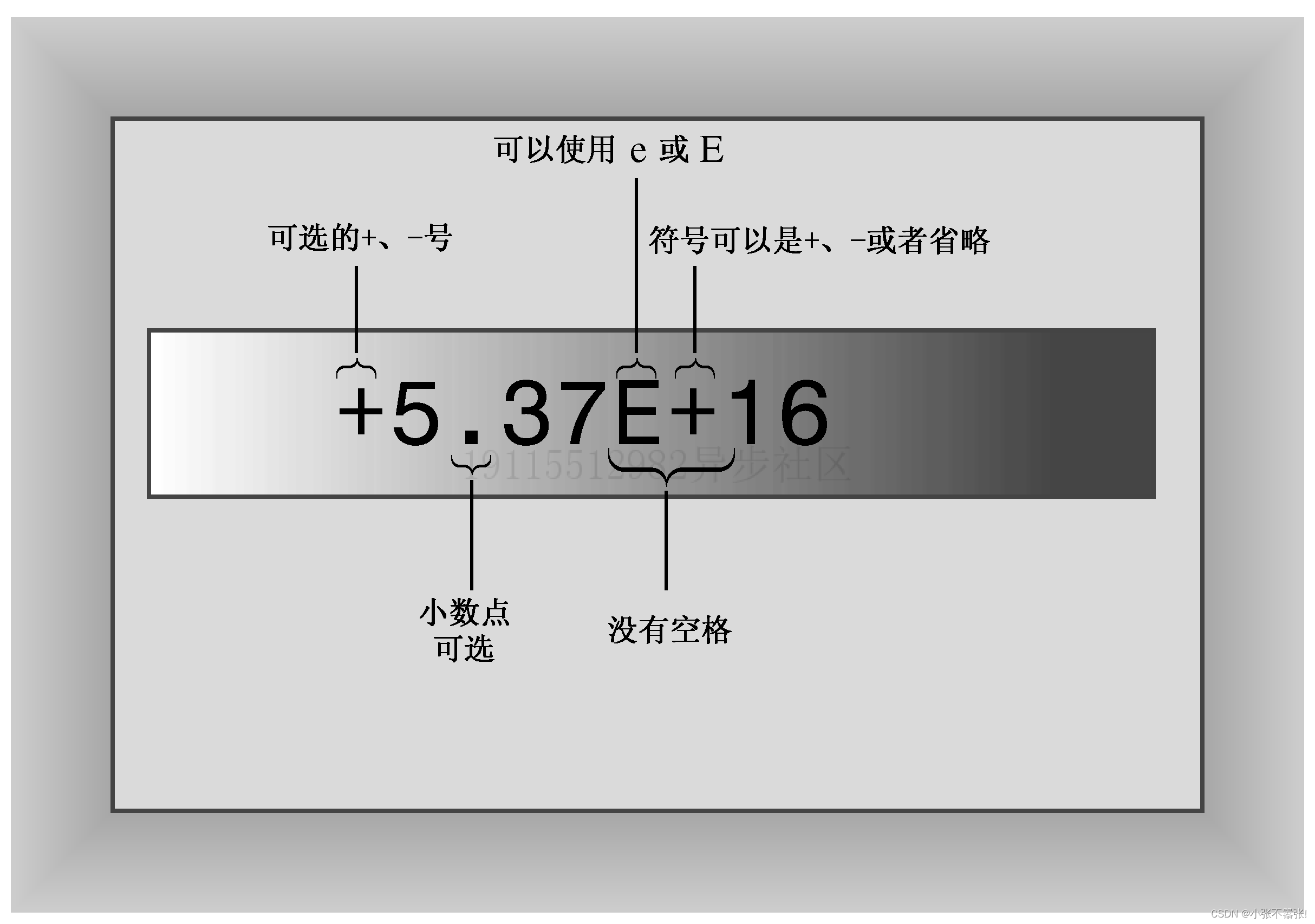
-
浮点数的注意事项:浮点数必须有小数点或E来区分整数,否则会被当作整型处理。浮点数中不能有空格,否则会被当作语法错误。浮点数在内部是用二进制来存储的,所以有些十进制小数无法精确地转换为二进制小数,会产生舍入误差。什么是舍入误差?
我们继续往下走。
记住:
d.dddE+n指的是将小数点向右移n位,而d.dddE-n指的是将小数点向左移n位。之所以称为“浮点”,就是因为小数点可移动。
3.3.2 浮点类型
- C++有3种浮点类型:float、double和long double,它们的有效位数和指数范围有所不同,取决于系统的实现。
- float至少32位,double至少48位,long double至少和double一样多。这些类型的有效位数可以从头文件cfloat或float.h中找到。
- 程序展示了float和double类型在表示数字时的精度差异。
// floatnum.cpp -- floating-point types
#include <iostream>
int main()
{
using namespace std;
cout.setf(ios_base::fixed, ios_base::floatfield); // fixed-point
float tub = 10.0 / 3.0; // good to about 6 places
double mint = 10.0 / 3.0; // good to about 15 places
const float million = 1.0e6;
cout << "tub = " << tub;
cout << ", a million tubs = " << million * tub;
cout << ",\nand ten million tubs = ";
cout << 10 * million * tub << endl;
cout << "mint = " << mint << " and a million mints = ";
cout << million * mint << endl;
return 0;
}
输出
tub = 3.333333, a million tubs = 3333333.250000,
and ten million tubs = 33333332.000000
mint = 3.333333 and a million mints = 3333333.333333
- 包含文件是文本文件,可以随意打开、阅读它们。它们包含了程序需要使用的功能和信息。阅读源文件和头文件是了解C++知识的好方法。如何查找系统支持的其他头文件?
我们继续往下走。
3.3.3 浮点常量
- 浮点常量是指在程序中直接书写的浮点数,例如3.14或1.23e-4。
- 浮点常量有三种类型:float、double和long double,它们的精度和范围有所不同。
- 默认情况下,浮点常量都属于double类型,除非使用f或F后缀表示float类型,或使用l或L后缀表示long double类型。
- 使用不同的后缀可以影响浮点常量的存储方式和计算结果。
示例如下:
1.234f
2.45E20F
2.345324E28
2.2L
3.3.4 浮点数的优缺点
- 浮点数可以表示整数之间的值和非常大或非常小的值,但浮点运算的速度通常比整数运算慢,且精度会降低。
- 程序清单展示了一个例子,说明了float类型在表示很大的数时会失去精度,导致计算结果不正确。
// fltadd.cpp -- precision problems with float
#include <iostream>
int main()
{
using namespace std;
float a = 2.34E+22f;
float b = a + 1.0f;
cout << "a = " << a << endl;
cout << "b - a = " << b - a << endl;
return 0;
}
输出
a = 2.34e+022
b - a = 0
- C++将基本类型分为几个族,类型signed char、short、int和long统称为符号整型;它们的无符号版本统称为无符号整型;C++11新增了long long。bool、char、wchar_t、符号整型和无符号整型统称为整型;C++11新增了char16_t和char32_t。float、double和long double统称为浮点型。整数和浮点型统称算术(arithmetic)类型。
3.4 C++算术运算符
- C++提供了5种基本的算术运算符:+、-、*、/和%。它们分别用于执行加法、减法、乘法、除法和求模运算。
- 算术运算符的操作数可以是变量或常量,也可以是表达式。表达式的值由运算符和操作数决定。
- 程序清单展示了如何使用算术运算符来计算浮点数。
// arith.cpp -- some C++ arithmetic
#include <iostream>
int main()
{
using namespace std;
float hats, heads;
cout.setf(ios_base::fixed, ios_base::floatfield); // fixed-point
cout << "Enter a number: ";
cin >> hats;
cout << "Enter another number: ";
cin >> heads;
cout << "hats = " << hats << "; heads = " << heads << endl;
cout << "hats + heads = " << hats + heads << endl;
cout << "hats - heads = " << hats - heads << endl;
cout << "hats * heads = " << hats * heads << endl;
cout << "hats / heads = " << hats / heads << endl;
return 0;
}
输出
Enter a number: 50.25
Enter another number: 11.17
hats = 50.250000; heads = 11.170000
hats + heads = 61.419998
hats - heads = 39.080002
hats * heads = 561.292480
hats / heads = 4.498657
也许读者对得到的结果心存怀疑。11.17加上50.25应等于61.42,但是输出中却是61.419998。记住,对于float,C++只保证6位有效位。如果将61.419998四舍五入成6位,将得到61.4200,这是保证精度下的正确值。如果需要更高的精度,请使用double或long double。
3.4.1 运算符优先级和结合性
- C++中的运算符有不同的优先级,高优先级的运算符先计算,低优先级的运算符后计算。先乘除,后加减。可以使用括号来改变计算顺序。
- C++中的运算符也有不同的结合性,当两个优先级相同的运算符被同时用于同一个操作数时,结合性决定了先计算左侧的运算符还是右侧的运算符。一般来说,算术运算符都是从左到右结合的。但
int dues = 20 * 5 + 24 * 6;两个*运算符并没有用于同一个操作数,所以该规则不适用。事实上,C++把这个问题留给了实现,让它来决定在系统中的最佳顺序。
C++中如何避免溢出和下溢?
我们继续往下走。
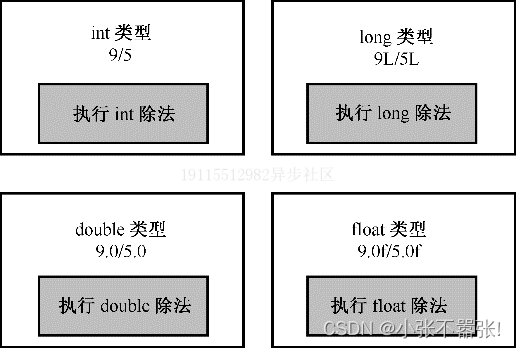
3.4.2 除法分支
- 除法运算符(/)的行为取决于操作数的类型,如果两个操作数都是整数,则执行整数除法,结果的小数部分被丢弃;如果一个或两个操作数是浮点数,则执行浮点除法,结果的小数部分被保留。
- 程序清单展示了如何使用cout.setf()方法来控制输出的格式,以及如何使用除法运算符来计算不同类型的值。程序的输出显示了整数除法和浮点除法的不同结果,以及float和double类型的不同精度。
// divide.cpp -- integer and floating-point division
#include <iostream>
int main()
{
using namespace std;
cout.setf(ios_base::fixed, ios_base::floatfield);
cout << "Integer division: 9/5 = " << 9 / 5 << endl;
cout << "Floating-point division: 9.0/5.0 = ";
cout << 9.0 / 5.0 << endl;
cout << "Mixed division: 9.0/5 = " << 9.0 / 5 << endl;
cout << "double constants: 1e7/9.0 = ";
cout << 1.e7 / 9.0 << endl;
cout << "float constants: 1e7f/9.0f = ";
cout << 1.e7f / 9.0f << endl;
return 0;
}
输出
Integer division: 9/5 = 1
Floating-point division: 9.0/5.0 = 1.800000
Mixed division: 9.0/5 = 1.800000
double constants: 1e7/9.0 = 1111111.111111
float constants: 1e7f/9.0f = 1111111.125000
- 运算符重载是一种使用相同的符号进行多种操作的方法,C++根据上下文(操作数的类型)来确定运算符的含义。C++有一些内置的重载示例,例如除法运算符。C++还允许扩展运算符重载,以便能够用于用户定义的类,这是一个重要的面向对象编程(OOP)属性。如图:
3.4.3 求模运算符
- 求模运算符:求模运算符是一种返回整数除法余数的运算符,它用%表示,例如181 % 14的值是13。
- 整数除法:整数除法是一种只保留商的整数部分的除法,它用/表示,例如181 / 14的值是12。
3.4.4 类型转换
类型转换是一种在不同的数据类型之间进行转换的方法,它可以让你的程序更灵活和高效。C++自动执行很多类型转换:
- 将一种算术类型的值赋给另一种算术类型的变量时,C++将对值进行转换;
- 表达式中包含不同的类型时,C++将对值进行转换;
- 将参数传递给函数时,C++将对值进行转换。
初始化和赋值进行的转换
- C++允许将一种类型的值赋给另一种类型的变量,但这样做可能会导致值的转换或截取。
- 将一个值赋给值取值范围更大的类型通常不会导致什么问题,但将一个值赋给值取值范围更小的类型可能会导致精度降低或值超出目标类型的取值范围。
| 转换 | 潜在的问题 |
|---|---|
| 将较大的浮点类型转换为较小的浮点类型,如将double转换为float | 精度(有效数位)降低,值可能超出目标类型的取值范围,在这种情况下,结果将是不确定的 |
| 将浮点类型转换为整型 | 小数部分丢失,原来的值可能超出目标类型的取值范围,在这种情况下,结果将是不确定的 |
| 将较大的整型转换为较小的整型,如将long转换为short | 原来的值可能超出目标类型的取值范围,通常只复制右边的字节 |
- C++对于一些转换的结果没有定义,这意味着不同的实现的反应可能不同。
- 传统初始化的行为与赋值相同,都会进行相应的转换。
以{ }方式初始化时进行的转换(C++11)
- 列表初始化是一种使用大括号来初始化变量的方法,它对类型转换的要求更严格,不允许缩窄转换。
- 缩窄转换是指变量的类型可能无法表示赋给它的值,例如将浮点型转换为整型,或将较大的整型转换为较小的整型。
- 列表初始化可以提高代码的安全性和可读性,因为它可以避免一些隐式的数据丢失或未定义的行为,如果发生缩窄转换,编译器将报错。
例如:
const int code = 66;
int x = 66;
char c1 {31325}; // narrowing, not allowed
char c2 = {66}; // allowed because char can hold 66
char c3 {code}; // ditto
char c4 = {x}; // not allowed, x is not constant
x = 31325;
char c5 = x; // allowed by this form of initialization
表达式中的转换
- C++在计算表达式时,会对不同的算术类型进行自动转换,以保证运算的一致性和正确性。
- C++会对bool、char、short等类型进行整型提升,将它们转换为int或更大的类型,以提高运算的效率。
- C++会根据一个校验表来确定两种不同类型的操作数之间的转换规则,通常是将较小的类型转换为较大的类型,以避免数据丢失。
- C++对于一些转换的结果没有定义,这意味着不同的实现的反应可能不同,因此应该避免这些转换
下面是C++11版本的校验表,编译器将依次查阅该列表。
(1)如果有一个操作数的类型是long double,则将另一个操作数转换为long double。
(2)否则,如果有一个操作数的类型是double,则将另一个操作数转换为double。
(3)否则,如果有一个操作数的类型是float,则将另一个操作数转换为float。
(4)否则,说明操作数都是整型,因此执行整型提升。
(5)在这种情况下,如果两个操作数都是有符号或无符号的,且其中一个操作数的级别比另一个低,则转换为级别高的类型。
(6)如果一个操作数为有符号的,另一个操作数为无符号的,且无符号操作数的级别比有符号操作数高,则将有符号操作数转换为无符号操作数所属的类型。
(7)否则,如果有符号类型可表示无符号类型的所有可能取值,则将无符号操作数转换为有符号操作数所属的类型。
(8)否则,将两个操作数都转换为有符号类型的无符号版本。
传递参数时的转换
- C++函数原型可以控制传递参数时的类型转换,以保证参数的类型与函数期望的类型一致。
- 如果取消函数原型对参数传递的控制,C++会对一些类型进行整型提升或浮点提升,以兼容传统C语言的代码,但这样做可能会导致数据丢失或未定义的行为。
- 整型提升是指将bool、char、short等类型转换为int或更大的类型,浮点提升是指将float类型转换为double类型。
强制类型转换
- C++允许通过强制类型转换机制显式地进行类型转换,以推翻一些类型规则或满足不同的期望。
- 强制类型转换的格式有两种,一种是使用类型名和圆括号,例如(long) thorn或long(thorn),
通用格式:
(typeName) value
typeName (value)
示例:
(long) thorn
long (thorn)
另一种是使用C++引入的强制类型转换运算符,例如static_cast (thorn)。
通用格式:
static_cast (value)
示例:
static_cast<long> (thorn)
C++引入的四个强制类型转换运算符分别是什么,它们有什么区别和用途?
我们继续往下走。
- 强制类型转换不会修改原来的值,而是创建一个新的、指定类型的值,可以在表达式中使用这个值。
- 强制类型转换可能会导致数据丢失或未定义的行为,因此应该谨慎使用。那么,什么情况下需要使用强制类型转换?
我们继续往下走。
3.4.5 C++11中的 auto 声明
- C++11新增了auto关键字,可以让编译器根据初始值的类型推断变量的类型,无需显式地指定变量的类型。
auto n = 100; // n is int
auto x = 1.5; // x is double
auto y = 1.3e12L; // y is long double
- auto关键字可以简化一些复杂类型的声明,如标准模板库(STL)中的类型,提高代码的可读性和可维护性。
例如,对于下述C++98代码:
std::vector<double> scores;
std::vector<double>::iterator pv = scores.begin();
C++11允许您将其重写为下面这样:
std::vector<double> scores;
auto pv = scores.begin();
- auto关键字也有一些限制和注意事项,例如不能用于函数参数和返回值,不能用于没有初始值的变量,不能用于列表初始化等。
我们继续往下走。
如何使用auto关键字来遍历容器或数组?我们继续往下走。
小思考🤔️
为何需要cout.put()?
答:
答案与历史有关。在C++的Release 2.0之前,cout将字符变量显示为字符,而将字符常量(如‘M’和‘N’)显示为数字。问题是,C++的早期版本与C一样,也把字符常量存储为int类型。也就是说,‘M’的编码77将被存储在一个16位或32位的单元中。而char变量一般占8位。
Unicode和ISO 10646之间有什么区别?它们如何协调一致?
答:
Unicode和ISO 10646之间的区别是Unicode不仅提供了数值编码,还提供了一些其他信息和规范,如字符属性、排序规则、正规化形式等。它们如何协调一致是通过一个联合技术委员会(UTC),它由两个组织共同管理:Unicode联盟(The Unicode Consortium)和ISO/IEC JTC1/SC2/WG2(ISO/IEC Joint Technical Committee 1, Subcommittee 2, Working Group 2)。这个委员会负责确保两个标准在码点分配和名称上保持同步,并处理任何潜在的冲突和问题。
为什么要将char类型与硬件属性匹配?这有什么好处?
答:
将char类型与硬件属性匹配的目的是为了提高程序的效率和性能。不同的硬件平台可能有不同的字节顺序(big-endian或little-endian)、字节大小(8位或16位)、字符编码(ASCII或EBCDIC)等,如果char类型能够适应这些差异,那么程序就可以更好地利用硬件资源,减少转换和适配的开销。
为什么需要新增char16_t和char32_t类型?
答:
随着编程人员日益熟悉Unicode,类型wchar_t显然不再能够满足需求。因为wchar_t类型的长度和符号特征不一致,不能保证能够表示所有的Unicode码点。char16_t和char32_t类型则可以确保能够表示任何Unicode码点,而且长度和符号特征是固定的。
为什么使用const限定符比使用#define语句更好?
答:
因为const限定符可以指定变量的类型,限制变量的作用域,以及用于更复杂的类型,而#define语句只是简单地替换文本。
什么是作用域规则?
答:
作用域规则是指名称在程序中的可见性和有效范围。不同的作用域有不同的生存期和可访问性。C++中有四种作用域:全局作用域、局部作用域、类作用域和命名空间作用域。
什么是舍入误差?
答:
舍入误差是指由于浮点数的精度有限,而导致的与真实值之间的差异。例如,十进制小数0.1无法精确地转换为二进制小数,只能用一个近似值来表示,如0.00011001100110011…。如果用一个有限位数的二进制来存储这个值,就会产生舍入误差。
如何查找系统支持的其他头文件?
答:
一种方法是查看编译器或IDE提供的文档,通常会列出标准库和扩展库的头文件。另一种方法是在系统中搜索.h或.hpp后缀的文件,然后打开查看它们的内容。
C++中如何避免溢出和下溢?
答:
C++中的数据类型都有一定的范围,如果超出了范围,就会发生溢出或下溢。一种方法是选择合适的数据类型,根据数据的大小和精度来选择最适合的类型。另一种方法是使用一些数学库或函数,例如cmath或limits,来检查数据是否在范围内,或者处理异常情况。
C++引入的四个强制类型转换运算符分别是什么,它们有什么区别和用途?
答:
C++引入的四个强制类型转换运算符分别是static_cast<>、const_cast<>、dynamic_cast<>和reinterpret_cast<>。它们的区别和用途如下:
1、static_cast<>用于基本数据类型之间的转换,或类指针之间具有继承关系的转换。
2、const_cast<>用于去除变量的const或volatile属性。
3、dynamic_cast<>用于在类层次结构中安全地向下转型,即将基类指针转换为派生类指针,并进行运行时检查。
4、reinterpret_cast<>用于进行低级别的、没有任何安全保证的位重新解释,例如将指针转换为整数。
什么情况下需要使用强制类型转换?
答:
一些可能需要使用强制类型转换的情况有:
1、将一个值赋给值取值范围更小的类型;
2、将一个浮点值转换为整型;将一个字符的编码转换为整数;
3、将一个指针转换为另一种指针类型等。
auto关键字和decltype关键字有什么区别和联系?
答:
auto关键字和decltype关键字都是C++11引入的类型推断机制,它们可以让编译器根据表达式的类型来确定变量的类型。它们的区别是,auto关键字需要变量有初始值,并且会忽略顶层const和引用,而decltype关键字不需要变量有初始值,并且会保留顶层const和引用。
如何使用auto关键字来遍历容器或数组?
答:
使用auto关键字来遍历容器或数组时,可以使用基于范围的for循环,例如for (auto x : arr)或for (auto &x :
vec),其中x是容器或数组中的元素,arr是数组名,vec是容器名。如果要修改元素的值,需要使用引用符号&。














 764
764











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









