






三、感知机及其python实现
分类模型;找到一个超平面 w ⃗ x ⃗ + b = 0 \vec w \vec x +b =0 wx+b=0 大于0进行分类判断;感知机也可以看成一个单层神经网络
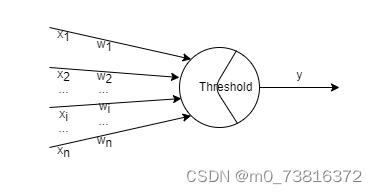
1. 模型
z = w ⃗ ⋅ x ⃗ + b = w 1 x 1 + w 2 x 2 + . . . + w n x n + b y = s i g n ( z ) = { 1 , z ≥ 0 − 1 , z < 0 z = \vec w \cdot \vec x + b=w_1x_1+w_2x_2+...+w_nx_n+b\\ y=sign(z)= \begin{cases} 1, z\geq0\\ -1, z<0 \end{cases} z=w⋅x+b=w1x1+w2x2+...+wnxn+by=sign(z)={1,z≥0−1,z<0
2. 损失函数
J ( w ) = − ∑ x i ∈ M y ( i ) ( w ⃗ ⋅ x ⃗ ( i ) + b ) J(w) = -\sum_{x_i\in{M}}{y^{(i)}( \vec w \cdot \vec x^{(i)}+b)} J(w)=−xi∈M∑y(i)(w⋅x(i)+b)
其中M为错误分类的样本点集合, w ⃗ , x ⃗ ( i ) \vec w , \vec x^{(i)} w,x(i) 都是n维的向量,点表示内积运算
3. 损失函数的原理推导
损失函数的几何意义为所有错误分类样本点距离超平面 x ⃗ w ⃗ + b = 0 \vec x \vec w + b=0 xw+b=0 的距离之和,接下来证明两点
-
w ⃗ \vec w w 为超平面的法向量
假设O为坐标原点,P1, P2为超平面上的任意两点,其坐标分别为为 x ⃗ ( 1 ) 和 x ⃗ ( 2 ) \vec x^{(1)}和\vec x^{(2)} x(1)和x(2) , 因此 w ⃗ 和 P 1 P 2 ⃗ \vec w 和 \vec{P1P2} w和P1P2 的內积为:
w ⃗ ⋅ P 1 P 2 → = w ⃗ ⋅ ( O P 2 → − O P 1 → ) = w ⃗ ( x ⃗ ( 1 ) − x ⃗ ( 2 ) ) = − b − ( − b ) = 0 \vec w \cdot \overrightarrow {P_1P_2}=\vec w \cdot (\overrightarrow {OP_2} - \overrightarrow {OP_1})\\ =\vec w (\vec x^{(1)} - \vec x^{(2)})\\ =-b - (-b)=0 w⋅P1P2=w⋅(OP2−OP1)=w(x(1)−x(2))=−b−(−b)=0
因此得证 w ⃗ \vec w w 为超平面的法向量 -
误分类点到超平面的距离公式为 d = − y ( i ) ( w ⃗ ⋅ x ⃗ ( i ) + b ) d = -y^{(i)}( \vec w \cdot \vec x^{(i)}+b) d=−y(i)(w⋅x(i)+b)
设坐标原点为O, 误分类点为P,其在超平面的投影点为P’,其坐标分别为为 x ⃗ 和 x ⃗ ’ \vec x和\vec x’ x和x’ 因为 P ′ P → \overrightarrow {P'P} P′P 和 w ⃗ \vec w w 平行,所以其內积的绝对值为两向量的模的乘积
∣ w ⃗ ⋅ P ′ P → ∣ = ∣ ∣ w ⃗ ∣ ∣ 2 ∗ d |\vec w \cdot \overrightarrow {P'P}| = ||\vec w||_2 *d ∣w⋅P′P∣=∣∣w∣∣2∗d
又因为P’在超平面上, 因此有 w ⃗ ⋅ x ⃗ ′ + b = 0 \vec w \cdot \vec x' + b = 0 w⋅x′+b=0
∣ w ⃗ ⋅ P ′ P → ∣ = ∣ w ⃗ ⋅ ( O P → − O P ′ → ) ∣ = ∣ w ⃗ ⋅ ( x ⃗ − x ⃗ ′ ) ∣ = ∣ w ⃗ ⋅ x ⃗ + b ∣ |\vec w \cdot \overrightarrow {P'P}|=|\vec w \cdot (\overrightarrow{OP} -\overrightarrow{OP'})| \\=|\vec w \cdot (\vec x-\vec x')| \\=|\vec w \cdot \vec x + b | ∣w⋅P′P∣=∣w⋅(OP−OP′)∣=∣w⋅(x−x′)∣=∣w⋅x+b∣
最后,因为对于误分类点必定满足 y ( i ) ( w ⃗ ⋅ x ⃗ ( i ) + b ) < 0 y^{(i)}( \vec w \cdot \vec x^{(i)}+b) < 0 y(i)(w⋅x(i)+b)<0 , 因此得误分类点到超平面的距离公式为 d = − y ( i ) ( w ⃗ ⋅ x ⃗ ( i ) + b ) d = -y^{(i)}( \vec w \cdot \vec x^{(i)}+b) d=−y(i)(w⋅x(i)+b)
4. python实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
def model(X, theta):
return X @ theta
def predict(x, theta):
flags = model(x, theta)
y = np.ones_like(flags)
y[np.where(flags < 0)[0]] = -1
return y
def computerCost(X, y, theta):
y_pred = predict(X, theta)
error_index = np.where(y_pred != y)[0]
return np.squeeze(-y_pred[error_index].T @ y[error_index])
def gradientDescent(X, y, alpha, num_iters=1000):
# m = X.shape[0]
#X = np.hstack((np.ones((m, 1)), X))
#y = y[:, np.newaxis]
n = X.shape[1]
theta = np.zeros((n, 1))
J_history = []
for i in range(num_iters):
y_pred = predict(X, theta)
error_index = np.where(y_pred != y)[0]
theta = theta + alpha * X[error_index, :].T @ y[error_index]
cur_cost = computerCost(X, y, theta)
J_history.append(cur_cost)
print('.', end='')
if cur_cost == 0:
print(f'Finished in advance in iteration {i+1}!')
break
return theta, J_history
一个实例
iris = datasets.load_iris()
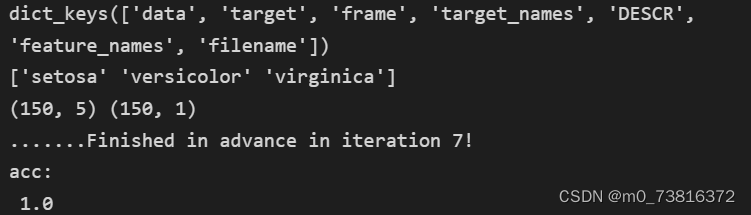
print(iris.keys())
print(iris.target_names)
X = iris.data
m = X.shape[0]
X = np.hstack((np.ones((m, 1)), X))
y = iris.target
y[np.where(y!=0)[0]] = -1
y[np.where(y==0)[0]] = 1
y = y.reshape((len(y), 1))
print(X.shape, y.shape)
theta, J_history = gradientDescent(X, y, 0.01, 1000)
y_pred = predict(X, theta)
acc = np.sum(y_pred == y)/len(y)
print('acc:\n', acc)
结果















 4599
4599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









