






Ascend C编程入门课
一、基础概念
1.Ascend C:是昇腾异构计算架构CANN针对算子开发场景推出的编程语言,通过多层接口抽象、自动并行计算、孪生调试等关键技术,极大提高算子开发效率。
2.使用Ascend C自定义开发算子的优势:
(1)C/C++原语编程,最大化匹配用户的开发习惯
(2)编程模型屏蔽硬件差异,编程范式提高开发效率
(3)多层级API封装,从简单到灵活,兼顾易用与高效
(4)孪生调试,CPU侧模拟昇腾AI处理器(NPU)的行为,可优先在CPU侧调试
注:NPU不能独立运行,需要与CPU协同工作,可以看成是CPU的协处理器,NPU与CPU通过PCIe总线连接在一起来协同工作。
3.当前Ascend C支持的产品型号为:
Atlas 推理系列产品(Ascend 310P处理器)
Atlas 训练系列产品
Atlas A2训练系列产品
Atlas 200/500 A2推理产品
CANN:释放澎湃算力,提供开放易用的开发体系,是华为针对AI场景推出的异构计算架构,通过提供多层次的编程接口,支持用户快速构建基于昇腾平台的AI应用和业务。

4.昇腾AI处理器:有不同的形态,最核心的部件是AI Core,有多个,是神经网络加速的计算核心,使用Ascend C编程语言开发的算子就运行在AI Core上。
AI Core内部的并行计算架构抽象如图:
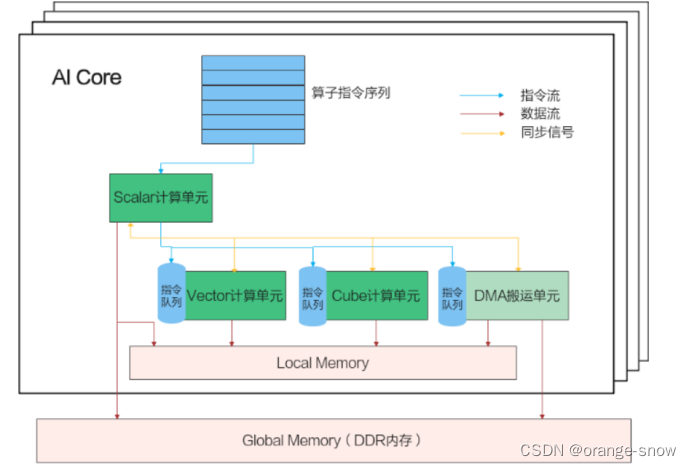
AI Core外面有一个Gobal Memory,是多个AI Core共享的,内部有一块本地内存Local Memory,因为靠近计算单元,所以它的带宽非常高,相对的容量就会很小。AI Core内部的核心组件有三个计算单元,标量计算单元、向量计算单元,矩阵计算单元。还有一个DMA搬运单元负责在Global Memory和Local Memory之间搬运数据。
5.SIMD(单指令多数据计算):Ascend C编程API主要是向量计算API和矩阵运算API,计算API都是SIMD 样式。
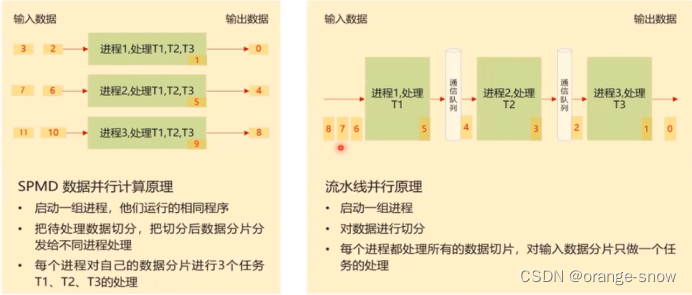
6.并行计算中两种常见方法:单程序多数据(SPMD)和流水线并行
二、Ascend C编程模型与范式
1.SPMD模型
Ascend C算子编程是SPMD的编程,将需要处理的数据拆分并分布在多个计算核心上运行,多个AI Core共享相同的指令代码,每个核上的运行实例唯一的区别是block_idx不同,每个核通过不同的block_idx来识别自己的身份,编程中使用函数GetBlockIdx()获取ID。
2.核函数:是Ascend C算子设备侧实现的入口,要为在一个核上执行的代码规定要进行的数据访问和计算操作,当核函数被调用时,多个核都执行相同的核函数代码,具有相同的参数,并行执行Ascend C允许用户使用核函数这种C/C++函数的语法扩展来管理设备端的运行代码,用户在核函数中进行算子类对象的创建和其成员函数的调用,由此实现该算子的所有功能。
3.核函数定义:
extern "C" __global__ __aicore__ void add_custom(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z);
__global__ __aicore__ void kernel_name(argument list);

使用__global__函数类型限定符来标识它是一个核函数,可以被<<<...>>>调用;使用__aicore__函数类型限定符来标识该核函数在设备端AI Core上执行。
指针入参变量需要增加变量类型限定符__gm__。表明该指针变量指向Global Memory上某处内存地址。

为了表达统一,使用GM_ADDR宏定义:
#define GM_ADDR __gm__ uint8_t*
使用GM_ADDR修饰入参的样例如下:
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z)
在后续的使用中需要将其转化为实际的指针类型。
核函数必须具有void返回类型。
SPMD编程模型允许核函数调用时,多个核并行地执行同一个计算任务。
常见的函数调用形式:
function_name(argument list);
核函数使用内核调用符<<<...>>>这种语法形式,来规定核函数的执行配置:
kernel_name<<<blockDim, l2ctrl, stream>>>(argument list);
注:内核调用符仅可在NPU侧编译时调用,CPU侧编译无法识别该符号。
核函数的调用是异步的,核函数的调用结束后,控制权立刻返回给主机端,可以调用aclrtSynchronizeStream函数来强制主机端程序等待所有核函数执行完毕。
4.编程API:Ascend C算子采用标准C++语法和一组类库API进行编程,可以在核函数的实现中根据自己的需求选择合适的API。Ascend C API的计算操作数都是Tensor类型:GlobalTensor和LocalTensor。
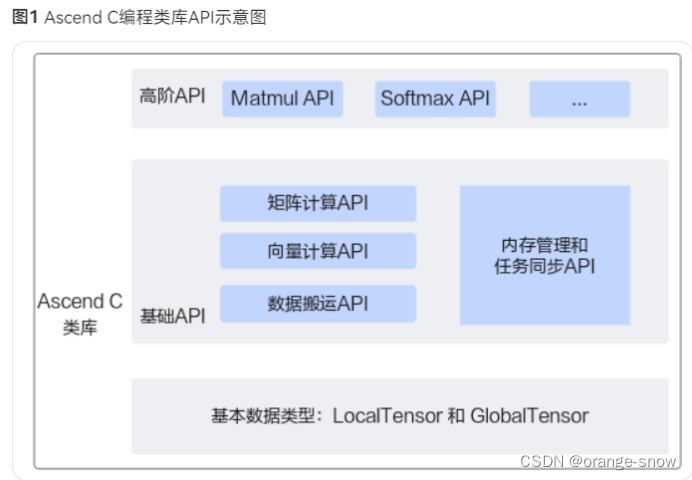
5.类库API分类:
高阶API:提供Matmul、SoftMax等高阶API,封装常用算法逻辑,可减少重复开发,提高开发者开发效率。
基础API:提供基础功能API。
计算类API,包括标量计算API、向量计算API、矩阵计算API,分别实现调用Scalar计算单元、Vector计算单元、Cube计算单元执行计算的功能。
数据搬运API,计算API基于Local Memory数据进行计算,所以数据需要先从Global Memory搬运至Local Memory,再使用计算接口完成计算,最后从Local Memory搬出至Global Memory。执行搬运过程的接口称之为数据搬移接口,比如DataCopy接口。
内存管理API,用于分配管理内存,比如AllocTensor、FreeTensor接口。
任务同步API,完成任务间的通信和同步,比如EnQue、DeQue接口。
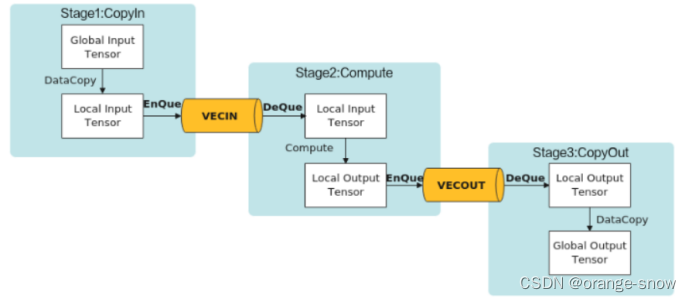
6.Ascend C流水编程范式:把算子核内的处理程序,分成多个流水任务(Stage),以张量(Tensor)为数据载体,以队列(Queue)进行任务之间的通信与同步,以内存管理模块(Pipe)管理任务间通信内存。
7.编程范式-抽象编程模型“TPIPE并行计算”:

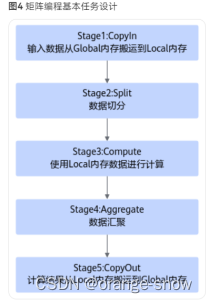
8.任务的通信和同步:Ascend C中使用Queue队列完成任务之间的数据通信和同步,提供EnQue、DeQue等基础API。CopyIn任务中将输入数据从Global内存搬运至Local内存后,需要使用EnQue将LocalTensor放入VECIN的Queue中;Compute任务等待VECIN的Queue中LocalTensor出队之后才可以完成矢量计算,计算完成后使用EnQue将计算结果LocalTensor放入到VECOUT的Queue中;CopyOut任务等待VECOUT的Queue中LocalTensor出队,再将其拷贝到Global内存。
 9.Ascend C使用GlobalTensor和LocalTensor作为数据的基本操作单元,它是各种指令API直接调用的对象,也是数据的载体。
9.Ascend C使用GlobalTensor和LocalTensor作为数据的基本操作单元,它是各种指令API直接调用的对象,也是数据的载体。
10.编程范式-内存管理:任务间数据传递使用到的内存统一由内存管理模块Pipe进行管理。Pipe作为片上内存管理者,通过InitBuffer接口对外提供Queue内存初始化功能,开发者可以通过该接口为指定的Queue分配内存。Queue队列内存初始化完成后,需要使用内存时,通过调用AllocTensor来为LocalTensor分配内存,当创建的LocalTensor完成相关计算无需再使用时,再调用FreeTensor来回收LocalTensor的内存。编程过程中使用到的临时变量内存同样通过Pipe进行管理。临时变量可以使用TBuf数据结构来申请指定QuePosition上的存储空间。使用TBuf申请的内存空间只能参与计算,无法执行Queue队列的入队出队操作。
- Ascend C矢量编程
1.使用内置宏__CCE_KT_TEST__来标识<<<...>>>仅在NPU模式下才会编译到,if defined则在CPU模式下编译,反之在NPU。
四、核函数运行验证

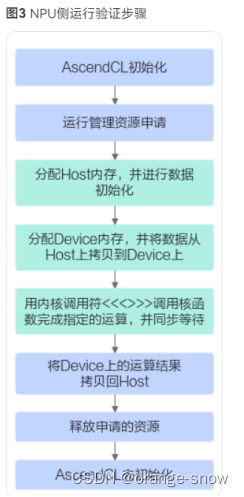
// AscendCL初始化
CHECK_ACL(aclInit(nullptr));
// 运行管理资源申请
aclrtContext context;
int32_t deviceId = 0;
CHECK_ACL(aclrtSetDevice(deviceId));
CHECK_ACL(aclrtCreateContext(&context, deviceId));
aclrtStream stream = nullptr;
CHECK_ACL(aclrtCreateStream(&stream));
// 分配Host内存
uint8_t *xHost, *yHost, *zHost;
uint8_t *xDevice, *yDevice, *zDevice;
CHECK_ACL(aclrtMallocHost((void**)(&xHost), inputByteSize));
CHECK_ACL(aclrtMallocHost((void**)(&yHost), inputByteSize));
CHECK_ACL(aclrtMallocHost((void**)(&zHost), outputByteSize));
// 分配Device内存
CHECK_ACL(aclrtMalloc((void**)&xDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));
CHECK_ACL(aclrtMalloc((void**)&yDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));
CHECK_ACL(aclrtMalloc((void**)&zDevice, outputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));
// Host内存初始化
ReadFile("./input/input_x.bin", inputByteSize, xHost, inputByteSize);
ReadFile("./input/input_y.bin", inputByteSize, yHost, inputByteSize);
CHECK_ACL(aclrtMemcpy(xDevice, inputByteSize, xHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE));
CHECK_ACL(aclrtMemcpy(yDevice, inputByteSize, yHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE));
// 用内核调用符<<<>>>调用核函数完成指定的运算,add_custom_do中封装了<<<>>>调用
add_custom_do(blockDim, nullptr, stream, xDevice, yDevice, zDevice);
CHECK_ACL(aclrtSynchronizeStream(stream));
// 将Device上的运算结果拷贝回Host
CHECK_ACL(aclrtMemcpy(zHost, outputByteSize, zDevice, outputByteSize, ACL_MEMCPY_DEVICE_TO_HOST));
WriteFile("./output/output_z.bin", zHost, outputByteSize);
// 释放申请的资源
CHECK_ACL(aclrtFree(xDevice));
CHECK_ACL(aclrtFree(yDevice));
CHECK_ACL(aclrtFree(zDevice));
CHECK_ACL(aclrtFreeHost(xHost));
CHECK_ACL(aclrtFreeHost(yHost));
CHECK_ACL(aclrtFreeHost(zHost));
// AscendCL去初始化
CHECK_ACL(aclrtDestroyStream(stream));
CHECK_ACL(aclrtDestroyContext(context));
CHECK_ACL(aclrtResetDevice(deviceId));
CHECK_ACL(aclFinalize());














 2446
2446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









