







 文章讨论了在搜索引擎中,由于关键词分词导致的文档重复问题,提出通过使用hash对倒排索引进行过滤,避免权重累加并保留唯一文档的方法。同时提及了增加测试用例和重新使用解析器获取新数据的重要性。
文章讨论了在搜索引擎中,由于关键词分词导致的文档重复问题,提出通过使用hash对倒排索引进行过滤,避免权重累加并保留唯一文档的方法。同时提及了增加测试用例和重新使用解析器获取新数据的重要性。
搜索结果重复问题
记得我们是如何进行查找的吗?首先把用户输入的关键词进行分词,然后再用每一个词去倒排索引进行匹配,把所有的倒排索引都找出来,然后根据权重进行降序排列,最后依次根据倒排索引里存的id,通过正排索引找到对应文档;把找到的所有文档变成一个json串,这样就算完成了一次查找。
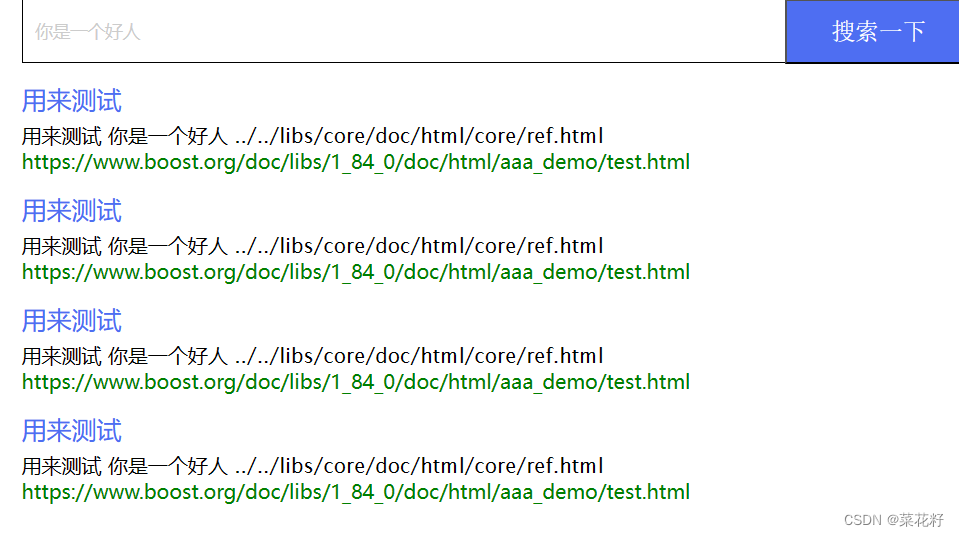
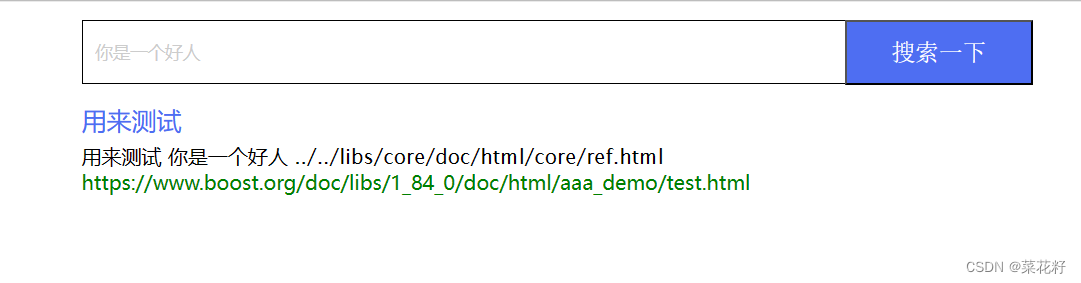
但问题是对用户关键词进行分词后,可能分词1里包含文档1,分词2里也有文档1,这样当我们将所有文档变成json串时,就会有两个文档1,很明显是造成了浪费的,我们需要把所有权重加起来,但只保留一份。
在data目录下增加一个测试用例
<html>
<head>
<title>用来测试</title>
<meta http-equiv="refresh" content="0;URL=../../libs/core/doc/html/core/ref.html">
</head>
<body>
你是一个好人
<a href=" ../../libs/core/doc/html/core/ref.html">../../libs/core/doc/html/core/ref.html</a>
</body>
</html>
注意:重新使用parser,获取新的数据。
解决方法
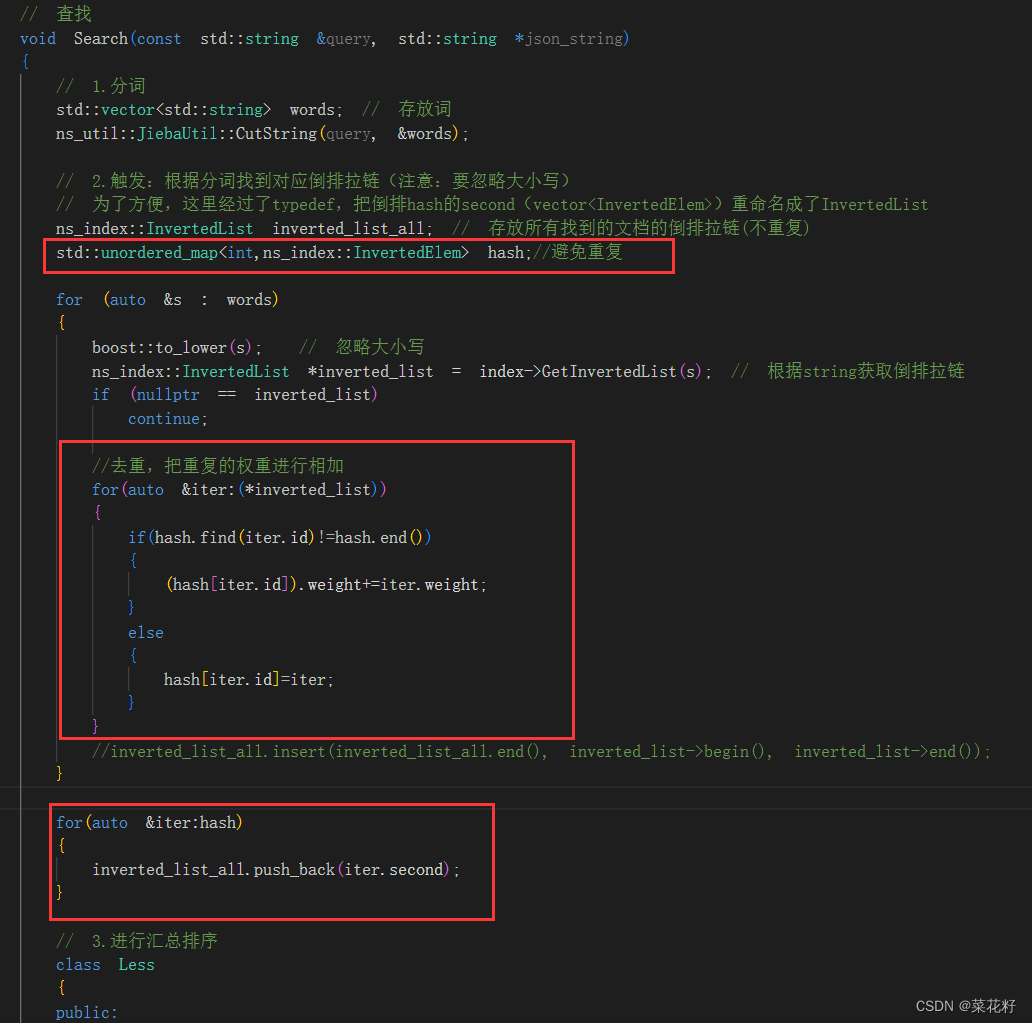
解决方案多种多样,这里我选择的是用一个hash进行过滤。创建一个hash,将所有得到的倒排索引都与该hash进行匹配,如果之前已经存在就将它们的权重相加,如果没有就放入。最后再将hash里的索引放入inverted_list_all里。

















 2067
2067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











