







Valse从2011年开始,从一开始的30多个人发展到现在的5000多人。
大模型时代的机遇和挑战 沈向洋
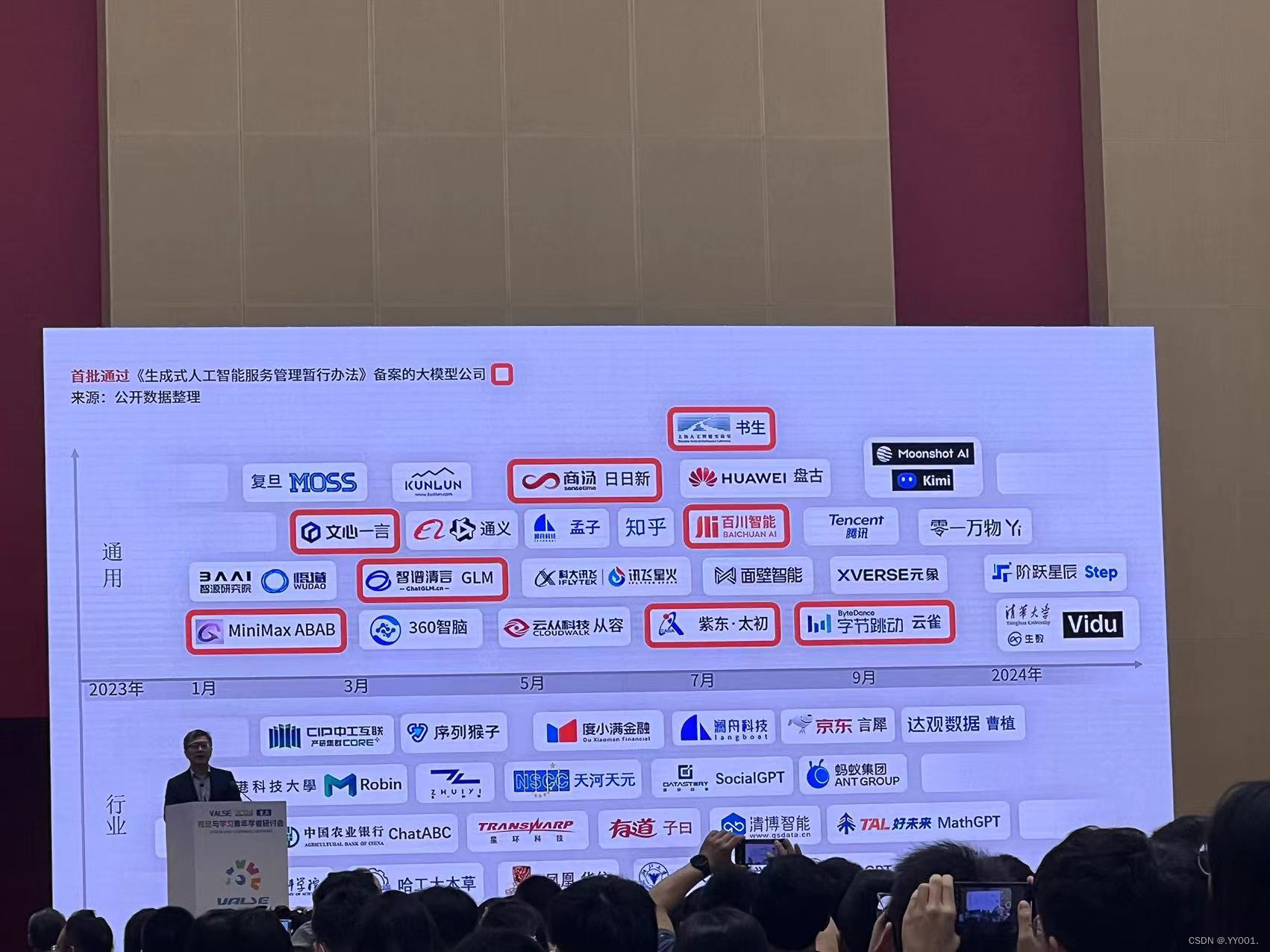
关于一些大模型:

画红框的是开源大模型
一些国产免费的大模型:跃问(教授重点推荐)
统一多模态理解与生成:通向AGI的必由之路
一些语言模型与多模态模型:

现有多模态框架的不足

多模态: 理解和生成统一的必然性和可能性
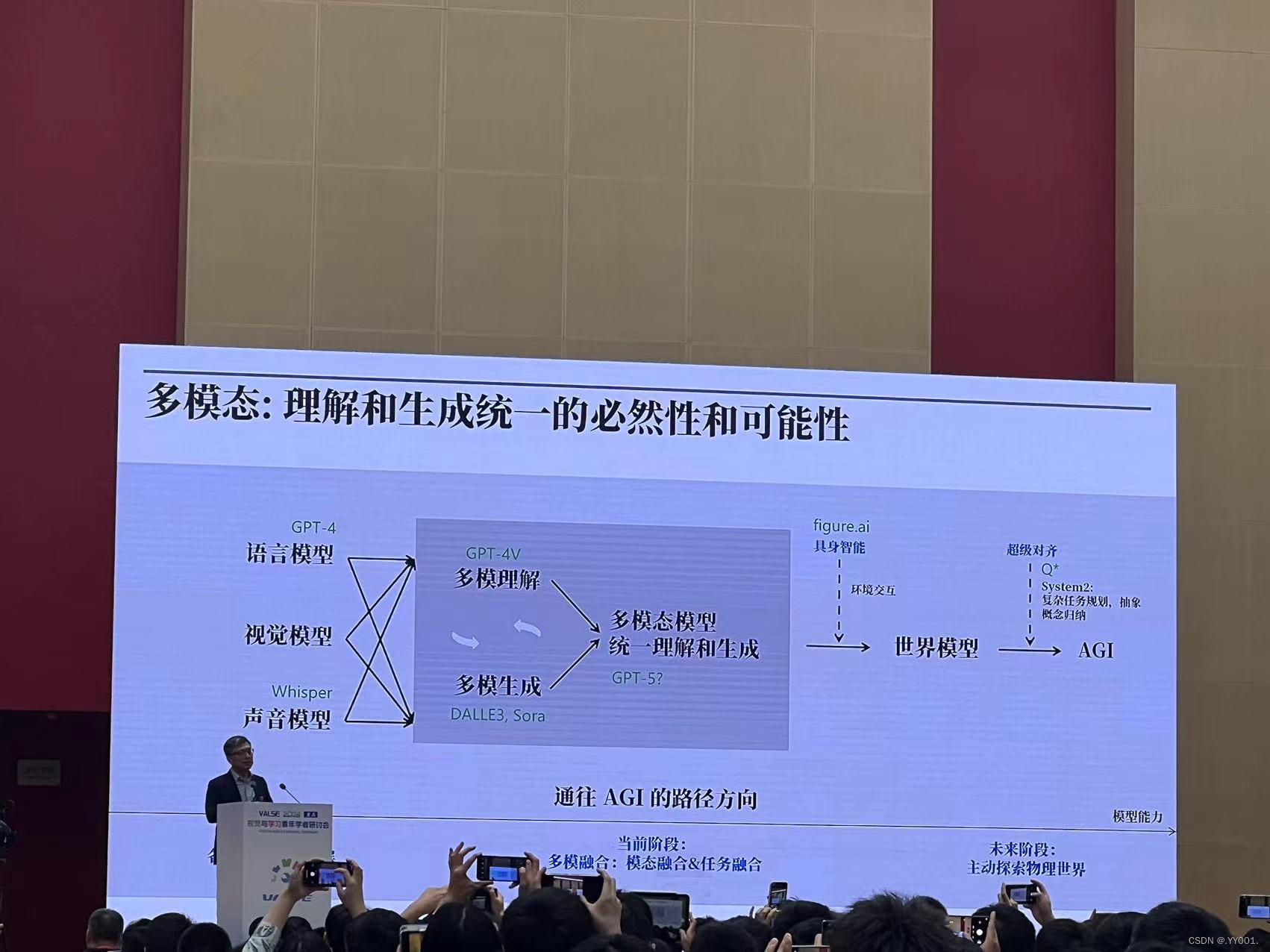
什么是多模理解和多模生成? 一个模型:DreamLLM

大模型将横扫所有垂直行业
不同规格的大模型,对应不同领域 不同人群 不同需求

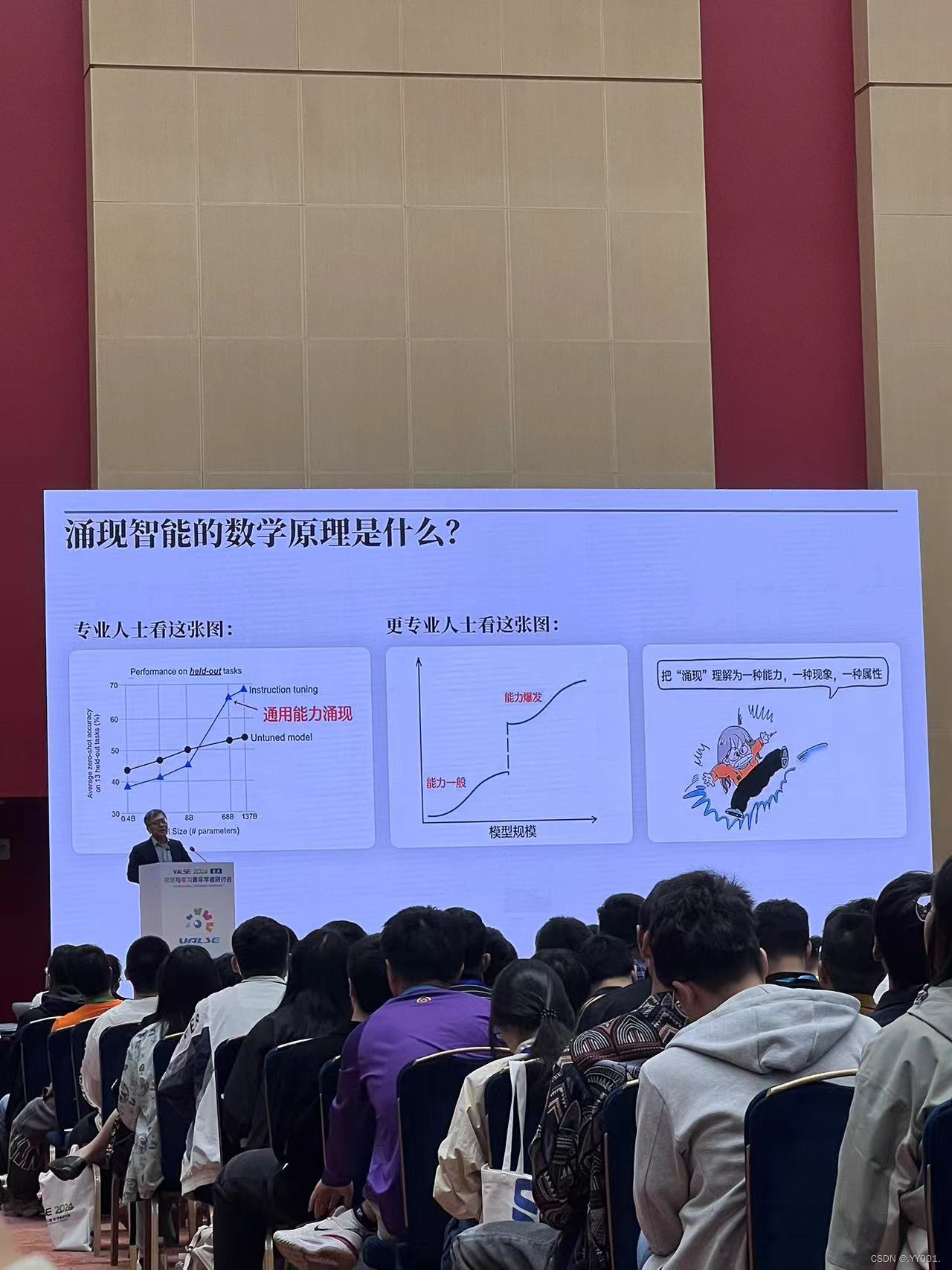
什么是涌现智能?
以深度学习框架为牵引促进自主AI生态发展

驱动本轮人工智能发展的四驾马车 (数据 算法 算力 框架)

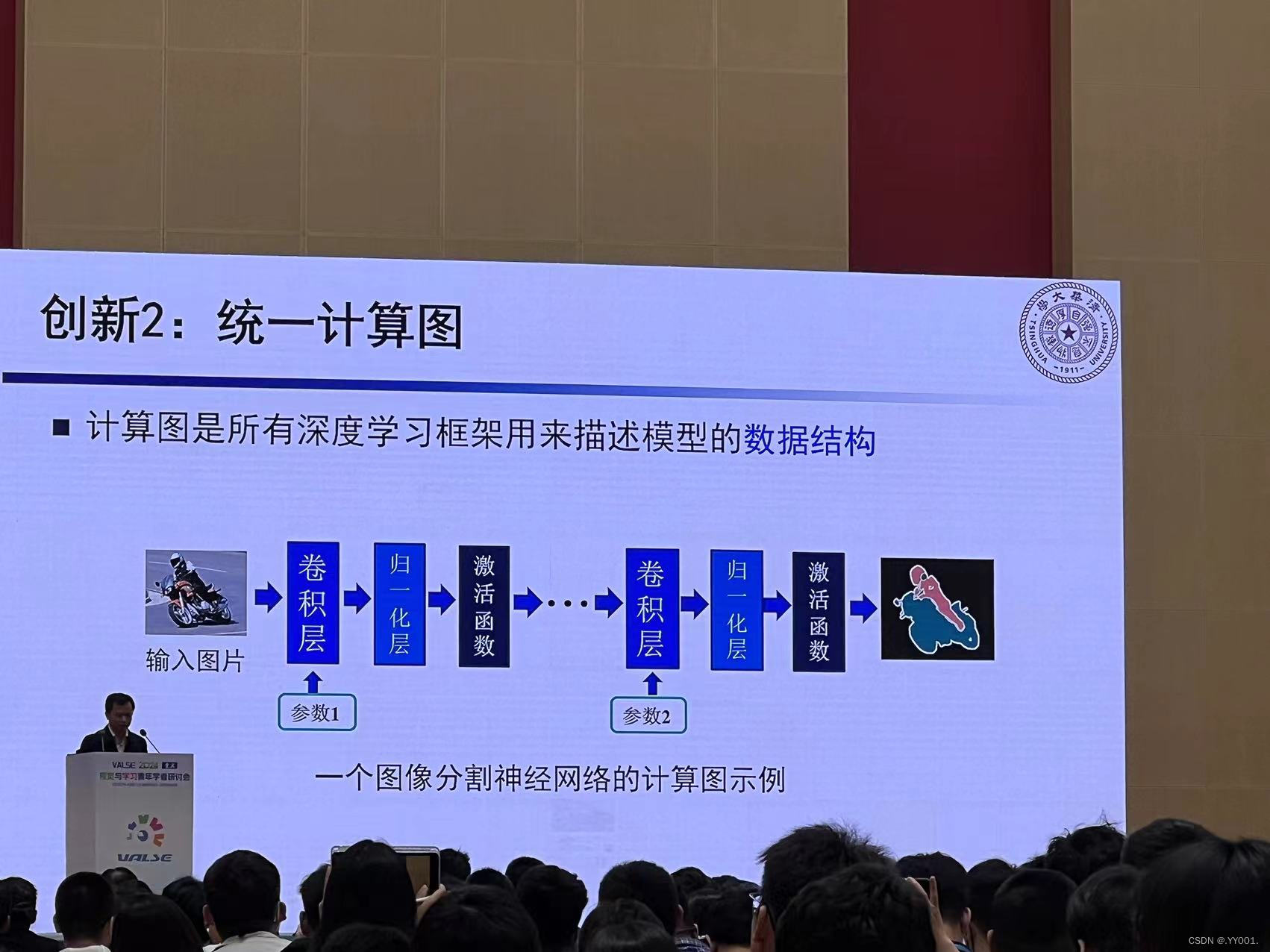
什么是计算图?
一个模型Subdiv Net
突破二维跟三维,是否可以用到各种数据维度?
 外部注意力机制
外部注意力机制

Fitten Code编程助手

构建高效的多模态语言大模型

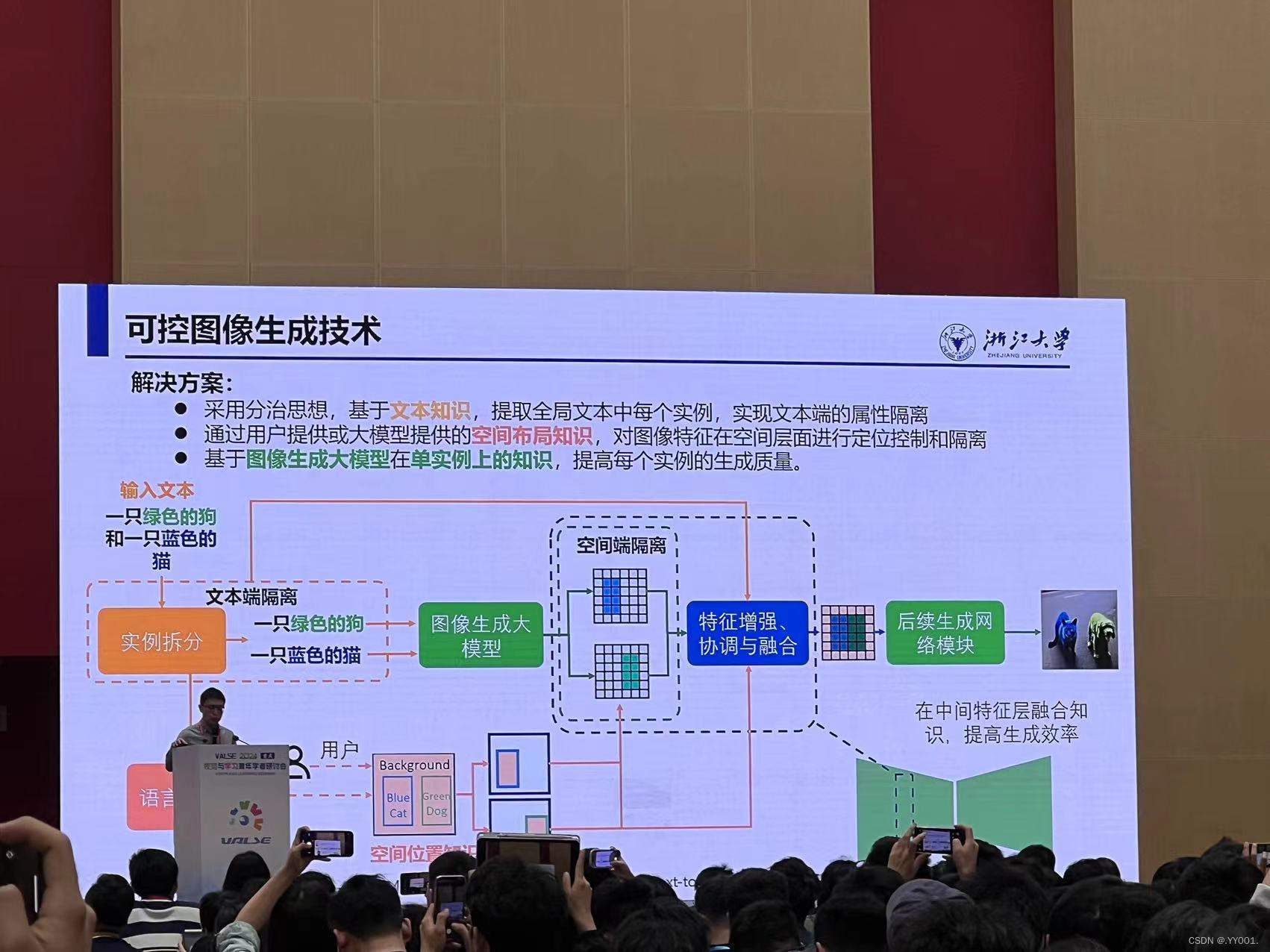
 可控图像生成技术
可控图像生成技术
具身智能

离身智能与具身智能的差异

多模态视觉融合方法是否存在性能极限?

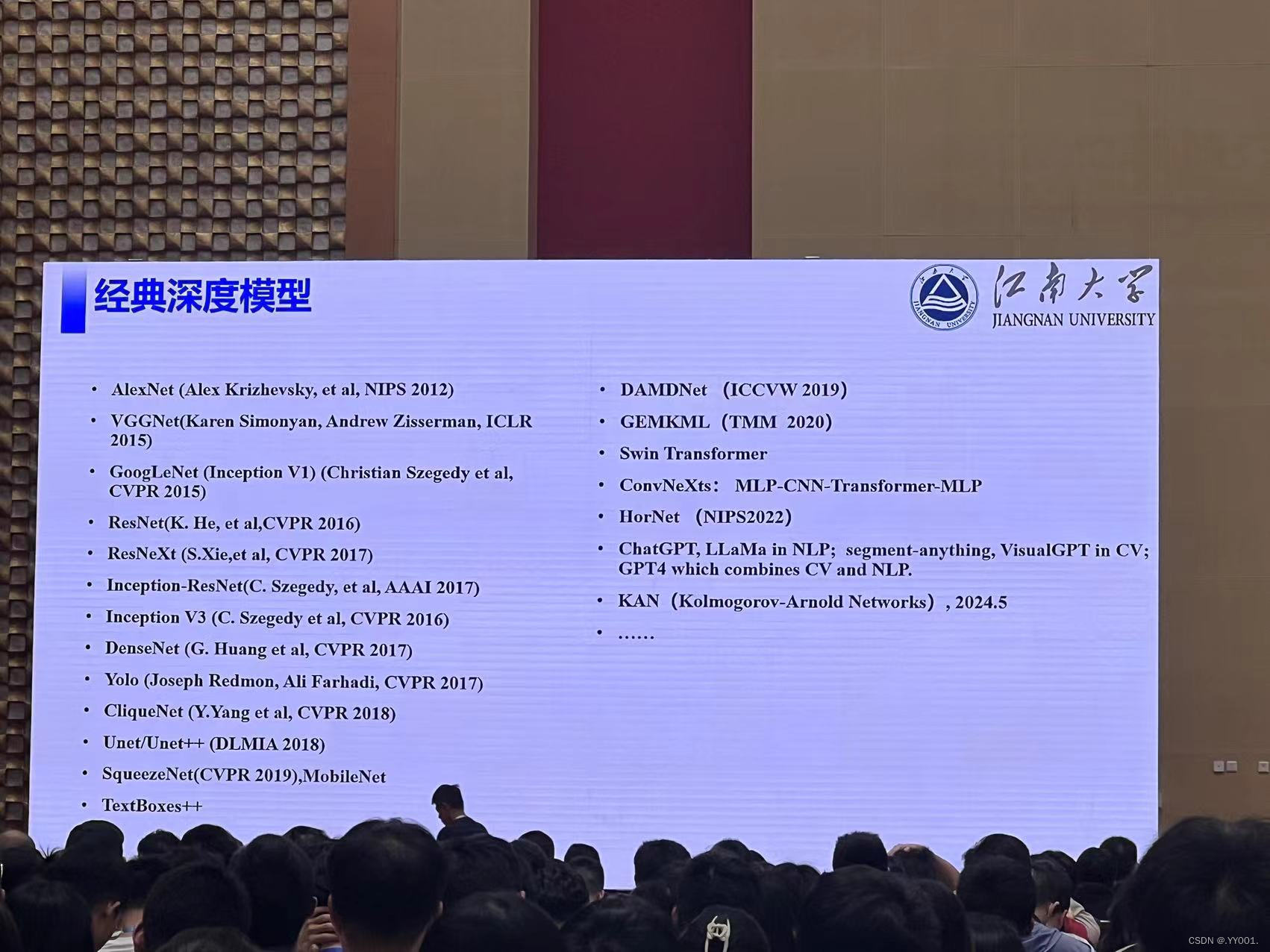
经典深度模型
深度学习面临的挑战

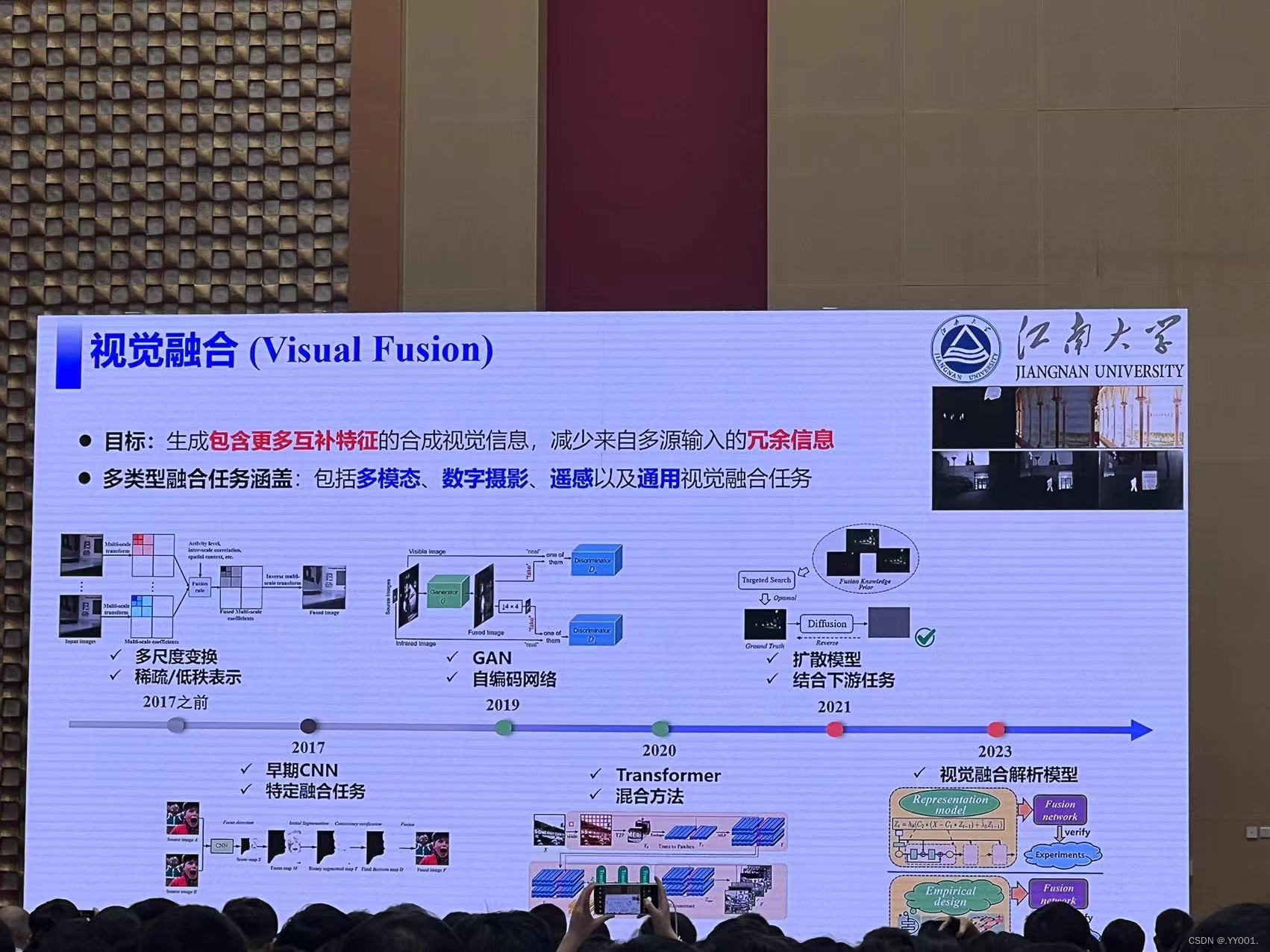
视觉融合
视觉融合的应用领域
 评价方法:客观与主观
评价方法:客观与主观

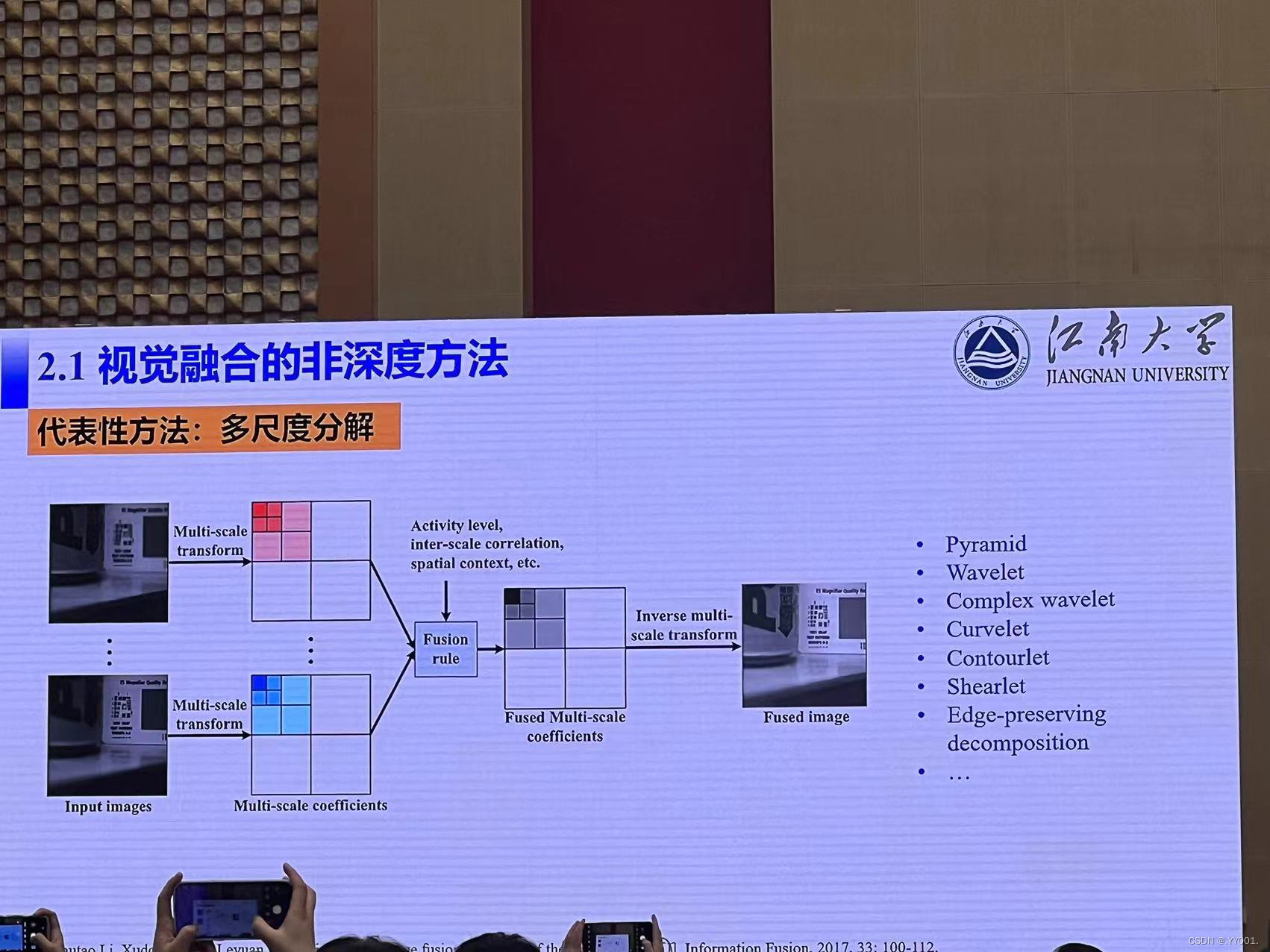
视觉融合的非深度方法

代表性方法
视觉融合的深度方法

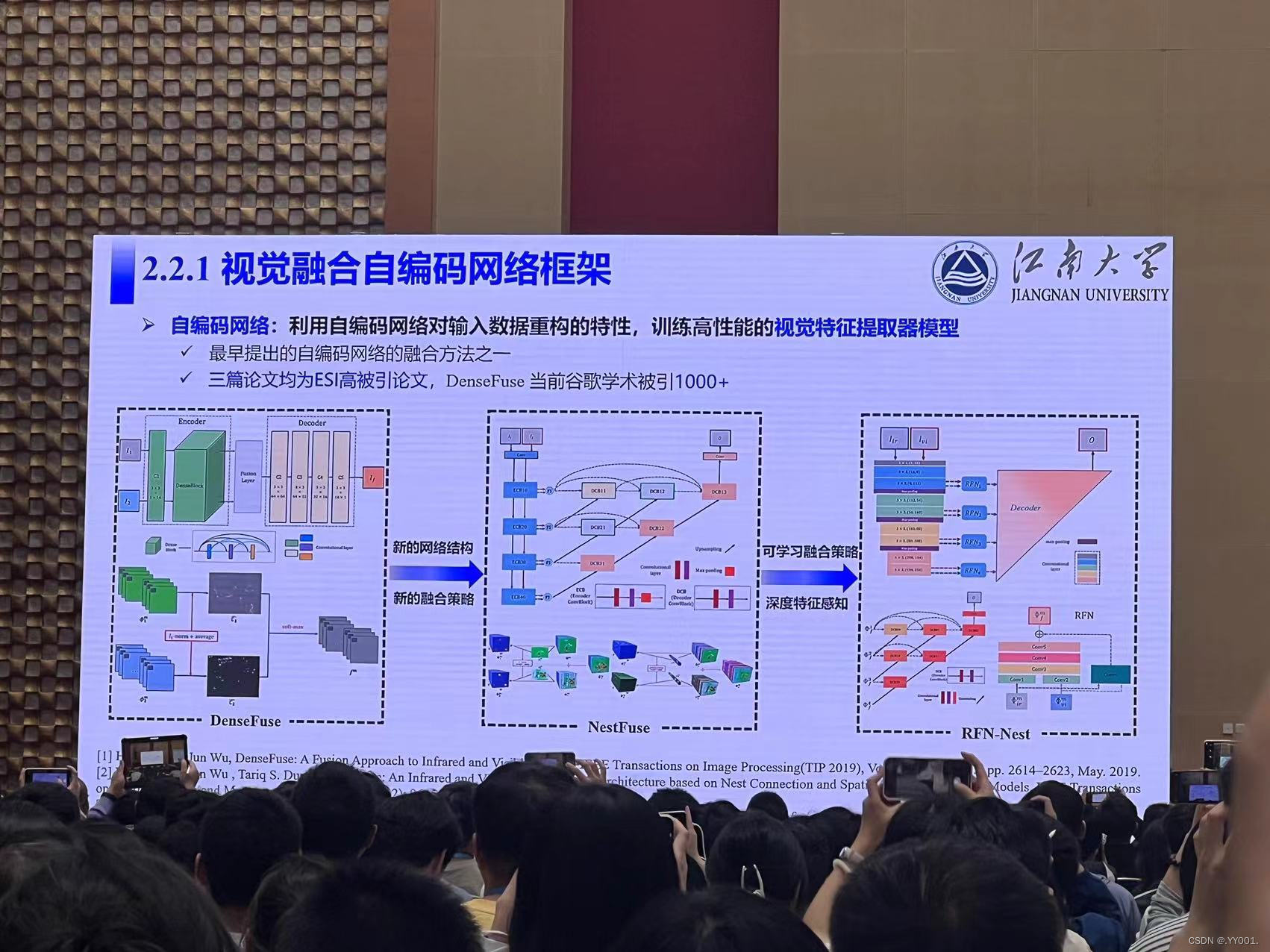
视觉融合自编码网络框架
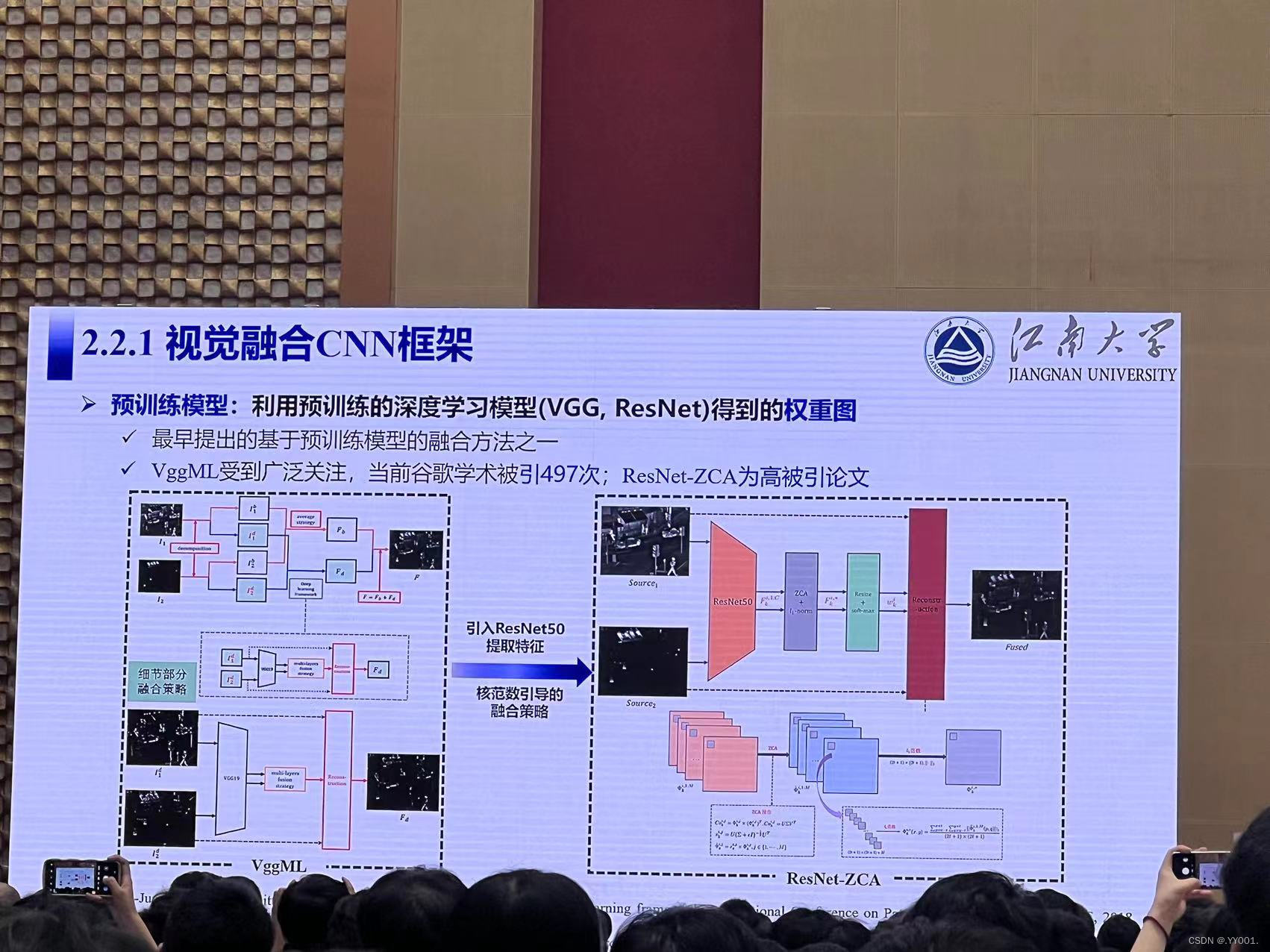
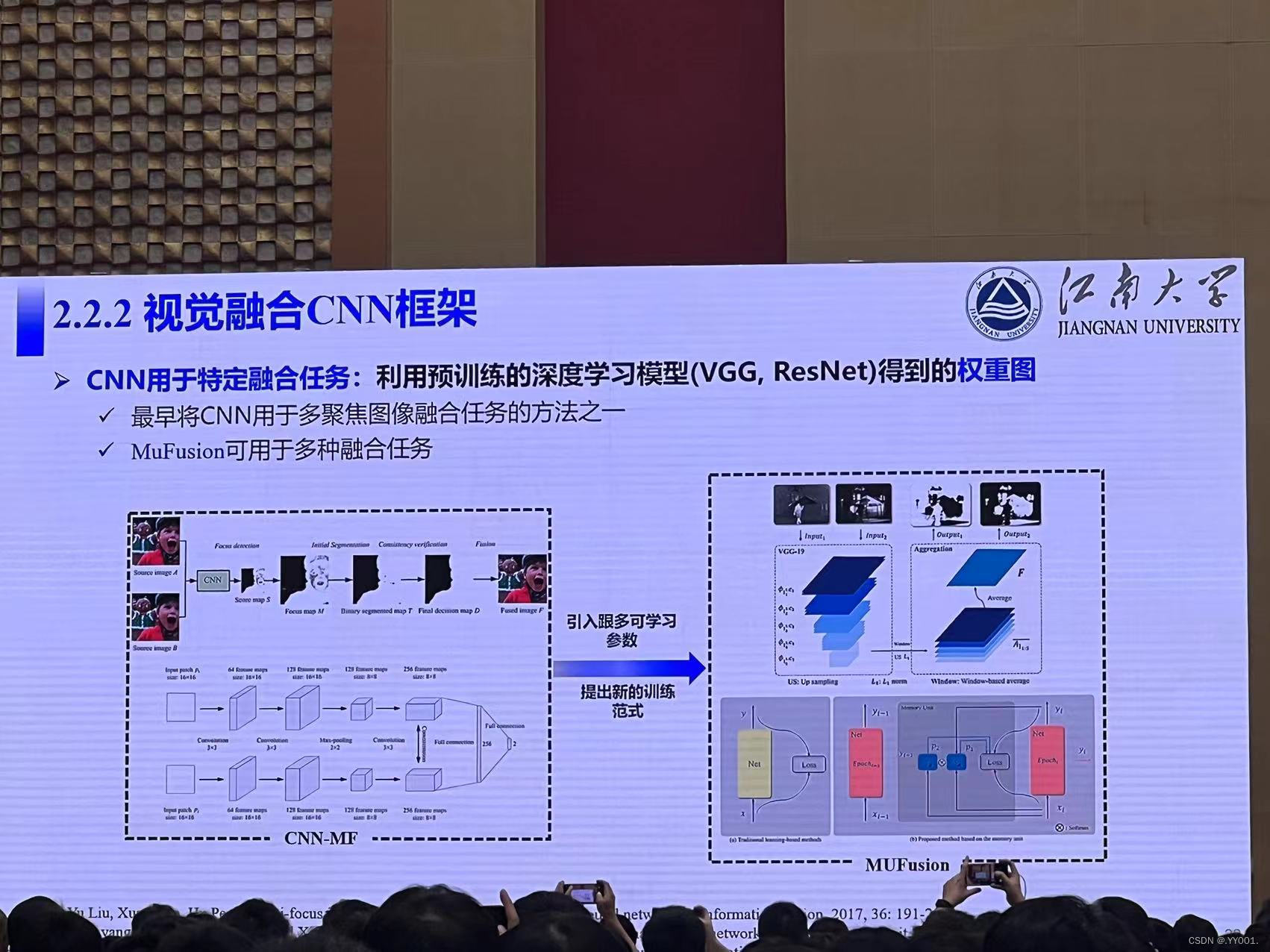
视觉融合CNN框架
视觉融合GAN框架



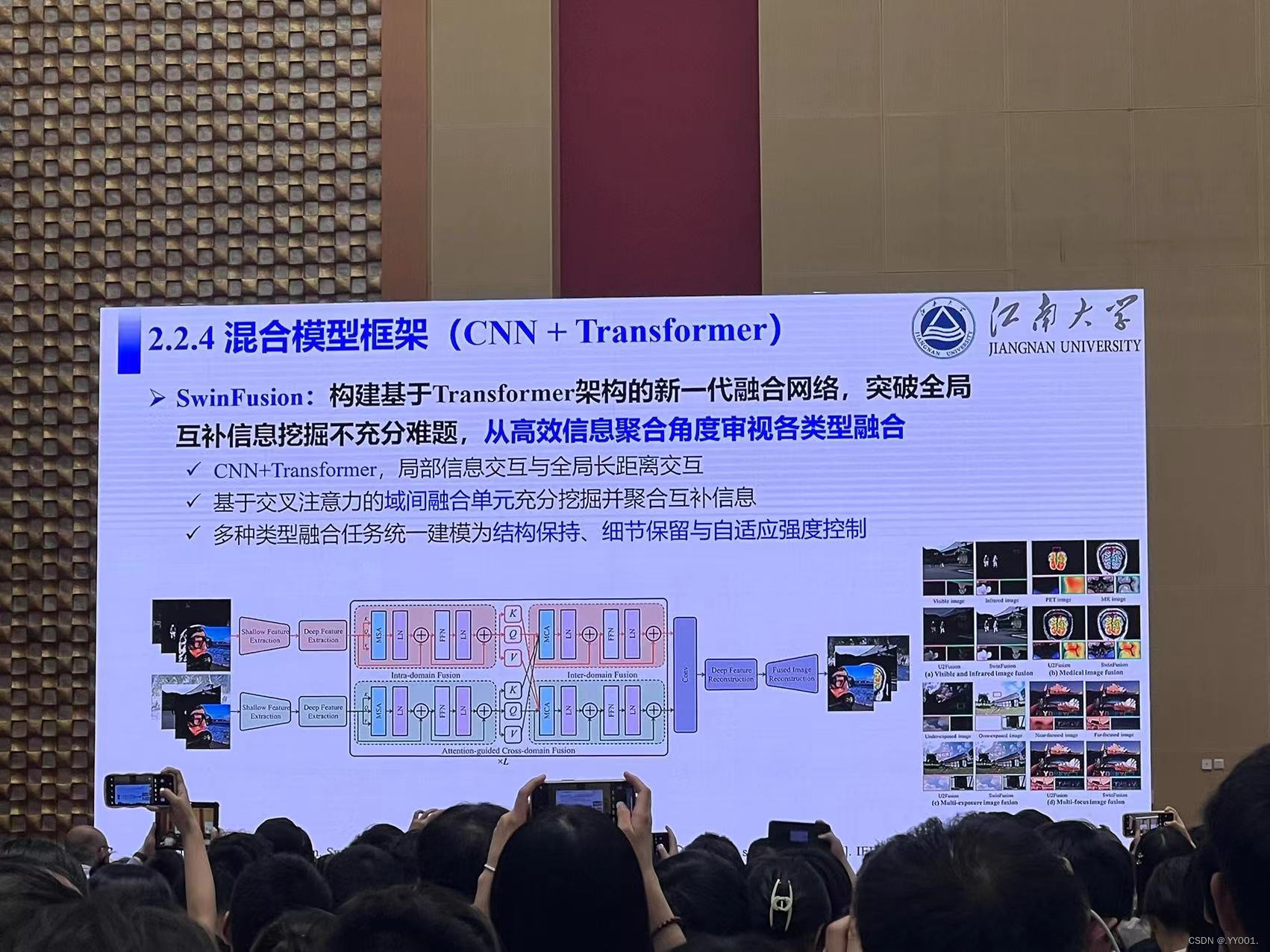
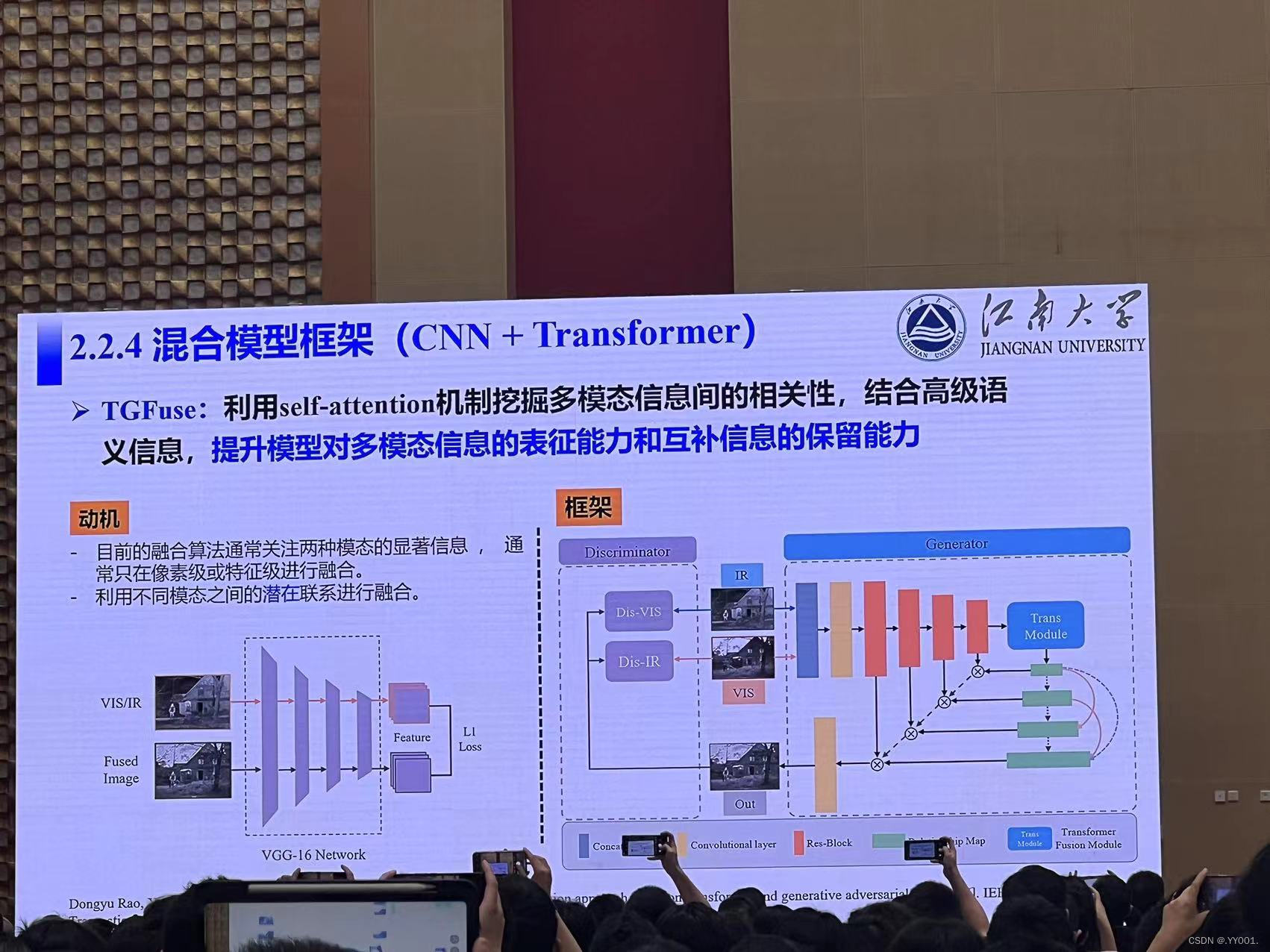
混合模型框架

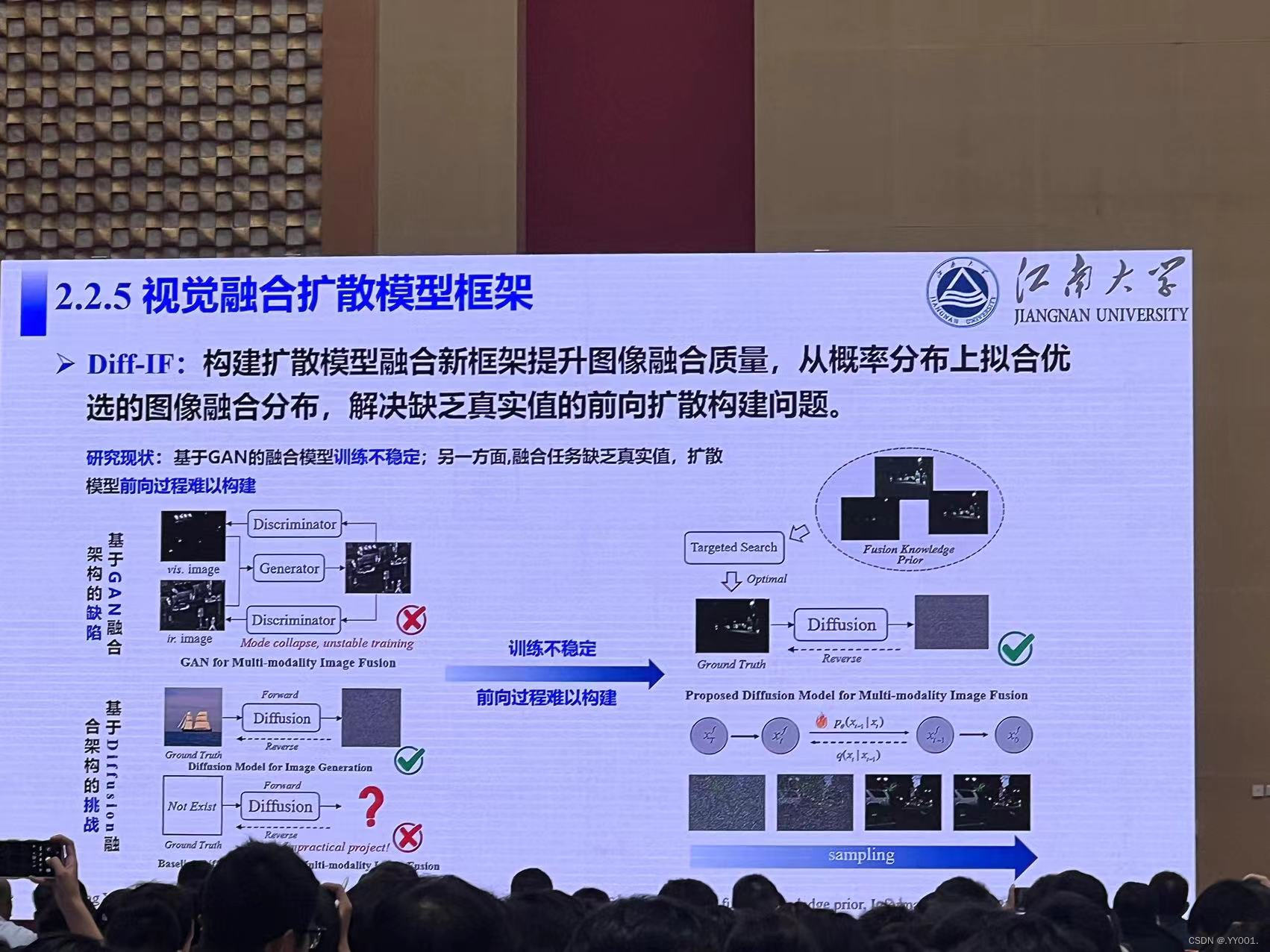
视觉融合扩散模型框架

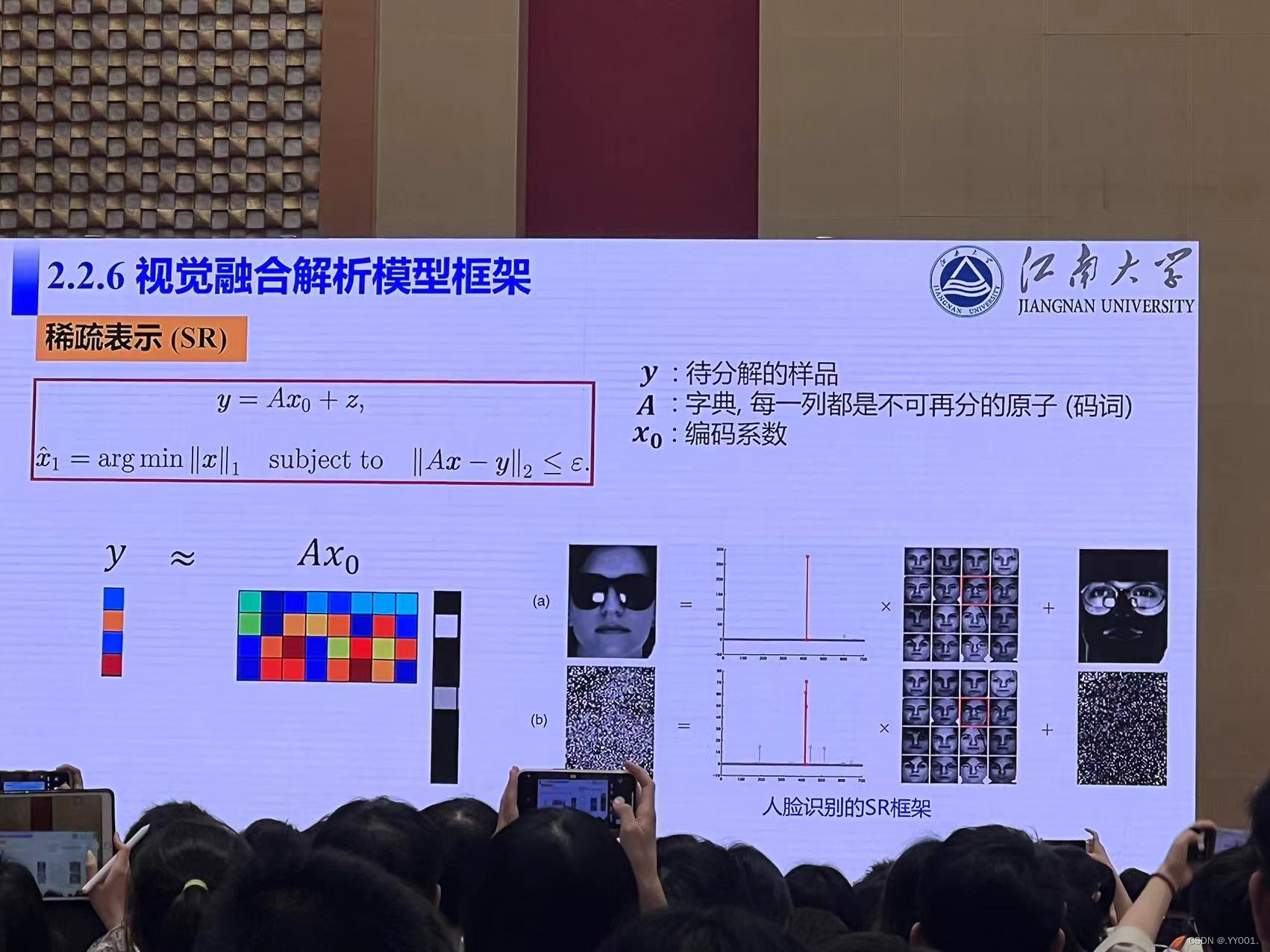
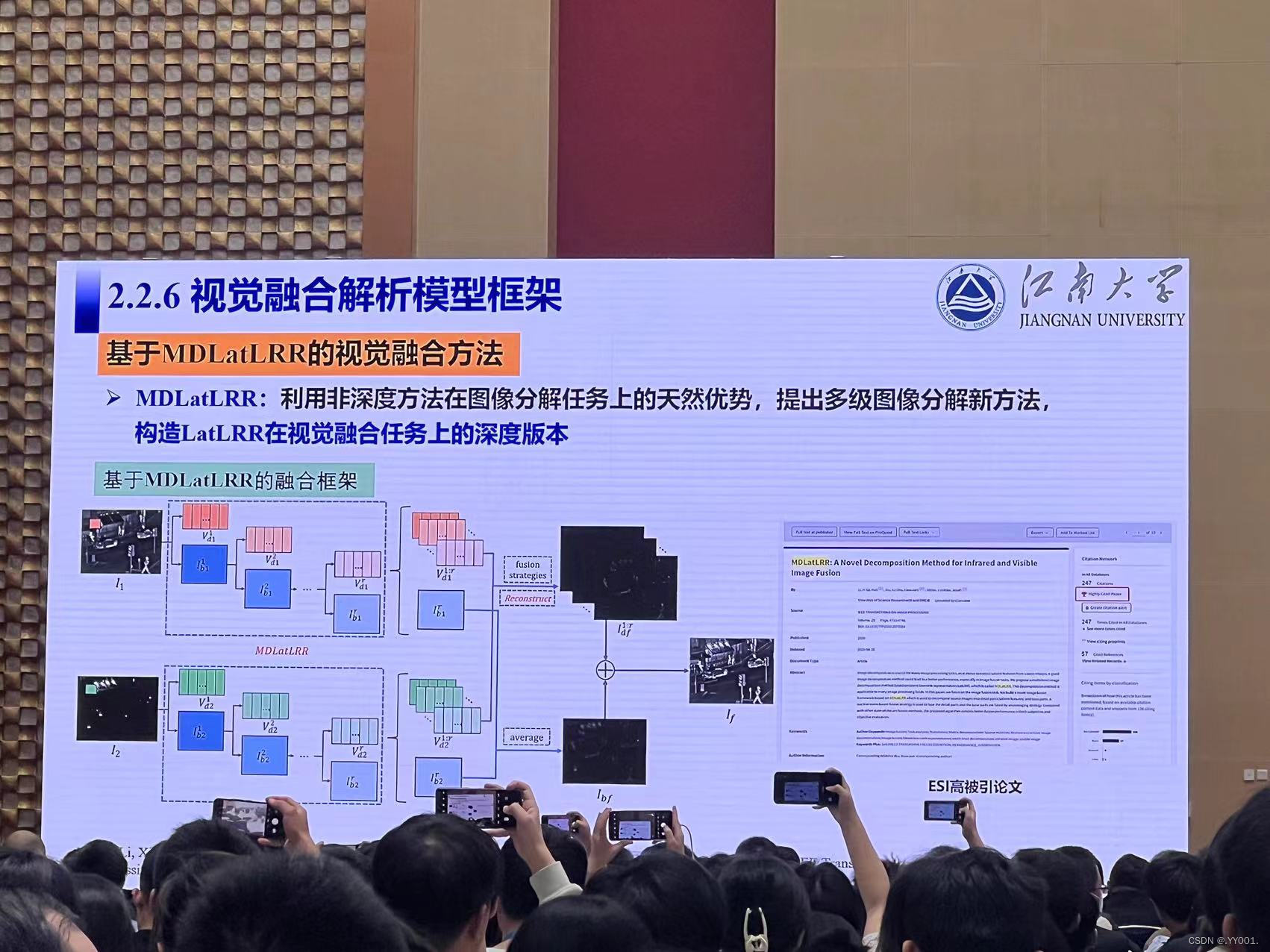
视觉融合解析模型框架


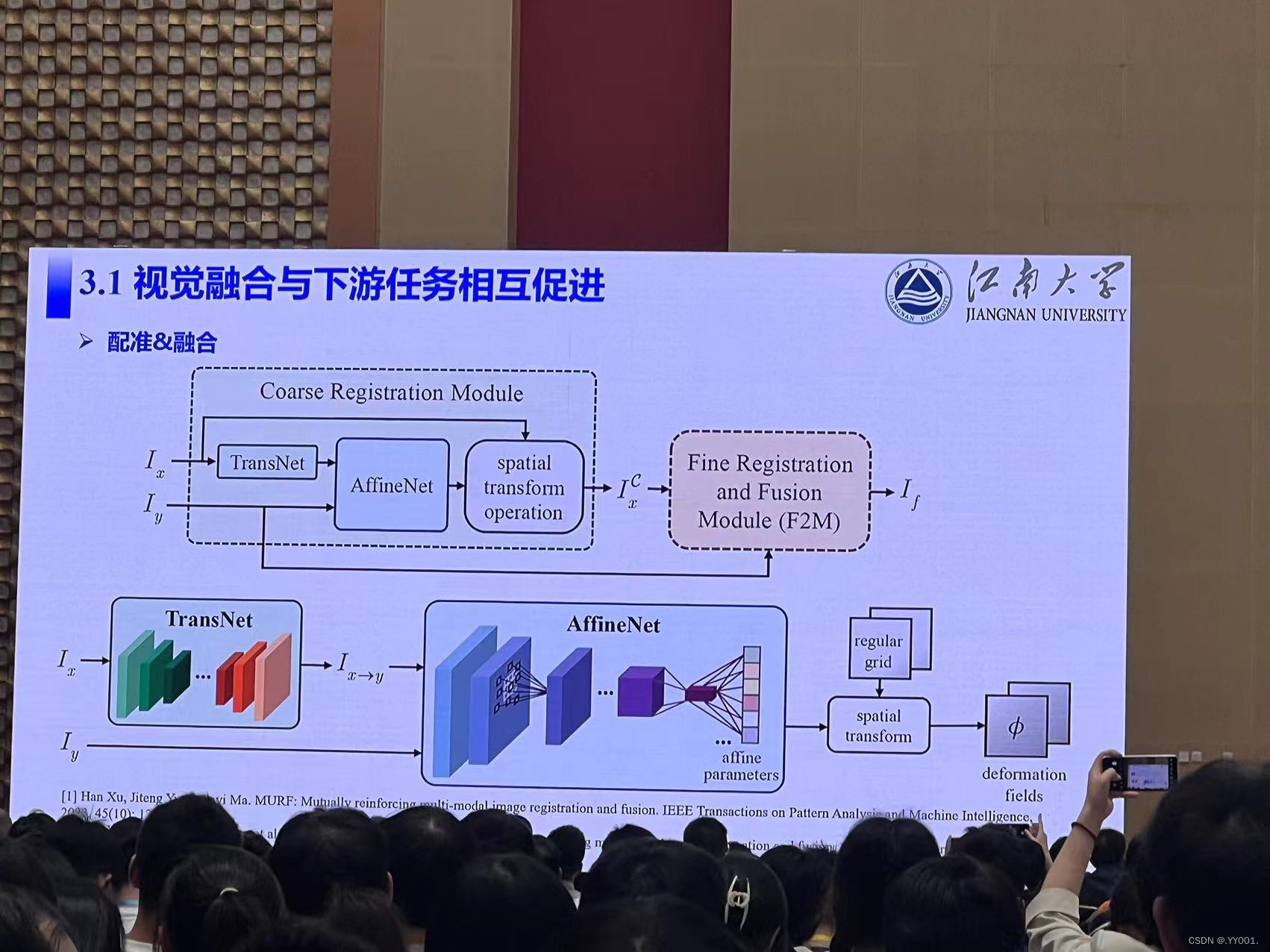
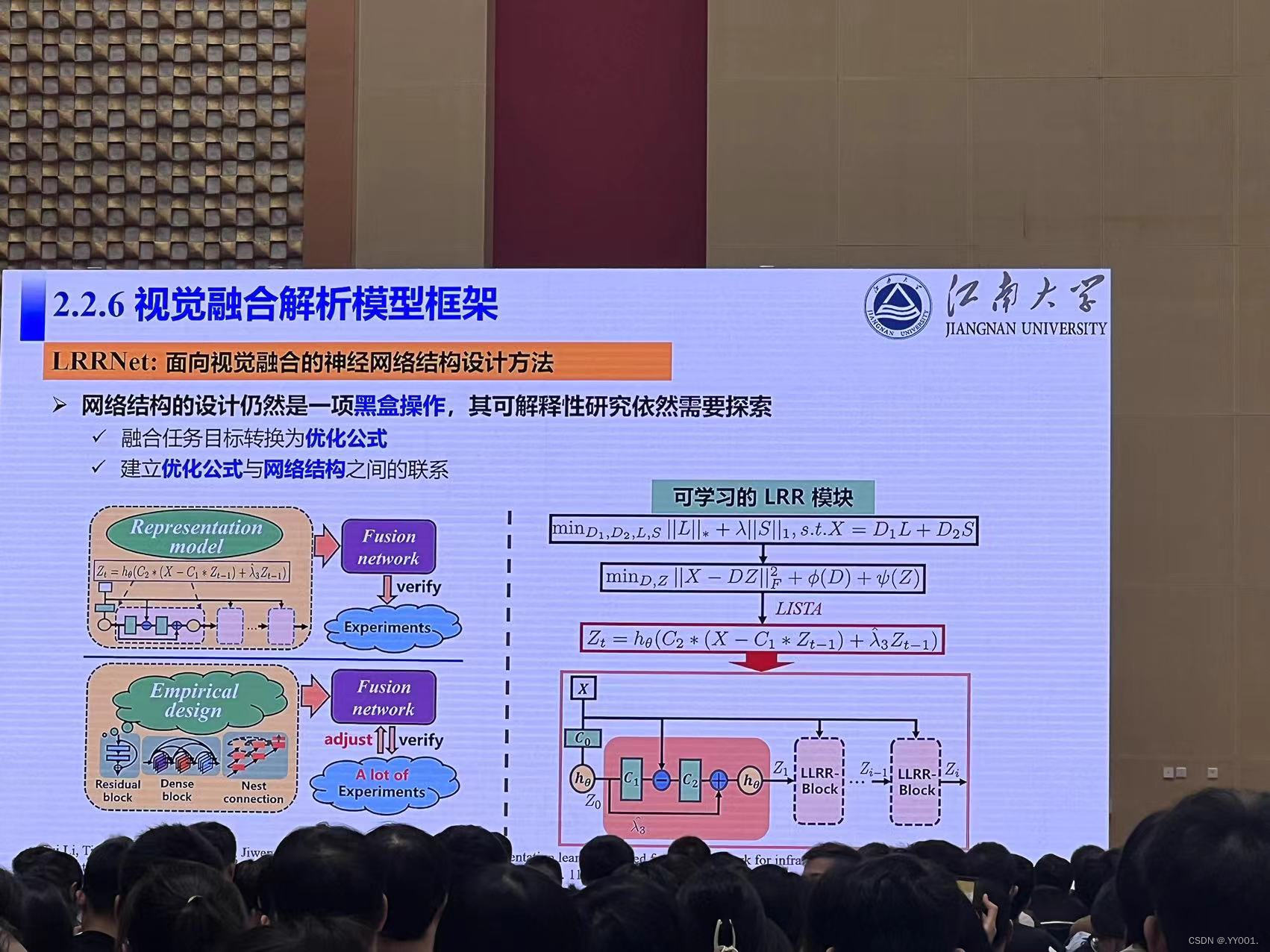 视觉融合与下游任务相互促进
视觉融合与下游任务相互促进


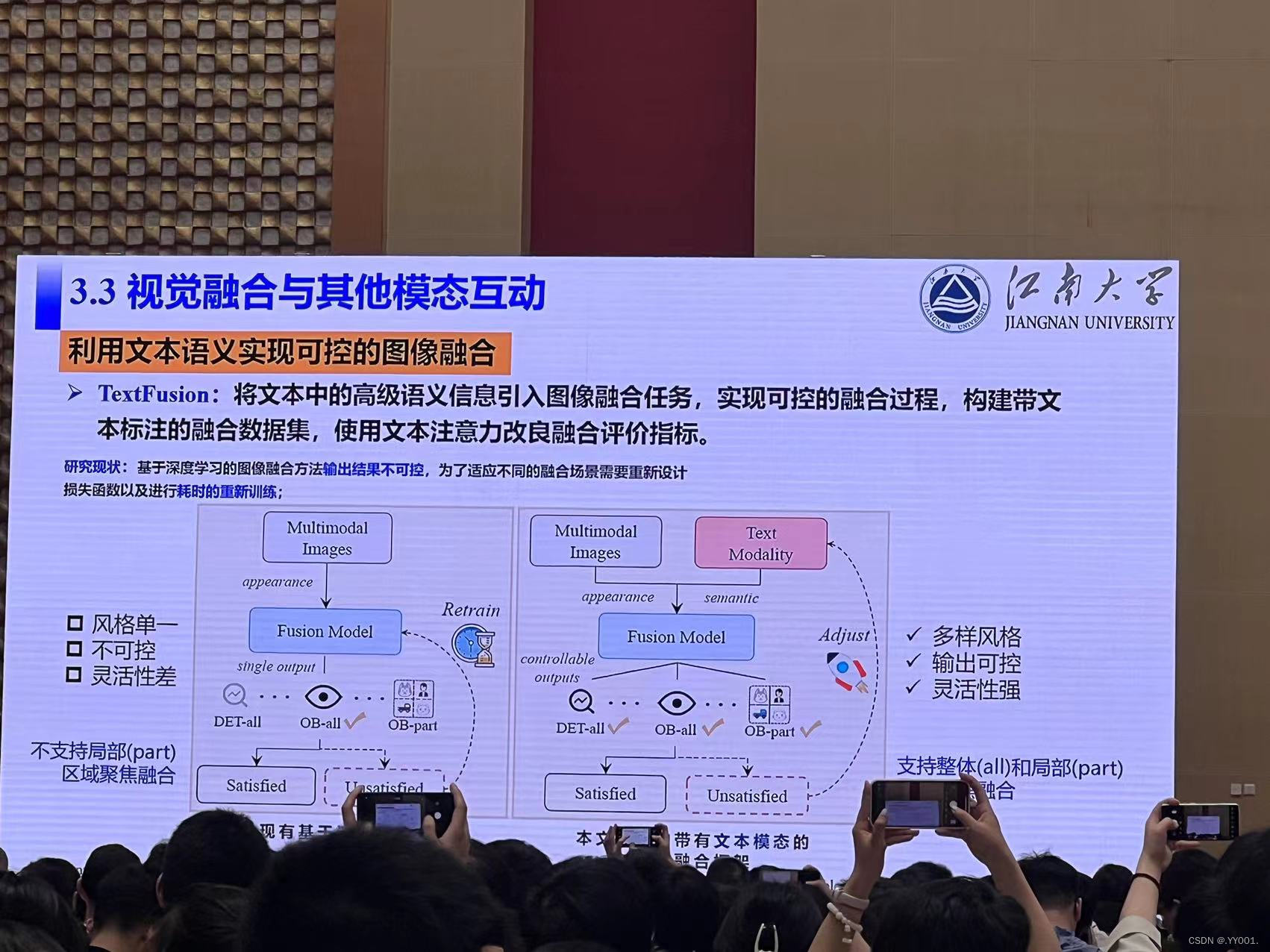
视觉融合与其他模态互动

结论

三维场景理解
挑战

数据集

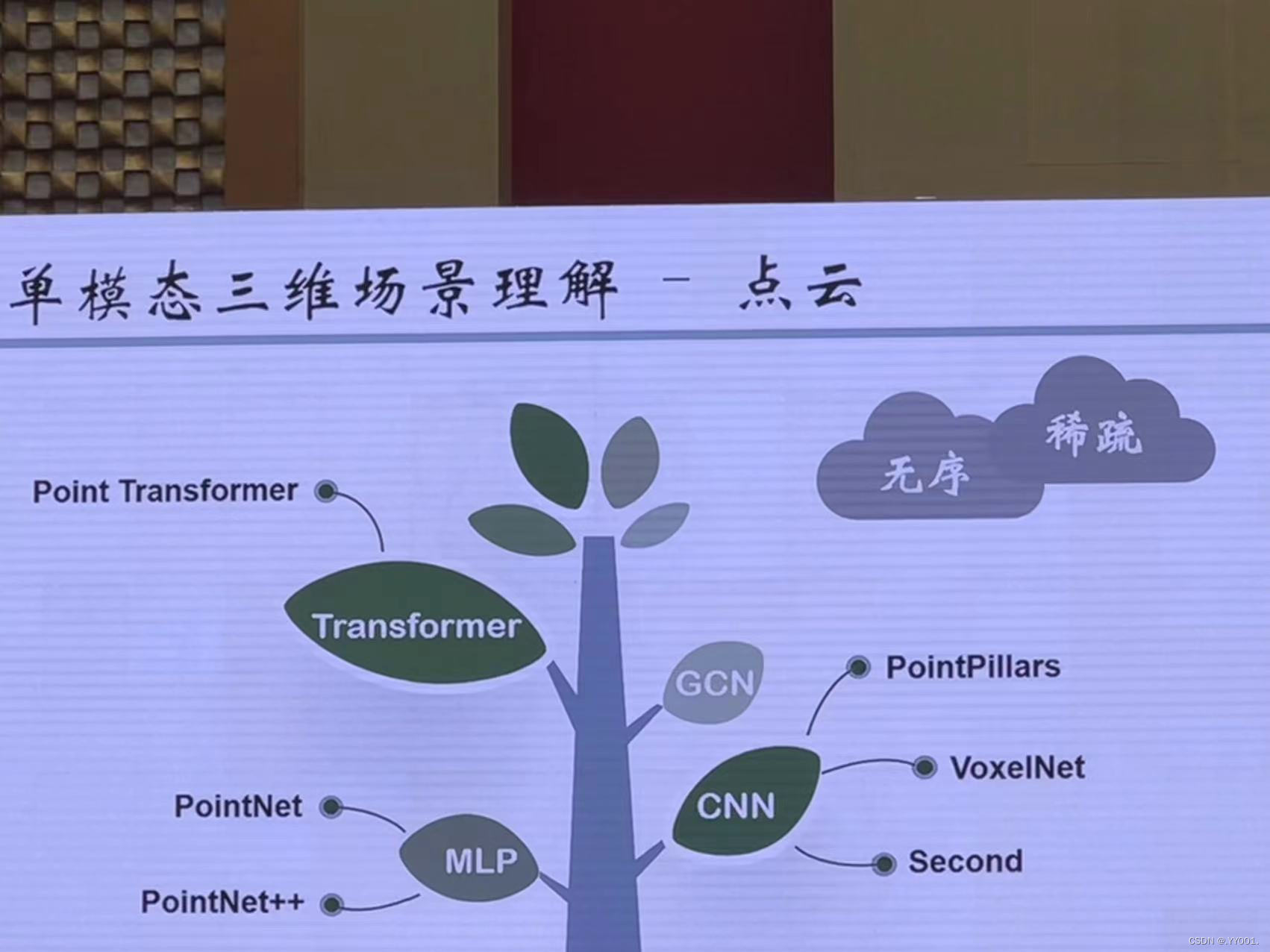
三维场景理解--点云
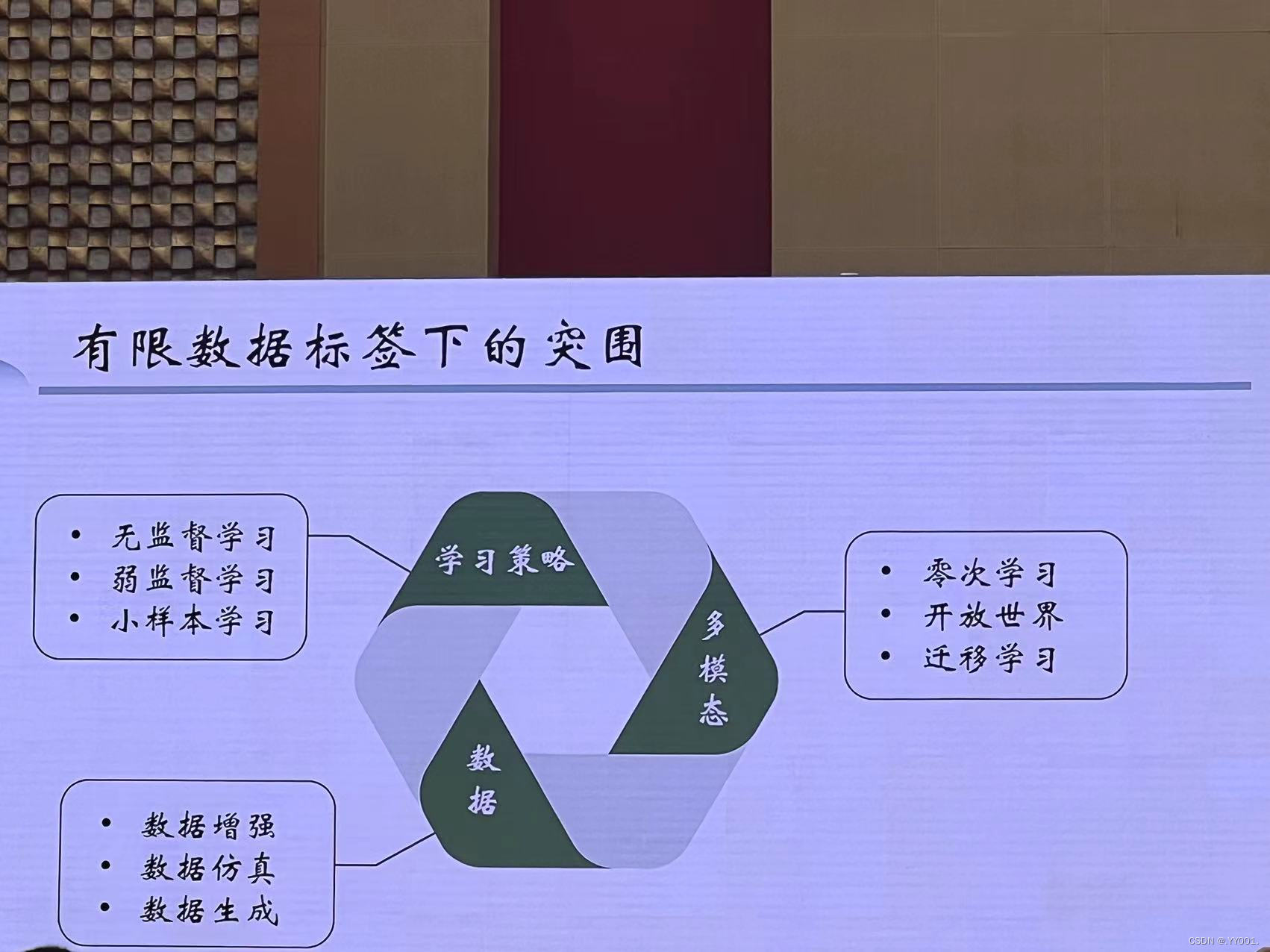
有限数据标签下的突围
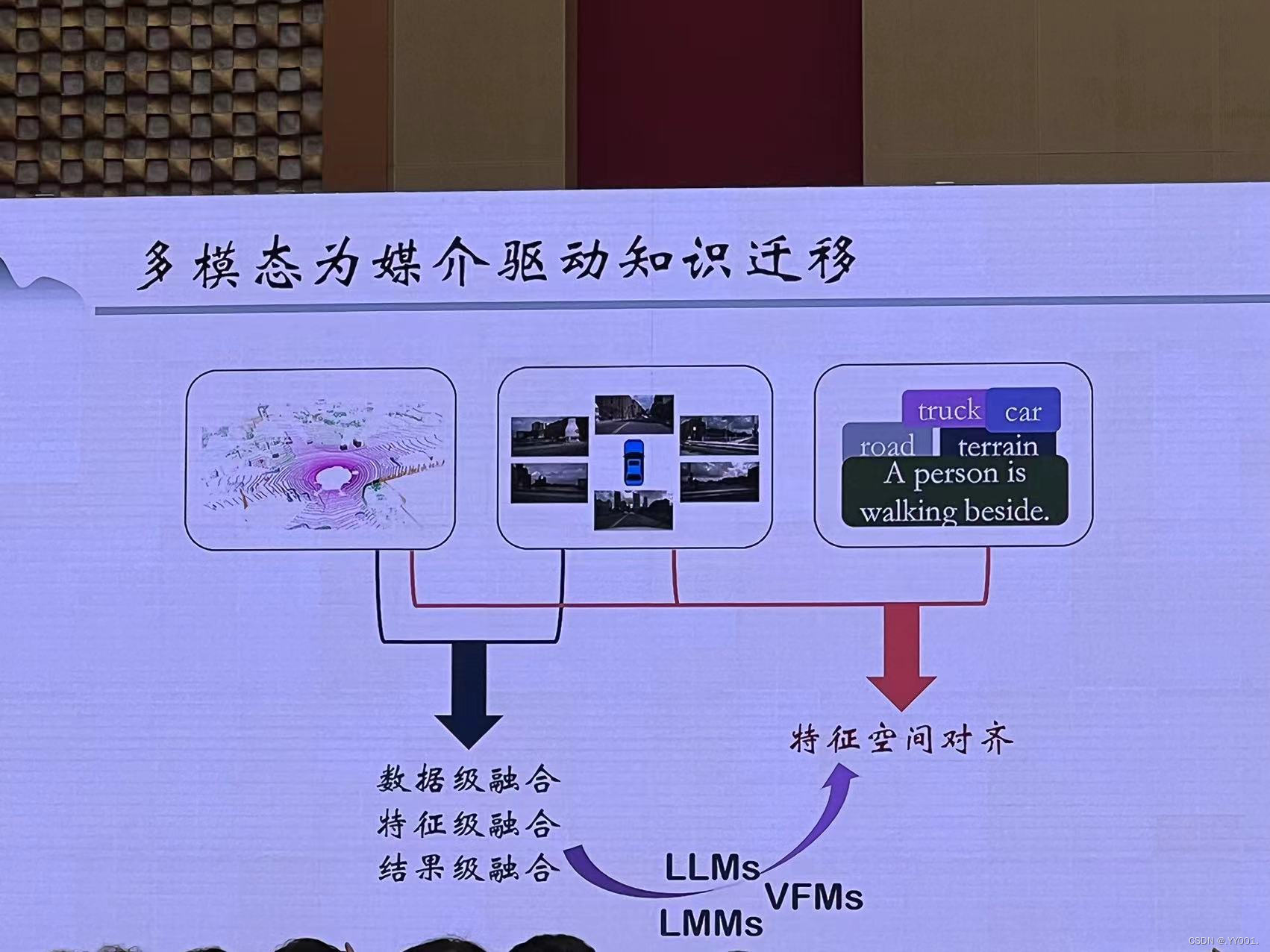
多模态为媒介驱动知识迁移
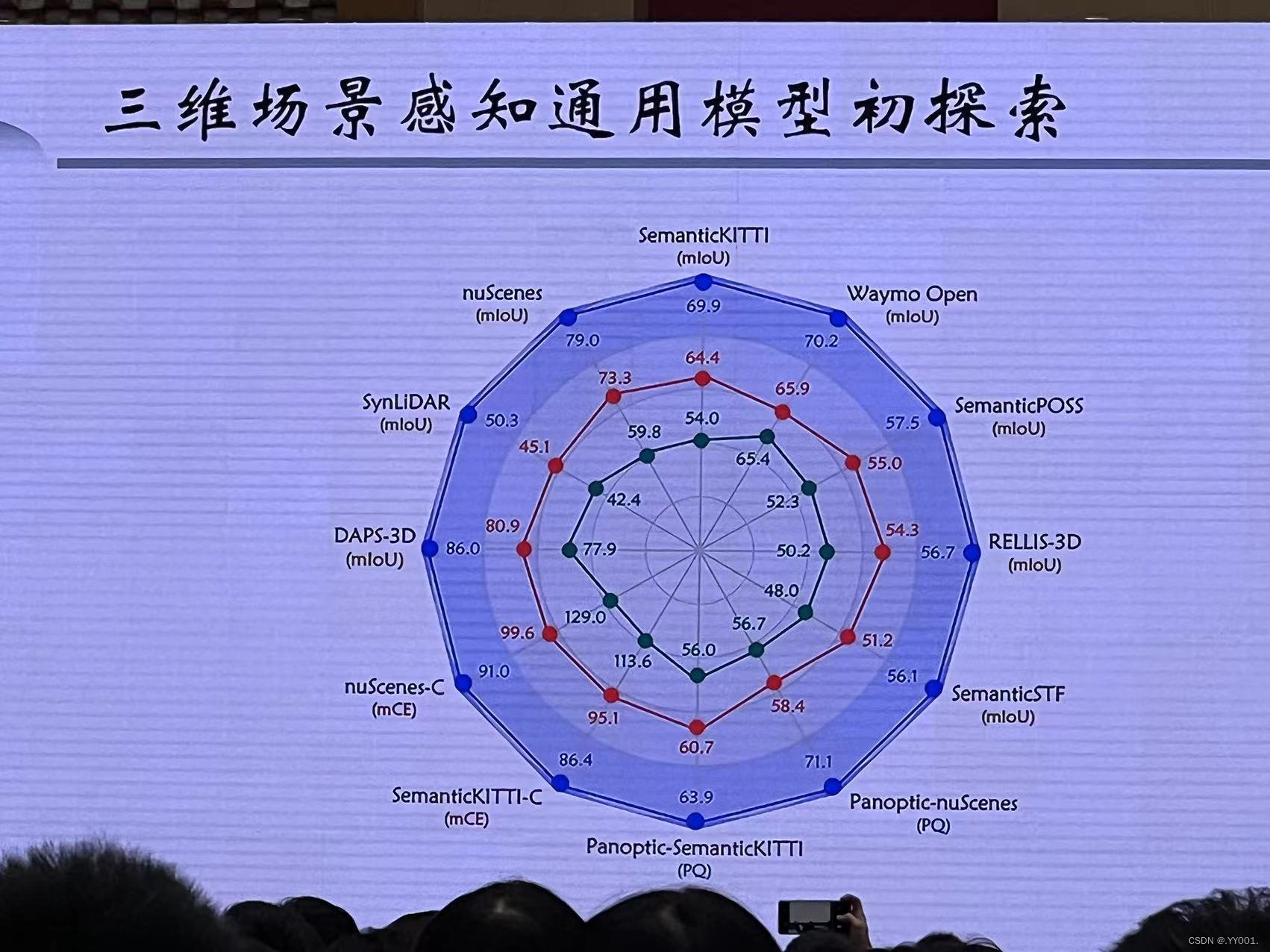
 三维场景感知通用模型初探索
三维场景感知通用模型初探索
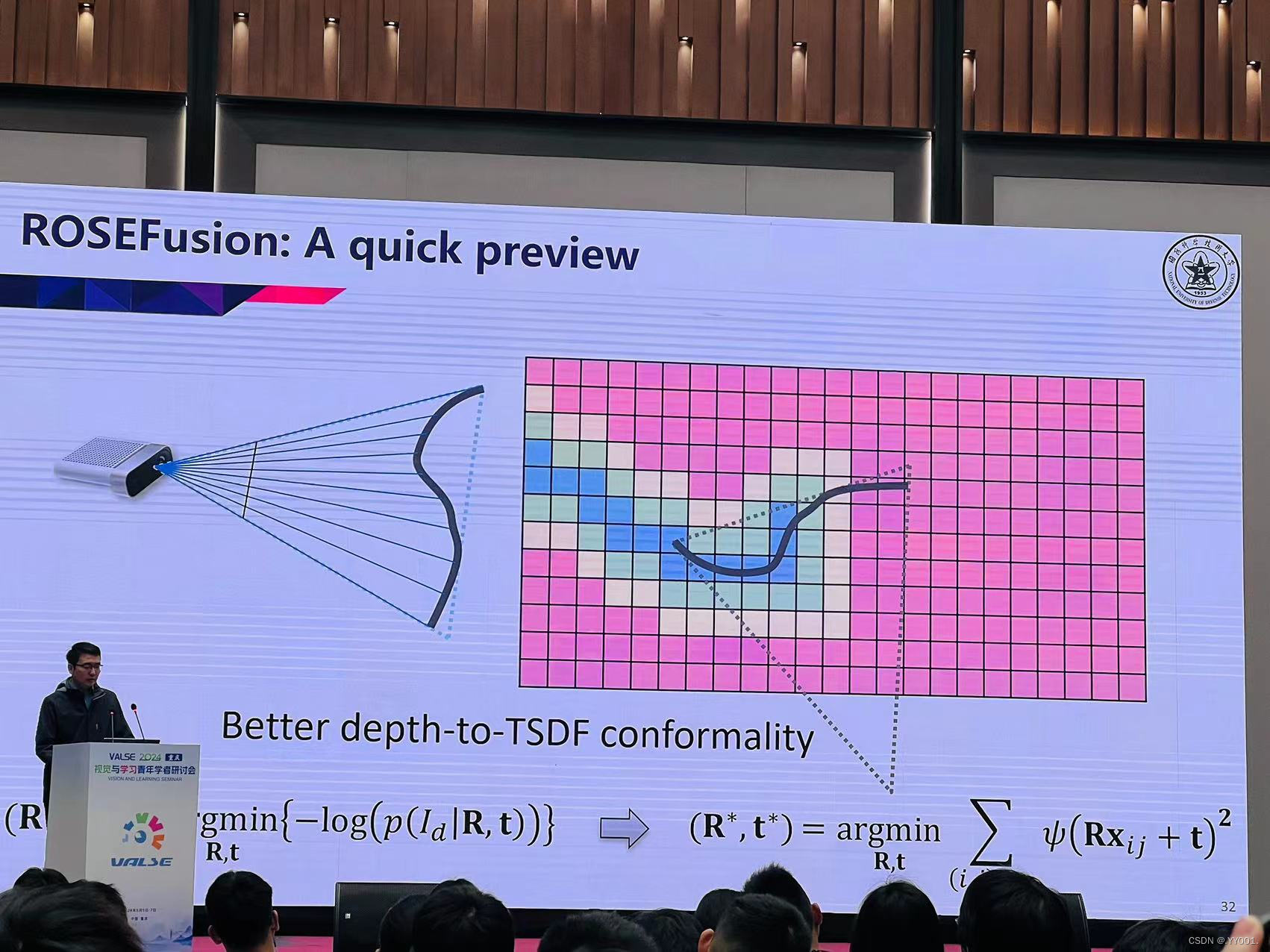
如何从2维学习方法复刻到3维


ROSEFusion: The key ideas

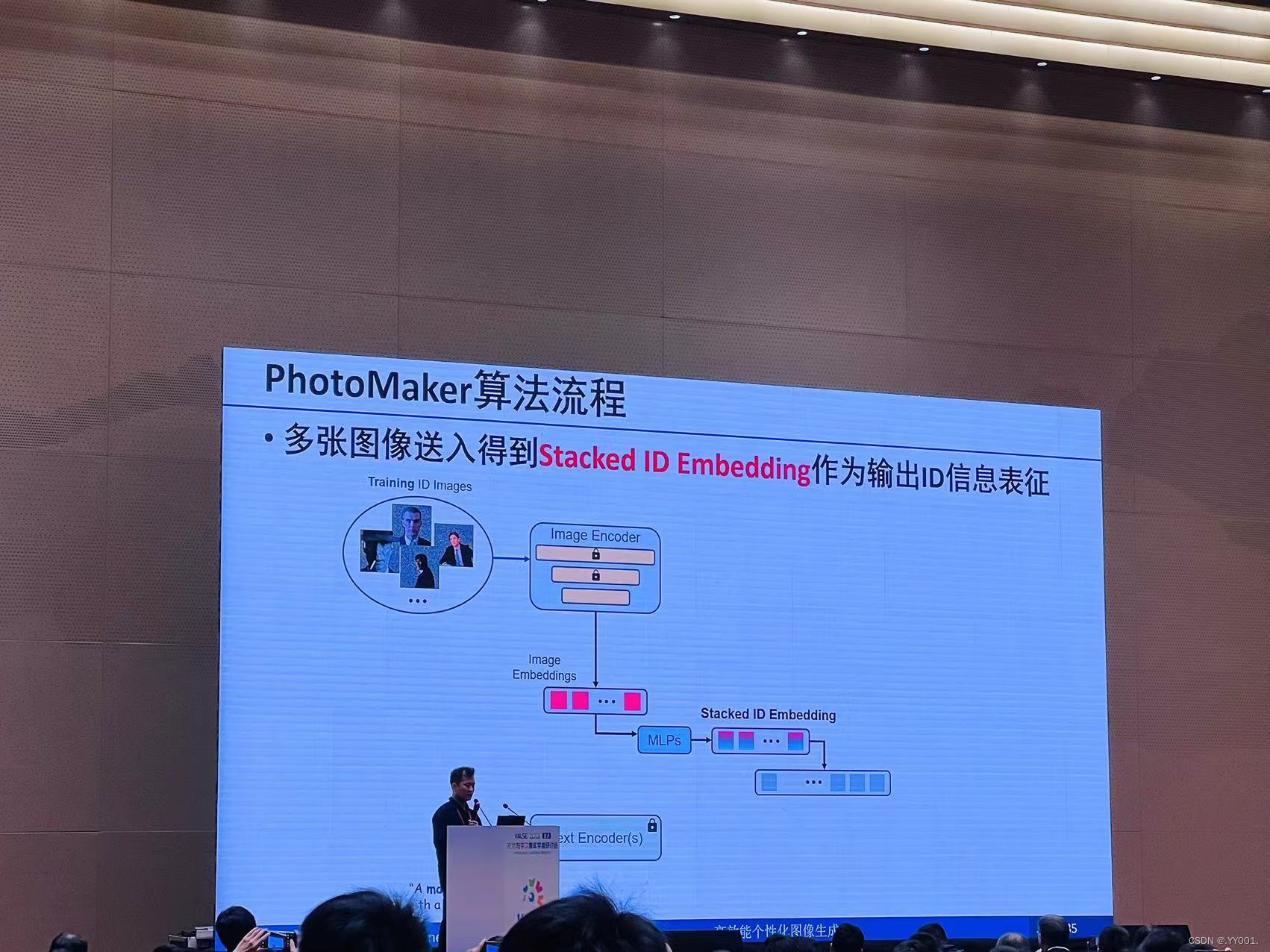
PhotoMaker算法流程
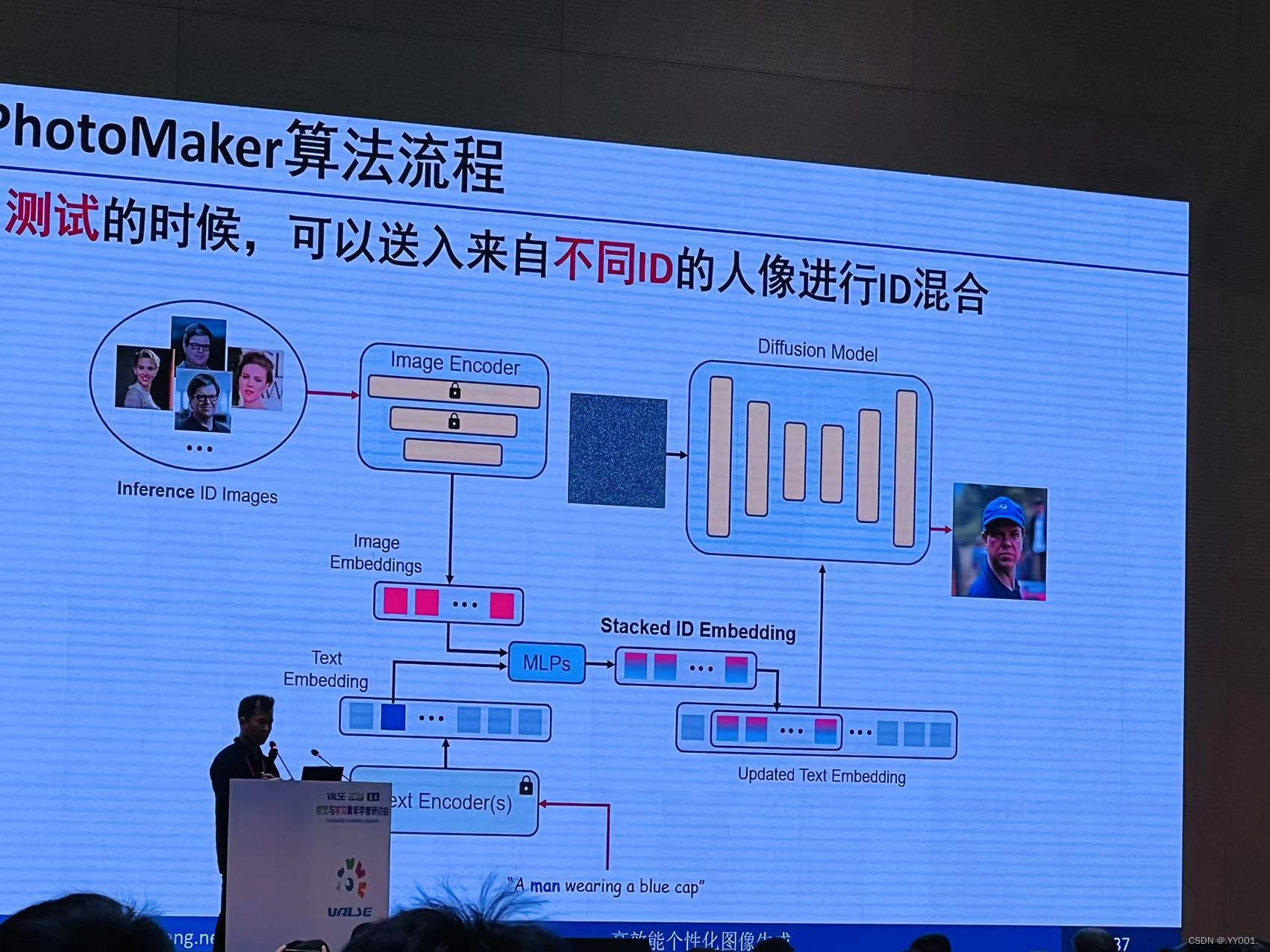
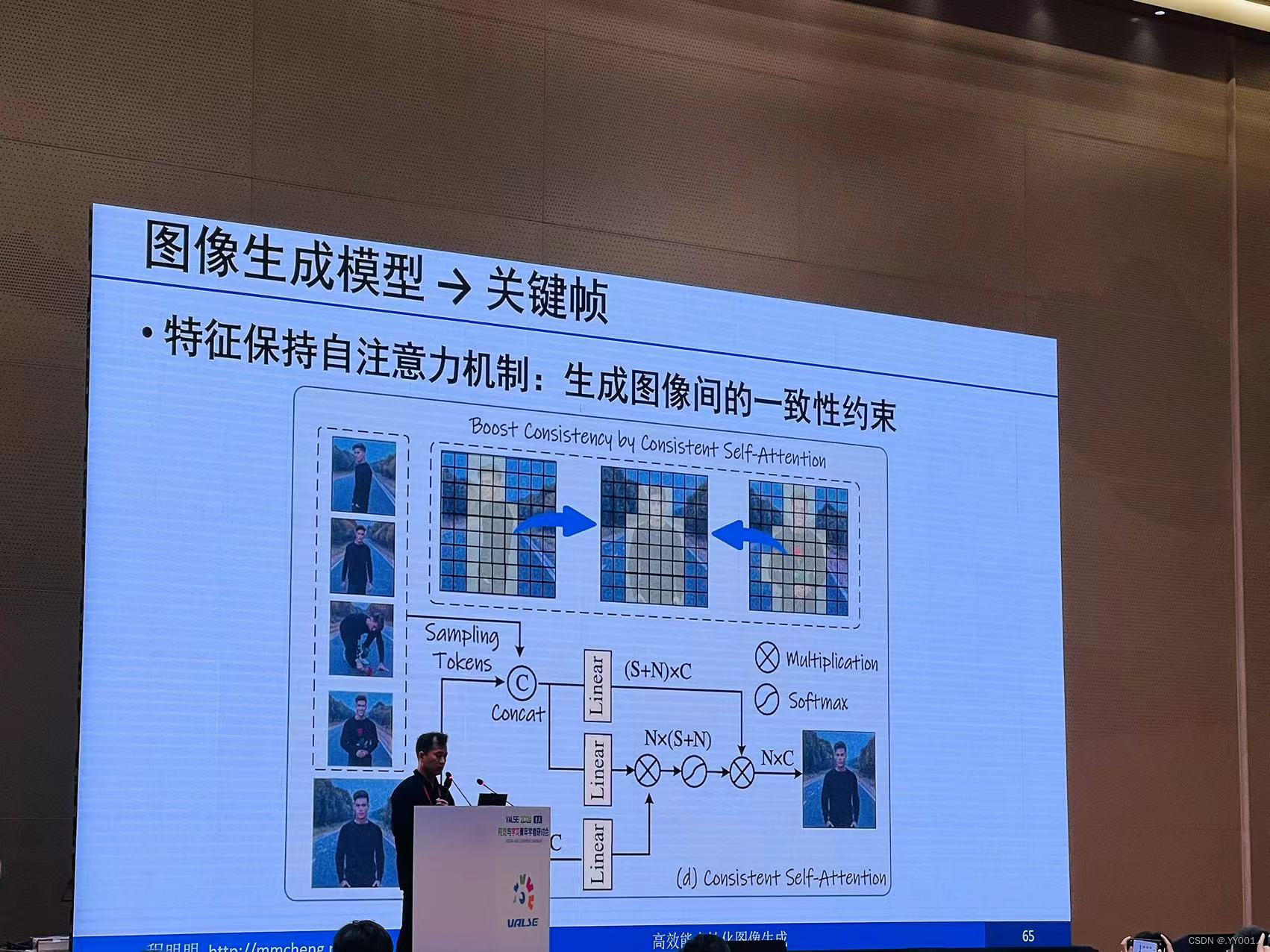
StoryDiffsion





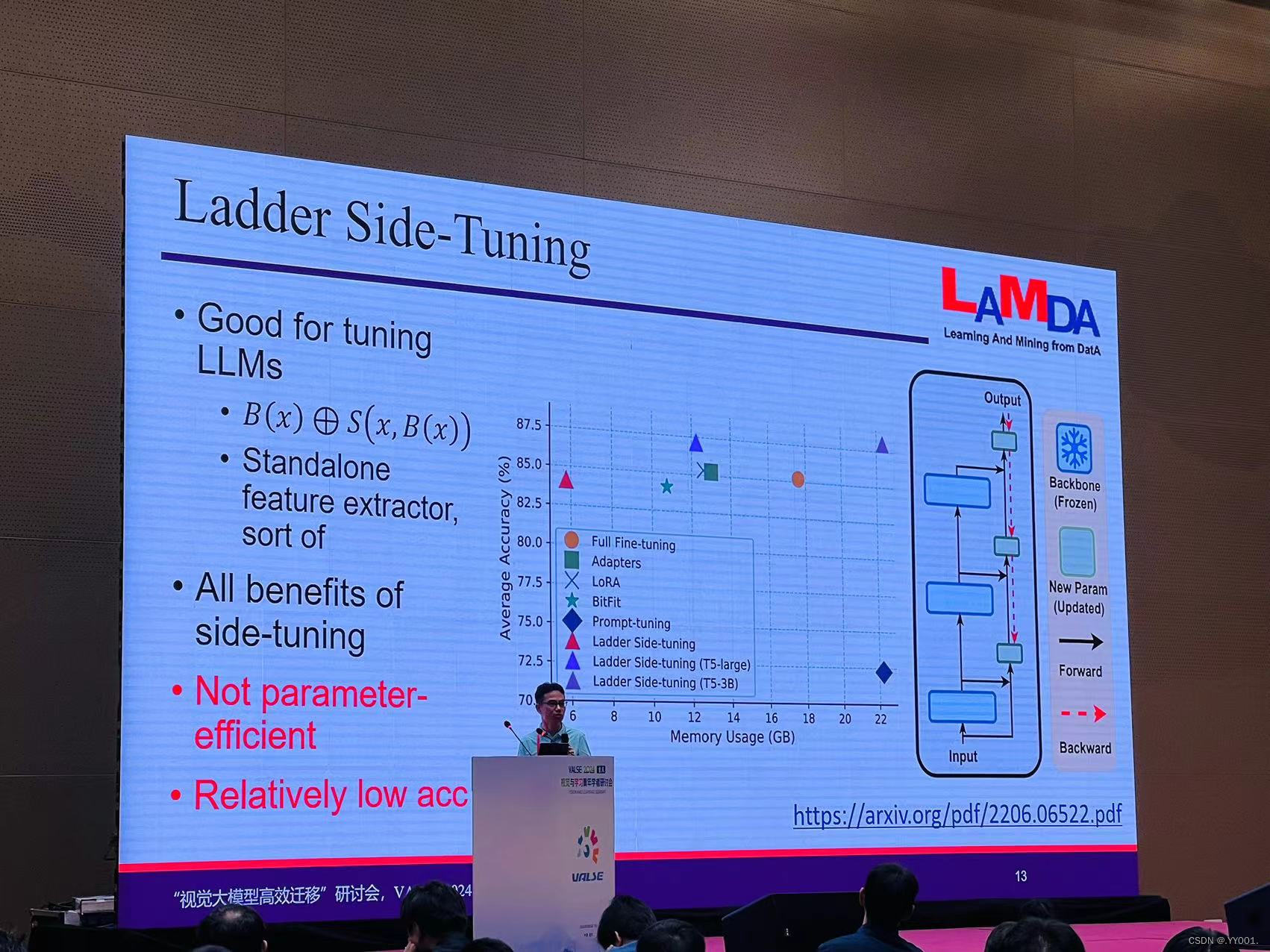
LAMDA





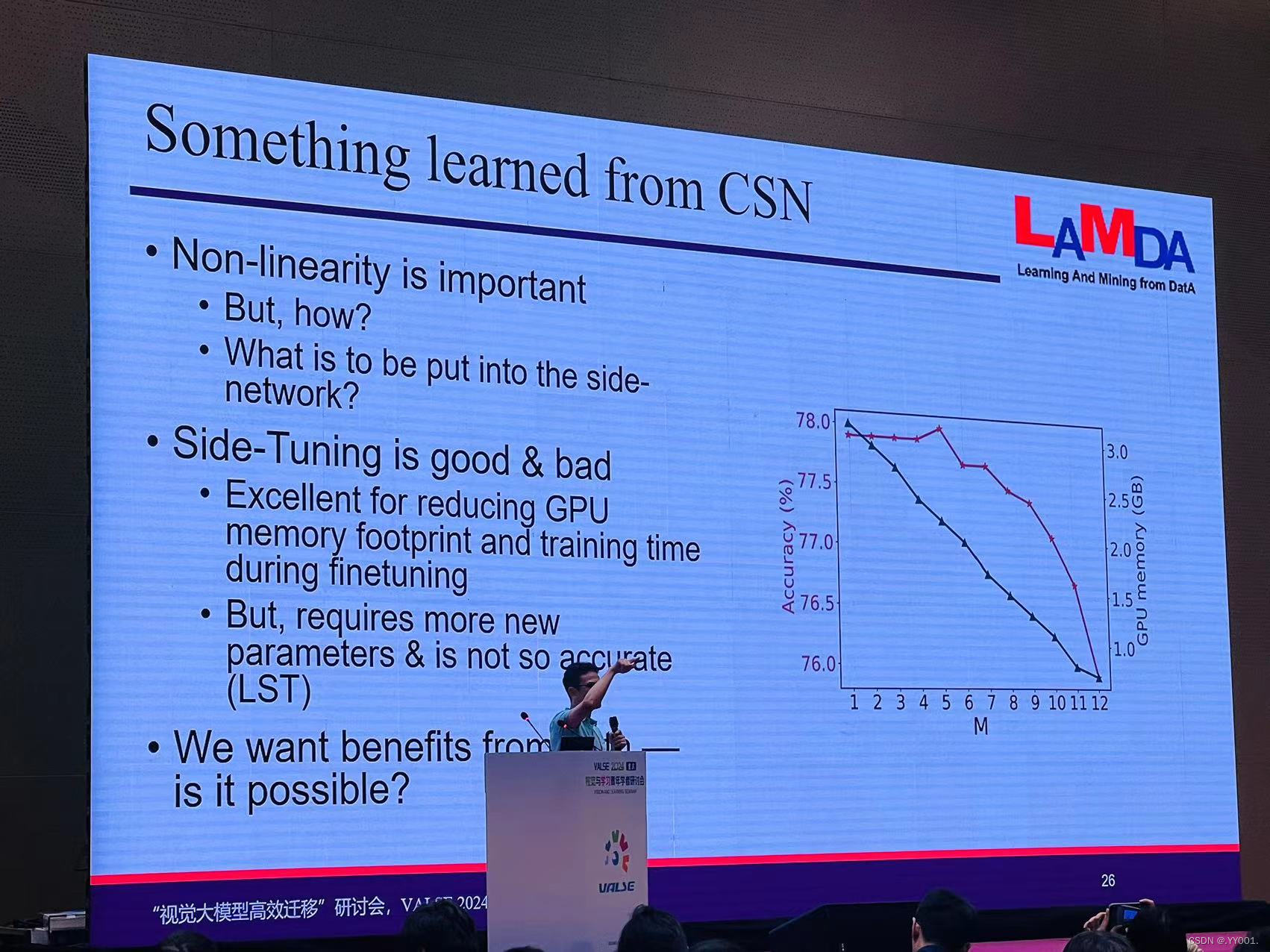
关键问题

CSN


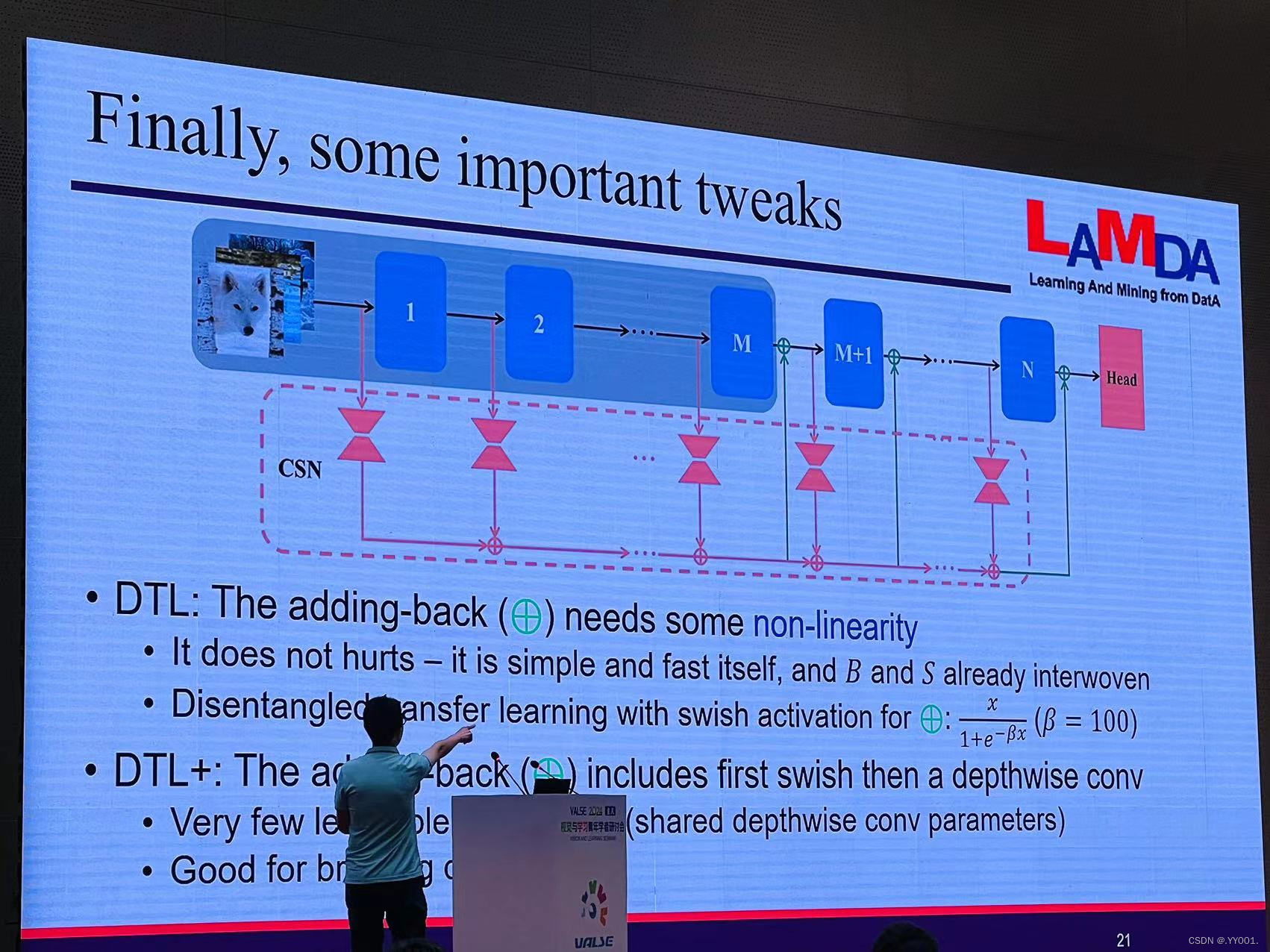
LAST


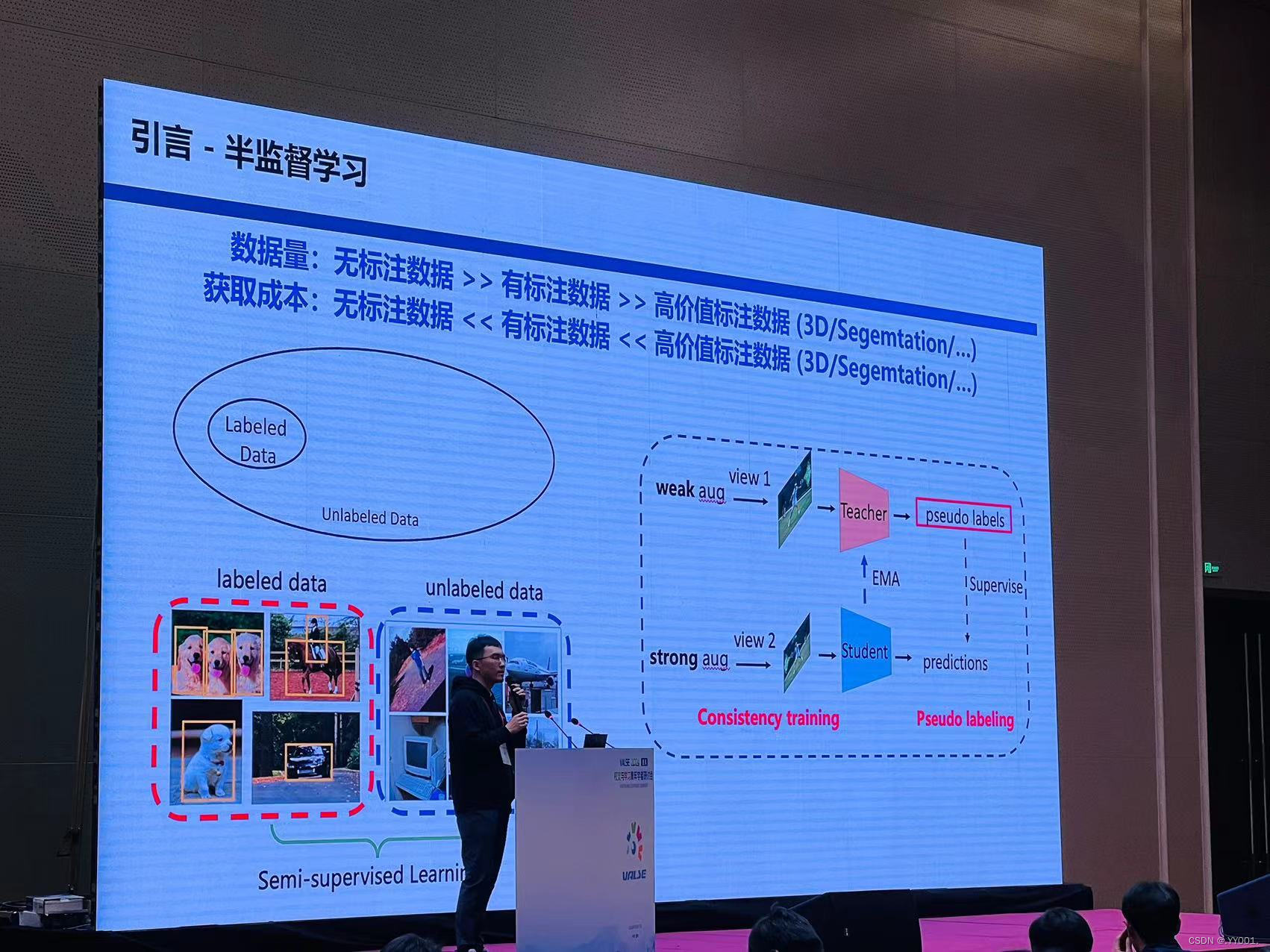
半监督学习


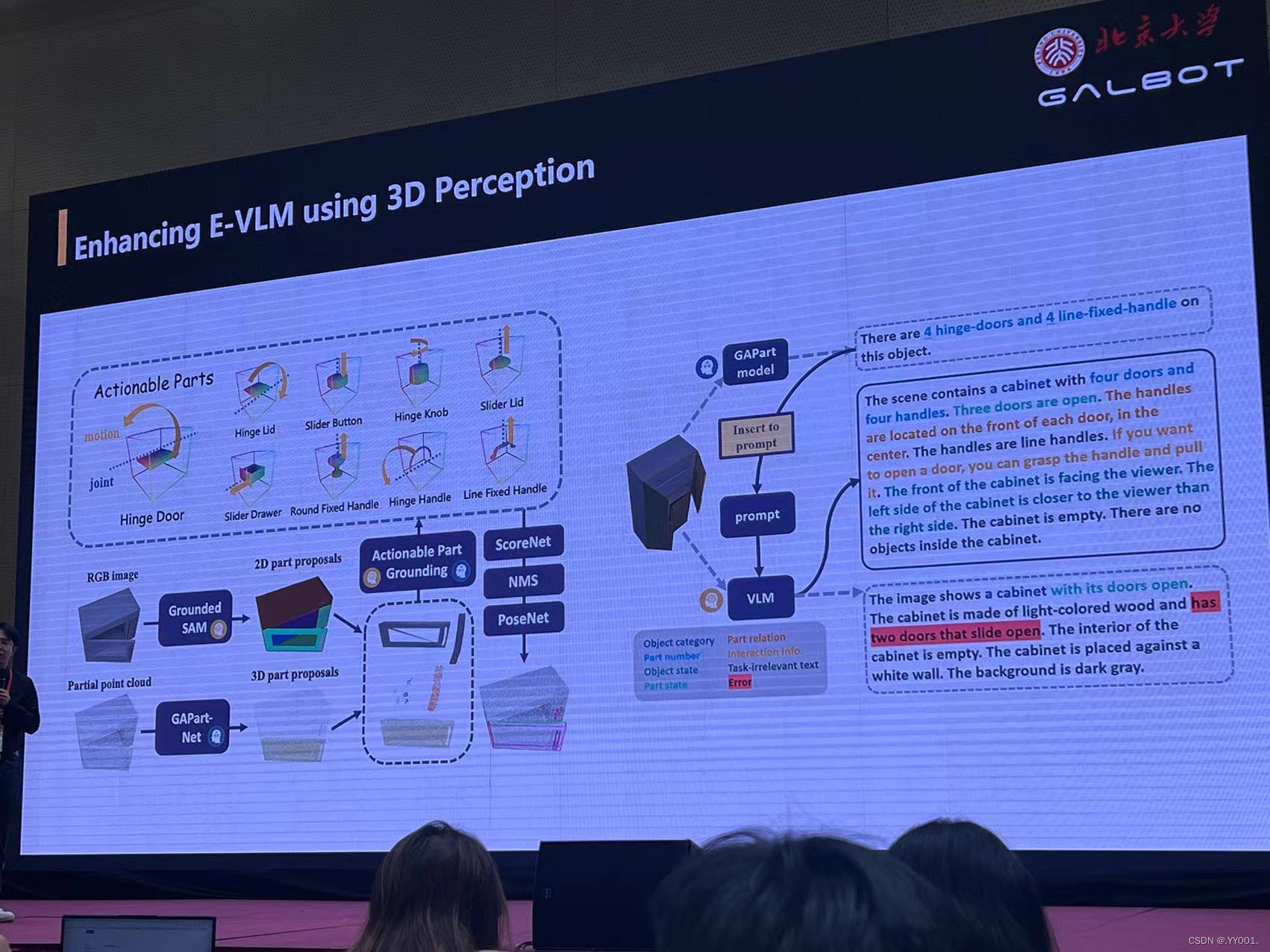
具身智能的视觉与学习

具身多模态大模型
输入 输出


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









