






K-means聚类算法——鸢尾花识别
这次的代码还有一定的问题要优化,预测的准确率有待提高,我们实验最好结果是98的测试集准确率。正常只有30左右。
一、选题分析
鸢尾花识别项目基于经典的K-means聚类算法,旨在通过特征值输入来预测鸢尾花的种类。选题的具体分析如下:
背景
鸢尾花数据集是一个经典的数据集,广泛应用于分类和聚类算法的教学和研究中。该数据集包含三类鸢尾花:Setosa、Versicolor和Virginica,每类各50个样本,每个样本有4个特征:花萼长、花萼宽、花瓣长和花瓣宽。
目标
- 使用K-means聚类算法对鸢尾花数据进行聚类:通过无监督学习的方式,将鸢尾花数据分成四类(也就是分为所谓的4簇)。
- 预测鸢尾花种类:用户输入鸢尾花的特征值后,系统能够预测其所属的种类。
- 展示预测的迭代过程:通过显示迭代过程中的质心变化,让我们可以更直观地理解K-means聚类算法的工作原理。
- 增加非鸢尾花数据:模拟实际环境中的数据混合情况,提高算法的鲁棒性(鲁棒性是指算法在面对噪声、数据缺失或异常数据等情况下仍然能保持其性能的能力。在鸢尾花识别项目中,确保K-means聚类算法的鲁棒性是非常重要的)而本项目正是通过添加非鸢尾花集,更好的模拟了实际情况。
需求
- 数据处理:包括数据加载、特征缩放和数据集划分。
- 算法实现:K-means聚类算法的实现,包括质心初始化、簇分配、质心更新和收敛判断。
- 结果展示:输入特征值进行预测,并显示预测结果及其迭代过程。
挑战
- 质心初始化的随机性:不同的初始化可能导致不同的聚类结果。
- 收敛判断:判断质心是否已经收敛需要设定合适的阈值。
- 处理混合数据:需要正确区分鸢尾花和非鸢尾花数据。
二、知识补充
1.k-means算法
K-means算法是一种常用的无监督学习方法,用于将数据点划分为K个簇,每个簇由其质心(centroid)表示。算法通过迭代的方式,最小化各点到其所属质心的距离,从而实现数据点的聚类。
K-means算法步骤
- 初始化:
- 随机选择K个点作为初始质心。
- 迭代步骤:
- 簇分配:将每个数据点分配到离它最近的质心所属的簇。
- 质心更新:重新计算每个簇的质心,质心为簇内所有点的平均值。
- 收敛条件:
- 质心不再发生变化,或者达到最大迭代次数。
补充:
- 一般情况下k-means算法是不确定有几个簇的,一般要运用“肘部法则”来判断几个簇,此题恰好已经分类好就不需要运用肘部法则来确定簇的数量。
三、整体设计思路
#include <iostream>
#include <fstream>
#include <vector>
#include <array>
#include <cmath>
#include <limits>
#include <algorithm>
#include <numeric>
#include <cstdlib>
#include <ctime>
#include <opencv2/opencv.hpp>
1.头文件的添加
<cstdlib>- 提供了标准库中的通用工具函数,包括动态内存分配、随机数生成、进程控制、环境查询和转换等功能。
<ctime>:- 用于随机数生成和时间相关的操作,例如在运用**
<cstdlib>** 初始化随机数种子srand(static_cast<unsigned int>(time(0)))和生成随机数rand()。
- 用于随机数生成和时间相关的操作,例如在运用**
<limits>:- 用于获取数据类型的极限值,例如
numeric_limits<double>::max()和numeric_limits<double>::min(),在代码中用于特征缩放和初始化距离数组。
- 用于获取数据类型的极限值,例如
<numeric>:- 用于数值算法操作,例如
accumulate用于计算总距离accumulate(distances.begin(), distances.end(), 0.0)。
- 用于数值算法操作,例如
2.对数据集部分内容的相关处理——标签
struct Iris {
array<double, 4> features;
int label; // 0: Setosa, 1: Versicolour, 2: Virginica, 3: 非鸢尾花
};
// 将字符串标签映射为整数
int labelToInt(const string& label) {
if (label == "setosa") return 0;
if (label == "versicolor") return 1;
if (label == "virginica") return 2;
return 3;
}
// 将整数标签映射为字符串
string labelToString(int label) {
if (label == 0) return "setosa";
if (label == 1) return "versicolor";
if (label == 2) return "virginica";
return "non-iris";
}
-
创建一个鸢尾花结构体
-
features:一个长度为 4 的array<double, 4>数组,用于存储鸢尾花的四个特征值(如花萼长、花萼宽、花瓣长、花瓣宽)。double是数据类型,4是数组大小。-
与原生数组相比,
array提供了更好的类型安全性和丰富的成员函数接口,使其使用更加方便和安全。 -
array与一般数组的区别
特性 传统数组 array初始化方式 支持 支持 获取大小 需手动计算 提供 size()方法边界检查 不支持 支持(通过 at()方法)迭代 使用循环 支持迭代器和范围 for循环类型安全 不完全 完全类型安全 与 STL 结合 不直接支持 完全支持 -
运用
array很好的避免了访问越界的现象。
-
-
label:一个int类型的标签,用于表示鸢尾花的种类。标签的含义如下:- 0:Setosa
- 1:Versicolour
- 2:Virginica
- 3:非鸢尾花
-
-
函数
labelToInt和函数labelToString-
将表示鸢尾花种类的字符串标签和整数标签进行转化
-
作用:
-
数据加载:从文件中加载鸢尾花数据时,字符串标签需要转换为整数标签以便于后续处理。
-
数据存储:处理后的数据需要保存到文件中时,需要将整数标签转换回字符串标签。
-
分类和预测:在分类和预测过程中,标签的表示形式需要在整数和字符串之间转换,以便于显示和分析结果。
-
-
这样提高了代码的可读性和维护性。
-
3.加载鸢尾花数据集
vector<Iris> loadIrisData(const string& filename) {
vector<Iris> data;
ifstream file(filename);
if (!file.is_open()) {
cerr << "无法打开文件" << endl;
return data;
}
string line;
while (getline(file, line)) {
istringstream iss(line);//创建了一个流对象
Iris iris;
string label;
if (iss >> iris.features[0] >> iris.features[1] >> iris.features[2] >> iris.features[3] >> label) {
iris.label = labelToInt(label);
data.push_back(iris);
}
}
file.close();
return data;
}
- 初始化
vector<Iris>:声明一个vector<Iris>变量data,用于存储从文件中读取的数据。 - 打开文件:使用
ifstream打开指定的文件。如果文件打开失败,输出错误信息并返回空的vector - 读取文件内容:使用
getline逐行读取文件内容。- 解析每一行:将每一行数据读入一个
istringstream对象iss。- 方便解析:
istringstream使得解析字符串变得非常简单,可以直接使用流提取运算符>>逐个提取数据项,而不需要手动拆分字符串。 - 一致的接口:使用
istringstream可以与从标准输入(如cin)读取数据的方式一致,简化了代码。 - 安全性:流操作符
>>会自动处理不同类型的数据,并在数据类型不匹配时返回错误状态,使得解析过程更加安全。
- 方便解析:
- 读取特征值和标签:从
iss中提取四个特征值和一个标签字符串,并将特征值存储到Iris结构体的features数组中。 - 转换标签:使用
labelToInt函数将标签字符串转换为整数标签,并存储到Iris结构体的label字段中。 - 添加到数据集:将解析后的
Iris结构体对象添加到data向量中。
- 解析每一行:将每一行数据读入一个
- 关闭文件:读取完所有行后,关闭文件。
- 返回数据集:返回包含所有读取和解析后的
Iris数据的vector。
4.生成非鸢尾花数据
vector<Iris> generateNonIrisData(int numSamples) {
vector<Iris> data;
srand(static_cast<unsigned int>(time(0)));
for (int i = 0; i < numSamples; ++i) {
Iris nonIris;
for (int j = 0; j < 4; ++j) {
nonIris.features[j] = (rand() % 11)/10.0 ;
}
nonIris.label = 3; // 非鸢尾花
data.push_back(nonIris);
}
return data;
}
-
函数返回值以及参数
-
该函数返回一个
std::vector<Iris>容器,包含生成的非鸢尾花数据。 -
numSamples参数指定要生成的样本数量。
-
-
设置随机数种子
- 使用当前时间设置随机数种子,确保每次运行程序时生成不同的随机数。
-
生成非鸢尾花数据
- 对于每一个样本:
- 创建一个
Iris对象nonIris。 - 使用内层的
for循环生成四个随机特征值,每个特征值在 0 到 1 之间。 - 将标签设置为
3,表示非鸢尾花。 - 将生成的
nonIris对象添加到data容器中。
- 创建一个
- 对于每一个样本:
-
增加非鸢尾花集更好的模拟实际情况,增加数据的多样性和复杂性。
5.将数据写入文件
void writeDataToFile(const vector<Iris>& data, const string& filename) {
ofstream file(filename);
if (!file.is_open()) {
cerr << "无法打开文件" << endl;
return;
}
for (const auto& iris : data) {
file << iris.features[0] << " " << iris.features[1] << " " << iris.features[2] << " " << iris.features[3] << " " << labelToString(iris.label) << endl;
}
file.close();
}
for (const auto& iris : data)运用这种方式- 使用
auto关键字可以让编译器自动推导出iris的类型。不需要显式地指定类型,减少了代码的冗长和可能的错误。 - 使用
const auto&可以避免不必要的拷贝操作,提高性能,并且通过引用来访问元素,这样修改iris的值不会影响原来的数据。另外,const确保了在循环体内不会修改容器中的元素。
- 使用
6.进行特征缩放
void scaleFeatures(vector<Iris>& data, array<double, 4>& minVal, array<double, 4>& maxVal) {
// 找到每个特征的最小值和最大值
for (const auto& iris : data) {
for (int i = 0; i < 4; ++i) {
if (iris.features[i] < minVal[i]) minVal[i] = iris.features[i];
if (iris.features[i] > maxVal[i]) maxVal[i] = iris.features[i];
}
}
// 进行特征缩放
for (auto& iris : data) {
for (int i = 0; i < 4; ++i) {
iris.features[i] = (iris.features[i] - minVal[i]) / (maxVal[i] - minVal[i]);
}
}
}
-
目的:通过特征缩放,可以使不同特征值在相同的范围内,有助于提高机器学习算法的性能和准确性。
-
缩放后的特征值 = (特征值 − 最小值) / (最大值 − 最小值) 缩放后的特征值=(特征值−最小值)/(最大值−最小值) 缩放后的特征值=(特征值−最小值)/(最大值−最小值)
这是特征缩放公式。
-
步骤:
- 找到每个特征的最小值和最大值
- 遍历数据集中的每个
Iris对象。 - 对于每个特征(共有四个),找到当前特征的最小值和最大值,并更新
minVal和maxVal数组。
- 遍历数据集中的每个
- 进行特征缩放
- 找到每个特征的最小值和最大值
-
优点:
- 消除特征值的量纲差异:特征缩放使得所有特征值在同一个量纲范围内,有助于提高机器学习算法(如 K-means)的性能和准确性。
- 增强数值稳定性:通过归一化,可以减少数值计算中的溢出和下溢问题,提高数值稳定性。
7.k-means类
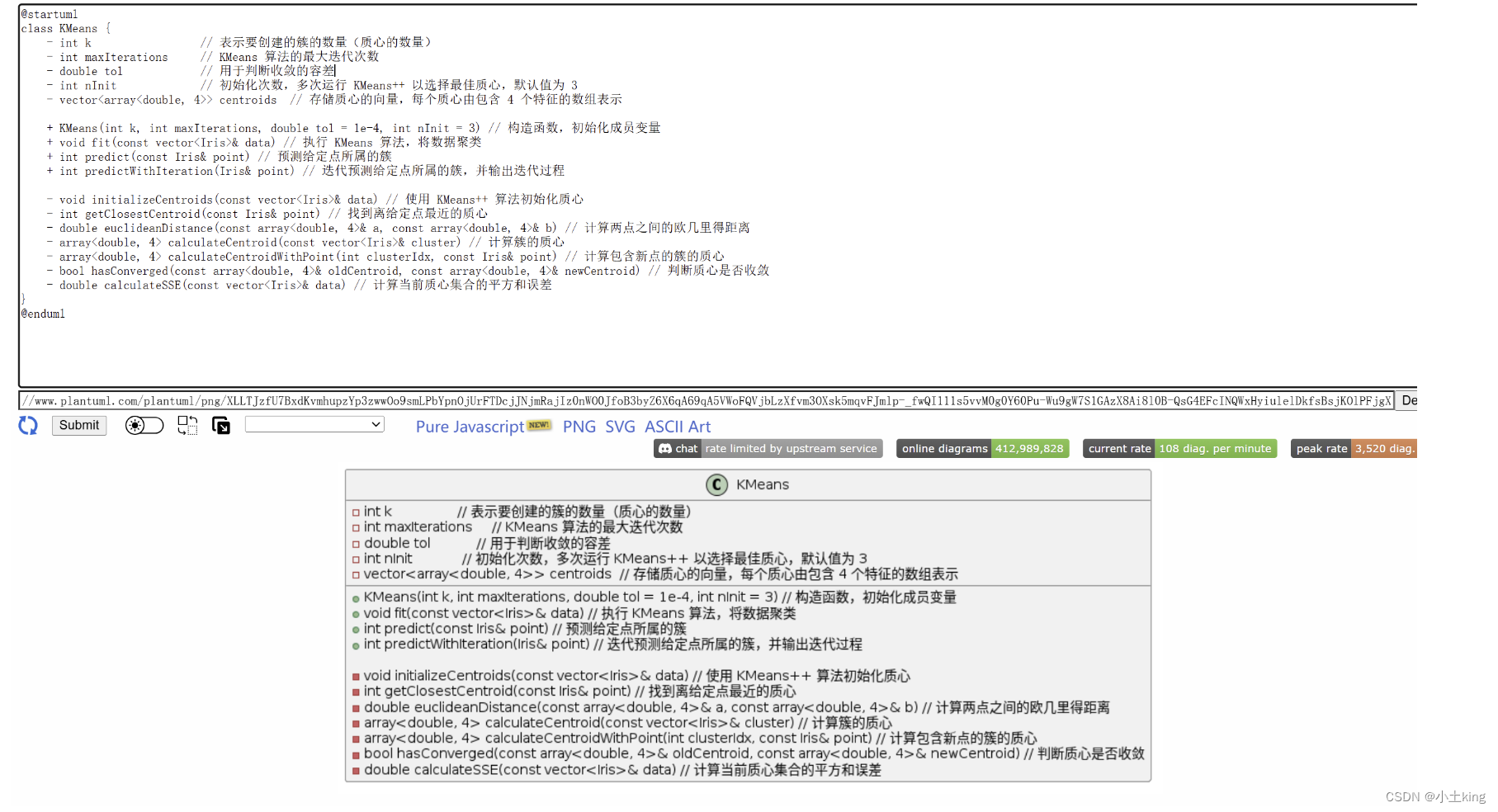
+(public)、-(private)用于修饰- 这是用plantUML绘制的用例图
1.构造函数
KMeans(int k, int maxIterations, double tol = 1e-4, int nInit = 3) : k(k), maxIterations(maxIterations), tol(tol), nInit(nInit) {}
-
初始化成员变量
-
k:聚类的数量(簇的数量)。 -
maxIterations:KMeans 算法的最大迭代次数。 -
tol:用于判断收敛的容差,默认为1e-4。 -
nInit:初始化次数,即多次运行 KMeans++ 算法以选择最佳质心,默认为3。
-
2.euclideanDistance函数——计算欧氏距离
double euclideanDistance(const array<double, 4>& a, const array<double, 4>& b) {
double sum = 0.0;
for (int i = 0; i < 4; ++i) {
sum += pow(a[i] - b[i], 2);
}
return sqrt(sum);
}
-
欧氏距离的数学公式
-
欧氏距离(Euclidean Distance)是两个向量之间最常用的距离度量方法,其公式如下:

-
使用一个
for循环遍历向量的每个维度。对于每个维度
i,计算a[i]和b[i]的差的平方,并将其累加到sum中。使用
pow计算平方。
-
3.initializeCentroids函数——初始化质心
void initializeCentroids(const vector<Iris>& data) {
centroids.push_back(data[rand() % data.size()].features);
for (int i = 1; i < k; ++i) {
vector<double> distances(data.size(), numeric_limits<double>::max());
for (size_t j = 0; j < data.size(); ++j) {
for (int m = 0; m < i; ++m) {
double dist = euclideanDistance(data[j].features, centroids[m]);
if (dist < distances[j]) {
distances[j] = dist;
}
}
}
double totalDistance = accumulate(distances.begin(), distances.end(), 0.0);
double randVal = (double)rand() / RAND_MAX * totalDistance;
for (size_t j = 0; j < data.size(); ++j) {
randVal -= distances[j];
if (randVal <= 0) {
centroids.push_back(data[j].features);
break;
}
}
}
}
-
选择第一个质心
- 这里使用
rand() % data.size()随机选择数据集中的一个点作为第一个质心。 data[rand() % data.size()].features获取这个随机点的特征并将其添加到centroids向量中。
- 这里使用
-
选择剩余质心
- 外层
for循环从i = 1开始,直到选择出k个质心。 - 初始化一个向量
distances,长度与数据集大小相同,初始值设置为numeric_limits<double>::max()(将此作为一个极大值),用于存储每个点到最近质心的距离。
- 外层
-
计算每个点到最近质心的距离
- 内层
for循环遍历数据集中的每个点j,并对每个点计算其到所有已有质心(从0到i-1)的距离。 - 调用
euclideanDistance函数(计算欧式距离)计算数据点data[j].features到质心centroids[m]的欧氏距离。 - 如果计算出的距离
dist小于distances[j],则更新distances[j]。
- 内层
-
计算总距离
- 使用
accumulate计算distances向量中所有元素的和,即所有数据点到最近质心的距离之和,存储在totalDistance中。- 两个参数是迭代器的起始位置和结束位置
- 使用
-
选择下一个质心
double randVal = (double)rand() / RAND_MAX * totalDistance;这行代码生成一个随机值randVal,它在0到totalDistance之间。首先(double)rand() / RAND_MAX生成一个0到1之间的随机浮点数,然后乘以totalDistance,这样randVal就在0到totalDistance之间。RAND_MAX是 C++ 标准库中定义的一个宏,它表示rand()函数能够生成的最大值
- 遍历数据集中的所有点。
- 对于每个点,将
randVal减去该点到已有质心的最短距离。 - 如果
randVal变为非正数,将当前点作为新的质心添加到centroids中并跳出循环。
- 对于每个点,将
好处:
- 通过一种加权随机选择的方法,确保距离已有质心较远的点有更高的概率被选为新的质心,这种方法有效地分散了质心的位置,从而提高k-means算法的初始化质量。
4.获取某个点最近的质心
int getClosestCentroid(const Iris& point) {
int bestIdx = 0;
double bestDist = numeric_limits<double>::max();
for (int i = 0; i < k; ++i) {
double dist = euclideanDistance(point.features, centroids[i]);
if (dist < bestDist) {
bestDist = dist;
bestIdx = i;
}
}
return bestIdx;
}
作用:这个函数的作用是找到一个点point离哪个质心最近,并返回该质心的索引。
-
初始化最优索引和最优距离
bestIdx:存储最近质心的索引,初始值为0。bestDist:存储最近质心的距离,初始值为numeric_limits<double>::max(),即最大的可能的double值。
-
遍历所有质心
- 遍历所有
k个质心,计算每个质心到点point的欧几里得距离. euclideanDistance(point.features, centroids[i]):计算点point的特征向量与第i个质心之间的欧几里得距离。- 如果计算得到的距离
dist小于当前的最优距离bestDist,则更新最优距离和最优索引。
- 遍历所有
-
返回最优索引
5.计算簇的质心
array<double, 4> calculateCentroidWithPoint(int clusterIdx, const Iris& point) {
array<double, 4> newCentroid = centroids[clusterIdx];
for (int i = 0; i < 4; ++i) {
newCentroid[i] = (centroids[clusterIdx][i] + point.features[i]) / 2.0;
}
return newCentroid;
}
-
参数解释
int clusterIdx:这是簇的索引,即我们要更新的质心所在簇的索引。const Iris& point:这是要添加到簇中的新点。、Iris是一个包含features和label的结构体,其中features是一个包含四个特征值的数组。
-
创建新质心:
- 从当前簇的质心开始创建一个新质心,
newCentroid被初始化为当前簇(clusterIdx)的质心。
- 从当前簇的质心开始创建一个新质心,
-
计算包含新点后的质心:
- 遍历质心的每一个特征。
- 对于每个特征,计算当前质心和新点在该维度的平均值。
-
示例
- 假设我们有一个簇的质心为
[2.0, 3.0, 4.0, 5.0],并且有一个新点的特征为[4.0, 5.0, 6.0, 7.0]。 - 返回的结果为:
{3.0, 4.0, 5.0, 6.0}
- 假设我们有一个簇的质心为
6.判断质心是否收敛
bool hasConverged(const array<double, 4>& oldCentroid, const array<double, 4>& newCentroid) {
double sum = 0.0;
for (int i = 0; i < 4; ++i) {
sum += pow(oldCentroid[i] - newCentroid[i], 2);
}
return sqrt(sum) < tol;
}
hasConverged函数用于判断旧质心和新质心之间的距离是否小于给定的容差tol,从而确定质心是否收敛。- 初始化距离和
- 计算欧式距离
- 返回是否收敛
7.计算误差平方和
double calculateSSE(const vector<Iris>& data) {
double sse = 0.0;
for (const auto& point : data) {
int clusterIdx = getClosestCentroid(point);
sse += pow(euclideanDistance(point.features, centroids[clusterIdx]), 2);
}
return sse;
}
-
作用:
- 计算当前质心集合的平方和误差 (SSE),用于衡量聚类效果的好坏。SSE 是每个数据点到其最近质心的距离的平方和。SSE 越小,表示聚类效果越好,因为数据点离它们的质心越近。
-
初始化 SSE
-
遍历数据集并计算 SSE
8.数据聚类
void fit(const vector<Iris>& data) {
double bestSSE = numeric_limits<double>::max();
vector<array<double, 4>> bestCentroids;
for (int init = 0; init < nInit; ++init) {
centroids.clear();
initializeCentroids(data);
for (int iter = 0; iter < maxIterations; ++iter) {
// 分配簇
vector<vector<Iris>> clusters(k);
for (const auto& point : data) {
int clusterIdx = getClosestCentroid(point);
clusters[clusterIdx].push_back(point);
}
// 更新质心
bool converged = true;
for (int i = 0; i < k; ++i) {
if (!clusters[i].empty()) {
array<double, 4> newCentroid = calculateCentroid(clusters[i]);
if (!hasConverged(centroids[i], newCentroid)) {
converged = false;
}
centroids[i] = newCentroid;
}
}
if (converged) {
break;
}
}
// 计算当前初始化的SSE
double currentSSE = calculateSSE(data);
if (currentSSE < bestSSE) {
bestSSE = currentSSE;
bestCentroids = centroids;
}
}
centroids = bestCentroids; // 使用最佳质心
}
-
作用:用于执行 KMeans 聚类算法,将数据分成
k个簇。函数多次初始化质心,选择平方和误差最小的初始化结果作为最终质心。 -
步骤:
-
初始化最佳 SSE 和最佳质心
bestSSE用于存储最小的 SSE。bestCentroids用于存储具有最小 SSE 的质心。
-
多次初始化质心并运行 KMeans
- 外层循环
nInit次,用于多次初始化质心。 - 每次初始化前清空
centroids,然后调用initializeCentroids初始化质心。
- 外层循环
-
进行 KMeans 聚类
- 内层循环
maxIterations次,进行最大迭代次数的 KMeans 聚类。 - 创建一个大小为
k的clusters向量,用于存储每个簇中的点。 - 遍历数据集中的每个点,将其分配到最近的质心对应的簇中。
- 内层循环
-
更新质心
- 遍历每个簇,计算新的质心。
- 检查簇是否为空如果簇不为空,则计算新质心。
- 调用
calculateCentroid函数计算当前簇clusters[i]的新质心。 - 调用
hasConverged函数检查旧质心centroids[i]和新质心newCentroid之间的距离是否小于容差tol。- 如果质心没有收敛(距离大于容差),则将
converged设为false。
- 如果质心没有收敛(距离大于容差),则将
- 调用
- 更新质心为新的质心。
- 如果所有质心都收敛(
converged仍为true),则提前结束循环。
-
计算 SSE 并更新最佳质心
- 计算当前质心集合的 SSE。
- 如果当前 SSE 小于最佳 SSE,则更新最佳 SSE 和最佳质心。
-
使用最佳质心
-
9.迭代预测给定点所属的簇,并输出迭代过程
int predictWithIteration(Iris& point) {
array<double, 4> currentCentroid = point.features;
for (int iter = 0; iter < maxIterations; ++iter) {
// 计算到每个质心的距离并打印
for (int i = 0; i < k; ++i) {
double dist = euclideanDistance(point.features, centroids[i]);
cout << "第 " << iter + 1 << " 次迭代,簇 " << i + 1 << ",质心: ";
for (int j = 0; j < 4; ++j) {
cout << centroids[i][j] << " ";
}
cout << ",距离: " << dist << endl;
}
// 寻找最接近的质心
int clusterIdx = getClosestCentroid(point);
// 打印预测的簇
cout << "第 " << iter + 1 << " 次迭代预测簇: " << clusterIdx + 1 << endl;
// 更新质心
centroids[clusterIdx] = calculateCentroidWithPoint(clusterIdx, point);
// 打印更新后的质心
cout << "第 " << iter + 1 << " 次迭代,更新后的质心 " << clusterIdx + 1 << ": ";
for (int j = 0; j < 4; ++j) {
cout << centroids[clusterIdx][j] << " ";
}
cout << endl;
if (hasConverged(currentCentroid, centroids[clusterIdx])) {
break;
}
currentCentroid = centroids[clusterIdx];
}
return getClosestCentroid(point);
}
-
初始化当前质心
- 将当前点的特征初始化为当前质心。
-
开始迭代
-
遍历每个簇,计算当前点到每个质心的欧几里得距离。
打印每个质心的坐标及其距离。
-
-
寻找最接近的质心
-
打印预测的簇
-
更新质心
-
打印更新后的质心
-
返回最终预测的簇
8.计算准确率
double calculateAccuracy(const vector<Iris>& data, KMeans& kmeans, vector<int>& predictions) {
int correctPredictions = 0;
for (const auto& point : data) {
int predictedCluster = kmeans.predict(point);
predictions.push_back(predictedCluster);
if (predictedCluster == point.label) {
correctPredictions++;
}
}
return static_cast<double>(correctPredictions) / data.size();
}
- 初始化正确预测计数器
- 初始化一个计数器
correctPredictions,用于记录预测正确的样本数量。
- 初始化一个计数器
- 遍历数据集
- 进行预测并保存预测结果
- 对每个点调用
kmeans模型的predict方法进行预测,得到预测的簇索引。 - 将预测结果存储在
predictions向量中。
- 对每个点调用
- 比较预测结果与真实标签
- 如果预测的簇索引与点的真实标签相同,则增加
correctPredictions计数器。
- 如果预测的簇索引与点的真实标签相同,则增加
- 计算并返回准确率
- 将正确预测的数量
correctPredictions转换为double类型,并除以数据集的大小data.size(),计算预测的准确率。 - 返回准确率。
- 将正确预测的数量
9.显示图片并打印类别
void showImage(const string& windowName, const string& imagePath, const string& text) {
Mat image = imread(imagePath);
if (image.empty()) {
cerr << "无法打开图片文件: " << imagePath << endl;
return;
}
putText(image, text, Point(10, 30), FONT_HERSHEY_SIMPLEX, 1, Scalar(0, 0, 255), 2);
imshow(windowName, image);
waitKey(0);
destroyWindow(windowName);
}
-
读取图像文件
- 使用
imread函数读取指定路径的图像文件,并存储在image变量中。 - 如果图像文件无法打开,
image将为空矩阵。此时输出错误信息并返回。
- 使用
-
在图像上绘制文本
- 使用
putText函数在图像上绘制文本。 - 参数说明:
image:目标图像text:要绘制的文本字符串。Point(10, 30):文本在图像上的左下角位置(坐标 (10, 30)FONT_HERSHEY_SIMPLEX:字体类型。1:字体大小缩放因子。Scalar(0, 0, 255):文本颜色(BGR,红色)。2:文本的线条粗细。
- 使用
-
显示图像
- 使用
imshow函数在名为windowName的窗口中显示图像。 - 使用
waitKey(0)等待用户按键,确保图像窗口保持打开状态。 - 使用
destroyWindow销毁图像窗口。
- 使用
10.main函数
int main() {
// 加载鸢尾花数据集
string filename = "iris.txt";
vector<Iris> irisData = loadIrisData(filename);
// 生成非鸢尾花数据并加入到鸢尾花数据集中
vector<Iris> nonIrisData = generateNonIrisData(50);
irisData.insert(irisData.end(), nonIrisData.begin(), nonIrisData.end());
// 将合并后的数据写回文件
writeDataToFile(irisData, filename);
// 进行特征缩放
array<double, 4> minVal = { numeric_limits<double>::max(), numeric_limits<double>::max(), numeric_limits<double>::max(), numeric_limits<double>::max() };
array<double, 4> maxVal = { numeric_limits<double>::min(), numeric_limits<double>::min(), numeric_limits<double>::min(), numeric_limits<double>::min() };
scaleFeatures(irisData, minVal, maxVal);
// 划分训练集和测试集
vector<Iris> trainingSet;
vector<Iris> testSet;
// 从前150个鸢尾花数据中随机选择70个样本作为训练集,剩余的30个作为测试集
int numIrisTrain = 70;
int numIrisTest = 30;
vector<int> irisIndices(150);
iota(irisIndices.begin(), irisIndices.end(), 0);
random_shuffle(irisIndices.begin(), irisIndices.end());
for (int i = 0; i < numIrisTrain; ++i) {
trainingSet.push_back(irisData[irisIndices[i]]);
}
for (int i = numIrisTrain; i < numIrisTrain + numIrisTest; ++i) {
testSet.push_back(irisData[irisIndices[i]]);
}
// 从非鸢尾花数据集中随机选择30个样本作为训练集,剩余的20个作为测试集
int numNonIrisTrain = 30;
int numNonIrisTest = 20;
vector<int> nonIrisIndices(nonIrisData.size());
iota(nonIrisIndices.begin(), nonIrisIndices.end(), 150);
random_shuffle(nonIrisIndices.begin(), nonIrisIndices.end());
for (int i = 0; i < numNonIrisTrain; ++i) {
trainingSet.push_back(irisData[nonIrisIndices[i]]);
}
for (int i = numNonIrisTrain; i < numNonIrisTrain + numNonIrisTest; ++i) {
testSet.push_back(irisData[nonIrisIndices[i]]);
}
KMeans kmeans(4, 100, 1e-4, 500);
kmeans.fit(trainingSet);
vector<int> predictions;
double accuracy = calculateAccuracy(testSet, kmeans, predictions);
cout << "预测准确率: " << accuracy * 100 << "%" << endl;
// 打印训练集的预测结果
vector<int> trainPredictions;
double trainAccuracy = calculateAccuracy(trainingSet, kmeans, trainPredictions);
cout << "训练集准确率: " << trainAccuracy * 100 << "%" << endl;
for (size_t i = 0; i < trainingSet.size(); ++i) {
cout << "训练集样本 " << i + 1 << " 预测簇: " << trainPredictions[i] << " 实际标签: " << trainingSet[i].label << endl;
}
for (size_t i = 0; i < testSet.size(); ++i) {
cout << "测试集样本 " << i + 1 << " 预测簇: " << predictions[i] << " 实际标签: " << testSet[i].label << endl;
}
while (true) {
cout << "请输入四个特征值(花萼长,花萼宽,花瓣长,花瓣宽),用空格分隔,输入 -1 退出:" << endl;
Iris input;
for (int i = 0; i < 4; ++i) {
cin >> input.features[i];
}
if (input.features[0] == -1) {
break;
}
// 进行特征缩放
for (int i = 0; i < 4; ++i) {
input.features[i] = (input.features[i] - minVal[i]) / (maxVal[i] - minVal[i]);
}
int predictedCluster = kmeans.predictWithIteration(input);
cout << "最终预测簇: " << predictedCluster << endl;
switch (predictedCluster) {
case 0:
showImage("结果", "iris_setosa.jpg", "Iris-setosa");
break;
case 1:
showImage("结果", "iris_versicolor.jpg", "Iris-versicolor");
break;
case 2:
showImage("结果", "iris_virginica.jpg", "Iris-virginica");
break;
case 3:
showImage("结果", "non_iris.jpg", "zhangsong");
break;
default:
cerr << "未知簇" << endl;
break;
}
}
return 0;
}
四、效果图
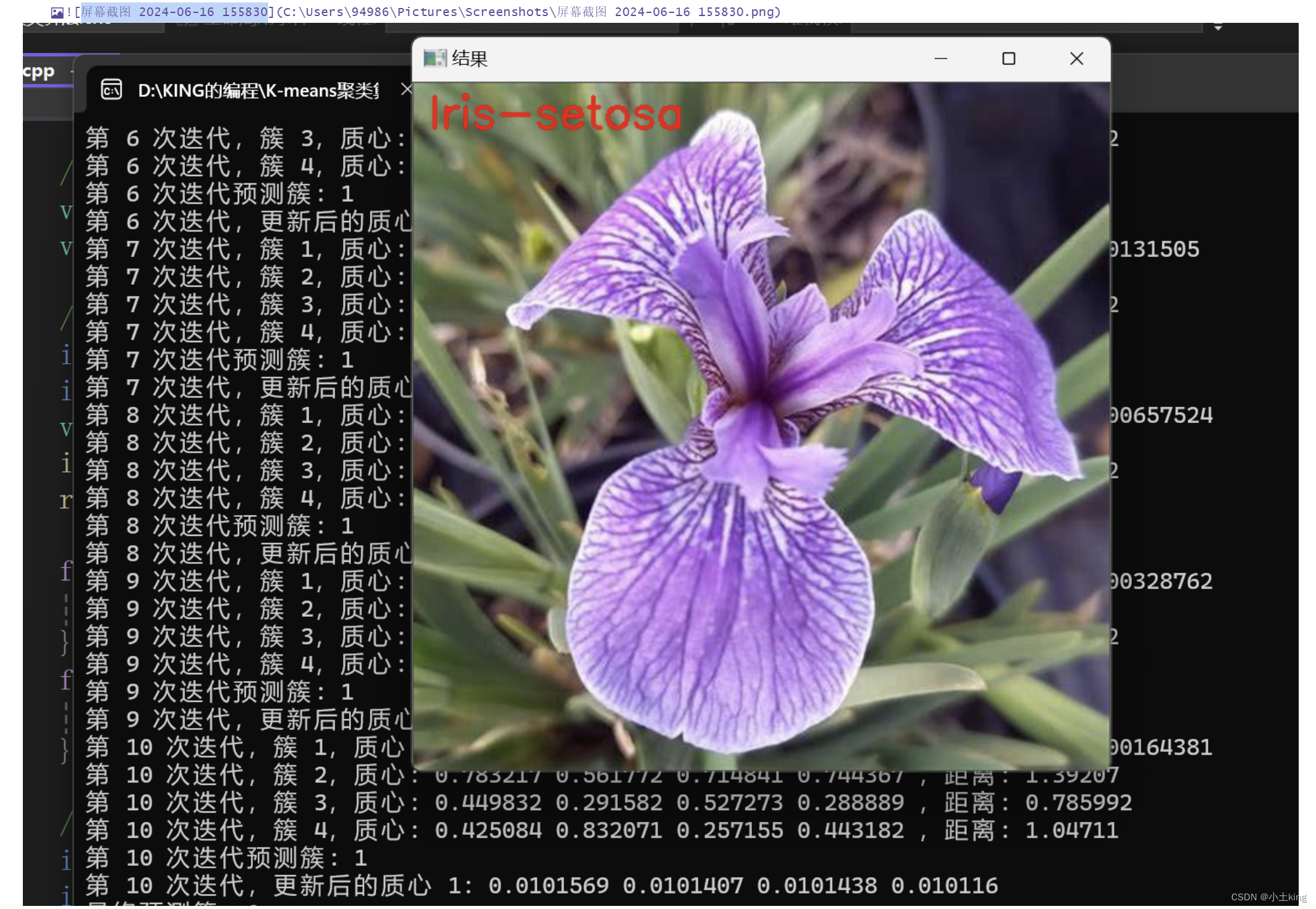
五、测试分析
- 这个整体的预测准确率有待提高,我们提高了初始化质心的次数,但依旧不够,一般准确率只有20~30,最好的时候是88.
六、源码
#include <iostream>
#include <fstream>
#include <vector>
#include <array>
#include <cmath>
#include <limits>
#include <algorithm>
#include <numeric>
#include <cstdlib>
#include <ctime>
#include <opencv2/opencv.hpp>
using namespace std;
using namespace cv;
struct Iris {
array<double, 4> features;
int label; // 0: Setosa, 1: Versicolour, 2: Virginica, 3: 非鸢尾花
};
// 将字符串标签映射为整数
int labelToInt(const string& label) {
if (label == "setosa") return 0;
if (label == "versicolor") return 1;
if (label == "virginica") return 2;
return 3;
}
// 将整数标签映射为字符串
string labelToString(int label) {
if (label == 0) return "setosa";
if (label == 1) return "versicolor";
if (label == 2) return "virginica";
return "non-iris";
}
// 加载鸢尾花数据集
vector<Iris> loadIrisData(const string& filename) {
vector<Iris> data;
ifstream file(filename);
if (!file.is_open()) {
cerr << "无法打开文件" << endl;
return data;
}
string line;
while (getline(file, line)) {
istringstream iss(line);
Iris iris;
string label;
if (iss >> iris.features[0] >> iris.features[1] >> iris.features[2] >> iris.features[3] >> label) {
iris.label = labelToInt(label);
data.push_back(iris);
}
}
file.close();
return data;
}
// 生成非鸢尾花数据
vector<Iris> generateNonIrisData(int numSamples) {
vector<Iris> data;
srand(static_cast<unsigned int>(time(0)));
for (int i = 0; i < numSamples; ++i) {
Iris nonIris;
for (int j = 0; j < 4; ++j) {
nonIris.features[j] = (rand() % 100);
}
nonIris.label = 3; // 非鸢尾花
data.push_back(nonIris);
}
return data;
}
// 将数据写回文件
void writeDataToFile(const vector<Iris>& data, const string& filename) {
ofstream file(filename);
if (!file.is_open()) {
cerr << "无法打开文件" << endl;
return;
}
for (const auto& iris : data) {
file << iris.features[0] << " " << iris.features[1] << " " << iris.features[2] << " " << iris.features[3] << " " << labelToString(iris.label) << endl;
}
file.close();
}
// 进行特征缩放
void scaleFeatures(vector<Iris>& data, array<double, 4>& minVal, array<double, 4>& maxVal) {
// 找到每个特征的最小值和最大值
for (const auto& iris : data) {
for (int i = 0; i < 4; ++i) {
if (iris.features[i] < minVal[i]) minVal[i] = iris.features[i];
if (iris.features[i] > maxVal[i]) maxVal[i] = iris.features[i];
}
}
// 进行特征缩放
for (auto& iris : data) {
for (int i = 0; i < 4; ++i) {
iris.features[i] = (iris.features[i] - minVal[i]) / (maxVal[i] - minVal[i]);
}
}
}
class KMeans {
public:
KMeans(int k, int maxIterations, double tol = 1e-4, int nInit =100) : k(k), maxIterations(maxIterations), tol(tol), nInit(nInit) {}
void fit(const vector<Iris>& data) {
double bestSSE = numeric_limits<double>::max();
vector<array<double, 4>> bestCentroids;
for (int init = 0; init < nInit; ++init) {
centroids.clear();
initializeCentroids(data);
for (int iter = 0; iter < maxIterations; ++iter) {
// 分配簇
vector<vector<Iris>> clusters(k);
for (const auto& point : data) {
int clusterIdx = getClosestCentroid(point);
clusters[clusterIdx].push_back(point);
}
// 更新质心
bool converged = true;
for (int i = 0; i < k; ++i) {
if (!clusters[i].empty()) {
array<double, 4> newCentroid = calculateCentroid(clusters[i]);
if (!hasConverged(centroids[i], newCentroid)) {
converged = false;
}
centroids[i] = newCentroid;
}
}
if (converged) {
break;
}
}
// 计算当前初始化的SSE
double currentSSE = calculateSSE(data);
if (currentSSE < bestSSE) {
bestSSE = currentSSE;
bestCentroids = centroids;
}
}
centroids = bestCentroids; // 使用最佳质心
}
int predict(const Iris& point) {
return getClosestCentroid(point);
}
int predictWithIteration(Iris& point) {
array<double, 4> currentCentroid = point.features;
for (int iter = 0; iter < maxIterations; ++iter) {
// 计算到每个质心的距离并打印
for (int i = 0; i < k; ++i) {
double dist = euclideanDistance(point.features, centroids[i]);
cout << "第 " << iter + 1 << " 次迭代,簇 " << i + 1 << ",质心: ";
for (int j = 0; j < 4; ++j) {
cout << centroids[i][j] << " ";
}
cout << ",距离: " << dist << endl;
}
// 寻找最接近的质心
int clusterIdx = getClosestCentroid(point);
// 打印预测的簇
cout << "第 " << iter + 1 << " 次迭代预测簇: " << clusterIdx + 1 << endl;
// 更新质心
centroids[clusterIdx] = calculateCentroidWithPoint(clusterIdx, point);
// 打印更新后的质心
cout << "第 " << iter + 1 << " 次迭代,更新后的质心 " << clusterIdx + 1 << ": ";
for (int j = 0; j < 4; ++j) {
cout << centroids[clusterIdx][j] << " ";
}
cout << endl;
if (hasConverged(currentCentroid, centroids[clusterIdx])) {
break;
}
currentCentroid = centroids[clusterIdx];
}
return getClosestCentroid(point);
}
private:
int k;
int maxIterations;
double tol;
int nInit;
vector<array<double, 4>> centroids;
void initializeCentroids(const vector<Iris>& data) {
centroids.push_back(data[rand() % data.size()].features);
for (int i = 1; i < k; ++i) {
vector<double> distances(data.size(), numeric_limits<double>::max());
for (size_t j = 0; j < data.size(); ++j) {
for (int m = 0; m < i; ++m) {
double dist = euclideanDistance(data[j].features, centroids[m]);
if (dist < distances[j]) {
distances[j] = dist;
}
}
}
double totalDistance = accumulate(distances.begin(), distances.end(), 0.0);
double randVal = (double)rand() / RAND_MAX * totalDistance;
for (size_t j = 0; j < data.size(); ++j) {
randVal -= distances[j];
if (randVal <= 0) {
centroids.push_back(data[j].features);
break;
}
}
}
}
//获取某个点最近的质心
int getClosestCentroid(const Iris& point) {
int bestIdx = 0;
double bestDist = numeric_limits<double>::max();
for (int i = 0; i < k; ++i) {
double dist = euclideanDistance(point.features, centroids[i]);
if (dist < bestDist) {
bestDist = dist;
bestIdx = i;
}
}
return bestIdx;
}
//计算欧式距离
double euclideanDistance(const array<double, 4>& a, const array<double, 4>& b) {
double sum = 0.0;
for (int i = 0; i < 4; ++i) {
sum += pow(a[i] - b[i], 2);
}
return sqrt(sum);
}
//计算簇的质心
array<double, 4> calculateCentroid(const vector<Iris>& cluster) {
array<double, 4> newCentroid = { 0.0, 0.0, 0.0, 0.0 };
for (const auto& point : cluster) {
for (int i = 0; i < 4; ++i) {
newCentroid[i] += point.features[i];
}
}
for (int i = 0; i < 4; ++i) {
newCentroid[i] /= cluster.size();
}
return newCentroid;
}
//计算簇的质心
array<double, 4> calculateCentroidWithPoint(int clusterIdx, const Iris& point) {
array<double, 4> newCentroid = centroids[clusterIdx];
for (int i = 0; i < 4; ++i) {
newCentroid[i] = (centroids[clusterIdx][i] + point.features[i]) / 2.0;
}
return newCentroid;
}
//判断质心是否收敛
bool hasConverged(const array<double, 4>& oldCentroid, const array<double, 4>& newCentroid) {
double sum = 0.0;
for (int i = 0; i < 4; ++i) {
sum += pow(oldCentroid[i] - newCentroid[i], 2);
}
return sqrt(sum) < tol;
}
//计算误差平方和
double calculateSSE(const vector<Iris>& data) {
double sse = 0.0;
for (const auto& point : data) {
int clusterIdx = getClosestCentroid(point);
sse += pow(euclideanDistance(point.features, centroids[clusterIdx]), 2);
}
return sse;
}
};
// 计算准确率
double calculateAccuracy(const vector<Iris>& data, KMeans& kmeans, vector<int>& predictions) {
int correctPredictions = 0;
for (const auto& point : data) {
int predictedCluster = kmeans.predict(point);
predictions.push_back(predictedCluster);
if (predictedCluster == point.label) {
correctPredictions++;
}
}
return static_cast<double>(correctPredictions) / data.size();
}
// 显示图片并打印类别
void showImage(const string& windowName, const string& imagePath, const string& text) {
Mat image = imread(imagePath);
if (image.empty()) {
cerr << "无法打开图片文件: " << imagePath << endl;
return;
}
putText(image, text, Point(10, 30), FONT_HERSHEY_SIMPLEX, 1, Scalar(0, 0, 255), 2);
imshow(windowName, image);
waitKey(0);
destroyWindow(windowName);
}
int main() {
// 加载鸢尾花数据集
string filename = "iris.txt";
vector<Iris> irisData = loadIrisData(filename);
// 生成非鸢尾花数据并加入到鸢尾花数据集中
vector<Iris> nonIrisData = generateNonIrisData(50);
irisData.insert(irisData.end(), nonIrisData.begin(), nonIrisData.end());
// 将合并后的数据写回文件
writeDataToFile(irisData, filename);
// 进行特征缩放
array<double, 4> minVal = { numeric_limits<double>::max(), numeric_limits<double>::max(), numeric_limits<double>::max(), numeric_limits<double>::max() };
array<double, 4> maxVal = { numeric_limits<double>::min(), numeric_limits<double>::min(), numeric_limits<double>::min(), numeric_limits<double>::min() };
scaleFeatures(irisData, minVal, maxVal);
// 划分训练集和测试集
vector<Iris> trainingSet;
vector<Iris> testSet;
// 从鸢尾花数据集中随机选择70个样本作为训练集,剩余的30个作为测试集
int numIrisTrain = 70;
int numIrisTest = 30;
vector<int> irisIndices(irisData.size() - nonIrisData.size());
iota(irisIndices.begin(), irisIndices.end(), 0);
random_shuffle(irisIndices.begin(), irisIndices.end());
for (int i = 0; i < numIrisTrain; ++i) {
trainingSet.push_back(irisData[irisIndices[i]]);
}
for (int i = numIrisTrain; i < numIrisTrain + numIrisTest; ++i) {
testSet.push_back(irisData[irisIndices[i]]);
}
// 从非鸢尾花数据集中随机选择30个样本作为训练集,剩余的20个作为测试集
int numNonIrisTrain = 30;
int numNonIrisTest = 20;
vector<int> nonIrisIndices(nonIrisData.size());
iota(nonIrisIndices.begin(), nonIrisIndices.end(), irisData.size() - nonIrisData.size());
random_shuffle(nonIrisIndices.begin(), nonIrisIndices.end());
for (int i = 0; i < numNonIrisTrain; ++i) {
trainingSet.push_back(irisData[nonIrisIndices[i]]);
}
for (int i = numNonIrisTrain; i < numNonIrisTrain + numNonIrisTest; ++i) {
testSet.push_back(irisData[nonIrisIndices[i]]);
}
KMeans kmeans(4, 100, 1e-4, 3);
kmeans.fit(trainingSet);
vector<int> predictions;
double accuracy = calculateAccuracy(testSet, kmeans, predictions);
cout << "预测准确率: " << accuracy * 100 << "%" << endl;
// 打印训练集的预测结果
vector<int> trainPredictions;
double trainAccuracy = calculateAccuracy(trainingSet, kmeans, trainPredictions);
cout << "训练集准确率: " << trainAccuracy * 100 << "%" << endl;
for (size_t i = 0; i < trainingSet.size(); ++i) {
cout << "训练集样本 " << i + 1 << " 预测簇: " << trainPredictions[i] << " 实际标签: " << trainingSet[i].label << endl;
}
for (size_t i = 0; i < testSet.size(); ++i) {
cout << "测试集样本 " << i + 1 << " 预测簇: " << predictions[i] << " 实际标签: " << testSet[i].label << endl;
}
while (true) {
cout << "请输入四个特征值(花萼长,花萼宽,花瓣长,花瓣宽),用空格分隔,输入 -1 退出:" << endl;
Iris input;
for (int i = 0; i < 4; ++i) {
cin >> input.features[i];
}
if (input.features[0] == -1) {
break;
}
// 进行特征缩放
for (int i = 0; i < 4; ++i) {
input.features[i] = (input.features[i] - minVal[i]) / (maxVal[i] - minVal[i]);
}
int predictedCluster = kmeans.predictWithIteration(input);
cout << "最终预测簇: " << predictedCluster << endl;
switch (predictedCluster ) {
case 0:
showImage("结果", "iris_setosa.jpg", "Iris-setosa");
break;
case 1:
showImage("结果", "iris_versicolor.jpg", "Iris-versicolor");
break;
case 2:
showImage("结果", "iris_virginica.jpg", "Iris-virginica");
break;
case 3:
showImage("结果", "non_iris.jpg", "zhangsong");
break;
default:
cerr << "未知簇" << endl;
break;
}
}
return 0;
}
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









