







Scala函数式编程
函数式编程
- 所谓的函数式编程指定就是
方法的参数列表可以接收函数对象. - 例如: add(10, 20)就不是函数式编程, 而
add(函数对象)这种格式就叫函数式编程. - 编写Spark/Flink的大量业务代码时, 都会使用到函数式编程。
| 函数名 | 功能 |
|---|---|
| foreach | 用来遍历集合的 |
| map | 用来对集合进行转换的 |
| flatmap | 用来对集合进行映射扁平化操作 |
| filter | 用来过滤出指定的元素 |
| sorted | 用来对集合元素进行默认排序 |
| sortBy | 用来对集合按照指定字段排序 |
| sortWith | 用来对集合进行自定义排序 |
| groupBy | 用来对集合元素按照指定条件分组 |
| reduce | 用来对集合元素进行聚合计算 |
| fold | 用来对集合元素进行折叠计算 |
示例一: 遍历(foreach)
采用 foreach 来遍历集合, 可以让代码看起来更简洁, 更优雅.
格式
def foreach(f:(A) => Unit): Unit
//简写形式
def foreach(函数)
说明

执行过程

需求
有一个列表,包含以下元素1,2,3,4,请使用foreach方法遍历打印每个元素
参考代码
object ClassDemo23 {
def main(args: Array[String]): Unit = {
//1. 定义一个列表, 包含1, 2, 3, 4
val list1 = List(1, 2, 3, 4)
//2. 通过foreach函数遍历上述的列表.
//x:表示集合中的每个元素 函数体表示输出集合中的每个元素.
list1.foreach((x:Int) => println(x))
}
}
示例二: 简化函数定义
概述
上述案例函数定义有点啰嗦,有更简洁的写法。可以通过如下两种方式来简化函数定义:
- 方式一: 通过
类型推断来简化函数定义.
解释: 因为使用foreach来迭代列表,而列表中的每个元素类型是确定的, 所以我们可以通过
类型推断让Scala程序来自动推断出来集合中每个元素参数的类型, 即: 在我们创建函数时,可以省略其参数列表的类型.
- 方式二: 通过
下划线来简化函数定义.
解释: 当函数参数,只在函数体中出现一次,而且函数体没有嵌套调用时,可以使用下划线来简化函数定义.
示例
- 有一个列表,包含元素1,2,3,4,请使用foreach方法遍历打印每个元素.
- 使用类型推断来简化函数定义.
- 使用下划线来简化函数定义
参考代码
object ClassDemo24 {
def main(args: Array[String]): Unit = {
//1. 有一个列表,包含元素1,2,3,4,请使用foreach方法遍历打印每个元素.
val list1 = List(1, 2, 3, 4)
list1.foreach((x:Int) => println(x))
println("-" * 15)
//2. 使用类型推断来简化函数定义.
list1.foreach(x => println(x))
println("-" * 15)
//3. 使用下划线来简化函数定义
list1.foreach(println(_))
}
}
实例三: 映射(map)
集合的映射操作是指 将一种数据类型转换为另外一种数据类型的过程 , 它是在进行数据计算的时候, 在编写Spark/Flink程序时用得最多的操作.
例如: 把List[Int]转换成List[String].
格式
def map[B](f: (A) ⇒ B): TraversableOnce[B]
//简写形式:
def map(函数对象)
说明

执行过程

需求
- 创建一个列表,包含元素1,2,3,4
- 将上述的数字转换成对应个数的 * , 即: 1变为*, 2变为**, 以此类推.
参考代码
object ClassDemo25 {
def main(args: Array[String]): Unit = {
//1. 创建一个列表,包含元素1,2,3,4
val list1 = List(1, 2, 3, 4)
//2. 将上述的数字转换成对应个数的`*`, 即: 1变为*, 2变为**, 以此类推.
//方式一: 普通写法
val list2 = list1.map((x:Int) => "*" * x)
println(s"list2: ${list2}")
//方式二: 通过类型推断实现.
val list3 = list1.map(x => "*" * x)
println(s"list3: ${list3}")
//方式三: 通过下划线实现.
val list4 = list1.map("*" * _)
println(s"list4: ${list4}")
}
}
示例四: 扁平化映射(flatMap)
扁平化映射可以理解为先map,然后再flatten, 如图:

解释:
- map是将列表中的
元素转换为一个List- flatten再将整个列表进行扁平化
格式
def flatMap[B](f:(A) => GenTraversableOnce[B]): TraversableOnce[B]
//简写形式:
def flatMap(f:(A) => 要将元素A转换成的集合B的列表)
说明

示例
需求
- 有一个包含了若干个文本行的列表:“hadoop hive spark flink flume”, “kudu hbase sqoop storm”
- 获取到文本行中的每一个单词,并将每一个单词都放到列表中.
思路分析

参考代码
object ClassDemo26 {
def main(args: Array[String]): Unit = {
//1. 有一个包含了若干个文本行的列表:"hadoop hive spark flink flume", "kudu hbase sqoop storm"
val list1 = List("hadoop hive spark flink flume", "kudu hbase sqoop storm")
//2. 获取到文本行中的每一个单词,并将每一个单词都放到列表中.
//方式一: 通过map, flatten实现.
val list2 = list1.map(_.split(" "))
val list3 = list2.flatten
println(s"list3: ${list3}")
//方式二: 通过flatMap实现.
//val list4 = strings.flatMap(x => x.split(" "))
val list4 = list1.flatMap(_.split(" "))
println(s"list4: ${list4}")
}
}
示例五: 过滤(filter)
过滤指的是 过滤出(筛选出)符合一定条件的元素 。
格式
def filter(f:(A) => Boolean): TraversableOnce[A]
//简写形式:
def filter(f:(A) => 筛选条件)
说明

执行过程

案例
- 有一个数字列表,元素为:1,2,3,4,5,6,7,8,9
- 请过滤出所有的偶数
参考代码
object ClassDemo27 {
def main(args: Array[String]): Unit = {
//1. 有一个数字列表,元素为:1,2,3,4,5,6,7,8,9
val list1 = (1 to 9).toList
//2. 请过滤出所有的偶数
//val list2 = list1.filter(x => x % 2 == 0)
val list2 = list1.filter(_ % 2 == 0)
println(s"list2: ${list2}")
}
}
示例六: 排序
在scala集合中,可以使用以下三种方式来进行排序:

默认排序(sorted)
所谓的默认排序指的是 对列表元素按照升序进行排列 . 如果需要降序排列, 则升序后, 再通过 reverse 实现.
需求
- 定义一个列表,包含以下元素: 3, 1, 2, 9, 7
- 对列表进行升序排序
- 对列表进行降序排列.
参考代码
object ClassDemo28 {
def main(args: Array[String]): Unit = {
//1. 定义一个列表,包含以下元素: 3, 1, 2, 9, 7
val list1 = List(3, 1, 2, 9, 7)
//2. 对列表进行升序排序
val list2 = list1.sorted
println(s"list2: ${list2}")
//3. 对列表进行降序排列.
val list3 = list2.reverse
println(s"list3: ${list3}")
}
}
指定字段排序(sortBy)
所谓的指定字段排序是指 对列表元素根据传入的函数转换后,再进行排序 .
例如: 根据列表List(“01 hadoop”, “02 flume”)的 字母进行排序.
格式
def sortBy[B](f:(A) => B): List[A]
//简写形式:
def sortBy(函数对象)
说明

示例
- 有一个列表,分别包含几下文本行:“01 hadoop”, “02 flume”, “03 hive”, “04 spark”
- 请按照单词字母进行排序
参考代码
object ClassDemo29 {
def main(args: Array[String]): Unit = {
//1. 有一个列表,分别包含几下文本行:"01 hadoop", "02 flume", "03 hive", "04 spark"
val list1 = List("01 hadoop", "02 flume", "03 hive", "04 spark")
//2. 请按照单词字母进行排序
//val list2 = list1.sortBy(x => x.split(" ")(1))
//简写形式:
val list2 = list1.sortBy(_.split(" ")(1))
println(s"list2: ${list2}")
}
}
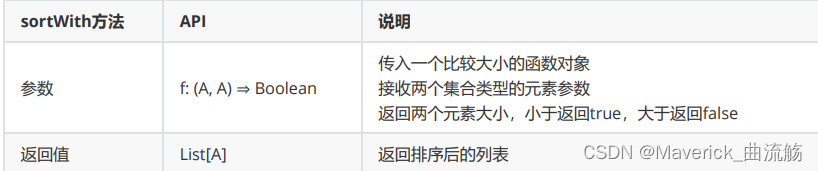
自定义排序(sortWith)
所谓的自定义排序指的是 根据一个自定义的函数(规则)来进行排序 .
格式
def sortWith(f: (A, A) => Boolean): List[A]
//简写形式:
def sortWith(函数对象: 表示自定义的比较规则)
说明
示例
- 有一个列表,包含以下元素:2,3,1,6,4,5
- 使用sortWith对列表进行降序排序
参考代码
object ClassDemo30 {
def main(args: Array[String]): Unit = {
//1. 有一个列表,包含以下元素:2,3,1,6,4,5
val list1 = List(2,3,1,6,4,5)
//2. 使用sortWith对列表进行降序排序
//val list2 = list1.sortWith((x, y)=> x > y) //降序
//简写形式:
val list2 = list1.sortWith(_ > _) //降序
println(s"list2: ${list2}")
}
}
示例七: 分组(groupBy)
分组指的是 将数据按照指定条件进行分组 , 从而方便我们对数据进行统计分析.
格式
def groupBy[K](f:(A) => K): Map[K, List[A]]
//简写形式:
def groupBy(f:(A) => 具体的分组代码)
说明

执行过程

需求
- 有一个列表,包含了学生的姓名和性别: “刘德华” -> “男”, “刘亦菲” -> “女”, “胡歌” -> “男”
- 请按照性别进行分组.
- 统计不同性别的学生人数.
参考代码
object ClassDemo31 {
def main(args: Array[String]): Unit = {
//1. 有一个列表,包含了学生的姓名和性别: "刘德华" -> "男", "刘亦菲" -> "女", "胡歌" -> "男"
val list1 = List("刘德华" -> "男", "刘亦菲" -> "女", "胡歌" -> "男")
//2. 请按照性别进行分组.
//val list2 = list1.groupBy(x => x._2)
//简写形式
val list2 = list1.groupBy(_._2)
//println(s"list2: ${list2}")
//3. 统计不同性别的学生人数. //Map(男 -> List((刘德华,男), (胡歌,男)), 女 -> List((刘亦菲,女)))
//Map(男 -> 2, 女 -> 1)
//x._1 表示男女
//x._2 对应List()
val list3 = list2.map(x => x._1 -> x._2.size) //x出现了两次,不能改为_
println(s"list3: ${list3}")
}
}
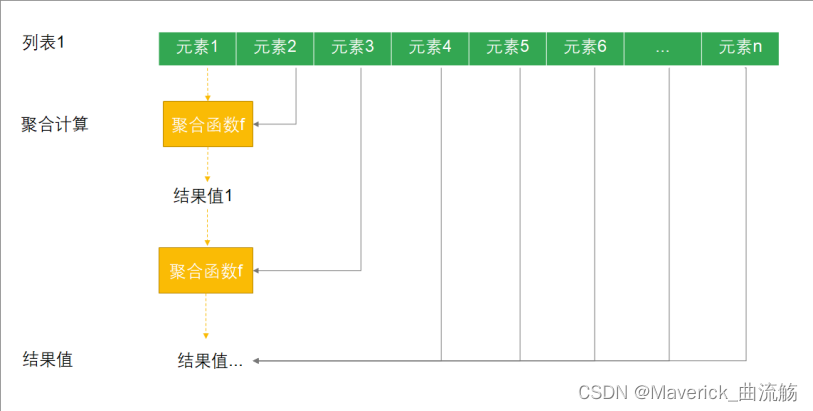
示例八: 聚合操作
所谓的聚合操作指的是将一个列表中的数据合并为一个 .这种操作经常用来统计分析中. 常用的聚合操作主要有两个:
- reduce: 用来对集合元素进行聚合计算
- fold: 用来对集合元素进行折叠计算
聚合(reduce)
reduce表示将列表传入一个函数进行聚合计算.
格式
def reduce[A1 >: A](op:(A1, A1) ⇒ A1): A1
//简写形式:
def reduce(op:(A1, A1) ⇒ A1)
说明

执行过程
注意:
reduce和reduceLeft效果一致,表示从左到右计算
reduceRight表示从右到左计算
需求
- 定义一个列表,包含以下元素:1,2,3,4,5,6,7,8,9,10
- 使用reduce计算所有元素的和
参考代码
object ClassDemo32 {
def main(args: Array[String]): Unit = {
//1. 定义一个列表,包含以下元素:1,2,3,4,5,6,7,8,9,10
val list1 = (1 to 10).toList
//2. 使用reduce计算所有元素的和
//val list2 = list1.reduce((x, y) => x + y)
//简写形式:
val list2 = list1.reduce(_ + _)
val list3 = list1.reduceLeft(_ + _)
val list4 = list1.reduceRight(_ + _)
println(s"list2: ${list2}")
println(s"list3: ${list3}")
println(s"list4: ${list4}")
}
}
//相减有所不同
//reduce 和 reduceLeft
println(list1.reduce(_-_))
//reduceRight与前两个不一样
//1,2,3,4,5,6,7,8,9,10
//第一次 9-10=-1
//第二次 8- -1 = 9
//第三次 7-9 =-2
//...............
println(list1.reduceRight(_-_))
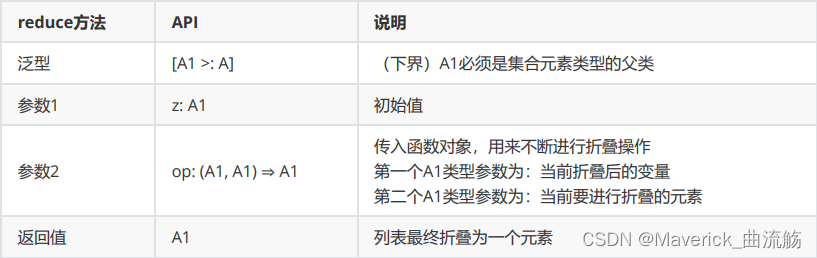
折叠(fold)
fold与reduce很像,只不过多了一个指定初始值参数.
格式
def fold[A1 >: A](z: A1)(op:(A1, A1) => A1): A1
//简写形式:
def fold(初始值)(op:(A1, A1) => A1)
说明
注意事项:
- fold和foldLet效果一致,表示从左往右计算
- foldRight表示从右往左计算
需求
- 定义一个列表,包含以下元素:1,2,3,4,5,6,7,8,9,10
- 假设初始化值是100, 使用fold方法计算所有元素的和.
参考代码
object ClassDemo33 {
def main(args: Array[String]): Unit = {
//1. 定义一个列表,包含以下元素:1,2,3,4,5,6,7,8,9,10
val list1 = (1 to 10).toList
//2. 假设初始化值是100, 使用fold计算所有元素的和
//val list2 = list1.fold(100)((x, y) => x + y)
//简写形式:
val list2 = list1.fold(100)(_ + _)
val list3 = list1.foldLeft(100)(_ + _)
val list4 = list1.foldRight(100)(_ + _)
println(s"list2: ${list2}")
println(s"list3: ${list3}")
println(s"list4: ${list4}")
}
}
案例: 学生成绩单
需求
- 定义列表, 记录学生的成绩, 格式为: 姓名, 语文成绩, 数学成绩, 英语成绩, 学生信息如下: (“张三”,37,90,100),(“李四”,90,73,81), (“王五”,60,90,76), (“赵六”,59,21,72), (“田七”,100,100,100)
- 获取所有语文成绩在60分(含)及以上的同学信息.
- 获取所有学生的总成绩.
- 按照总成绩降序排列.
- 打印结果.
参考代码
object ClassDemo34 {
def main(args: Array[String]): Unit = {
//1. 定义列表, 记录学生的成绩, 格式为: 姓名, 语文成绩, 数学成绩, 英语成绩
val stuList = List(("张三",37,90,100), ("李四",90,73,81), ("王五",60,90,76), ("赵
六",59,21,72), ("田七",100,100,100))
//2. 获取所有语文成绩在60分(含)及以上的同学信息.
val chineseList = stuList.filter(_._2 >= 60)
//3. 获取所有学生的总成绩.
val countList = stuList.map(x => x._1 -> (x._2 + x._3 + x._4))
//4. 按照总成绩降序排列.
val sortList1 = countList.sortBy(_._2).reverse
//也可以通过sortWith实现.
val sortList2 = countList.sortWith((x, y) => x._2 > y._2)
//5. 打印结果.
println(s"语文成绩及格的学生信息: ${chineseList}")
println(s"所有学生及其总成绩: ${countList}")
println(s"总成绩降序排列: ${sortList1}")
println(s"总成绩降序排列: ${sortList2}")
}
}















 406
406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









