







 本文介绍了如何通过参数估计和反向传播机制在张量计算中优化线性模型,通过梯度下降法调整权重和偏置,以最小化损失函数。作者逐步演示了从简单线性关系到复杂模型优化的过程,包括学习率的选择、梯度计算和数据可视化。
本文介绍了如何通过参数估计和反向传播机制在张量计算中优化线性模型,通过梯度下降法调整权重和偏置,以最小化损失函数。作者逐步演示了从简单线性关系到复杂模型优化的过程,包括学习率的选择、梯度计算和数据可视化。
学习的机制
一、学习就是参数估计
已有输入数据和期望数据(实际数据),以及权重的初始值,给模型输入初始值,将输出与实际数据进行对比来评估误差。为了优化模型参数(权重),权重单位变化后的误差变化是使用复合函数的导数的链式法则计算(反向传播),然后在误差减小的方向上更新权重值,重复改过程,就可以将误差降到可接受的值
背景引入
为一个没有刻度的温度计标上刻度
%matplotlib inline
import numpy as np
import torch
torch.set_printoptions(edgeitems=2, linewidth=75)
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]#单位为摄氏度的温度
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]#未知单位
#转化为张量
t_c = torch.tensor(t_c)
t_u = torch.tensor(t_u)
我们猜测t_c和t_u呈线性相关
于是我们定义模型:
def model(t_u, w, b):
return w * t_u + b
二、减少损失是我们想要的
学习的过程要试图是损失函数减小,这次尝试中将损失函数定义为差值的平方:
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c) ** 2
return squared_diffs.mean()
我们初始化模型并获得损失函数的值
w = torch.ones(())
b = torch.zeros(())
t_p = model(t_u, w, b)
#tensor([35.7000, 55.9000, 58.2000, 81.9000, 56.3000, 48.9000, 33.9000,
# 21.8000, 48.4000, 60.4000, 68.4000])
loss = loss_fn(t_p, t_c)
loss
tensor(1763.8848)
我们为参数简单并草率的拟合了一个损失函数和线性方程,我们该如何优化w, b使得损失达到最小。在此之前,我们先来简单地了解下张量的广播
当张量的维度shape不一致时,广播机制会自动调整张量维度使得计算可以顺利进行。

x = torch.ones(())
y = torch.ones(3,1)
z = torch.ones(1,3)
a = torch.ones(2, 1, 1)
print(f"shapes: x: {x.shape}, y: {y.shape}")
print(f" z: {z.shape}, a: {a.shape}")
print("x * y:", (x * y).shape)
print("y * z:", (y * z).shape)
print("y * z * a:", (y * z * a).shape)
y * z * a
shapes: x: torch.Size([]), y: torch.Size([3, 1])
z: torch.Size([1, 3]), a: torch.Size([2, 1, 1])
x * y: torch.Size([3, 1])
y * z: torch.Size([3, 3])
y * z * a: torch.Size([2, 3, 3])
tensor([[[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]]])
三、沿着梯度下降
3.1减小损失
梯度下降的思想就是计算个参数的损失变化率,并在减小损失变化率的方向上修改参数,关于损失率我们这样计算:
delta = 0.1
loss_rate_of_change_w = \
(loss_fn(model(t_u, w + delta, b), t_c) - loss_fn(model(t_u, w - delta, b), t_c)) / (2.0 * delta)
loss_rate_of_change_b = \
(loss_fn(model(t_u, w, b + delta), t_c) - loss_fn(model(t_u, w, b - delta), t_c)) / (2.0 * delta)
w的增加会导致损失的变化,如果变化是负的则增加w以减少损失,如果变化是正的则反之;一般来说要缓慢的改变参数,因此我们使用一个很小的因子(学习率)来衡量变化率
learning_rate = 1e-2
b = b - learning_rate * loss_rate_of_change_b
w = w - learning_rate * loss_rate_of_change_w
以上操作表示的是梯度下降基本参数的更新步骤。通过重复以上评估步骤(我们只要选择一个够小的学习率),将收敛到在给定参数上使损失最小的参数的最优值
3.2分析
对模型和损失的重复评估来探测损失函数在w,b领域的行为,计算变化率在参数较多的场合并不适用,如果损失太快,我们就无法很好的知道损失在哪个方向上减小的最快。我们取领域无限小来研究,即损失对参数的求导,将每个倒数的损失导数放入一个导数向量中(梯度)
3.2.1 计算导数
我们的损失函数(loss_fn)是差方形式因此导数为:2 * (t_c - t_p) / t_p.size(0)
线性函数(model)的对w求导为:t_u, 对b求导为:1
3.2.2 定义梯度
t_p实际上就是model函数得出的结果,下面用model函数(m)来替代t_p
在这里插入图片描述
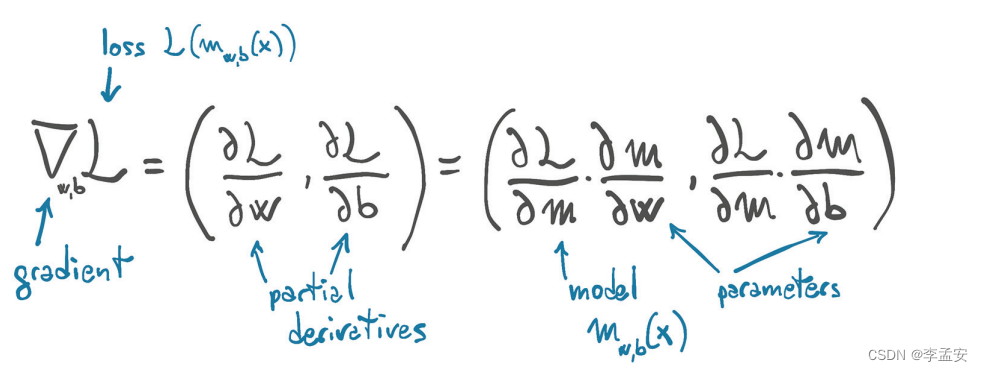
def dloss_fn(t_p, t_c):
return 2 * (t_p - t_c) / t_p.size(0)
def dmodel_dw(t_u, w, b):
return t_u
def dmodel_db(t_u, w, b):
return 1.0
def grad_fn(t_u, t_c, t_p, w, b):
dloss_dm = dloss_fn(t_p, t_c)
dloss_dw = dloss_dm * dmodel_dw(t_u, w, b)
dloss_db = dloss_dm * dmodel_db(t_u, w, b)
return torch.stack([dloss_dw.sum(), dloss_db.sum()])
3.3迭代以适应模型
3.3.1 循环训练
def training_loop(n_epochs, learning_rate, params, t_u, t_c,
print_params=True):
for epoch in range(1, n_epochs + 1):
w, b = params
t_p = model(t_u, w, b) # <1>
loss = loss_fn(t_p, t_c)
grad = grad_fn(t_u, t_c, t_p, w, b) # <2>
params = params - learning_rate * grad
if epoch in {1, 2, 3, 10, 11, 99, 100, 4000, 5000}: # <3>
print('Epoch %d, Loss %f' % (epoch, float(loss)))
if print_params:
print(' Params:', params)
print(' Grad: ', grad)
if epoch in {4, 12, 101}:
print('...')
if not torch.isfinite(loss).all():
break # <3>
return params
training_loop(
n_epochs = 100,
learning_rate = 1e-2,
params = torch.tensor([1.0, 0.0]),
t_u = t_u,
t_c = t_c)
Epoch 1, Loss 1763.884766
Params: tensor([-44.1730, -0.8260])
Grad: tensor([4517.2964, 82.6000])
Epoch 2, Loss 5802484.500000
Params: tensor([2568.4011, 45.1637])
Grad: tensor([-261257.4062, -4598.9702])
Epoch 3, Loss 19408029696.000000
Params: tensor([-148527.7344, -2616.3931])
Grad: tensor([15109614.0000, 266155.6875])
...
Epoch 10, Loss 90901105189019073810297959556841472.000000
Params: tensor([3.2144e+17, 5.6621e+15])
Grad: tensor([-3.2700e+19, -5.7600e+17])
Epoch 11, Loss inf
Params: tensor([-1.8590e+19, -3.2746e+17])
Grad: tensor([1.8912e+21, 3.3313e+19])
tensor([-1.8590e+19, -3.2746e+17])
最后训练的结果并不好,因为learning rate过大导致修正过度,我们将learning rate减小后发现损失率下降得很慢,这个问题可以通过学习率自适应来解决,但是更新时的梯度存在问题
3.4 归一化输入
training_loop(
n_epochs = 100,
learning_rate = 1e-4,
params = torch.tensor([1.0, 0.0]),
t_u = t_u,
t_c = t_c)
Epoch 1, Loss 1763.884766
Params: tensor([ 0.5483, -0.0083])
Grad: tensor([4517.2964, 82.6000])
Epoch 2, Loss 323.090515
Params: tensor([ 0.3623, -0.0118])
Grad: tensor([1859.5493, 35.7843])
Epoch 3, Loss 78.929634
Params: tensor([ 0.2858, -0.0135])
Grad: tensor([765.4666, 16.5122])
...
Epoch 10, Loss 29.105247
Params: tensor([ 0.2324, -0.0166])
Grad: tensor([1.4803, 3.0544])
Epoch 11, Loss 29.104168
Params: tensor([ 0.2323, -0.0169])
Grad: tensor([0.5781, 3.0384])
...
Epoch 99, Loss 29.023582
Params: tensor([ 0.2327, -0.0435])
Grad: tensor([-0.0533, 3.0226])
Epoch 100, Loss 29.022667
Params: tensor([ 0.2327, -0.0438])
Grad: tensor([-0.0532, 3.0226])
tensor([ 0.2327, -0.0438])
在这份learning_rate改进后的代码中我们可以发现:w和b的梯度相差有点大,这意味着learning_rate并不同时适合w、b,我们想要做出与每个参数对应的learning_rate,但是对于多参数模型来说又太麻烦,因此使用归一化操作:改变输入,使得w,b的梯度不会有太大的不同
t_un = 0.1 * t_u
params = training_loop(
n_epochs = 50000,
learning_rate = 1e-2,
params = torch.tensor([1.0, 0.0]),
t_u = t_un,
t_c = t_c,
print_params = False)
params
Epoch 1, Loss 80.364342
Epoch 2, Loss 37.574913
Epoch 3, Loss 30.871077
...
Epoch 10, Loss 29.030489
Epoch 11, Loss 28.941877
...
Epoch 99, Loss 22.214186
Epoch 100, Loss 22.148710
...
Epoch 4000, Loss 2.927680
Epoch 5000, Loss 2.927648
tensor([ 5.3676, -17.3042])
params = training_loop(
n_epochs = 5000,
learning_rate = 1e-2,
params = torch.tensor([1.0, 0.0]),
t_u = t_un,
t_c = t_c,
print_params = False)
params
Epoch 1, Loss 80.364342
Epoch 2, Loss 37.574913
Epoch 3, Loss 30.871077
...
Epoch 10, Loss 29.030489
Epoch 11, Loss 28.941877
...
Epoch 99, Loss 22.214186
Epoch 100, Loss 22.148710
...
Epoch 4000, Loss 2.927680
Epoch 5000, Loss 2.927648
tensor([ 5.3671, -17.3012])
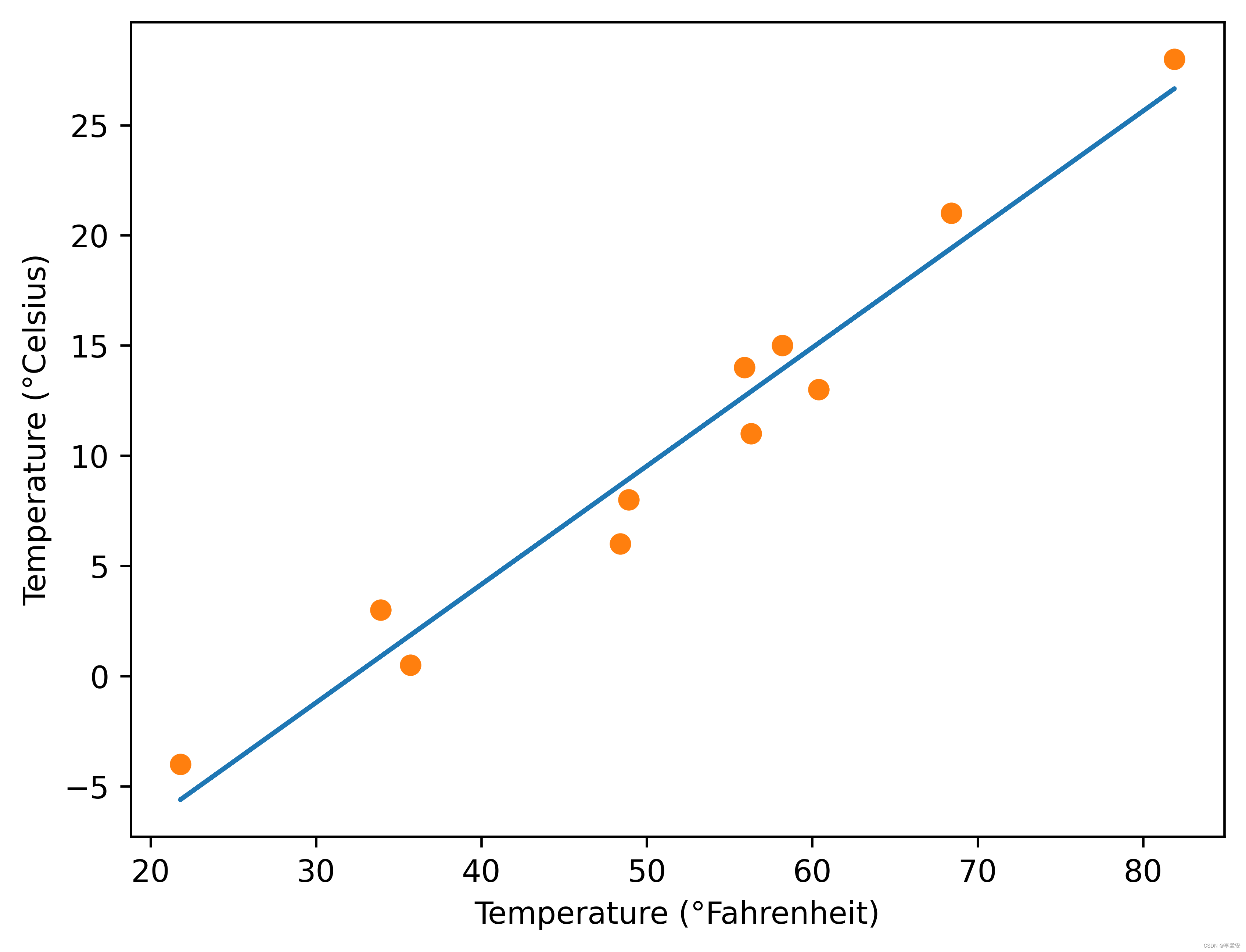
3.5 数据的可视化
%matplotlib inline
from matplotlib import pyplot as plt
t_p = model(t_un, *params) # *params作为参数传递,等价为params[0],params[1]
fig = plt.figure(dpi=600)
plt.xlabel("Temperature (°Fahrenheit)")
plt.ylabel("Temperature (°Celsius)")
plt.plot(t_u.numpy(), t_p.detach().numpy()) # <2>
plt.plot(t_u.numpy(), t_c.numpy(), 'o')
plt.savefig("temp_unknown_plot.png", format="png") # bookskip


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









