







文章目录
nvidia-smi是Nvidia显卡命令行管理套件,基于NVML库,旨在管理和监控Nvidia GPU设备。
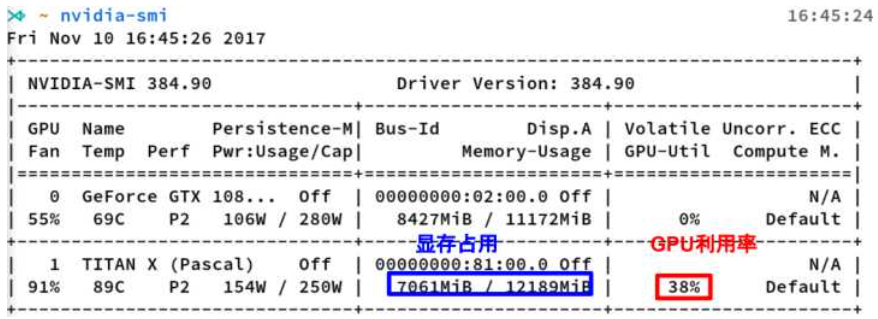
nvidia-smi的输出
这是nvidia-smi命令的输出,其中最重要的两个指标:
-
显存占用
-
GPU利用率
显存占用和GPU利用率是两个不一样的东西,显卡是由GPU计算单元和显存等组成的,显存和GPU的关系有点类似于内存和CPU的关系。
这里推荐一个好用的小工具:gpustat,直接pip install gpustat即可安装,gpustat基于nvidia-smi,可以提供更美观简洁的展示,结合watch命令,可以动态实时监控GPU的使用情况。
watch --color -n1 gpustat -cpu
gpustat 输出
显存可以看成是空间,类似于内存。
-
显存用于存放模型,数据
-
显存越大,所能运行的网络也就越大
GPU计算单元类似于CPU中的核,用来进行数值计算。衡量计算量的单位是flop: the number of floating-point multiplication-adds,浮点数先乘后加算一个flop。计算能力越强大,速度越快。衡量计算能力的单位是flops:每秒能执行的flop数量

1. 显存分析
1.1 存储指标

K、M,G,T是以1024为底,而KB 、MB,GB,TB以1000为底。不过一般来说,在估算显存大小的时候,我们不需要严格的区分这二者。
在深度学习中会用到各种各样的数值类型,数值类型命名规范一般为TypeNum,比如Int64、Float32、Double64。
-
Type:有Int,Float,Double等
-
Num: 一般是 8,16,32,64,128,表示该类型所占据的比特数目
常用的数值类型如下图所示:
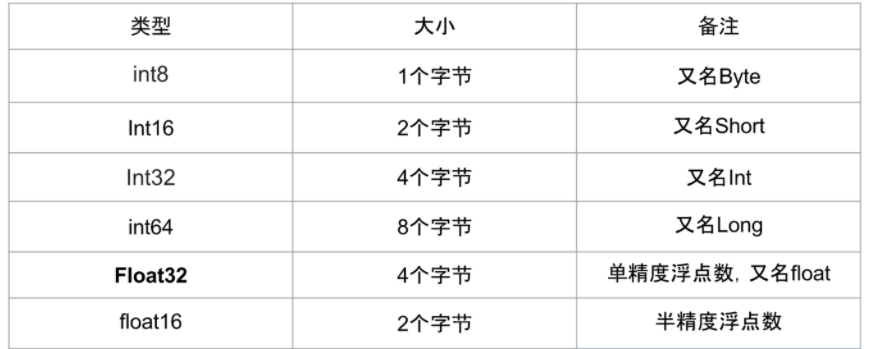
常用的数值类型
其中Float32 是在深度学习中最常用的数值类型,称为单精度浮点数,每一个单精度
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









