预剪枝前
#include<iostream>
#include<fstream>
#include<istream>
#include<iomanip>
#include<sstream>
#include<stdio.h>
#include<vector>
#include<string>
#include<map>
#include<set>
#include<cmath>
#include<algorithm>
#include<time.h>
using namespace std;
class DataSet{
public:
vector<string> Attribute;
vector<vector<string>> Data;
map<string,vector<string>> AttributeValue;
DataSet();
DataSet(vector<vector<string>> data, vector<string> attribute);
void Connect();
};
DataSet::DataSet(){
Attribute={"花萼长度","花萼宽度","花瓣长度","花瓣宽度"};
}
DataSet::DataSet(vector<vector<string>> data, vector<string> attribute){
Data=data;
Attribute=attribute;
Connect();
}
void DataSet::Connect(){
if(Data.empty()) return;
vector<vector<string>> attribute;
vector<string> TempAttribute = Attribute;
TempAttribute.push_back("类别");
attribute.resize(TempAttribute.size());
for(int i=0;i<Data[0].size();i++){
for(int j=0;j<Data.size();j++){
attribute[i].push_back(Data[j][i]);
}
AttributeValue[TempAttribute[i]]=attribute[i];
}
}
void Read_csv(DataSet &dataSet,string fname){
ifstream csv_data(fname, ios::in);
if (!csv_data.is_open()){
cout << "Error: opening file fail" << endl;
exit(1);
}
else{
string line;
vector<string> words;
string word;
getline(csv_data, line);
istringstream sin;
while (getline(csv_data, line))
{
word.clear();
words.clear();
sin.clear();
sin.str(line);
while (getline(sin, word, ',')){
words.push_back(word);
}
dataSet.Data.push_back(words);
}
csv_data.close();
dataSet.Data.pop_back();
}
dataSet.Connect();
}
class Node{
public:
Node(){
isLeaf=false;
isRoot=false;
}
vector<double> MidValue;
bool isLeaf;
bool isRoot;
string node_Attribute;
double Mid;
string Attribute;
vector<Node*> ChildrenNode;
};
class DecisionTree{
public:
void TreeGenerate(DataSet &dataSet,Node* Father);
double CalcEntropy(DataSet &dataSet);
double CalcInfoGain(double midValue,DataSet& dataSet,string Value);
vector<double> FindMidValue(DataSet &dataSet);
map<string,double> FindBestInfoGain(DataSet &dataSet);
map<string,int> CountTimes(DataSet &dataSet);
void DestoryDecisionTree(Node* node);
vector<string> Prediction(DataSet &dataSet,Node *node);
};
void DecisionTree::TreeGenerate(DataSet &dataSet,Node* Father){
Node *newNode=new Node;
Father->ChildrenNode.push_back(newNode);
vector<double> newMid = FindMidValue(dataSet);
newNode->MidValue = newMid;
bool isSame=true;
string curAttr=dataSet.AttributeValue["类别"][0];
for(int i=0;i<dataSet.AttributeValue["类别"].size();i++){
if(dataSet.AttributeValue["类别"][i]!=curAttr){
isSame=false;
break;
}
}
if(isSame){
newNode->isLeaf=true;
newNode->node_Attribute=curAttr;
return ;
}
isSame = true;
for (int i = 0; i < dataSet.Attribute.size(); i++) {
string a = dataSet.AttributeValue[dataSet.Attribute[i]][0];
if (stod(a) > Father->MidValue[i]) {
for (int j = 1; j < dataSet.Data.size(); j++) {
if (stod(dataSet.AttributeValue[dataSet.Attribute[i]][j]) <= Father->MidValue[i]) {
isSame = false;
break;
}
}
}
else {
for (int j = 1; j < dataSet.Data.size(); j++) {
if (stod(dataSet.AttributeValue[dataSet.Attribute[i]][j]) > Father->MidValue[i]) {
isSame = false;
break;
}
}
}
if(isSame==false) break;
}
if(dataSet.Attribute.empty()||isSame==true){
newNode->isLeaf=true;
map<string,int> mp=CountTimes(dataSet);
int maxTimes=-1;
string maxValue;
for(auto i=mp.begin();i!=mp.end();i++){
if(i->second>maxTimes){
maxValue=i->first;
maxTimes=i->second;
}
}
newNode->node_Attribute=maxValue;
return;
}
map<string,double> BestAttributeMap=FindBestInfoGain(dataSet);
string BestAttribute=BestAttributeMap.begin()->first;
newNode->Attribute = BestAttribute;
vector<string> TempAttribute;
TempAttribute.push_back(BestAttribute);
vector<string> TempValue=dataSet.AttributeValue[BestAttribute];
vector<string> TempAttr = dataSet.AttributeValue["类别"];
vector<vector<string>> TempData(TempValue.size());
for(int i=0;i<TempValue.size();i++){
TempData[i].push_back(TempValue[i]);
TempData[i].push_back(TempAttr[i]);
}
DataSet d(TempData,TempAttribute);
vector<double> MidArray=FindMidValue(d);
double bestmid = MidArray[0];
newNode->Mid = bestmid;
vector<vector<vector<string>>> NextData(2);
for (int i = 0; i < dataSet.Data.size(); i++) {
if (stod(dataSet.AttributeValue[BestAttribute][i]) < bestmid) {
NextData[0].push_back(dataSet.Data[i]);
}
else {
NextData[1].push_back(dataSet.Data[i]);
}
}
for (int i = 0; i < NextData.size(); i++) {
Node* newChild = new Node;
if (NextData[i].empty()){
newNode->ChildrenNode.push_back(newChild);
newChild->isLeaf = true;
map<string, int> mp = CountTimes(dataSet);
int maxTimes = -1;
string maxValue;
for (auto i = mp.begin(); i != mp.end(); i++) {
if (i->second > maxTimes) {
maxValue = i->first;
maxTimes = i->second;
}
}
newChild->node_Attribute = maxValue;
return ;
}
else {
delete newChild;
DataSet NewDataSet(NextData[i], dataSet.Attribute);
TreeGenerate(NewDataSet, newNode);
}
}
}
vector<string> DecisionTree::Prediction(DataSet &dataSet,Node *node) {
vector<string> ClassArray;
if (node->isLeaf) {
ClassArray.push_back(node->node_Attribute);
return ClassArray;
}
else{
for (int i = 0; i < dataSet.Data.size(); i++) {
vector<string> oneClass;
vector<vector<string>> tempData;
tempData.push_back(dataSet.Data[i]);
DataSet d(tempData, dataSet.Attribute);
if (stod(dataSet.AttributeValue[node->Attribute][i]) < node->Mid || node->isRoot) {
oneClass=Prediction(d, node->ChildrenNode[0]);
}
else{
oneClass=Prediction(d, node->ChildrenNode[1]);
}
for(int j=0;j<oneClass.size();j++)
ClassArray.push_back(oneClass[j]);
}
}
return ClassArray;
}
map<string,int>DecisionTree::CountTimes(DataSet &dataSet){
map<string,int> ClassCount;
vector<string> classList=dataSet.AttributeValue["类别"];
for(int i=0;i<classList.size();i++){
if(!ClassCount.count(classList[i])){
ClassCount.insert({classList[i],0});
}
ClassCount[classList[i]]++;
}
return ClassCount;
}
void DecisionTree::DestoryDecisionTree(Node* node) {
if (!node->isLeaf)
{
for (size_t i = 0; i < node->ChildrenNode.size(); i++)
{
DestoryDecisionTree(node->ChildrenNode[i]);
}
}
delete node;
node = nullptr;
}
double DecisionTree::CalcEntropy(DataSet &dataSet){
int sum=dataSet.Data.size();
map<string,int> ClassCount=CountTimes(dataSet);
vector<string> classList=dataSet.AttributeValue["类别"];
double entropy=0;
for(auto item = ClassCount.begin();item!=ClassCount.end();item++){
double p=(double)item->second/sum;
if(p==0) entropy-=0;
else entropy-=p*log(p)/log(2);
}
return entropy;
}
vector<double> DecisionTree::FindMidValue(DataSet &dataSet){
vector<double> bestMid;
for(int i=0;i<dataSet.Attribute.size();i++){
vector<string> valueString=dataSet.AttributeValue[dataSet.Attribute[i]];
vector<double> valueDouble;
for(int j=0;j<valueString.size();j++){
valueDouble.push_back(stod(valueString[j]));
}
sort(valueDouble.begin(),valueDouble.end());
vector<double> midArray;
for(int j=0;j<valueDouble.size()-1;j++){
midArray.push_back((valueDouble[j]+valueDouble[j+1])/2);
}
double bestmid;
if(midArray.empty()) bestmid=valueDouble[0];
else bestmid=midArray[0];
double maxmidEntrophy=0;
for(int j=0;j<midArray.size();j++){
double gain=CalcInfoGain(midArray[j],dataSet,dataSet.Attribute[i]);
if(gain>=maxmidEntrophy){
maxmidEntrophy=gain;
bestmid=midArray[j];
}
}
bestMid.push_back(bestmid);
}
return bestMid;
}
double DecisionTree::CalcInfoGain(double midValue,DataSet& dataSet,string Value){
vector<vector<string>> leftData;
vector<vector<string>> rightData;
int leftCount=0;
int sum=dataSet.Data.size();
double mid=midValue;
for(int i=0;i<dataSet.Data.size();i++){
if(stod(dataSet.AttributeValue[Value][i])<=mid){
leftCount++;
leftData.push_back(dataSet.Data[i]);
}else{
rightData.push_back(dataSet.Data[i]);
}
}
DataSet d1(leftData,dataSet.Attribute);
DataSet d2(rightData,dataSet.Attribute);
double gain=CalcEntropy(dataSet)-leftCount*CalcEntropy(d1)/sum-(sum-leftCount)*CalcEntropy(d2)/sum;
return gain;
}
map<string,double> DecisionTree::FindBestInfoGain(DataSet &dataSet){
double maxgain=0;
string bestAttri;
vector<double> middle=FindMidValue(dataSet);
for(int i=0;i<dataSet.Attribute.size();i++){
double mid=middle[i];
double gain=CalcInfoGain(mid,dataSet,dataSet.Attribute[i]);
if(gain>maxgain){
maxgain=gain;
bestAttri=dataSet.Attribute[i];
}
}
map<string,double> mp;
mp[bestAttri]=maxgain;
return mp;
}
int main()
{
clock_t start = clock();
DataSet dataSet;
string fname = "iris.csv";
Read_csv(dataSet,fname);
DecisionTree dt;
Node* RootNode = new Node;
map<string, double> BestAttributeMap = dt.FindBestInfoGain(dataSet);
string BestAttribute = BestAttributeMap.begin()->first;
RootNode->Attribute = BestAttribute;
vector<string> TempAttribute;
TempAttribute.push_back(BestAttribute);
vector<string> TempValue = dataSet.AttributeValue[BestAttribute];
vector<string> TempAttr = dataSet.AttributeValue["类别"];
vector<vector<string>> TempData(TempValue.size());
for (int i = 0; i < TempValue.size(); i++) {
TempData[i].push_back(TempValue[i]);
TempData[i].push_back(TempAttr[i]);
}
DataSet d(TempData, TempAttribute);
vector<double> MidArray = dt.FindMidValue(d);
vector<double> Midd = dt.FindMidValue(dataSet);
RootNode->MidValue = Midd;
double bestmid = MidArray[0];
RootNode->Mid = bestmid;
RootNode->isRoot=true;
dt.TreeGenerate(dataSet, RootNode);
DataSet dataSet_pre;
string fname_pre;
fname_pre = "iris_pre.csv";
Read_csv(dataSet_pre, fname_pre);
vector<string> pre;
pre=dt.Prediction(dataSet_pre, RootNode);
double accuracy_score=0;
int count_accuracy=0;
for(int i=0;i<pre.size();i++){
if(pre[i]==dataSet_pre.AttributeValue["类别"][i]) count_accuracy++;
}
accuracy_score=count_accuracy/pre.size();
cout<<fixed<<setprecision(2)<<"decision_tree's accuracy_score:"<<accuracy_score*100<<"%"<<endl;
dt.DestoryDecisionTree(RootNode);
clock_t finish = clock();
cout<<"(Before)The time cost is:"<<double(finish - start) / CLOCKS_PER_SEC<<endl;
return 0;
}
运行结果
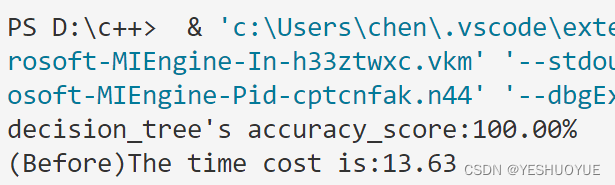
预剪枝后
#include<iostream>
#include<fstream>
#include<istream>
#include<iomanip>
#include<sstream>
#include<stdio.h>
#include<vector>
#include<string>
#include<map>
#include<set>
#include<cmath>
#include<algorithm>
#include<time.h>
using namespace std;
class DataSet{
public:
vector<string> Attribute;
vector<vector<string>> Data;
map<string,vector<string>> AttributeValue;
DataSet();
DataSet(vector<vector<string>> data, vector<string> attribute);
void Connect();
};
DataSet::DataSet(){
Attribute={"花萼长度","花萼宽度","花瓣长度","花瓣宽度"};
}
DataSet::DataSet(vector<vector<string>> data, vector<string> attribute){
Data=data;
Attribute=attribute;
Connect();
}
void DataSet::Connect(){
if(Data.empty()) return;
vector<vector<string>> attribute;
vector<string> TempAttribute = Attribute;
TempAttribute.push_back("类别");
attribute.resize(TempAttribute.size());
for(int i=0;i<Data[0].size();i++){
for(int j=0;j<Data.size();j++){
attribute[i].push_back(Data[j][i]);
}
AttributeValue[TempAttribute[i]]=attribute[i];
}
}
void Read_csv(DataSet &dataSet,string fname){
ifstream csv_data(fname, ios::in);
if (!csv_data.is_open()){
cout << "Error: opening file fail" << endl;
exit(1);
}
else{
string line;
vector<string> words;
string word;
getline(csv_data, line);
istringstream sin;
while (getline(csv_data, line))
{
word.clear();
words.clear();
sin.clear();
sin.str(line);
while (getline(sin, word, ',')){
words.push_back(word);
}
dataSet.Data.push_back(words);
}
csv_data.close();
dataSet.Data.pop_back();
}
dataSet.Connect();
}
class Node{
public:
Node(){
isLeaf=false;
isRoot=false;
nodeAccuracy=0;
}
vector<double> MidValue;
bool isLeaf;
bool isRoot;
string node_Attribute;
double Mid;
string Attribute;
vector<Node*> ChildrenNode;
double nodeAccuracy;
};
class DecisionTree{
public:
void TreeGenerate(DataSet &dataSet,Node* Father);
double CalcEntropy(DataSet &dataSet);
double CalcInfoGain(double midValue,DataSet& dataSet,string Value);
double AccuracyRate(DataSet &dataSet, Node* node);
vector<double> FindMidValue(DataSet &dataSet);
map<string,double> FindBestInfoGain(DataSet &dataSet);
map<string,int> CountTimes(DataSet &dataSet);
void DestoryDecisionTree(Node* node);
vector<string> Prediction(DataSet &dataSet,Node *node);
};
void DecisionTree::TreeGenerate(DataSet &dataSet,Node* Father){
Node *newNode=new Node;
Father->ChildrenNode.push_back(newNode);
vector<double> newMid = FindMidValue(dataSet);
newNode->MidValue = newMid;
bool isSame=true;
string curAttr=dataSet.AttributeValue["类别"][0];
for(int i=0;i<dataSet.AttributeValue["类别"].size();i++){
if(dataSet.AttributeValue["类别"][i]!=curAttr){
isSame=false;
break;
}
}
if(isSame){
newNode->isLeaf=true;
newNode->node_Attribute=curAttr;
return ;
}
isSame = true;
for (int i = 0; i < dataSet.Attribute.size(); i++) {
string a = dataSet.AttributeValue[dataSet.Attribute[i]][0];
if (stod(a) > Father->MidValue[i]) {
for (int j = 1; j < dataSet.Data.size(); j++) {
if (stod(dataSet.AttributeValue[dataSet.Attribute[i]][j]) <= Father->MidValue[i]) {
isSame = false;
break;
}
}
}
else {
for (int j = 1; j < dataSet.Data.size(); j++) {
if (stod(dataSet.AttributeValue[dataSet.Attribute[i]][j]) > Father->MidValue[i]) {
isSame = false;
break;
}
}
}
if(isSame==false) break;
}
if(dataSet.Attribute.empty()||isSame==true){
newNode->isLeaf=true;
map<string,int> mp=CountTimes(dataSet);
int maxTimes=-1;
string maxValue;
for(auto i=mp.begin();i!=mp.end();i++){
if(i->second>maxTimes){
maxValue=i->first;
maxTimes=i->second;
}
}
newNode->node_Attribute=maxValue;
return;
}
map<string,double> BestAttributeMap=FindBestInfoGain(dataSet);
string BestAttribute=BestAttributeMap.begin()->first;
newNode->Attribute = BestAttribute;
vector<string> TempAttribute;
TempAttribute.push_back(BestAttribute);
vector<string> TempValue=dataSet.AttributeValue[BestAttribute];
vector<string> TempAttr = dataSet.AttributeValue["类别"];
vector<vector<string>> TempData(TempValue.size());
for(int i=0;i<TempValue.size();i++){
TempData[i].push_back(TempValue[i]);
TempData[i].push_back(TempAttr[i]);
}
DataSet d(TempData,TempAttribute);
vector<double> MidArray=FindMidValue(d);
double bestmid = MidArray[0];
newNode->Mid = bestmid;
vector<vector<vector<string>>> NextData(2);
for (int i = 0; i < dataSet.Data.size(); i++) {
if (stod(dataSet.AttributeValue[BestAttribute][i]) < bestmid) {
NextData[0].push_back(dataSet.Data[i]);
}
else {
NextData[1].push_back(dataSet.Data[i]);
}
}
for (int i = 0; i < NextData.size(); i++) {
Node* newChild = new Node;
if (NextData[i].empty()){
newNode->ChildrenNode.push_back(newChild);
newChild->isLeaf = true;
map<string,int>mp = CountTimes(dataSet);
int maxTimes = -1;
string maxValue;
for (auto i = mp.begin(); i != mp.end(); i++) {
if (i->second > maxTimes) {
maxValue = i->first;
maxTimes = i->second;
}
}
newChild->node_Attribute = maxValue;
return ;
}
else {
DataSet NewDataSet(NextData[i], dataSet.Attribute);
map<string,int> mp=CountTimes(dataSet);
int maxTimes=-1;
string maxValue;
for(auto i=mp.begin();i!=mp.end();i++){
if(i->second>maxTimes){
maxValue=i->first;
maxTimes=i->second;
}
}
newNode->node_Attribute=maxValue;
mp = CountTimes(NewDataSet);
maxTimes = -1;
maxValue="";
for (auto i = mp.begin(); i != mp.end(); i++) {
if (i->second > maxTimes) {
maxValue = i->first;
maxTimes = i->second;
}
}
newChild->node_Attribute = maxValue;
if(AccuracyRate(dataSet,newNode)>AccuracyRate(NewDataSet,newChild)){
newNode->isLeaf=true;
delete newChild;
return;
}
delete newChild;
TreeGenerate(NewDataSet, newNode);
}
}
}
double DecisionTree::AccuracyRate(DataSet &dataSet, Node* node){
vector<string> ClassArray=dataSet.AttributeValue["类别"];
string NodeAttr=node->node_Attribute;
int count=0;
for(int i=0;i<ClassArray.size();i++){
if(NodeAttr==ClassArray[i]) count++;
}
return 1.0*count/ClassArray.size();
}
vector<string> DecisionTree::Prediction(DataSet &dataSet,Node *node) {
vector<string> ClassArray;
if (node->isLeaf) {
ClassArray.push_back(node->node_Attribute);
return ClassArray;
}
else{
for (int i = 0; i < dataSet.Data.size(); i++) {
vector<string> oneClass;
vector<vector<string>> tempData;
tempData.push_back(dataSet.Data[i]);
DataSet d(tempData, dataSet.Attribute);
if (stod(dataSet.AttributeValue[node->Attribute][i]) < node->Mid || node->isRoot) {
oneClass=Prediction(d, node->ChildrenNode[0]);
}
else{
oneClass=Prediction(d, node->ChildrenNode[1]);
}
for(int j=0;j<oneClass.size();j++)
ClassArray.push_back(oneClass[j]);
}
}
return ClassArray;
}
map<string,int>DecisionTree::CountTimes(DataSet &dataSet){
map<string,int> ClassCount;
vector<string> classList=dataSet.AttributeValue["类别"];
for(int i=0;i<classList.size();i++){
if(!ClassCount.count(classList[i])){
ClassCount.insert({classList[i],0});
}
ClassCount[classList[i]]++;
}
return ClassCount;
}
void DecisionTree::DestoryDecisionTree(Node* node) {
if (!node->isLeaf)
{
for (size_t i = 0; i < node->ChildrenNode.size(); i++)
{
DestoryDecisionTree(node->ChildrenNode[i]);
}
}
delete node;
node = nullptr;
}
double DecisionTree::CalcEntropy(DataSet &dataSet){
int sum=dataSet.Data.size();
map<string,int> ClassCount=CountTimes(dataSet);
vector<string> classList=dataSet.AttributeValue["类别"];
double entropy=0;
for(auto item = ClassCount.begin();item!=ClassCount.end();item++){
double p=(double)item->second/sum;
if(p==0) entropy-=0;
else entropy-=p*log(p)/log(2);
}
return entropy;
}
vector<double> DecisionTree::FindMidValue(DataSet &dataSet){
vector<double> bestMid;
for(int i=0;i<dataSet.Attribute.size();i++){
vector<string> valueString=dataSet.AttributeValue[dataSet.Attribute[i]];
vector<double> valueDouble;
for(int j=0;j<valueString.size();j++){
valueDouble.push_back(stod(valueString[j]));
}
sort(valueDouble.begin(),valueDouble.end());
vector<double> midArray;
for(int j=0;j<valueDouble.size()-1;j++){
midArray.push_back((valueDouble[j]+valueDouble[j+1])/2);
}
double bestmid;
if(midArray.empty()) bestmid=valueDouble[0];
else bestmid=midArray[0];
double maxmidEntrophy=0;
for(int j=0;j<midArray.size();j++){
double gain=CalcInfoGain(midArray[j],dataSet,dataSet.Attribute[i]);
if(gain>=maxmidEntrophy){
maxmidEntrophy=gain;
bestmid=midArray[j];
}
}
bestMid.push_back(bestmid);
}
return bestMid;
}
double DecisionTree::CalcInfoGain(double midValue,DataSet& dataSet,string Value){
vector<vector<string>> leftData;
vector<vector<string>> rightData;
int leftCount=0;
int sum=dataSet.Data.size();
double mid=midValue;
for(int i=0;i<dataSet.Data.size();i++){
if(stod(dataSet.AttributeValue[Value][i])<=mid){
leftCount++;
leftData.push_back(dataSet.Data[i]);
}else{
rightData.push_back(dataSet.Data[i]);
}
}
DataSet d1(leftData,dataSet.Attribute);
DataSet d2(rightData,dataSet.Attribute);
double gain=CalcEntropy(dataSet)-leftCount*CalcEntropy(d1)/sum-(sum-leftCount)*CalcEntropy(d2)/sum;
return gain;
}
map<string,double> DecisionTree::FindBestInfoGain(DataSet &dataSet){
double maxgain=0;
string bestAttri;
vector<double> middle=FindMidValue(dataSet);
for(int i=0;i<dataSet.Attribute.size();i++){
double mid=middle[i];
double gain=CalcInfoGain(mid,dataSet,dataSet.Attribute[i]);
if(gain>maxgain){
maxgain=gain;
bestAttri=dataSet.Attribute[i];
}
}
map<string,double> mp;
mp[bestAttri]=maxgain;
return mp;
}
int main()
{
clock_t start = clock();
DataSet dataSet;
string fname = "iris.csv";
Read_csv(dataSet,fname);
DecisionTree dt;
Node* RootNode = new Node;
map<string, double> BestAttributeMap = dt.FindBestInfoGain(dataSet);
string BestAttribute = BestAttributeMap.begin()->first;
RootNode->Attribute = BestAttribute;
vector<string> TempAttribute;
TempAttribute.push_back(BestAttribute);
vector<string> TempValue = dataSet.AttributeValue[BestAttribute];
vector<string> TempAttr = dataSet.AttributeValue["类别"];
vector<vector<string>> TempData(TempValue.size());
for (int i = 0; i < TempValue.size(); i++) {
TempData[i].push_back(TempValue[i]);
TempData[i].push_back(TempAttr[i]);
}
DataSet d(TempData, TempAttribute);
vector<double> MidArray = dt.FindMidValue(d);
vector<double> Midd = dt.FindMidValue(dataSet);
RootNode->MidValue = Midd;
double bestmid = MidArray[0];
RootNode->Mid = bestmid;
RootNode->isRoot=true;
dt.TreeGenerate(dataSet, RootNode);
DataSet dataSet_pre;
string fname_pre;
fname_pre = "iris_pre.csv";
Read_csv(dataSet_pre, fname_pre);
vector<string> pre;
pre=dt.Prediction(dataSet_pre, RootNode);
double accuracy_score=0;
int count_accuracy=0;
for(int i=0;i<pre.size();i++){
if(pre[i]==dataSet_pre.AttributeValue["类别"][i]) count_accuracy++;
}
accuracy_score=count_accuracy/pre.size();
cout<<fixed<<setprecision(2)<<"decision_tree's accuracy_score:"<<accuracy_score*100<<"%"<<endl;
dt.DestoryDecisionTree(RootNode);
clock_t finish = clock();
cout<<"(After)The time cost is:"<<double(finish - start) / CLOCKS_PER_SEC<<endl;
return 0;
}
运行结果
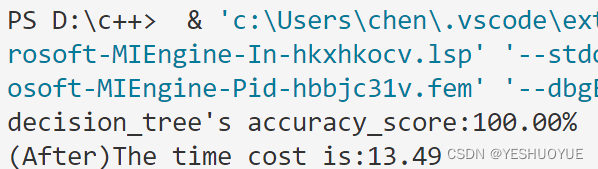























 279
279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









