






一、核心概念与技术演进
1. 跳跃连接(Skip Connection)的本质突破
跳跃连接是深度学习领域的关键创新,其核心思想是绕过部分网络层直接传递信息,解决了深层网络的梯度消失和退化问题。这种设计通过数学公式 y=F(x)+x 实现,其中 F(x) 是残差函数,x 是直接跳过的输入。这种结构不仅保留了原始特征,还通过梯度分流(Gradient Shunting)机制让网络更易优化。
- 技术优势:
- 缓解梯度问题:反向传播时,梯度可以通过跳跃路径直接传递,避免深层网络梯度衰减。
- 提升特征复用:允许浅层的底层特征(如边缘、纹理)与深层的语义特征(如物体类别)直接融合。
- 支持超深网络:ResNet-152 等模型通过跳跃连接实现 152 层深度,而传统 CNN 难以训练超过 30 层的网络。
2. ResNet:跳跃连接的经典实践
ResNet(残差网络)是跳跃连接的集大成者,其核心模块残差块(Residual Block)分为两种类型:
- Basic Block(用于浅层网络):两个 3x3 卷积层叠加,输入直接相加。
- Bottleneck Block(用于深层网络):1x1 卷积降维、3x3 卷积提取特征、1x1 卷积升维,减少计算量。
ResNet 的成功验证了跳跃连接的有效性,例如在 ImageNet 分类任务中,ResNet-50 的错误率比 VGG-16 降低了 3.5%。
3. Transformer:自注意力机制的崛起
Transformer 最初用于自然语言处理,其核心是自注意力机制(Self-Attention),能够捕捉序列中的长距离依赖关系。与 ResNet 不同,Transformer 通过计算每个位置与其他位置的相关性来生成上下文表示,公式为:
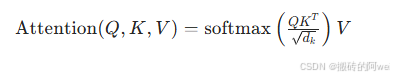
- 技术特点:
- 全局建模能力:相比 CNN 的局部感受野,Transformer 能直接建模全局信息。
- 并行计算:自注意力机制可以并行计算,适合 GPU 加速。
- 位置编码:通过正弦 / 余弦函数注入位置信息,解决序列顺序问题。
二、跳跃连接在 Transformer 中的创新应用
1. 标准 Transformer 的跳跃连接设计
Transformer 的编码器和解码器中广泛使用跳跃连接:
- 多头注意力层:输入经过线性变换后与输出相加。
- 前馈神经网络层:输出与输入相加,再进行层归一化。
这种设计确保了信息在不同层之间的流动,避免了梯度消失。例如,在 ViT(Vision Transformer)中,每个 Transformer 块的结构为:
2. 跳跃连接的改进与优化
- 层归一化(Layer Normalization):
传统跳跃连接在深层网络中可能导致梯度爆炸或消失。研究表明,在跳跃路径上添加层归一化(如 Transformer 中的做法)可以稳定训练过程。例如,ResNet 中的 Batch Normalization(BN)与 Transformer 中的 Layer Normalization(LN)在跳跃连接中的效果差异显著。 - 递归跳跃连接(Recursive Skip Connection):
提出的 2R-Skip+LN 结构通过递归应用跳跃连接和层归一化,自适应调整输入尺度,提升了模型在图像分类和机器翻译任务中的性能。
3. 典型案例:SparX 模型
香港大学提出的 SparX 模型结合了跳跃连接与稀疏跨层机制,通过将网络层分为神经节层(Ganglion Layer)和常规层(Normal Layer),实现了更高效的信息交互:
- 神经节层:包含动态位置编码(DPE)和跨层通道聚合器(DMCA),负责全局信息整合。
- 常规层:仅处理局部特征,减少计算量。
这种设计使 SparX-Mamba-T 在 ImageNet-1K 上的 Top-1 准确率比 VMamba-T 提升 1%,同时参数量减少 50%。
三、ResNet 与 Transformer 的融合架构
1. 混合架构的设计思路
- 特征互补:ResNet 擅长提取局部细节,Transformer 擅长捕捉全局语义。
- 多阶段融合:在 ResNet 的不同阶段插入 Transformer 模块,例如:
- 早期融合:在 ResNet 的浅层添加 Transformer,增强全局建模。
- 晚期融合:在 ResNet 的深层添加 Transformer,提升语义理解。
- 参数共享:通过跳跃连接共享部分参数,减少计算量。
2. 典型模型与应用
- SpikingResformer:
将 ResNet 的多阶段设计与脉冲自注意力机制结合,适用于脉冲神经网络(SNNs)。在 ImageNet 上,SpikingResformer-L 的 Top-1 准确率达 79.4%,优于传统 SNN 模型。 - EfficientRMT-Net:
结合 ResNet-50 和 Vision Transformer,采用深度卷积(DWC)和阶段块结构,在土豆叶病分类任务中准确率达 99.12%。 - TransUNet:
在医学图像分割中,将 ResNet 作为编码器的前三层提取局部特征,Transformer 作为编码器的深层部分捕捉全局语义,Dice 系数达 0.8171,优于传统 U-Net。
四、技术挑战与未来方向
1. 当前挑战
- 计算复杂度:Transformer 的自注意力机制复杂度为 \(O(n^2)\),在高分辨率图像中计算成本高昂。
- 训练稳定性:跳跃连接与自注意力机制的结合可能导致梯度不稳定,需要精心设计归一化策略。
- 硬件适配:混合架构对 GPU/TPU 的并行计算优化要求更高。
2. 未来方向
- 动态跳跃连接:根据任务需求自适应调整跳跃路径,如 SparX 的稀疏跨层机制。
- 轻量化设计:通过知识蒸馏、剪枝等技术压缩混合模型,如 EfficientRMT-Net 的深度卷积。
- 多模态融合:将 ResNet+Transformer 扩展到视频、3D 点云等多模态任务,如 Swin Transformer 的 3D 版本。
五、总结
跳跃连接、Transformer 和 ResNet 的融合代表了深度学习架构的前沿探索。ResNet 通过跳跃连接突破了 CNN 的深度限制,Transformer 通过自注意力机制革新了序列建模,而两者的结合(如 SparX、SpikingResformer)则在保持高效局部特征提取的同时,增强了全局语义理解。未来,随着动态架构设计和硬件加速技术的发展,这类混合模型有望在计算机视觉、自然语言处理等领域实现更广泛的应用。

















 1204
1204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









