









文章目录
1.前言
本文主要介绍如何在Windows系统安装能够自行同步备份数据的软件Syncthing,以及如何与cpolar配合,让我们能在公共互联网上远程对本地部署的Syncthing进行操作。
我们手机里新拍的照片、工作接收的文件档案、随手编辑写下的文档、或者新下载的视频,这些数据很快就能填满容量堪忧的智能设备(手机、平板等)。正因如此,云存储一时间风头无两,不仅能让这些海量的数据有地方安身,还能随时分享给需要的人。但大厂的云盘总是问题多多,只能自建云盘保平安。
实际上,现在的私人云盘软件已经发展得十分完善,不仅能满足基本的大容量存储需求,还能不受限速困扰。当然,一些私有云盘软件,还能提供很多特色功能。
2. Syncthing网站搭建
Syncthing与知名的Resilio Sync很像,都是基于P2P分布式技术,能够让对台设备实现实时同步文件(也可以选择某台设备文件只上传)。不过从其功能设计上看,可能更偏向“文件/文件夹”同步工具,不过并不妨碍我们将其作为云盘服务器工具来使用。
2.1. Syncthing下载和安装
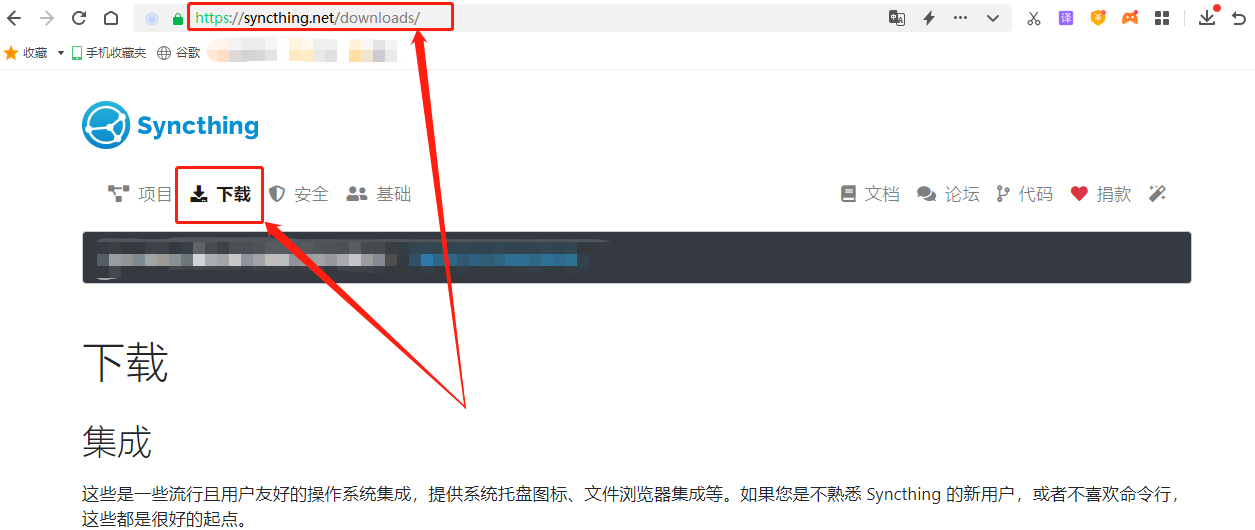
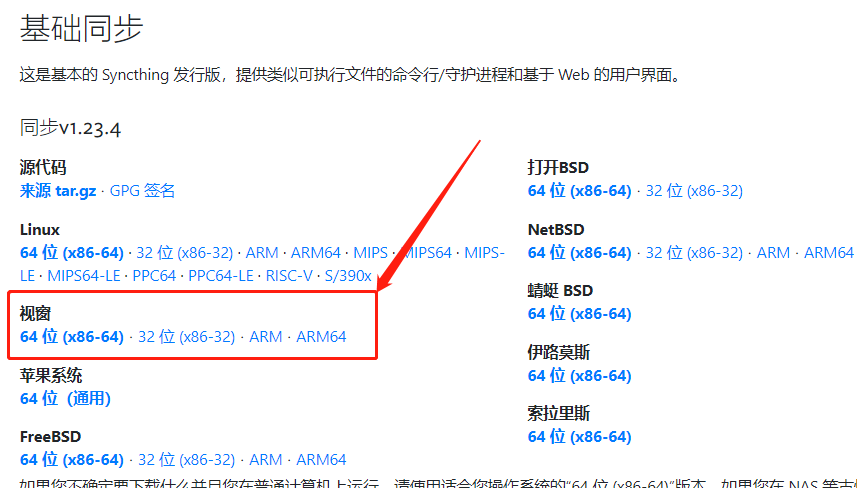
Syncthing虽然是以web页面进行操控,但其安装并不像其他Web部署那样,需要将Web文件放进运行环境中,而是直接提供了对Windows系统来说十分方便的.exe文件安装方式(为什么说Windows?因为笔者使用Windows啊),我们只要在其官网下载页面【https://syncthing.net/downloads/】,下载对应操作系统软件即可。当然Syncthing也提供其他主流操作系统版本的软件下载。
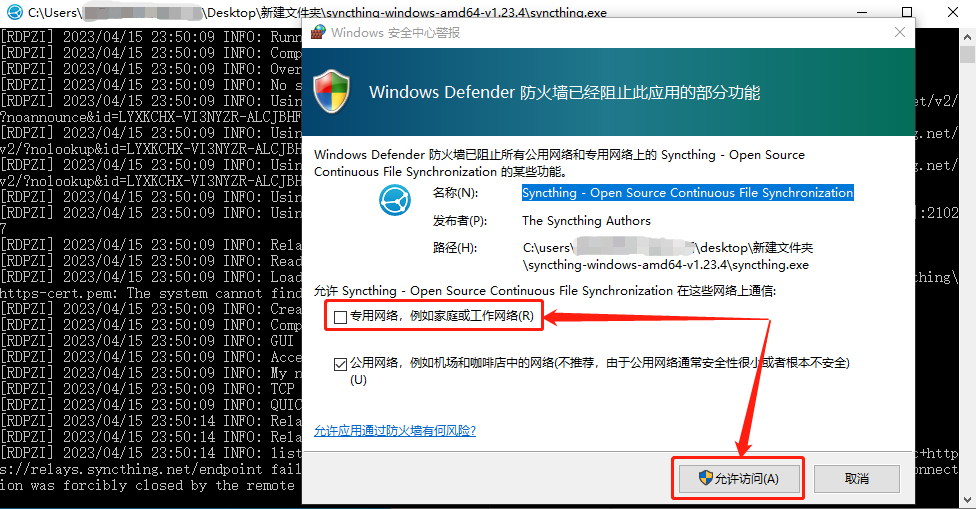
Syncthing软件压缩包下载完成后,将压缩包解压,找到解压后文件夹里的Syncthing.exe程序,双击即可运行。在安装过程中,可能会弹出Windows防火墙询问,我们只要允许其访问即可。
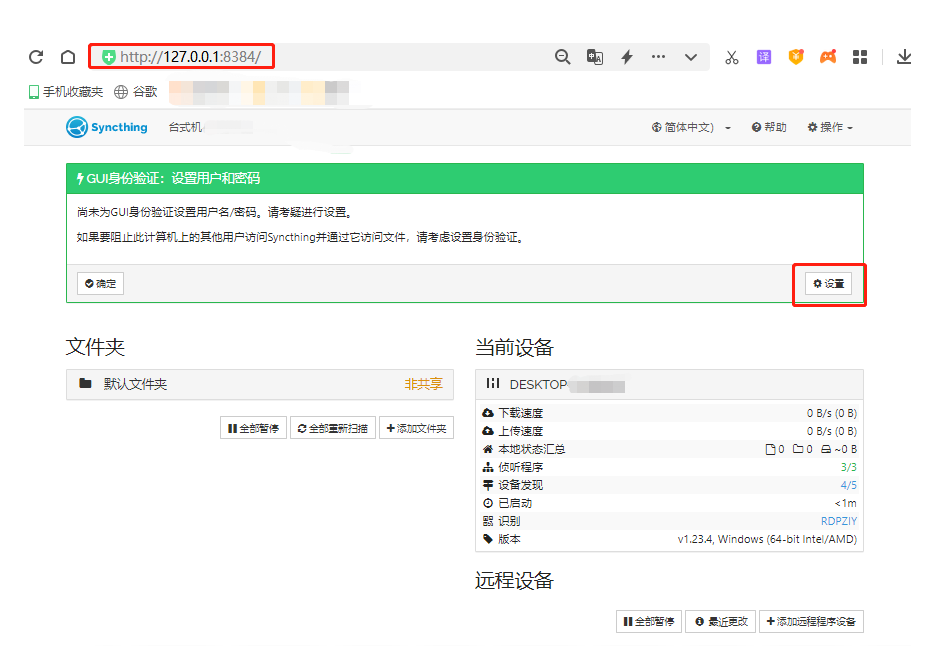
安装程序结束后,Syncthing会自动打开浏览器的8384端口(Syncthing的默认输出端口),进入Syncthing的主界面,我们可以在这里对Syncthing进行设置,如同步内容,设备准入等等。
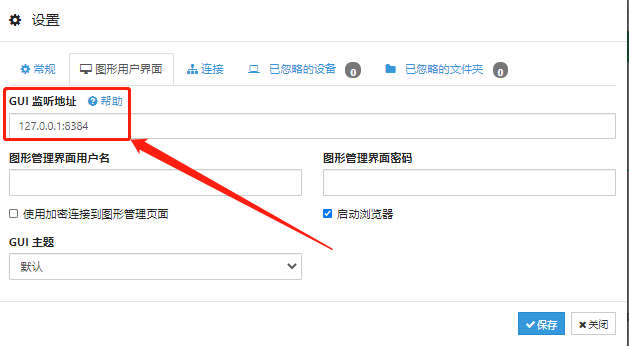
在设置页面,我们也能找到Syncthing的输出端口号,而我们之后的操作,主要就是将这个只能在局域网内访问到的Syncthing页面,变成能够在公共互联网上访问到的私人云盘入口。
2.2. Syncthing网页测试
当然,为了确定我们能在局域网内访问到Syncthing网页,确保Syncthing网页运行无误,我们可以进行一个小测试,即在浏览器的无痕模式中,输入Syncthing地址+端口号,如果能正常访问到Syncthing网页,即证明我们的Syncthing可以正常运行
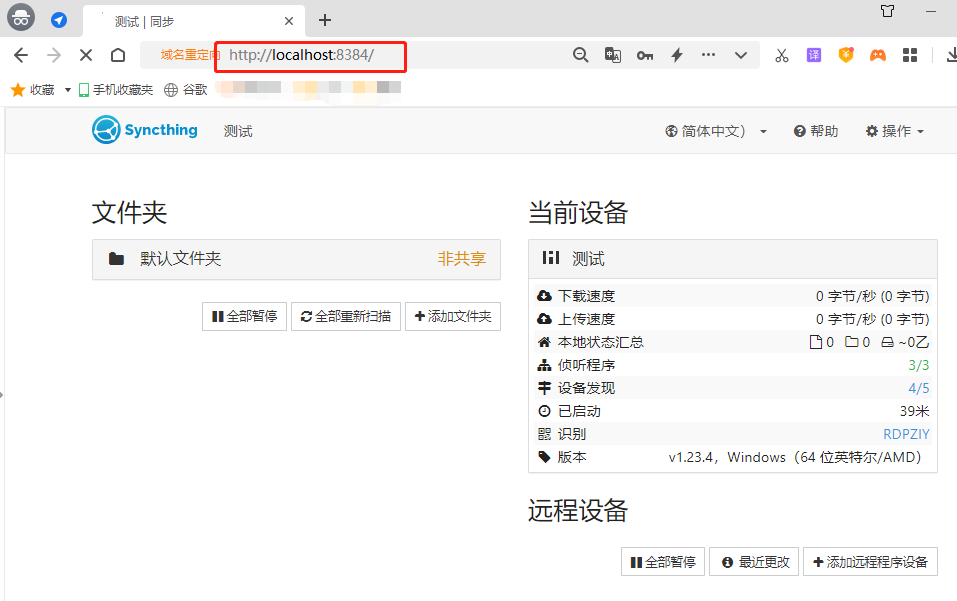
需要注意的是,Syncthing在没有添加到Windows服务列表并启用后台运行时,需要保持命令行窗口运行,如果关闭的话,会导致Syncthing运行终止。
2.3.cpolar的安装和注册
完成Syncthing的安装后,就可以转入cpolar的安装。与Syncthing一样,cpolar的安装注册同样很简单。我们可以直接在cpolar的官网页面找到“下载”按钮。
cpolar官网:https://www.cpolar.com/
笔者使用的是Windows操作系统,因此选择Windows版本进行下载。
Cpolar下载完成后,将下载的文件解压,双击解压后的.msi文件,即可自动执行安装程序。接着只要一路“Next”就能完成安装。
由于cpolar会为每个用户创建独立的数据隧道,并辅以用户密码和token码保证数据安全,因此我们在使用cpolar之前,需要进行用户注册。注册过程也非常简单,只要在cpolar主页右上角点击“用户注册”,在注册页面填入必要信息,就能完成注册。

3.本地网页发布
现在,我们有了可以正常运行的Syncthing软件,和可以建立内网穿透数据隧道的cpolar,接下来我们就可以使用cpolar,创建一个能够连接本地测试页面的公共互联网地址,让我们的Syncthing能在公共互联网上进行操作设置。
3.1.Cpolar云端设置
文件同步可能是随机和持续的,单cpolar免费版的数据隧道每24小时重置一次。相信谁也不会想每天进行数据隧道的重连,因此可以将冲破拉人升级至vip版,以便获得能长期稳定存在的内网穿透数据隧道。
下一步,我们着手对内网穿透数据隧道进行设置,要获得长期稳定的内网穿透数据隧道,需要先登录cpolar的官网,并在用户主页面左侧找到“预留”按钮,并点击进入cpolar的数据隧道预留页面。
在这里生成一个公共互联网地址(也可以看做数据隧道的入口),由于此时这个地址没有连接本地的软件输出端口,因此也可以看做是一条空白的数据隧道。
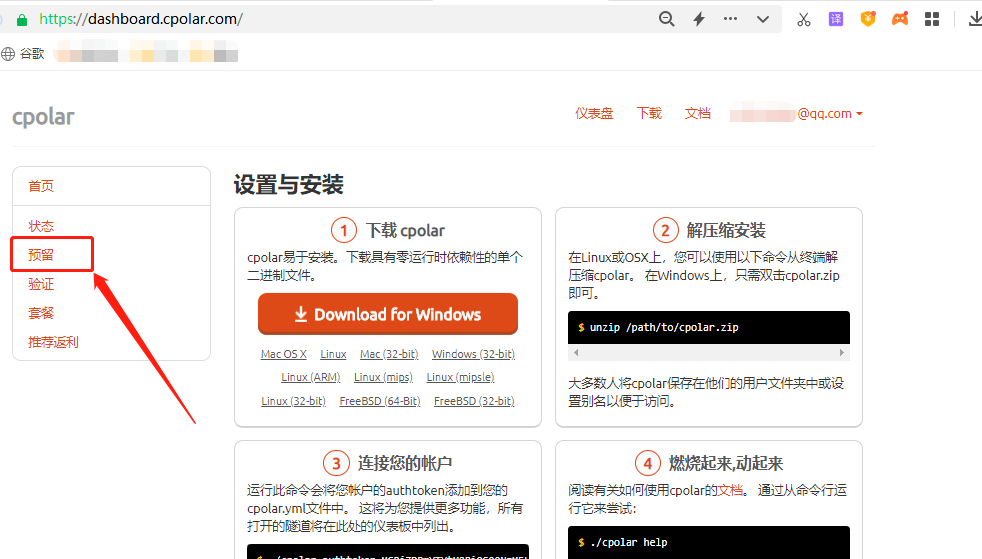
在预留页面,可以看到很多种可保留的数据隧道,这里我们选择“保留二级子域名”栏位。
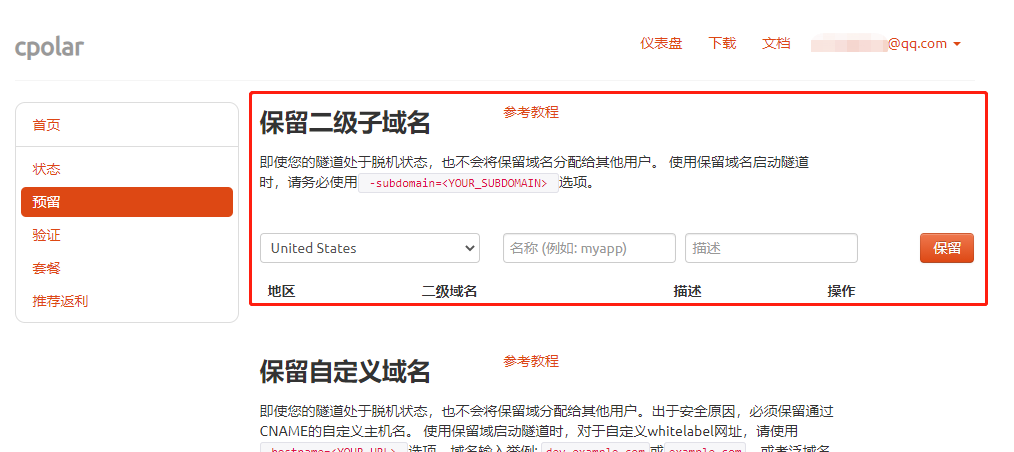
在“保留二级子域名”栏位,需要进行几项信息的简单设置,设置内容为:
地区:服务器所在区域,就近选择即可二级域名:会最终出现在生成的公共互联网地址中,作为网络地址的标识之一描述:可以看做这条数据隧道的描述,能够与其他隧道区分开即可
完成这几项设置后,就可以点击右侧的“保留”按钮,将这条数据隧道保留下来。
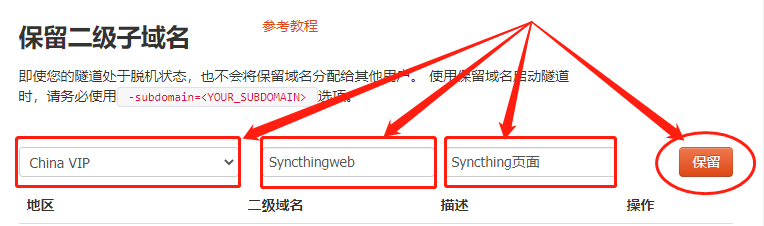
当然,如果这条数据隧道不打算再使用,还可以点击右侧的“x”将其轻松删除,节约宝贵的隧道名额。

3.2.Cpolar本地设置
完成cpolar云端的设置,并保留了空白数据隧道后,我们打开本地的cpolar客户端,将云端生成的空白数据隧道与本地的测试页面连接起来。
在本地打开并登录cpolar客户端后(可以在浏览器中输入localhost:9200直接访问,也可以在开始菜单中点击cpolar客户端的快捷方式)。
点击客户端主界面左侧“隧道管理”项下的“创建隧道”按钮,进入本地隧道创建页面(如果要创建临时数据隧道,可直接在这里进行设置,不必登录cpolar官网设置空白数据隧道)。
在这个页面,同样需要进行几项信息设置,这些信息设置包括:
1.
隧道名称– 可以看做cpolar本地的隧道信息注释,只要方便我们分辨即可;
2.协议– 由于Syncthing是网页显示的,因此选择http协议;
3.本地地址– 本地地址即为Syncthing的输出端口号,而Syncthing默认输出端口为8384,因此这里也填入8384;
4.域名类型– 在这个例子中,我们已经在cpolar云端预留了二级子域名的数据隧道,因此勾选“二级子域名”(如果预留的是自定义域名,则勾选自定义域名),并在下一行“Sub Domain”栏中填入预留的二级子域名,该例子中为“Syncthingweb”(如果打算创建临时数据隧道,则直接勾选“随机域名”,由cpolar客户端自行生成网络地址);
5.地区– 与cpolar云端预留的信息一样,我们依照实际使用地填写即可;
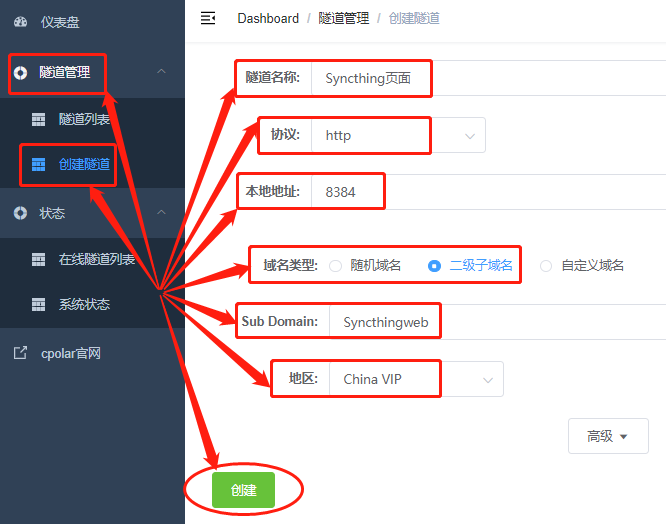
完成这几项简单设置,就可以点击页面下方的“创建”按钮,将cpolar云端的空白数据隧道与本地的Syncthing页面连接起来。
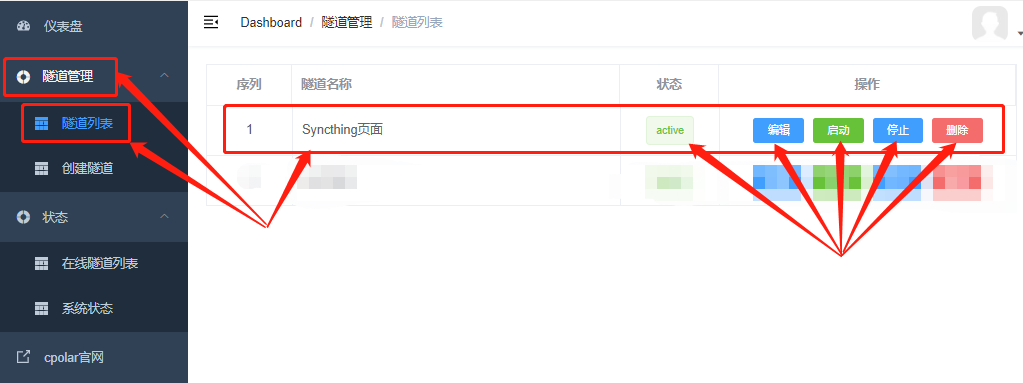
我们可以在“隧道管理”项下的“隧道列表”页面中,对这条数据隧道进行管理,包括开启、关闭或删除这条隧道,也可以点击“编辑”按钮,最这条数据隧道的信息进行修改。
4.公网访问测试
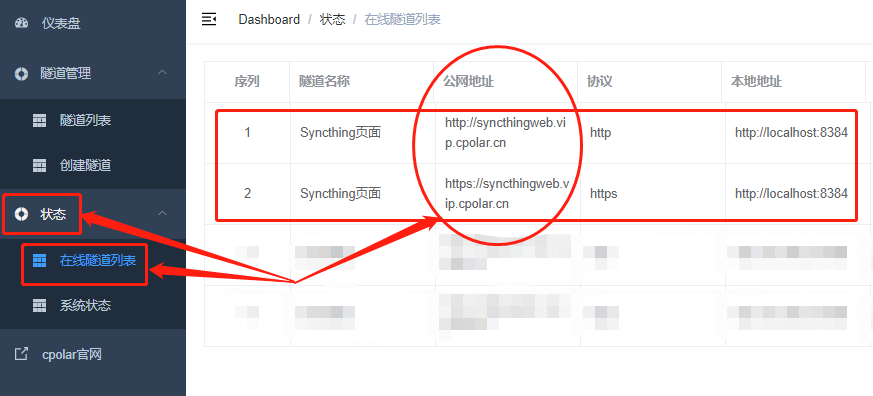
最后,我们点击左侧“状态”项下的“在线隧道列表”按钮,就能找到这个页面的公共互联网地址。
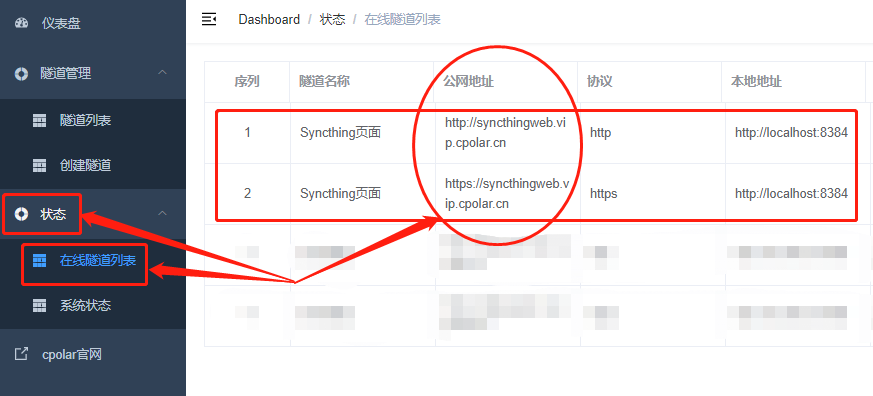
不过Syncthing有host头检查功能,因此我们还需要对cpolar的数据隧道进行一个小修改,才能在公共互联网上访问到本地Syncthing网页。我们回到“隧道管理”项下的“隧道列表”页面,找到“Syncthing页面”的“编辑”,并在数据隧道
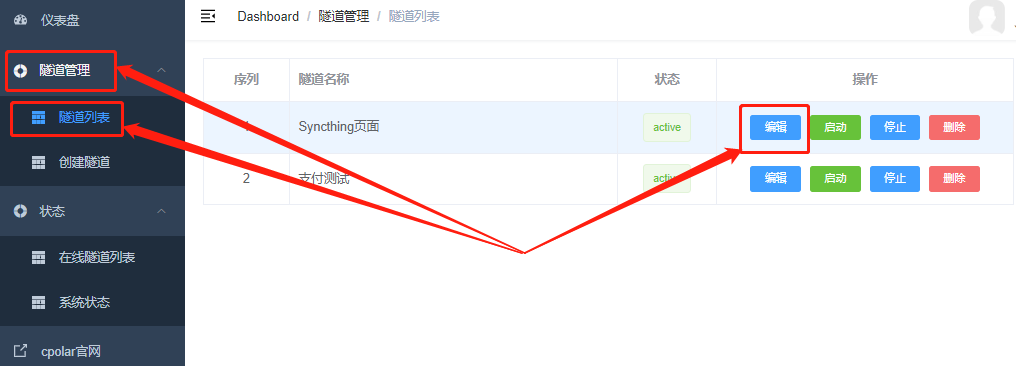
进入“Syncthing页面”,点击“高级”按钮,为这条数据隧道编辑一个新的host头。
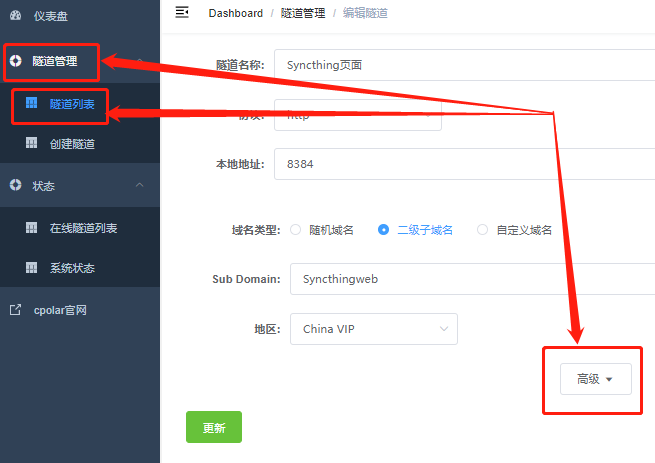
点开“高级”设置页面,找到“Host头域”,将Syncthing在本地的网页地址填入空格处,也就是“localhost:8384”,这样公共互联网访客通过cpolar访问本地Syncthing网页时,cpolar可以重写host头。填写完成后,点击页面下方的“更新”按钮,保存我们所做的host头变更。

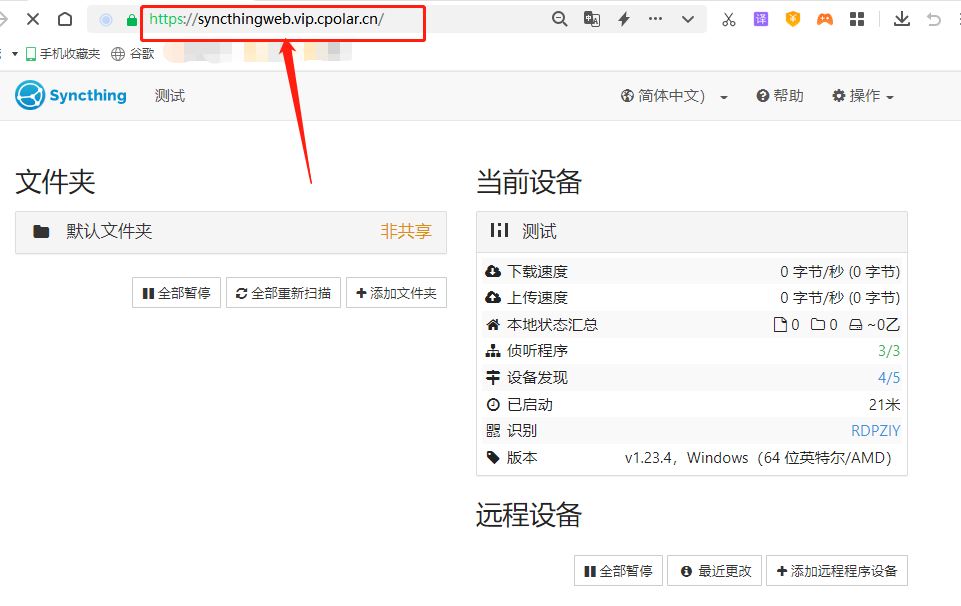
完成host头的设置后,我们回到“在线隧道列表”页面,找到Syncthing页面的公共互联网地址,将这个地址粘贴到浏览器中,就能看到本地Syncthing页面,让我们能在公共互联网上,访问到Syncthing页面。
5.结语
当然,使用cpolar创建的数据隧道访问本地Syncthing页面并不是cpolar的唯一用途,我们可以使用cpolar创建任何指向本地tcp或http端口的内网穿透数据隧道,将本地网页或软件发布到公共互联网上。
















 4791
4791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











