 深度学习中的下采样与上采样原理及应用,
深度学习中的下采样与上采样原理及应用,




 本文详细阐述了下采样(包括池化和卷积层的下采样作用)和上采样(如插值、转置卷积和Up-Pooling)在深度学习中的概念、作用以及常用方式。着重比较了卷积层与池化层在下采样中的区别,并讨论了上采样在扩大特征图尺寸的应用。
本文详细阐述了下采样(包括池化和卷积层的下采样作用)和上采样(如插值、转置卷积和Up-Pooling)在深度学习中的概念、作用以及常用方式。着重比较了卷积层与池化层在下采样中的区别,并讨论了上采样在扩大特征图尺寸的应用。
目录
今天在看文章的时候,又看到了下采样这一名词,好的,在深度学习的过程中我常常见到它,它是啥来着?我怎么又忘记了?那还是做个笔记记录一下吧。
先来捋一下思路,什么是卷积啊?这个没忘吧,我对它的概念是什么呢?
(1)在卷积神经网络中,卷积是最基本的操作模块。
(2)在WHC的图像操作中,卷积就是输入图像区域和滤波器进行内积求和的过程。
那卷积与我要回顾的采样有什么关系呢?事实上,卷积就是下采样的一种方式。(所以,以后只要能想到卷积,就能回忆起来下采样了)
那就一起来讨论一下下采样和上采样吧!
1.下采样的相关知识
1.1下采样的概念?(什么是下采样?)
在我看来,将一张图片缩小,采用不同的方法将像素点合并从而获得更小分辨率的照片就叫做下采样,而池化(pooling)就是经典的下采样。
1.2下采样的作用?
下采样层有两个作用:
(1)减少计算量,防止过拟合;
(2)增大感受野,使得后面的卷积核能够学到更加全局的信息。
1.3下采样的常用方式?
下采样的方式主要有两种:
(1)采用stride为2的池化层,如Max-pooling和Average-pooling,目前常用的是Max-pooling,因为它计算简单而且能够更好的保留纹理特征;
(2)采用stride为2的卷积层,下采样的过程是一个信息损失的过程,而池化层是不可学习的,用stride为2的可学习卷积层来代替pooling可以得到更好的效果,当然同时也增加了一定的计算量。
在这里我有一个思考:为什么池化与卷积操作都能实现下采样的目的,或者说都能缩小特征图像的尺寸,那为什么不直接使用卷积层替代池化层,既能提取特征又能达到池化的效果呢?(下面是我找到的一些解释)
1. 首先,使用卷积层和池化层作为下采样层各自都具有一些优点:
(1)卷积层作为下采样层的优点:
①保留空间信息:卷积操作在滑动卷积核时会保留输入特征的空间结构和位置信息,因此在进行下采样时,卷积层可以更好地保留重要的空间信息;
②可学习的特征表示:卷积层通过卷积操作从输入特征中学习到具有代表性的特征表示,因此可以更好地适应不同的数据分布和任务需求。参数共享:卷积操作具有参数共享的特性,同一个卷积核在整个特征图上共享参数,因此可以减少模型的参数量,降低过拟合的风险;
③参数共享:卷积操作具有参数共享的特性,同一个卷积核在整个特征图上共享参数,因此可以减少模型的参数量,降低过拟合的风险。
(2)池化层作为下采样层的优点:
①减小计算量:池化操作简单且计算量较小,通过取池化窗口内的最大值或平均值来进行下采样,可以有效地减小特征图的尺寸,并降低后续层的计算量。
②降低过拟合:池化操作具有一定的平移不变性,可以减少特征图的维度并平滑特征,从而降低模型对数据的敏感度,减少过拟合的风险。
③提高网络的局部不变性:最大值池化操作可以提取局部最重要的特征,从而增强网络对于局部不变性的学习能力,使得网络对于局部变化具有更好的鲁棒性。
综上所述,卷积层和池化层各自具有一些优点,可以根据具体任务的需求和特征图的特点选择合适的下采样方法,或者将它们结合起来使用,以达到最佳的性能和效率。
2.其次,二者本身的主要作用(侧重点)就不同
池化层和卷积层在实现特征图像的下采样的主要作用和方式有所不同:
(1)卷积层的主要作用是通过卷积操作提取特征,而不是专门用来下采样。卷积操作通过滑动卷积核在特征图上提取局部信息,得到输出特征图。虽然卷积操作通常会使得输出特征图尺寸略微减小(取决于步幅和边界填充的设置),但它的主要作用是保留输入特征的空间结构和位置信息,并提取特征用于后续的任务。
(2)池化层的主要作用是进行下采样,以减小特征图的尺寸,并且减少计算量。池化操作通常使用最大值池化或平均值池化,在每个池化窗口内取最大值或平均值作为输出,从而将特征图像的尺寸减小。池化层的主要目的是在保留重要信息的同时降低特征图的维度,使得后续的神经网络模型更加高效。
所以,尽管卷积层和池化层都可以实现特征图像的下采样,但它们的作用不同,各有优势。直接使用卷积层替代池化层虽然可以达到一定的下采样效果,但可能会导致信息的丢失和计算量的增加。因此,在设计神经网络时,通常会根据任务的需要和特征图的尺寸进行选择和组合,以达到最佳的性能和效率。
2.上采样的相关知识
2.1上采样的概念?(什么是上采样?)
在我看来,将一张照片放大,在像素点之间根据放大倍数,以插值的形式插入像素值从而达到放大图像的目的。
2.2上采样的作用?
在卷积神经网络中,由于输入图像通过卷积神经网络(CNN)提取特征后,输出的尺寸往往会变小,而有时我们需要将图片恢复到原来的尺寸以便进行进一步的计算(如图像的语义分割),这时候就需要上采样操作帮助我们放大图像。
2.3上采样的常用方式?
上采样的方式主要有三种:
(1)插值:一般使用的是双线性插值,因为效果最好,虽然计算上比其他插值方式复杂,但是相对于卷积计算可以说不值一提,其他插值方式还有最近邻插值、三线性插值等;
(2)转置卷积又或是说反卷积(Transpose Conv):通过对输入feature map间隔填充0,再进行标准的卷积计算,可以使得输出feature map的尺寸比输入更大;是一种可学习的向上采样方式,里面的参数可以学习。(deconv(反卷积)和conv的区别在于在进行网络的前向传播和反向传播计算的时候作相反的计算)
(3)Up-Pooling :在max pooling时记录最大值的索引位置,然后在unpooling阶段时将对应的值放置到原先最大值位置,其余位置补0;没有参数,速度更快,采取给定策略上采样。(或者说,就是在池化过程中,记录下max-pooling在对应kernel中的坐标,在反池化过程中,将一个元素根据kernel进行放大,根据之前的坐标将元素填写进去,其他位置补0。)
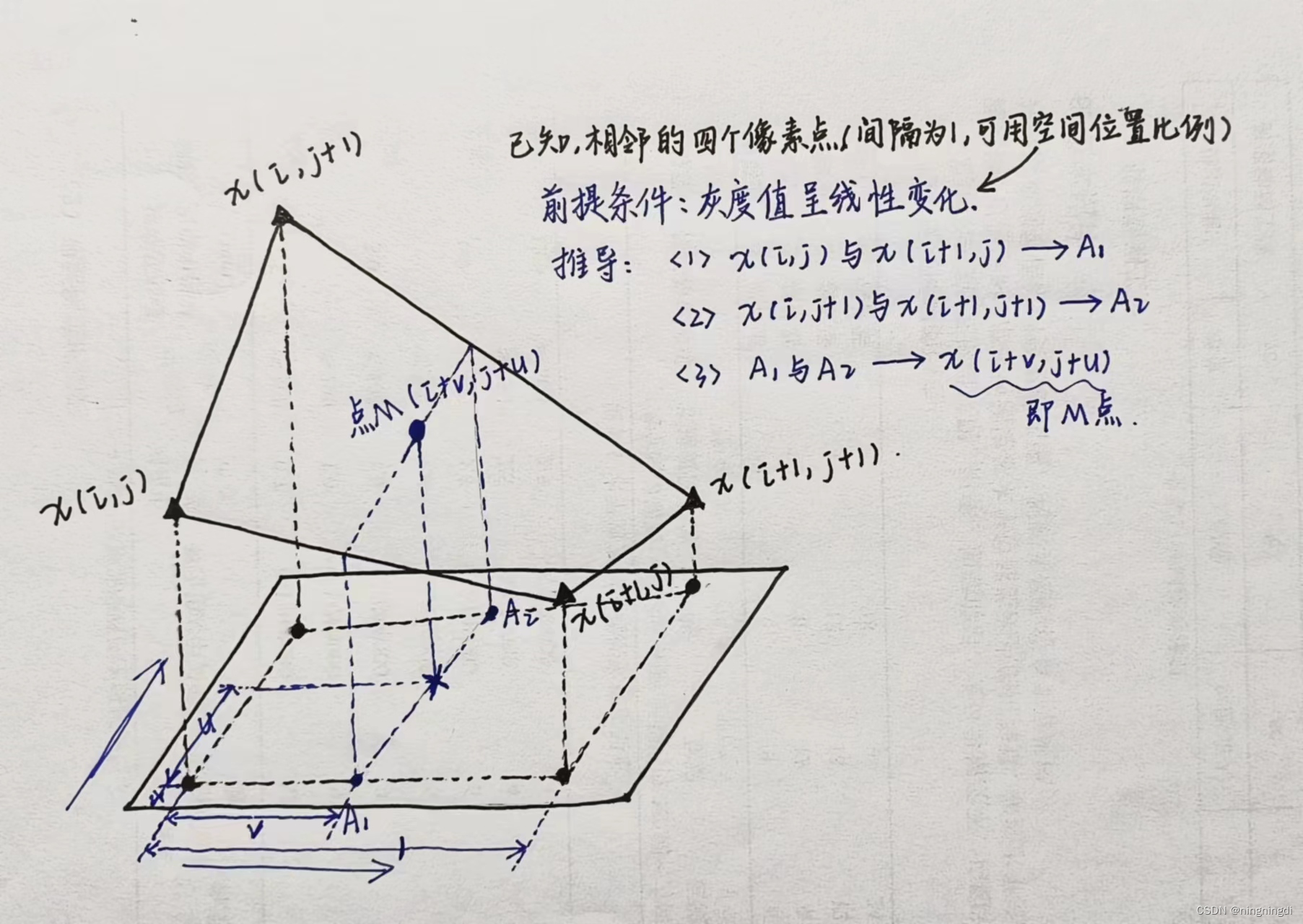
在这里,再回顾一下双线性插值的计算过程,即利用待求像素四个相邻像素的灰度在两个方向上作线性内插。回忆如下:
在最最后,特别声明,作为一名纯小白,渴望学习新知识,本文参考以下资料进行整合与总结,文章中可能出现理解不当的地方,若有所见解或异议可在下方评论,谢谢!一起进步吧!
引用及参考:

















 35万+
35万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









