






1、构建pyspark执行环境入口对象(SparkContext)
#导包
from pyspark import SparkConf, SparkContext
#创建SparkConf类对象
conf = SparkConf().setMaster("local[*]).\
setAppName("test_spark_app")
#基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)
#打印pyspark的运行版本
print(sc.version)
#停止SparkContext对象运行
sc.stop()1.1、spark的编程模型

RDD对象:
pyspark支持通过SparkContext对象的parallelize成员方法,将list、tuple、set、dict、str转换为pyspark的RDD对象。
转换时:字符串会被拆分成单个的字符,存入·RDD对象
from pyspark SparkConf, SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf = conf)
#通过parallelize方法将python对象加载到是【ark内,成为RDD对象
rdd1 = sc.parallelize([1,2,3,4,5])
rdd2 = sc.parallelize((1,2,3,4,5))
rdd2 = sc.parallelize("dhskj")
rdd4 = sc.parallelize({1,2,3,4,5})
rdd5 = sc.parallelize({"key1": "value1","key2": "value2"})
#如果需要查看RDD里面有什么内容,需要collect()方法
print(rdd1.collect())
print(rdd2.collect())
print(rdd3.collect())
print(rdd4.collect())
print(rdd5.collect())
#读取文件转RDD对象,数据输入spark,就会成为rdd对象。
rdd = sc.textFile("D:/hello.txt")
print(rdd.collect())
sc.stop()RDD对象是什么?
是分布式弹性数据集,是oyspark中数据计算的载体,它可以:1、提供数据存储;2、提供数据计算的各类方法;3、数据计算后,返回的仍旧是RDD对象。
怎么输入数据到spark,即得到RDD对象
1、通过SparkContext的parallelize成员方法,将python数据容器转换为RDD对象
2、通过SparkContext的textFile成员方法,读取文本文件得到RDD对象
2、数据计算
| 数据计算指令 | 指令格式 |
| map | rdd.map(func)/rdd.map(lambda 变量: 函数体) |
| flapMap | rdd.flapMap(func)/rdd.flapMap(lambda 变量: 函数体);指令个数基本与map一致,差别在于。flapMap的输出是无嵌套的数据。 数据(“shu shi kjoi","jhdi ewju hdd","jhui jk ijn") map得到的结果:[[”shu","shi","kjoi",["jhdi","ewju","hdd"],["jhui","jk","ijn"]] flapMap得到的结果:[”shu","shi","kjoi","jhdi","ewju","hdd","jhui","jk","ijn"] |
| reduceByKey | reduceByKey(lambda a,b: a+b);对二元元组操作,用于分组聚合操作 |
| filter | filter(lambda x: 命题);数据滤波,仅保留命题为真的数据 |
| distinct | distin(),去重操作 |
| sortBy | sortBy(lambda x: 用于排序的参数,ascending = True, numPartition = 1);ascending = True升序;ascending = False降序;numPartition = *表示分区数目,这个数目与spark的分布式操作相关。 |
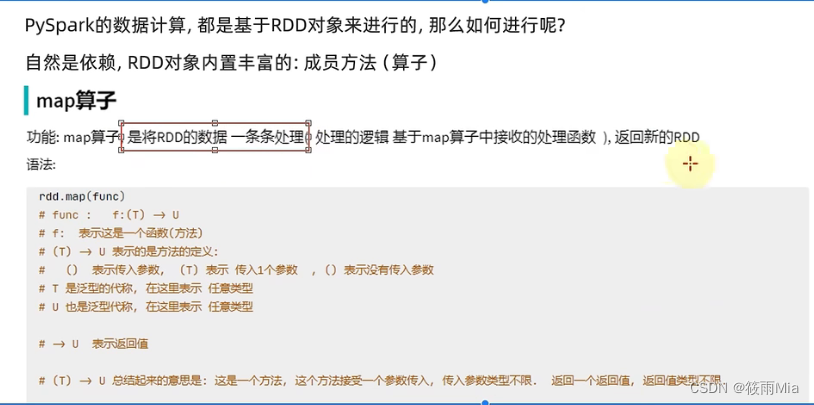
2.1、map算子
功能:将RDD的数据一条条处理,处理的逻辑 基于map算子中接收的处理函数func,返回新RDD
rdd.map(func)
支持链式调用
from pyspark SparkConf, SparkContext
#当spark找不到python解释器所在时,会报错。可以这样做:
#import os
#os.envior['PYSPARK_PYTHON'] ] "d:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf = conf)
#通过parallelize方法将python对象加载到是【ark内,成为RDD对象
rdd1 = sc.parallelize([1,2,3,4,5])
#通过map方法将全部数据都乘10
def func(data):
return data*10
rdd2 = rdd1.map(func)
内部的func可用两种方式书写:
1、用def定义函数
2、用lambda表达式快速编写
2.2、flapMap算子
功能:对rdd执行map操作,然后进行解除嵌套操作
#解除嵌套前:
list1 = [[1,2,3],[4,5,6],[8,9,0]]
#解除嵌套后
list1 = [1,2,3,4,5,6,8,9,0]
代码
from pyspark SparkConf, SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf = conf)
#通过parallelize方法将python对象加载到是【ark内,成为RDD对象
rdd2 = sc.parallelize(["dhskj fdjlk dsklf","sfd rfds ewr","wq wef sade"])
rdd = rdd2.map(lambda x: x.split(" "))
rdd1 = rdd2.flapmap(lambda x: x.split(" "))
2.3、redunceByKey算子
KV型:二元元组,(Key,Value)
功能:针对KV型ADD,自动按照Key分组,然后根据算子中提供的聚合逻辑,完成组内数据value的聚合函数

代码
from pyspark SparkConf, SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf = conf)
#通过parallelize方法将python对象加载到是spark内,成为RDD对象
rdd2 = sc.parallelize([("men",23),("men",32),("women",66),("women",88])
rdd = rdd2.reducebykey(lambda x,y: x+y))
2.4、案例1
使用pyspark相关方法,读取文件,统计单词出现次数
from pyspark SparkConf, SparkContext
import os
os.environ["PYSPARK_PYTHON"] = "D/hskdj/python.ext"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf = conf)
#读取文件
rdd = sc.textFile("D:/hello.txt")
#取出全部单词
rdd1 = rdd.flapMap(lambda x: x.split(" "))
#将所有单词都转换成二元元组
rdd2 = rdd1.map(lambda y: (y,1))
#分组求和
rdd3 = rdd2.reduceByKey(lambda a,b: a+b)
#打印输出2.5、filter算子
1、接收一个处理函数,可用lambda编写处理函数
2、面对RDD数据,逐个处理,将True返回到RDD
from pyspark SparkConf, SparkContext
import os
os.environ["PYSPARK_PYTHON"] = "D/hskdj/python.ext"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf = conf)
rdd = sc.parallelze([1,2,3,4,5])
#只保留偶数
rdd1 = rdd.filtre(lambda num: num % 2 == 0)5、distinc算子
功能:对RDD数据进行去重,返回新的RDD,不需要传参
from pyspark SparkConf, SparkContext
import os
os.environ["PYSPARK_PYTHON"] = "D/hskdj/python.ext"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf = conf)
rdd = sc.parallelze([1,2,3.4.5.6,3,4,5])
#只保留偶数
rdd1 = rdd.dictinc()2.6、sortBy算子
功能:对RDD数据进行排序,基于指定点排序顺序
rdd.sortBy(func,ascending=Flase,numPartition = 1)
1、处理函数可用lambda编写
2、函数表示用来决定排序的依据
3、可以控制升序或者降序
4、全局排序需要设置分区数为1
from pyspark SparkConf, SparkContext
import os
os.environ["PYSPARK_PYTHON"] = "D/hskdj/python.ext"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf = conf)
#读取文件
rdd = sc.textFile("D:/hello.txt")
#取出全部单词
rdd1 = rdd.flapMap(lambda x: x.split(" "))
#将所有单词都转换成二元元组
rdd2 = rdd1.map(lambda y: (y,1))
#分组求和
rdd3 = rdd2.reduceByKey(lambda a,b: a+b)
rdd4 = rdd3.sortBy(lambda x: x[1], ascending=False, numPartition=1)
#打印输出2.7、案例2
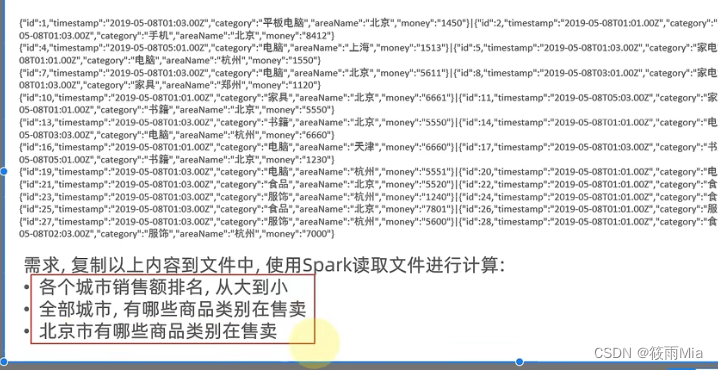
代码
#案例2
#每行包含多个json,要先分离
from pyspark SparkConf, SparkContext
import json
import os
os.environ["PYSPARK_PYTHON"] = "D/hskdj/python.ext"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf = conf)
##----需求1:统计城市销售额---------
#读取文件
rdd = sc.textFile("D:/hello.txt")
#取出全部单词
str_rdd1 = rdd.flapMap(lambda x: x.split("|"))
#JSON转字典
dict_rdd = str_rdd1.map(lambda x: json.loads(x))
#取出城市和销售数据,搞成二元元组
rdd2 = dict_rdd.map(lambda x: (x['areaName'],int(x['money'])))
#分组聚合 reduceByKey
rdd3 =rdd2.reduceByKey(lambda A,B: A+B)
#排序
rdd4 = rdd3.sortBy(lambda x: x[1], ascending = False, numPartition=1)
##-----需求2:全部城市,有哪些商品在卖
#取出所有商品部类别,去重
rdd5 = rdd4.map(lambda x: x['category']).distinc()
##-----需求3:北京市有哪些商品在卖
#过滤,只保留北京
rdd6 = rdd5.filter(lambda x: x['areaName'] == 'beijing')
#取出所有商品类别
rdd7 = rdd6.map(lambda x: x['category']).distinc() 3、将RDD对象输出为python
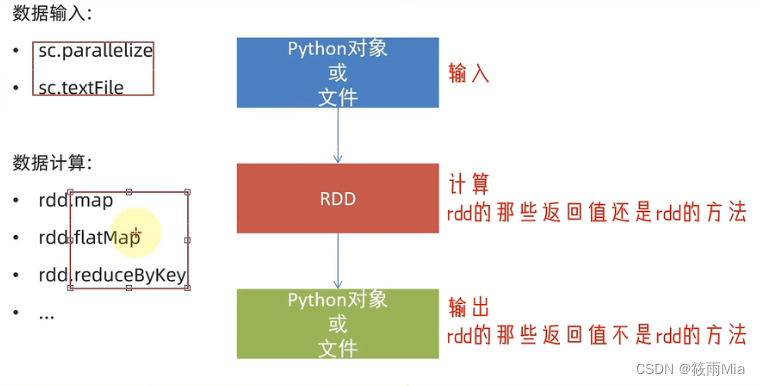
代码
#collect算子
#将RDD各个分区内的数据,统一收集到driver中,形成一个List对象
#用法:rdd.collect()
#返回值是一个list
##RDD------>List
#reduce算子
#将RDD数据集合按照你传入的逻辑进行聚合
#用法:rdd.reduce(func)
#example:rdd.reduce(lambda a,b: a+b))
#类似有reduceByKey
#take算子
#取RDD的前N个元素,组合成lst返回给你
#用法:rdd.take(5)
#count算子
#计算RDD中元素个数
#用法:rdd.count()
3.1 RDD数据输出到文件中
#saveAsTextFile算子
##数据输出到文件中
#用法:rdd.saveAsTextFile("目标地址")
from pyspark SparkConf, SparkContext
import json
import os
os.environ["PYSPARK_PYTHON"] = "D/hskdj/python.ext"
os.environ['HADOOP_HOME']="D"/dev/hadoop-3.0.0"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf = conf)
#读取文件
rdd = sc.textFile("D:/hello.txt")
ou = rdd.saveAsTextFile("D:/output")
##环境配置完,重新跑时,要将文件夹中可能存在的output文件夹删除,不然会报错直接进行转换会报错
这是因为环境缺少配置,
3.2 设置分区
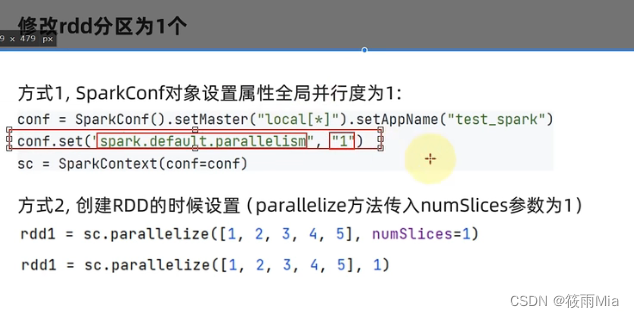
1、RDD输出到文件的方法:1)rdd.saveAsTextFile(路径);2)输出的结果是一个文件夹;3)有几个分区就输出多少个结果文件夹;
2、如何修改RDD分区:1)SparkConf对象设置conf.set("spark.default.parallelism","1");2)创建RDD的时候,sc.parallelize方法传入numSlices参数为1
3.3 案例2
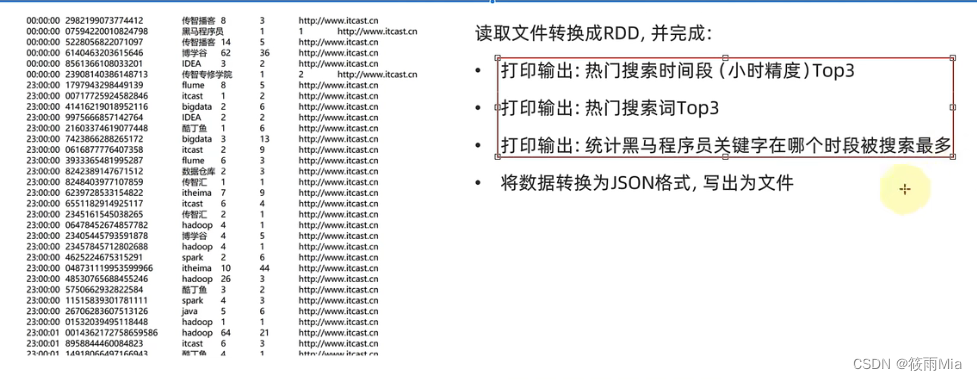
from pyspark SparkConf, SparkContext
import json
import os
os.environ["PYSPARK_PYTHON"] = "D/hskdj/python.ext"
os.environ['HADOOP_HOME']="D"/dev/hadoop-3.0.0"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
conf.set("spark.default.parallelism","1")
sc = SparkContext(conf = conf)
#读取文件
rdd = sc.textFile("D:/hello.txt")
##TODO1 热门搜索时间段前三(小时精度)
##链式规则,一条完成
rdd1 = rdd.map9lambda x: x.split("\t")).\
map(lambda x: x[0][:2]).\
map(lambda x: (x,1)).\
reduceByKey(lambda a,b: a+b).\
sortBy(lambda x: x[1], ascending == False, numPartition == 1).\
take(3)
##分步完成
#1.1 取出全部时间,并转化成小时
time_rdd = rdd.map(lambda x: x.split("\t")).map(lambda x: x[0][:2])
#1.2 转换为小时的二元元组
hour_rdd = time_rdd.flapMap(lambda x: (x,1))
#1.3 分组聚合
group_rdd = hour_rdd.reduceByKey(lambda x,y: x+y)
#1.4 排序
sort_rdd = group_rdd.sortBy(lambda x: x[1],ascending == False, numPartition == 1)
#取前三
out_rdd1 = sort.rdd.take(3)
##TODO2 热门搜索词前三
##链式写法
rdd2 = rdd.map(lambda x: (x.split("\t")[2],1)).\
reduceByKey(lambda a,b: a+b).\
sortBy(lambda x: x[1], ascending = Flase, numPartition = 1).\
take(3)
#分步写法
#2.1 取出全部搜索词
word_rdd = rdd.map(lambda x: x.split("\t")).map(lambda x: x[2])
#2.2 转换为,key=搜索词;value=1的二元元组
word_rdd1 = word.rdd.map(lambda x: (x,1))
#2.3 分组聚合
group_rdd1 = word_rdd1.reduceByKey(lambda a,b: a+b)
#2.4 排序
sort_rdd1 = group_rdd1.sortBy(lambda x: x[1], ascdending =False, numPartition = 1)
#2.5 取出前3
out_rdd2 = sort_rdd1.take(3)
##TODO3 统计黑马程序员在什么时间段搜素最多
##链式写法
rdd3 = rdd.map(lambda x: (x.split("\t")[2],1)).\
filter(lambder x: x == "黑马程序员").\
reduceByKey(lambda a,b: a+b).\
sortBy(lambda x: x[1], ascending = True, numPartition = 1).\
take(1`)
##分步写法
#3.1 过滤内容,只保留 黑马程序员关键字
heima_rdd = word_rdd.filter(lambda x: x == "黑马程序员")
#3.2 转换为二元元组
group_rdd2 = heima_rdd.map(lambda x: (x,1))
#3.3 分组聚合
group_rdd22 = group_rdd2.reduceByKey(lambda a,b: a+b)
#3.4 排序
sort_rdd2 = group_rdd2.sortBy(lambda x: x[1], ascdening = True, numPartition = 1)
#3.5 取最高
out_rdd3 = sort_rdd2.take(1)
##TODO4 有效数据转换成json格式,并写入到文件中
##链式写法
rdd4 = rdd.map(lambda x: x.split("\t")).\
map(lambda x: {"time": x[0], "user_id": x[1], "key_word": x[2],"randk1": x[3], "randk2": x[4], "url": x[5]}).\
saveTextFile("D:/output_json")
##分步写法
#4.1 转换为json形式的RDD
rdd4 = rdd.map(lambda x: x.split("\t"))
rdd5 = rdd4.map(lambda x: {"time": x[0], "user_id": x[1], "key_word": x[2],"randk1": x[3], "randk2": x[4], "url": x[5]}).\
#4.2 导出到文件中
out = rdd5.saveTextFile("D:/output_json")















 284
284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









