







parser代码的基本结构
打开parser.cc,用vscode或者vim都行。
一.总体概述
首先递归式的把文件名和路径读入一个数组内,接着把数组内的每一个数据按照一定的格式进行划分,最后把划分后的内容输入到output路径里。
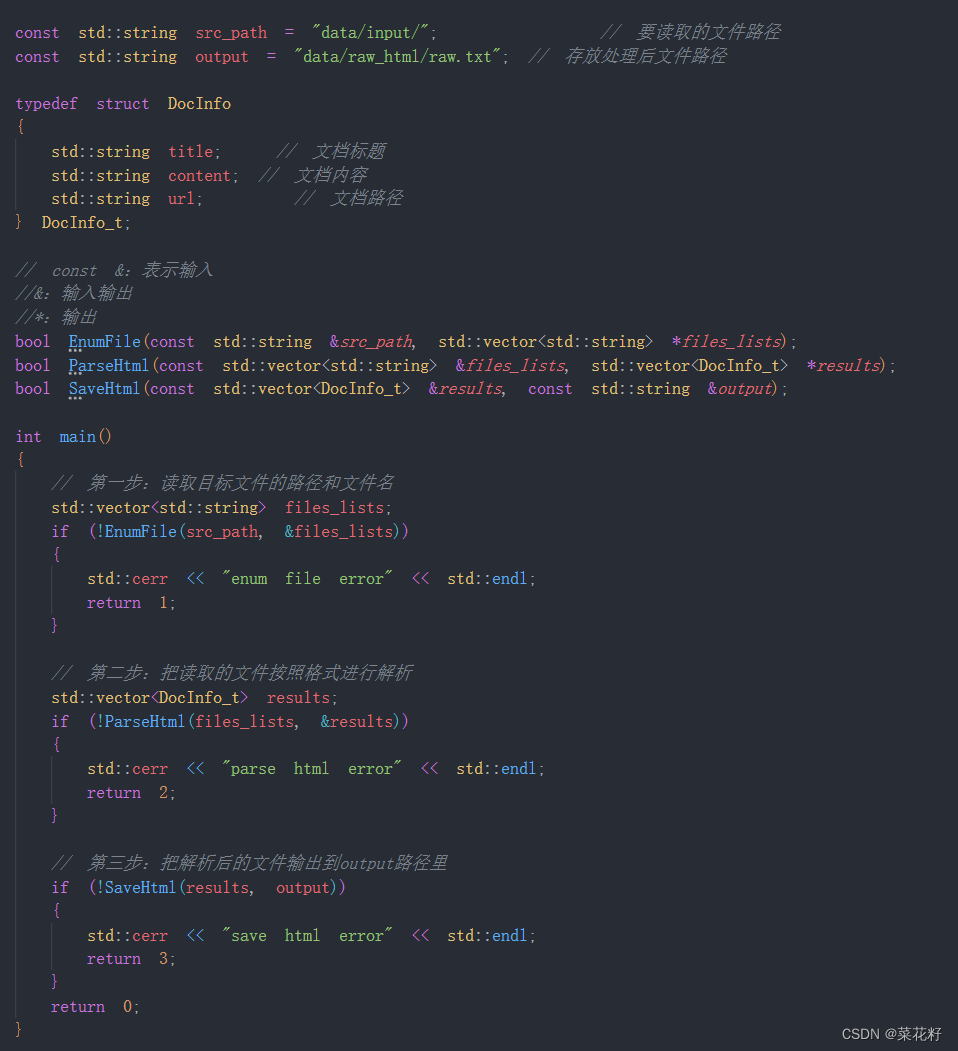
二. EumeFile的实现
由于C++库对于文件的实现并不完整,所以我们需要使用Boost库里的函数。
安装Boost开发库

需要注意的是,我们现在做的是Boost库的搜索引擎,并非对它的源代码进行搜索,而是对它的使用手册进行搜索。
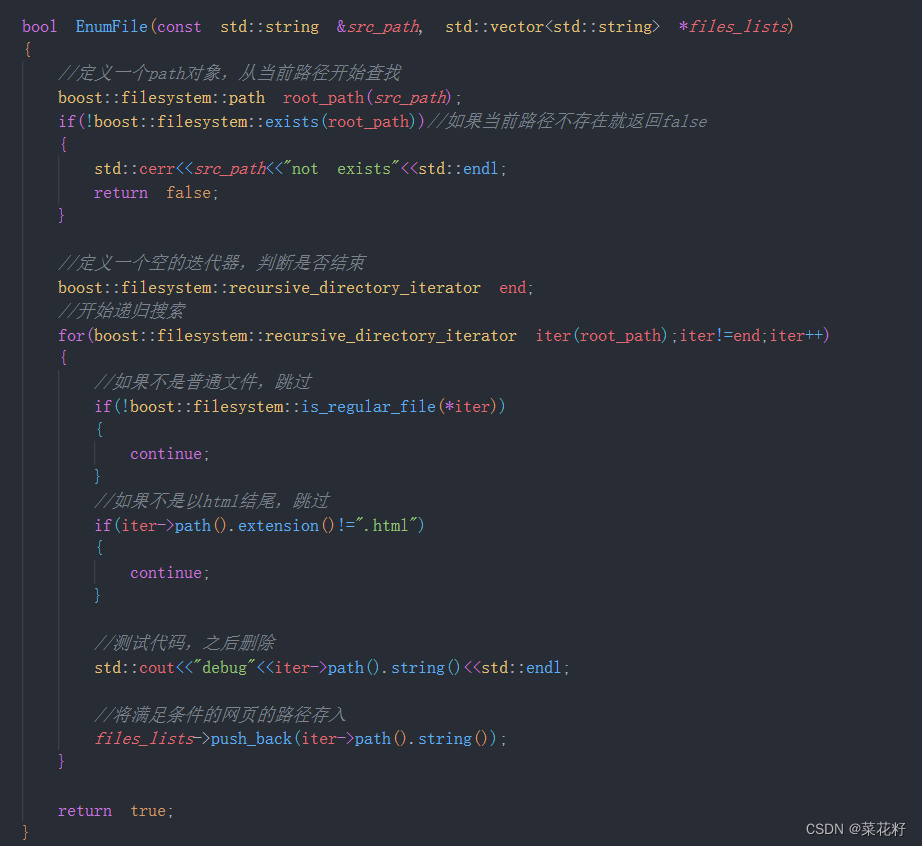
首先判断该路径是否存在,接着以递归的方式不断搜索文件,再判断搜索到的是否是普通文件,然后再是否是以.html结尾,最后将它的路径存入。
测试一下
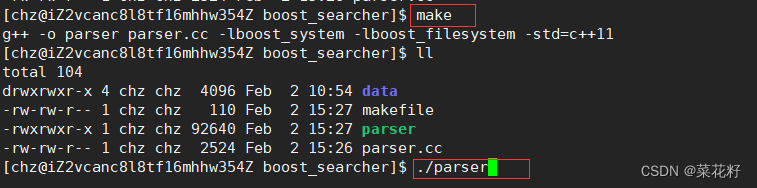
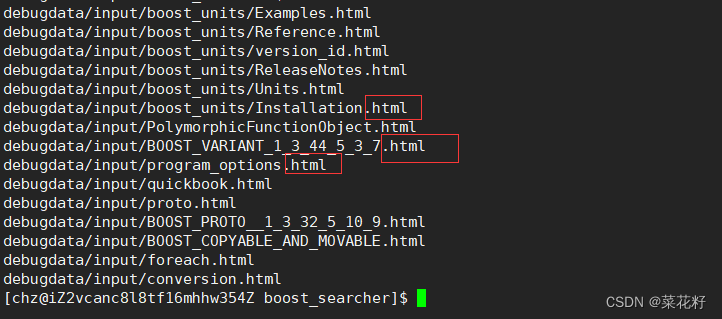
测试完成,没有问题。
三.ParserHtml的实现
该函数主要功能:读取信息,然后分离出title,content,url。
总体框架
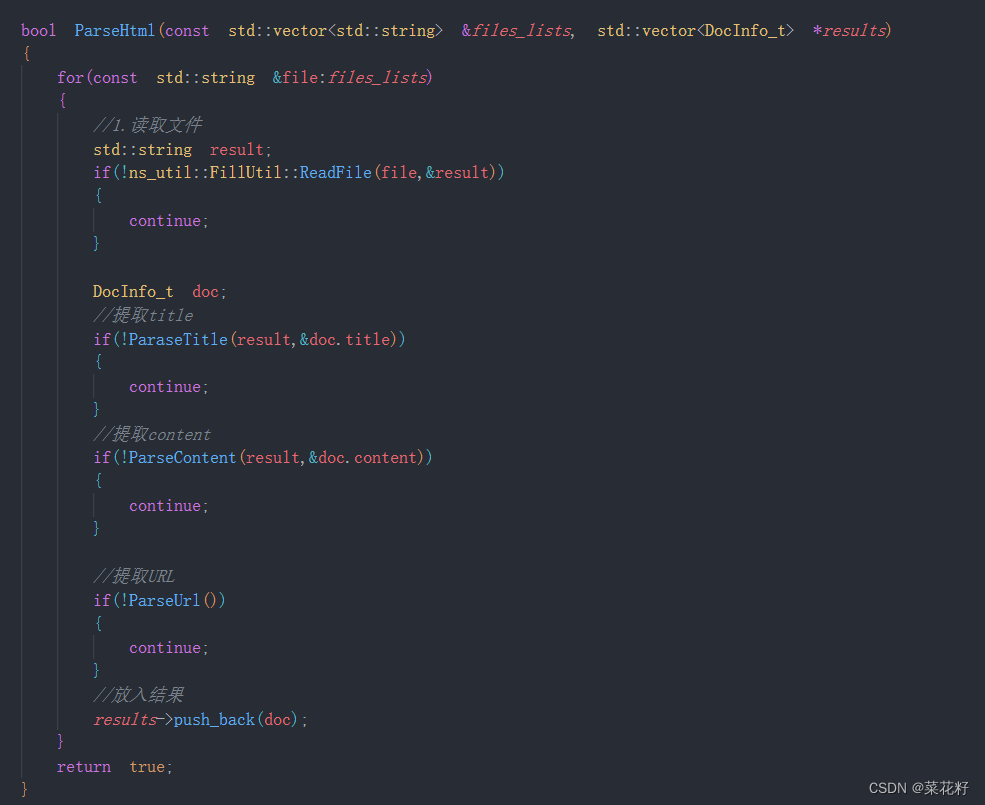
1.读取文件
由于读文件是非常常用的,所以我们将它封装在一个工具类里
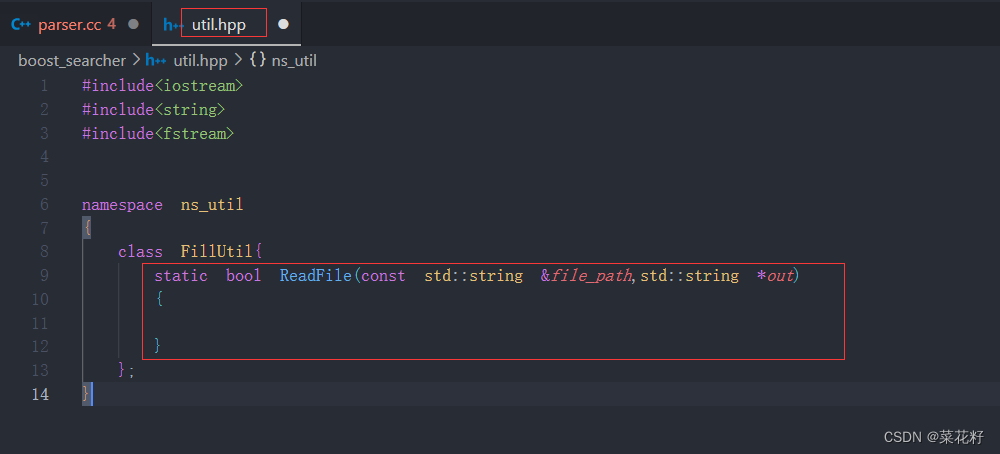

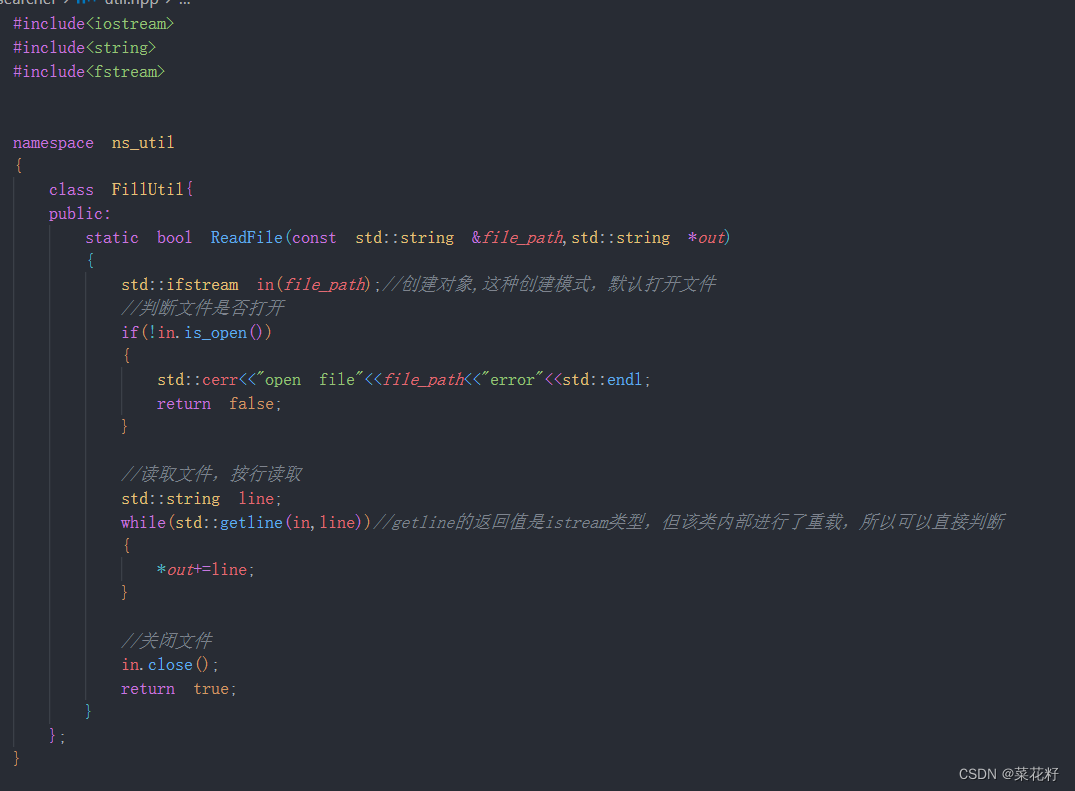
2.解析title
title的查找很简单,找到两个title之间的部分就行了。
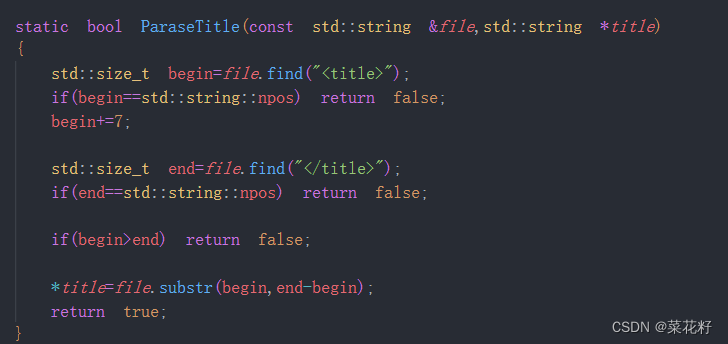
3.获取content
此处我们使用一个小技巧,定义两种状态:标签和内容。遍历整个文件,当遇到<时变为标签状态,此时不读取;当遇到>时,变为内容状态,此时开始读取。
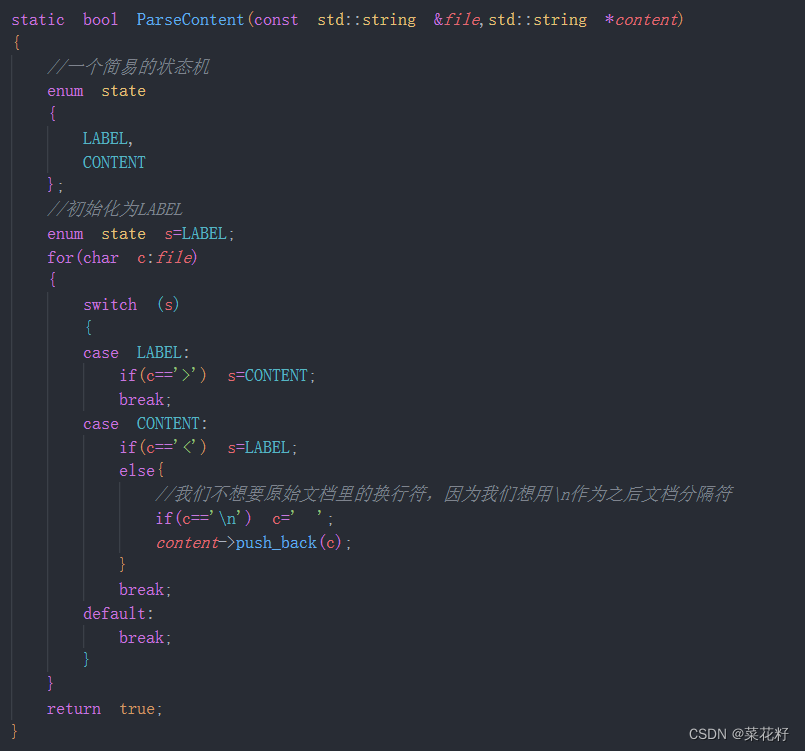
4.获取URL
boost库的官方文档是与我们下载后的html有路径对应关系。
官网链接:
我们下载的链接:

data/input/accumulators.html
所以,本质是把下载下来的boost库 doc/html拷贝到了data/input下。实际上我们要对我们当前获取的路径进行剪切和拼接,将data/input/accumulators.html变成https://www.boost.org/doc/libs/1_84_0/doc/html/accumulators.html。这样就能得到官网的URL了。
测试:由于数据很多,我们看一个就行了

测试完毕,没有问题。
四.SaveHtml实现
为了方便我们使用getline能一次读出来整个文件,对于文档内部使用\3分割,文档之间使用\n分割。例如:title\3content\3url\n 。

测试
测试完成,没问题。
五.完整源代码
parse.cc
#include <iostream>
#include <vector>
#include <string>
#include <boost/filesystem.hpp>
#include "util.hpp"
const std::string src_path = "data/input/"; // 要读取的文件路径
const std::string output = "data/raw_html/raw.txt"; // 存放处理后文件路径
typedef struct DocInfo
{
std::string title; // 文档标题
std::string content; // 文档内容
std::string url; // 文档路径
} DocInfo_t;
// const &:表示输入
//&:输入输出
//*:输出
bool EnumFile(const std::string &src_path, std::vector<std::string> *files_lists);
bool ParseHtml(const std::vector<std::string> &files_lists, std::vector<DocInfo_t> *results);
bool SaveHtml(const std::vector<DocInfo_t> &results, const std::string &output);
int main()
{
// 第一步:读取目标文件的路径和文件名
std::vector<std::string> files_lists;
if (!EnumFile(src_path, &files_lists))
{
std::cerr << "enum file error" << std::endl;
return 1;
}
// 第二步:把读取的文件按照格式进行解析
std::vector<DocInfo_t> results;
if (!ParseHtml(files_lists, &results))
{
std::cerr << "parse html error" << std::endl;
return 2;
}
// 第三步:把解析后的文件输出到output路径里
if (!SaveHtml(results, output))
{
std::cerr << "save html error" << std::endl;
return 3;
}
return 0;
}
bool EnumFile(const std::string &src_path, std::vector<std::string> *files_lists)
{
// 定义一个path对象,从当前路径开始查找
boost::filesystem::path root_path(src_path);
if (!boost::filesystem::exists(root_path)) // 如果当前路径不存在就返回false
{
std::cerr << src_path << "not exists" << std::endl;
return false;
}
// 定义一个空的迭代器,判断是否结束
boost::filesystem::recursive_directory_iterator end;
// 开始递归搜索
for (boost::filesystem::recursive_directory_iterator iter(root_path); iter != end; iter++)
{
// 如果不是普通文件,跳过
if (!boost::filesystem::is_regular_file(*iter))
{
continue;
}
// 如果不是以html结尾,跳过
if (iter->path().extension() != ".html")
{
continue;
}
// 测试代码,之后删除
// std::cout<<"debug"<<iter->path().string()<<std::endl;
// 将满足条件的网页的路径存入
files_lists->push_back(iter->path().string());
}
return true;
}
static bool ParaseTitle(const std::string &file, std::string *title)
{
std::size_t begin = file.find("<title>");
if (begin == std::string::npos)
return false;
begin += 7;
std::size_t end = file.find("</title>");
if (end == std::string::npos)
return false;
if (begin > end)
return false;
*title = file.substr(begin, end - begin);
return true;
}
static bool ParseContent(const std::string &file, std::string *content)
{
// 一个简易的状态机
enum state
{
LABEL,
CONTENT
};
// 初始化为LABEL
enum state s = LABEL;
for (char c : file)
{
switch (s)
{
case LABEL:
if (c == '>')
s = CONTENT;
break;
case CONTENT:
if (c == '<')
s = LABEL;
else
{
// 我们不想要原始文档里的换行符,因为我们想用\n作为之后文档分隔符
if (c == '\n')
c = ' ';
content->push_back(c);
}
break;
default:
break;
}
}
return true;
}
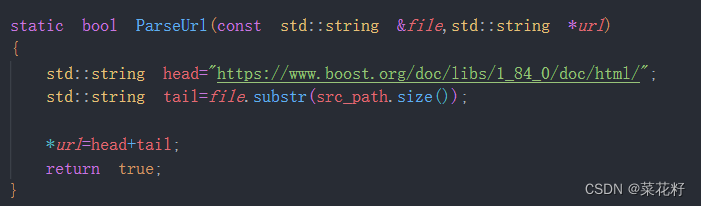
static bool ParseUrl(const std::string &file, std::string *url)
{
std::string head = "https://www.boost.org/doc/libs/1_84_0/doc/html/";
std::string tail = file.substr(src_path.size());
*url = head + tail;
return true;
}
bool ParseHtml(const std::vector<std::string> &files_lists, std::vector<DocInfo_t> *results)
{
for (const std::string &file : files_lists)
{
// 1.读取文件
std::string result;
if (!ns_util::FillUtil::ReadFile(file, &result))
{
continue;
}
DocInfo_t doc;
// 提取title
if (!ParaseTitle(result, &doc.title))
{
continue;
}
// 提取content
if (!ParseContent(result, &doc.content))
{
continue;
}
// 提取URL
if (!ParseUrl(file, &doc.url))
{
continue;
}
// 放入结果
results->push_back(std::move(doc));//细节;因为直接使用push_back会发生拷贝,为了提高效率使用move
// 测试代码
// std::cout<<"title:"<<doc.title<<std::endl;
// std::cout<<"content:"<<doc.content<<std::endl;
// std::cout<<"url:"<<doc.url<<std::endl;
// break;
}
return true;
}
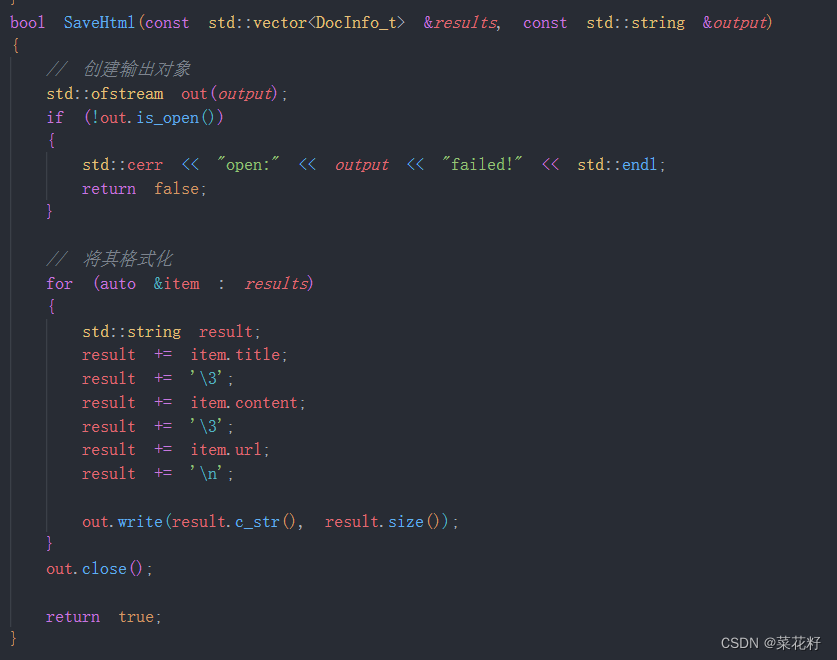
bool SaveHtml(const std::vector<DocInfo_t> &results, const std::string &output)
{
// 创建输出对象
std::ofstream out(output);
if (!out.is_open())
{
std::cerr << "open:" << output << "failed!" << std::endl;
return false;
}
// 将其格式化
for (auto &item : results)
{
std::string result;
result += item.title;
result += '\3';
result += item.content;
result += '\3';
result += item.url;
result += '\n';
out.write(result.c_str(), result.size());
}
out.close();
return true;
}
util.hpp
#include<iostream>
#include<string>
#include<fstream>
namespace ns_util
{
class FillUtil{
public:
static bool ReadFile(const std::string &file_path,std::string *out)
{
std::ifstream in(file_path);//创建对象,这种创建模式,默认打开文件
//判断文件是否打开
if(!in.is_open())
{
std::cerr<<"open file"<<file_path<<"error"<<std::endl;
return false;
}
//读取文件,按行读取
std::string line;
while(std::getline(in,line))//getline的返回值是istream类型,但该类内部进行了重载,所以可以直接判断
{
*out+=line;
}
//关闭文件
in.close();
return true;
}
};
}

















 1031
1031











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











