






超算第三次考核
shell入门教程
shell编程作业
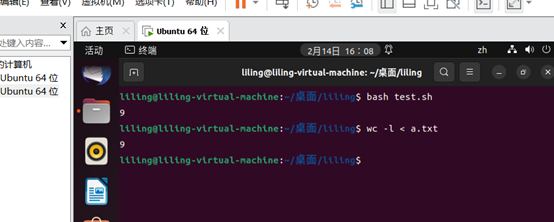
1.统计文件的行数
wc -l < a.txt
#!/bin/bash
i=0;
while read p;
do
i=$((i+1))
done < a.txt
echo $i结果如下:
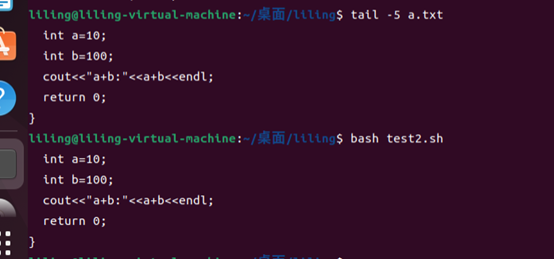
2.打印文件的最后5行
tail -5 a.txt
#!/bin/bash
end=$(wc -l a.txt)
start=$(( end - 5 + 1 ))
if[[ $start -lt 1 ]];
then
start=1
fi
sed -n "$start,$end p" a.txt结果如下:
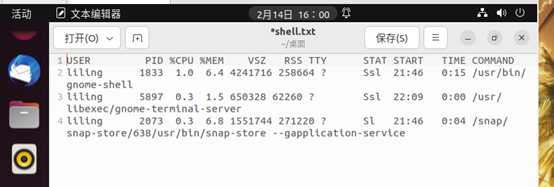
3.对后台CPU使用率的的监控,并将CPU利用率前三的进程信息存储到文件中
ps aux|head -n1 > shell.txt
ps aux|sort -nr -k3|head -n3 >> shell.txt
OpenMP
笔记见PDF
代码优化
1.矩阵乘法优化
①分块矩阵
#include<stdio.h>
#include<omp.h>
#include<stdlib.h>
#include<math.h>
const int N = 500;
double a[500][500];
double b[500][500];
double c_0[500][500];
double c[500][500];
int main(){
//---------------读取数据---------------------------//
int i,j,k;
FILE* f1;
FILE* f2;
FILE* out;
f1 = fopen("data_a.txt", "r");
f2 = fopen("data_b.txt", "r");
out = fopen("data_c.txt", "w");
for(int i=1;i<N;i++)
for(int j=1;j<N;j++){
fscanf(f1,"%lf",&a[i][j]);
fscanf(f2,"%lf",&b[i][j]);
}
//--------------------------------------------------//
double t0,t1;
double T0,T1;
//--------------初始矩阵乘法运算--------------------//
t0 = omp_get_wtime();
//mul
for(int i=1;i<N;i++)
for(int j=1;j<N;j++)
for(int k=1;k<N;k++)
c_0[i][j] += a[i][k]*b[k][j];
t1 = omp_get_wtime();
T0 = (t1-t0)*1000;
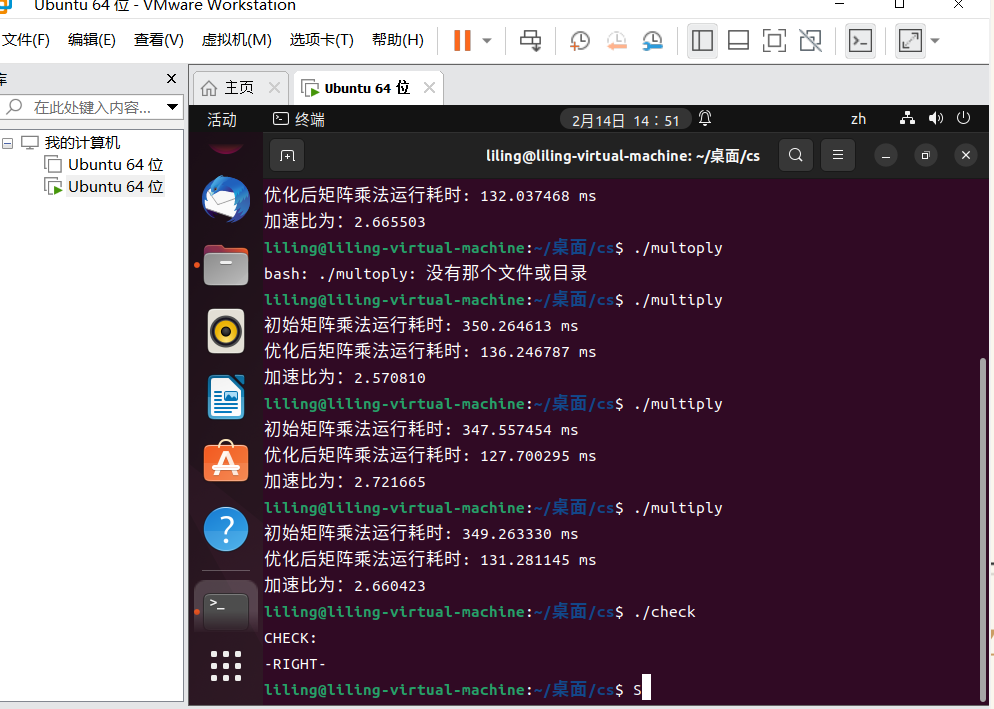
printf("初始矩阵乘法运行耗时: %f ms\n", T0);
//---------------------------------------------------//
t0 = omp_get_wtime();
//-----------优化矩阵乘法运算(需修改部分)-----------//
//--------------- c = a * b -------------------------//
//omp_set_num_threads(64) ;
#pragma omp parallel shared(N,a,b,c) private(i,j,k)
{
double r;
int n=4;
int T=N/n;
#pragma omp for schedule(dynamic)
for(int it=0;it<n;++it)
{
for(int kt=0;kt<n;++kt)
{
for(int jt=0;jt<n;++jt)
{
for( i=it*T;i<it*T+T;++i)
{
for( k=kt*T;k<kt*T+T;++k)
{
r=a[i][k];
for( j=jt*T;j<jt*T+T;++j)
{
c[i][j]+= r*b[k][j];
}
//c[i][j]=r;
}
}
}
}
}
//#pragma omp parallel for shared(N,a,b) //private(i,j,k)
for( ;i<N;++i)
{
for( ;k<N;++k)
{
r=a[i][k];
for( ;j<N;++j)
{
c[i][j] += r*b[k][j];
}
//c[i][j]=r;
}
}
}
//--------------------------------------------------//
t1 = omp_get_wtime();
T1 = (t1-t0)*1000;
printf("优化后矩阵乘法运行耗时: %f ms\n", T1);
printf("加速比为:%f\n",T0/T1);
//----------------数据输出---------------------------//
for(int i=1;i<N;i++)
for(int j=1;j<N;j++)
fprintf(out,"%lf\n",c[i][j]);
//---------------------------------------------------//
fclose(f1);
fclose(f2);
fclose(out);
}
②循环调整(将ijk转为ikj)
之前试过将循环转为kij,但是结果时错误的,应该时并行时私有变量的缘故,但是不明白如何修正,转为ikj没有这种错误
#include<stdio.h>
#include<omp.h>
#include<stdlib.h>
#include<math.h>
const int N = 500;
double a[500][500];
double b[500][500];
double c_0[500][500];
double c[500][500];
int main(){
//---------------读取数据---------------------------//
int i,j,k;
FILE* f1;
FILE* f2;
FILE* out;
f1 = fopen("data_a.txt", "r");
f2 = fopen("data_b.txt", "r");
out = fopen("data_c.txt", "w");
for(int i=1;i<N;i++)
for(int j=1;j<N;j++){
fscanf(f1,"%lf",&a[i][j]);
fscanf(f2,"%lf",&b[i][j]);
}
//--------------------------------------------------//
double t0,t1;
double T0,T1;
//--------------初始矩阵乘法运算--------------------//
t0 = omp_get_wtime();
//mul
for(int i=1;i<N;i++)
for(int j=1;j<N;j++)
for(int k=1;k<N;k++)
c_0[i][j] += a[i][k]*b[k][j];
t1 = omp_get_wtime();
T0 = (t1-t0)*1000;
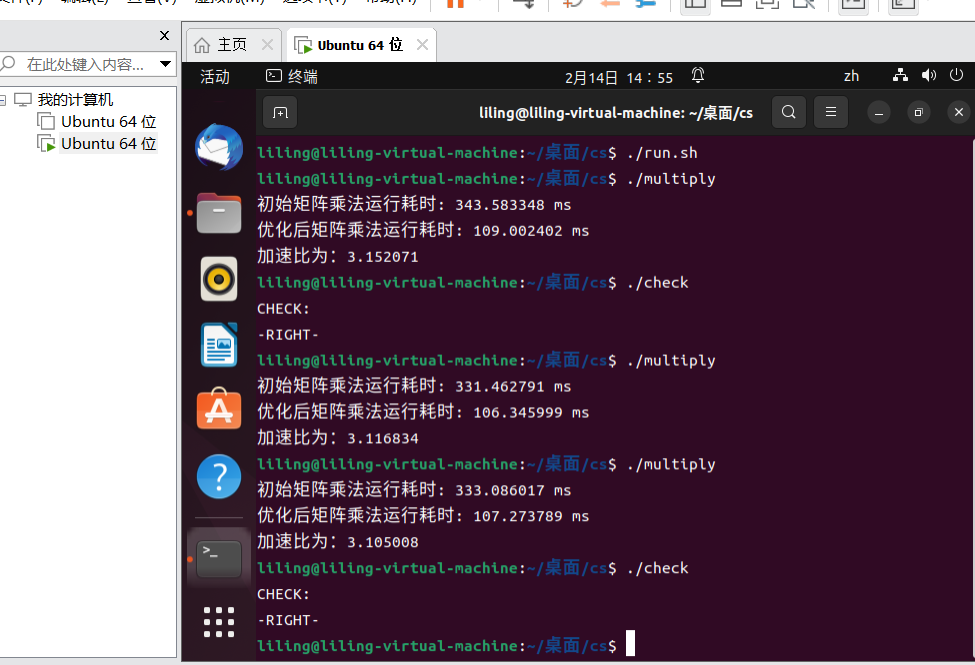
printf("初始矩阵乘法运行耗时: %f ms\n", T0);
//---------------------------------------------------//
t0 = omp_get_wtime();
//-----------优化矩阵乘法运算(需修改部分)-----------//
//--------------- c = a * b -------------------------//
#pragma omp parallel shared(N,a,b) private(i,j,k)
{
#pragma omp for schedule(dynamic)
for(int i=1;i<N;i++)
{
for(int k=1;k<N;k++)
{
double r=a[i][k];
for(int j=1;j<N;j++)
{
c[i][j] += r*b[k][j];
}
}
}
}
//--------------------------------------------------//
t1 = omp_get_wtime();
T1 = (t1-t0)*1000;
printf("优化后矩阵乘法运行耗时: %f ms\n", T1);
printf("加速比为:%f\n",T0/T1);
//----------------数据输出---------------------------//
for(int i=1;i<N;i++)
for(int j=1;j<N;j++)
fprintf(out,"%lf\n",c[i][j]);
//---------------------------------------------------//
fclose(f1);
fclose(f2);
fclose(out);
}
2.稀疏矩阵向量乘法
#include<stdio.h>
#include<omp.h>
int main()
{
double t0,t1;
double T0,T1;
const float val[]={10,20,30,40,50,60,70,80,100};
const float val1[]={10,20,30,40,50,60,70,80,100};
const int columnIndex[]={0,1,1,3,2,3,4,5,49};
const int columnIndex1[]={0,1,1,3,2,3,4,5,49};
const int rowIndex[]={0,2,4,7,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,9};
const int rowIndex1[]={0,2,4,7,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,8,9};
const static int numRows=50;
const static int SIZE=50;
float r[SIZE];
float r_sw[SIZE];
const float x[]={1,2,3,4};
int fail=0;
int i;
int j;
int rowStart;
int rowEnd;
//优化前代码
t0=omp_get_wtime();
for( i=0;i<numRows;i++)
{
rowStart = rowIndex[i];
rowEnd = rowIndex[i+1];
float sum = 0.0f;
for( j=rowStart;j<rowEnd;j++)
{
sum += val[j] * x[columnIndex[j]];
}
r[i] = sum;
}
t1=omp_get_wtime();
T0=(t1-t0)*1000;
printf("former:%lf ms\n",T0);
//优化后代码
t0=omp_get_wtime();
#pragma omp parallel num_threads(2)
{
#pragma omp parallel for schedule(dynamic,6)
for( i=0;i<numRows;i++)
{
rowStart = rowIndex1[i];
rowEnd = rowIndex1[i+1];
float sum = 0.0f;
for( j=rowStart;j<rowEnd;j++)
{
sum += val1[j] * x[columnIndex1[j]];
}
r_sw[i] = sum;
}
}
t1=omp_get_wtime();
T1=(t1-t0)*1000;
printf("later:%lf ms\n",T1);
printf("ratio:%lf\n",T0/T1);
for(int i = 0; i < SIZE; i++)
if(r_sw[i] != r[i])
fail = 1;
if(fail == 1)
printf("FAILED\n");
else
printf("PASS\n");
return 0;
}liling@liling-virtual-machine:~/桌面/cs$ gcc -fopenmp xishu.c
liling@liling-virtual-machine:~/桌面/cs$ ./a.out
former:0.000240 ms
later:0.075098 ms
ratio:0.003196
PASS
liling@liling-virtual-machine:~/桌面/cs$ ./a.out
former:0.000501 ms
later:0.058317 ms
ratio:0.008591
PASS
liling@liling-virtual-machine:~/桌面/cs$ ./a.out
former:0.000261 ms
later:0.066893 ms
ratio:0.003902
PASS
liling@liling-virtual-machine:~/桌面/cs$ ./a.out
former:0.000231 ms
later:0.056985 ms
ratio:0.004054
PASS
liling@liling-virtual-machine:~/桌面/cs$ ./a.out
former:0.000240 ms
later:0.058228 ms
ratio:0.004122
PASS
liling@liling-virtual-machine:~/桌面/cs$ ./a.out
former:0.000240 ms
later:0.096999 ms
ratio:0.002474
PASS
liling@liling-virtual-machine:~/桌面/cs$ ./a.out
former:0.000230 ms
later:0.107478 ms
ratio:0.002140
PASS优化失败,size的大小调试了很多,但是都比原来的慢,应该是负载的太均衡,但是不懂如何修正,修行功夫不够,希望能给予正确示范。
之前用的是4×6的矩阵,但是疑其过小,无法发挥出动态的优势就改为100×50
除此之外还有一个问题:在我还没有优化时,加速比竟达近2,了解到优化中数组要重开,不然会有访存问题,重开之后发现如果我向量也重开,那么结果就会是错的,奇怪明明是一样的向量一样的矩阵,为什么结果会错?















 953
953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









