







Application of long-wave near infrared hyperspectral imaging for determination of moisture content of single maize seed
长波近红外高光谱成像技术在单粒玉米种子水分含量测定中的应用


文章目录
思维导图
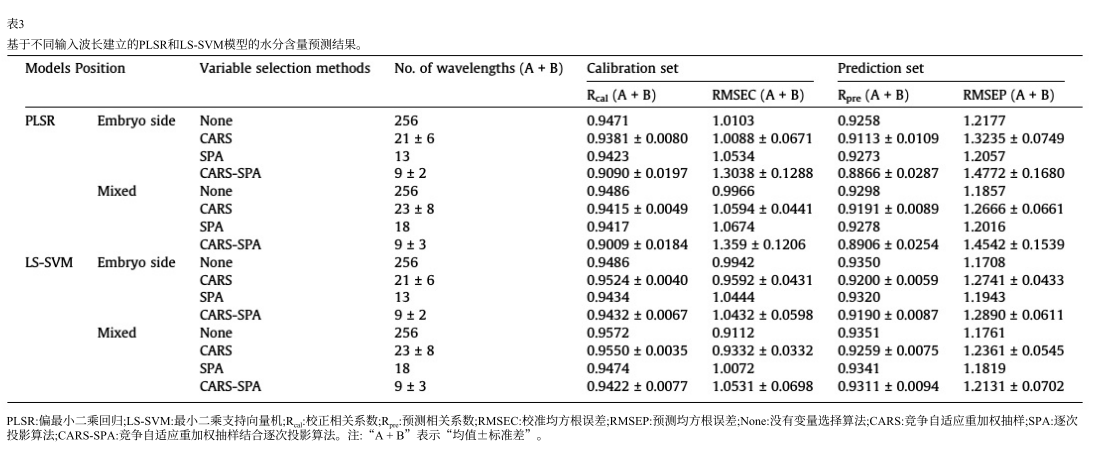
| 论文 | 材料 | 光谱范围 | 光谱数据的提取和预处理 | 使用光谱类型 | 波长选择方法 | 模型 |
|---|---|---|---|---|---|---|
| Application of long-wave near infrared hyperspectral imaging for determination of moisture content of single maize seed 长波近红外高光谱成像在单粒玉米种子含水量检测中的应用 | 命名为“正单958”的玉米种子购自当地市场(中国北京)。为了增加MC梯度,总共292个样本被分为4组。每组用湿纱布包裹,保存在恒温恒湿室(2℃,50%相对湿度)。这样,玉米种子可以均匀吸水,抑制发芽。然后,每12小时取出一组样品,放置在实验室中8小时,以减少温度对预测精度的影响。将总样本按3:1的比例分为校准集和预测集。因此,随机选取219个样本作为校准集,建立MC预测模型,剩余73个样本作为预测集,评估模型的性能。为了比较不同校准模型的性能,所有分析均使用相同的校准集和预测集。 | 光谱范围为930-2548 nm,每张原始高光谱图像包含256张单波长图像,在930 - 2548nm的光谱范围内,相邻波段之间的光谱增量约为6.32 nm。 | 从分析后的高光谱图像中提取1098 nm的灰度图像;最大类间方差法(maximum between-class variance method,又称OTSU)是一种获得图像二值化最佳处理阈值的经典方法,最早由Otsu[43]提出。本文采用OTSU算法对灰度图像(玉米种子区域标记为“1或白色”,背景区域标记为“0或黑色”)进行背景分割,得到最优阈值。接下来,对二值图像中的玉米种子(连通区域)进行编号。随后,将带有序列号的二值图像与每个波长的灰度图像相乘,去除背景。最后,根据序列号提取每个玉米种子的平均光谱。对玉米种子进行编号的目的是对应同一种子中的胚和胚乳侧谱。这对于获得玉米种子两侧的平均谱是必不可少的。 | 胚侧、胚乳侧和混合后的光谱 | CARS、SPA、CARS-SPA组合算法 | 偏最小二乘回归(PLSR)和最小二乘支持向量机(LS-SVM) |
摘要
水分含量(MC)是评价种子品质的重要因素之一。然而,单粒种子中水分含量的准确检测是非常困难的。本研究以单粒玉米种子为研究对象。研制了长波近红外(LWNIR)高光谱成像系统,在930-2548 nm光谱范围内获取玉米种子胚侧和胚乳侧的反射率图像,提取玉米种子两侧的混合光谱。然后,基于不同类型的光谱,建立全光谱模型并进行比较。结果表明,基于胚胎侧光谱和混合光谱建立的模型比基于胚乳侧光谱建立的模型具有更好的性能。接下来,提出了竞争自适应重加权采样(CARS)和逐次投影算法(SPA)相结合的方法,从全光谱数据中选择最有效的波长。为了探索波长选择算法的稳定性,分别基于胚胎侧光谱和混合光谱,采用这两种方法进行了200次独立实验。将每个选择结果作为偏最小二乘回归(PLSR)和最小二乘支持向量机(LS-SVM)的输入,构建用于确定单个玉米种子MC的校准模型。结果表明,综合考虑模型的精度、稳定性和复杂性,混合光谱建立的CARS-SPA-LS-SVM模型最适合MC预测。在200次独立评价中,CARS-SPA-LS-SVM模型的预测精度为Rpre= 0.9311±0.0094,RMSEP = 1.2131±0.0702。综合研究表明,长波近红外高光谱成像可以将CARS-SPA-LS-SVM方法与混合光谱相结合,用于无创、快速测量单个玉米种子MC,建立了一个鲁棒、准确的模型。这些结果可为评价单粒玉米种子的其他内在品质属性(如淀粉含量)提供有益的参考。
1.引言
玉米是世界上的主要作物之一,在大多数地区和国家都被视为重要的主食。此外,它也是畜牧业和水产养殖业的重要饲料。同时,玉米在工业领域也发挥着关键作用,如精制酒精[3]、制糖[4]和生产淀粉[5]。玉米种子的好坏决定着玉米的产量和品质。水分含量(MC)是评价种子品质的关键指标。水分含量会影响种子的贮藏时间和发芽率。中国用于贮藏、加工、销售和种植的玉米种子的MC不应超过13%[7]。当玉米种子在贮藏过程中MC超过20%时,呼吸作用就会加速。这种现象会产生大量的水分和热量,影响储存[8]的安全性。而玉米种子中MC含量低,会导致种子品质退化,甚至因失水而死亡。此外,准确评估玉米籽粒MC对产量预测也至关重要[9]。
卡尔费希尔滴定法[10]和电子水分分析仪[11]等化学和物理方法已被应用于玉米单粒种子中微量元素的测定。卡尔费希尔滴定法需要碘和二氧化硫的反应来测量水分含量。该方法可以检测单个玉米种子的MC,但具有破坏性,费时费力,检测精度有限。电子水分分析仪的原理是将被测样品作为传感器的介质,根据随样品含水量变化的电容或电阻值来测量MC。虽然这些方法可以实现无损检测,但不能应用于单个玉米种子。而且,以上方法都无法开发出针对单个玉米种子的在线检测设备。因此,它们不适合用于单粒种子的快速无损检测。近红外光谱分析技术由于具有无损、速度快、成本低、无公害的优点[16],已被广泛应用于种子质量检测,如测定豌豆坚果的MC和真菌[12,13]、大豆中的油脂[14]、小麦中的蛋白质含量[15]等。然而,传统的近红外光谱分析技术只能提供样品中一个小点的光谱信息。因此,必须专门设计光谱实验系统来测量单个种子的质量。同时,由于种子外部特性的差异,也很难保证单个种子的检测精度。
高光谱成像(high spectral imaging, HSI)将传统的光谱学和数字成像技术集成到一个系统中,从被测样品中同时获取光谱和成像信息[17,18]。近年来,HSI技术被用作一种有效的工具,用于基于空间信息检测尺寸[19]、颜色[20]和表面缺陷[21]等外部特征,以及基于光谱信息检测水分[22]、淀粉[23]和蛋白质脂肪等内部质量[24,25]。HSI也被应用于种子质量的检测,包括种子的分类[27,28]、谷类作物的真菌检测[29,30]、大米淀粉[31]的检测等。Tian, Huang, Li, Fan和Zhang[32]证明了利用全胚侧和胚结构的长波近红外(1000 - 2500nm)光谱可以实现玉米种子的MC检测,并且利用胚结构光谱进行单个玉米种子的MC检测效果更好。但单粒玉米种子的胚侧或胚乳侧表面结构存在差异,玉米胚乳侧也可能含有与水有关的信息[33]。**Zhang和Guo[34]基于可见/近红外(Vis/NIR) (423 ~ 991 nm)和近红外(NIR) (914 ~ 1661 nm)高光谱成像技术提取了玉米种子两侧完整区和质心区的平均反射率光谱。**结果表明,利用质心区提取的NIR光谱与无信息变量消除(UVE)相结合建立的PLSR模型对玉米籽粒MC的预测效果较好。但忽略了特征波长选择方法的稳定性和玉米结构的影响。为了克服这些缺点,本研究分别利用每侧全区域的平均光谱和两侧的混合光谱(胚侧和胚乳侧的平均光谱)构建校准模型,并通过比较模型的稳定性来确定最优模型。而无信息变量消除(uninformative variable elimination,UVE)仅消除无用信息,所选特征波长仍然是冗余的。因此,本研
究的目标之一是使用更少的波长构建更简化的预测模型。
在目前的高光谱成像系统中,通常有两个光谱范围,即可见光和短波近红外(VIS-SWNIR)光谱范围(400-1000 nm)和长波近红外(LWNIR)光谱范围(1000-2500 nm)。由于缺乏合适的长波近红外光谱成像设备,利用LWNIR光谱区的研究很少。但是,长波近红外应该更适合于种子的MC检测,因为在这个光谱区域有很多与水有关的波长。因此,本研究的目标之一是探讨930-2548 nm光谱范围内LWNIR HSI测定玉米单粒种子MC的潜力。
一般来说,高光谱数据包含数百个波长,这些波长携带着大量的冗余和多重共线性信息。这些不重要的信息可能会降低模型的性能,比如检测速度、稳定性等。或者,可以使用波长选择算法来减少无用信息并简化模型,以提高模型[35]的效率和可靠性。竞争自适应重加权采样(CARS)[36]和连续投影算法(SPA)[37]是两种常用的波长选择算法[38]。许多研究已经证明了它们在波长选择方面的优异性能。在最近的研究中发现,两种互补的波长选择策略在组合时可能会实现叠加效应[39-41]。本研究将CARS算法与SPA相结合,选择有效波长,优化模型拟合,提高预测性能。此外,偏最小二乘回归(PLSR)等线性模型是最常用的种子质量定量分析模型。然而,这种模型只能处理光谱与化学成分之间的线性关系,而不能分析潜在的非线性信息。分析玉米种子MC检测的线性和非线性模型,以获得更稳健和稳定的预测模型,这一点至关重要。因此,利用最小二乘支持向量机(LS-SVM)建立玉米种子MC预测的非线性校准模型。
2. 材料与方法
2.1. 样品
命名为“正单958”的玉米种子购自当地市场(中国北京)。为了增加MC梯度,总共292个样本被分为4组。每组用湿纱布包裹,保存在恒温恒湿室(2℃,50%相对湿度)。这样,玉米种子可以均匀吸水,抑制发芽。然后,每12小时取出一组样品,放置在实验室中8小时,以减少温度对预测精度的影响。将总样本按3:1的比例分为校准集和预测集。因此,随机选取219个样本作为校准集,建立MC预测模型,剩余73个样本作为预测集,评估模型的性能。为了比较不同校准模型的性能,所有分析均使用相同的校准集和预测集。
2.2. 高光谱成像系统和图像采集
采用图1所示的HSI系统,在反射模式下获取所有样品的高光谱图像,光谱范围为930-2548 nm。HSI系统置于涂有黑色哑光油墨的检测室中,以避免杂散光的干扰。该系统主要由五个部分组成:一台高光谱光谱仪(ImSpector N25E, spectrum Imaging有限公司,奥卢,芬兰),两个150w卤素光源,一台320256像素阵列近红外摄像机(xva -2.5 - 320, Xenics有限公司,比利时),一台步进电机驱动的电动定位样品台(EZHR17EN, AllMotion,公司,USA),一台计算机(Dell OPTIPLEX 990,Intel ® Core ™ i5-2400 CPU,工作频率3.10 GHZ),配备SpectraCube数据采集软件和样品台控制软件(台湾五十铃光学公司)。
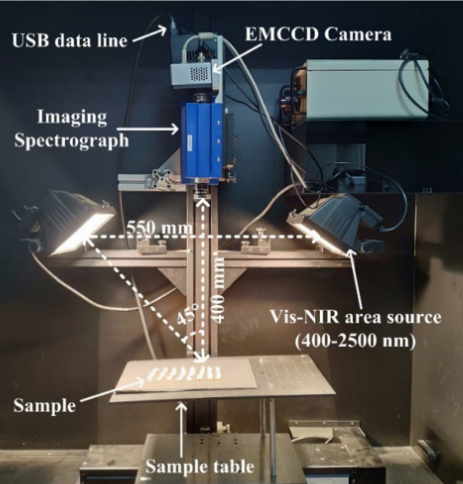
对于图像采集,将相机与样品之间的距离调整为400mm。卤素光区光源之间的距离为550 mm,与水平面的夹角为45°。设置样品台的移动速度为43 mm/s,相机的曝光时间为2 ms。每张原始高光谱图像包含256张单波长图像,在930 - 2548nm的光谱范围内,相邻波段之间的光谱增量约为6.32 nm。相机有一个二维传感器阵列,有320个256个光电二极管。这意味着近红外高光谱图像在x方向为320像素,y方向为n像素,k方向为256波段,如图2所示。
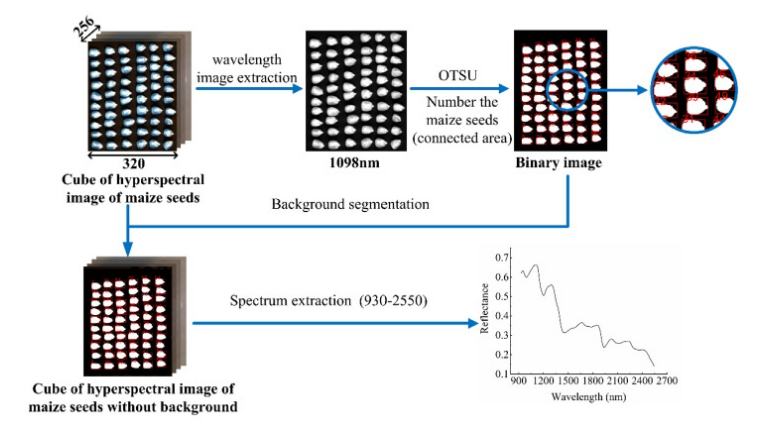
在本研究中,分别采集了样品胚胎侧和胚乳侧的高光谱图像。具体来说,首先采集每个种子的胚侧图像,然后,将检测到的种子倒过来采集胚乳侧图像。考虑到分布不均匀对于相机中的光和暗电流的影响,应使用白光和暗光参考[42]对获得的原始高光谱图像进行校准。基于相同的高光谱系统和参数,使用具有99%反射效率的白色漫反射板(Spectralon SRT-99-100,Labsphere公司,North Sutton, NH,USA)获得白色参考(Rwhite)。由于没有光照射到探测器时,相机芯片的信号不为零,因此获得了反射率接近0%的黑色参比(Rblack),以消除CCD探测器的暗电流效应。这个黑色参考点是通过关闭所有光源并在镜头上盖上黑色帽来收集的,经校正后的高光谱图像R可以计算如下:
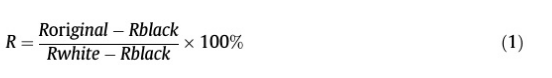
其中R和Roriginal分别代表校正后的高光谱图像和原始的高光谱图像。
2.3. 光谱的提取和预处理
基于校正后的高光谱图像r提取单个玉米种子的平均光谱,光谱数据提取流程图如图2所示。首先,从分析后的高光谱图像中提取1098 nm的灰度图像;最大类间方差法(maximum between-class variance method,又称OTSU)是一种获得图像二值化最佳处理阈值的经典方法,最早由Otsu[43]提出。本文采用OTSU算法对灰度图像(玉米种子区域标记为“1或白色”,背景区域标记为“0或黑色”)进行背景分割,得到最优阈值。接下来,对二值图像中的玉米种子(连通区域)进行编号。随后,将带有序列号的二值图像与每个波长的灰度图像相乘,去除背景。最后,根据序列号提取每个玉米种子的平均光谱。对玉米种子进行编号的目的是对应同一种子中的胚和胚乳侧谱。这对于获得玉米种子两侧的平均谱是必不可少的。利用“regionprops”函数对玉米种子进行编号。值得一提的是,编号算法的主要原理是基于每一列的连通区域(玉米种子)最左边的像素位置。基于这一原理,如果一颗玉米种子的最左边像素位于同一列中其他种子位置的前面,则该玉米种子编号为1。如果两个玉米种子的最左边位置相同,则玉米种子将从上到下进行编号。但在数据采集过程中,由于样品表振动引起的位置变化,可能无法获得预期的玉米种子序号。如果出现这种情况,可以通过调整错误的序列号来获得期望的结果。
在获得每个样本的平均光谱后,对原始光谱数据进行预处理,消除高频随机噪声,以提高模型的性能[44];本研究采用savitzky-golay (SG)平滑(窗口大小为19点)结合标准正态变量(SNV)对原始光谱数据进行预处理。SG平滑是一种常用的预处理算法,通过对窗口内的每个点进行拟合运算或求平均值来获得最佳估估值,平滑可以提高信噪比[45]。SNV消除了散射产生的光谱的斜率变化和粒度变化[46]。
2.4. 参考测量
玉米种子的MC参考值通过成像后的重力法得到。将这些玉米种子放入135℃的烘箱中保温48 h,烘箱中的高温干燥环境使玉米脱水。在每个玉米种子干燥前后,用分析天平(LS220A,Precisa, Switzerland)测量其重量。MC计算公式如下:

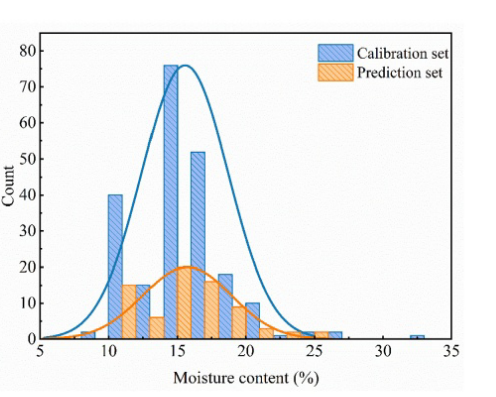
式中,MC表示玉米种子含水量,wbe-fore>表示玉米种子干燥前的重量。wafter>为干燥后单个玉米的重量。如表1所示,校正集中样本的MC范围(9.12-32.91%)大于预测集中样本的MC范围(10.93-25.28%)。同时,图3的直方图显示了校准集和预测集的玉米种子MC的分布情况。可以清楚地看到,校准集和预测集的趋势相似,都是正态分布。因此,样品的MC范围有利于建立稳定的校准模型来预测水分含量。

2.5. 波长选择方法
波长选择在高光谱数据分析中是一个重要的步骤,因为去除非信息和冗余波长将简化校准模型,提高模型的处理速度和鲁棒性。本研究采用CARS-SPA组合选择玉米种子MC特征波长进行预测。作为比较,还使用了单CARS和SPA进行波长选择。
2.5.1. 竞争自适应重加权抽样(CARS)
CARS是一种快速有效的波长选择方法。一般来说,每次采样运行包括四个主要步骤。首先,通过蒙特卡罗方法从标定集中选取N个子集(每个子集包含校准集的80-90%),并利用每个子集构建PLS模型;其次,利用指数递减函数(exponential - reduction function, EDF)逐步高效地去除全谱中的少量信息或无信息;第三,自适应重加权采样(ARS)模仿“适者生存”原则,选择具有较大权重的波长。第四,将交叉验证均方根误差(RMSECV)值最小的波长作为最优波长;将选择的波长作为输入,分别建立PLS和LS-SVM模型。
2.5.2. 逐次投影算法(SPA)
SPA算法[37]被广泛应用于高光谱数据的波长选择。该算法的主要目的是选择信息冗余最小的波长。它使用向量投影分析在光谱信息中寻找最小冗余信息变量组,使变量之间的共线性最小化,减少建模变量的数量[47]。在SPA运行过程中,建立了不同子集的多元线性回归(MLR)模型,计算了模型的RMSE。最佳波长可由RMSE最小的子集确定。
2.5.3. CARS-SPA组合算法
CARS算法可以去除全光谱中很少或没有信息的波长。然而,所选择的波长可能存在共线性信息,导致模型的过拟合。因此,CARS结合SPA (CARS-SPA)被用于提高波长选择性能[40,48]。对于CARS-SPA组合,首先利用CARS获得与玉米种子MC相关的一组潜在波长,然后利用SPA从这些确定的潜在波长中选择最有效的波长子集。
2.6. 模型验证与评价
模型验证是多变量数据分析的重要步骤。最小二乘回归(least squares regression, PLSR)模型作为一种多变量数据分析方法,被广泛用于预测食品和农产品的内部成分[49-51]。采用留一交叉验证法,在充分交叉验证的标定集基础上建立线性PLSR模型,并在RMSECV达到最小[52]时进行交叉验证,确定潜在变量(lv)。
作为对比,采用径向基函数(RBF)核函数的最小二乘支持向量机(LS-SVM)建立非线性模型。正则化参数gamma ©和RBF核函数参数sig2(r2)是LS-SVM模型中的重要参数,它们决定了模型[53]的稳定性和预测性能。Gamma ©用于最大化模型性能(在训练上)和最小化模型复杂度。较大的gamma ©意味着较小的正则化,因此是一个更非线性的模型。Sig2 (r2)影响模型中邻居的数量,大Sig2 (r2)意味着模型中邻居更多,从而导致更非线性的模型[54]。采用留一交叉验证的网格搜索技术确定gamma ©和sig的最优参数值2(r2)[55]。RMSECV达到最小值时选择最佳参数。
通过校正的相关系数(Rcal)与预测的相关系数(Rpre)、校正的均方根误差(RMSEC)与预测的均方根误差(RMSEP)来评价模型的性能。一般来说,预测能力和准确率越高的模型对应的Rcal、Rpre越高,RMSEC、RMSEP越低。这些评估参数定义如下:
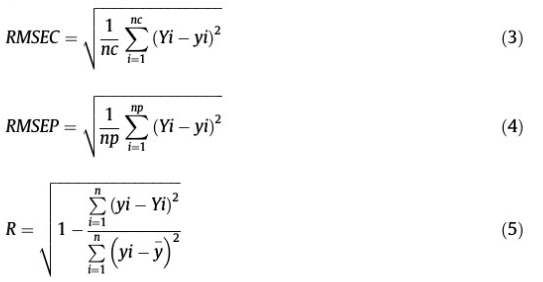
式中,Yi和yi分别为校准集和预测集中第i个样本的预测MC值和参考MC值;nc和np分别为校准集或预测集中的样本数,分别为。yi为校准或预测集中样本的平均MC参考值;N为校准集或预测集中的样本个数。
使用MATLAB 2016b软件(Math works inc., Natick, MA, USA)完成所有计算,包括光谱数据预处理、波长选择、模型建立和评估。
3. 结果与讨论
3.1. 高光谱反射光谱
在930-2548 nm光谱范围内,玉米种子胚侧、胚乳侧和两侧提取的原始和预处理平均反射率光谱如图4所示。其中胚侧和胚乳侧分别对应有胚和胚乳的玉米种子的表面。混合光谱为胚侧光谱和胚乳侧光谱的平均值。图4a、b、c分别为胚侧、胚乳侧和混合后的原始反射光谱。这些光谱是从校准集中样品的高光谱图像中提取的。显然,可以观察到,不同侧面的光谱在全波长上具有相同的趋势,但也存在一定的差异。这可能是由于表面结构(有胚胎或胚乳的那一面)的不同造成的。从图4-a-b也可以很容易地观察到,在960 nm、1200 nm、1450 nm和1950 nm左右有四个相对明显的吸收峰。960nm处的吸收峰可能与水和碳水化合物中存在的O-H次泛音的共同作用有关。1450 nm附近的吸收峰可归因于O-H拉伸第一泛音,1200 nm和1950 nm附近的吸收峰也与种子中的MC有关[56 - 58]。经SG和SNV联合预处理法处理后的胚芽侧、胚乳侧及混合样本的光谱分别如图4d、e、f所示。可以发现,原始数据中的高频噪声被去除了,一些特征信息更加明显。
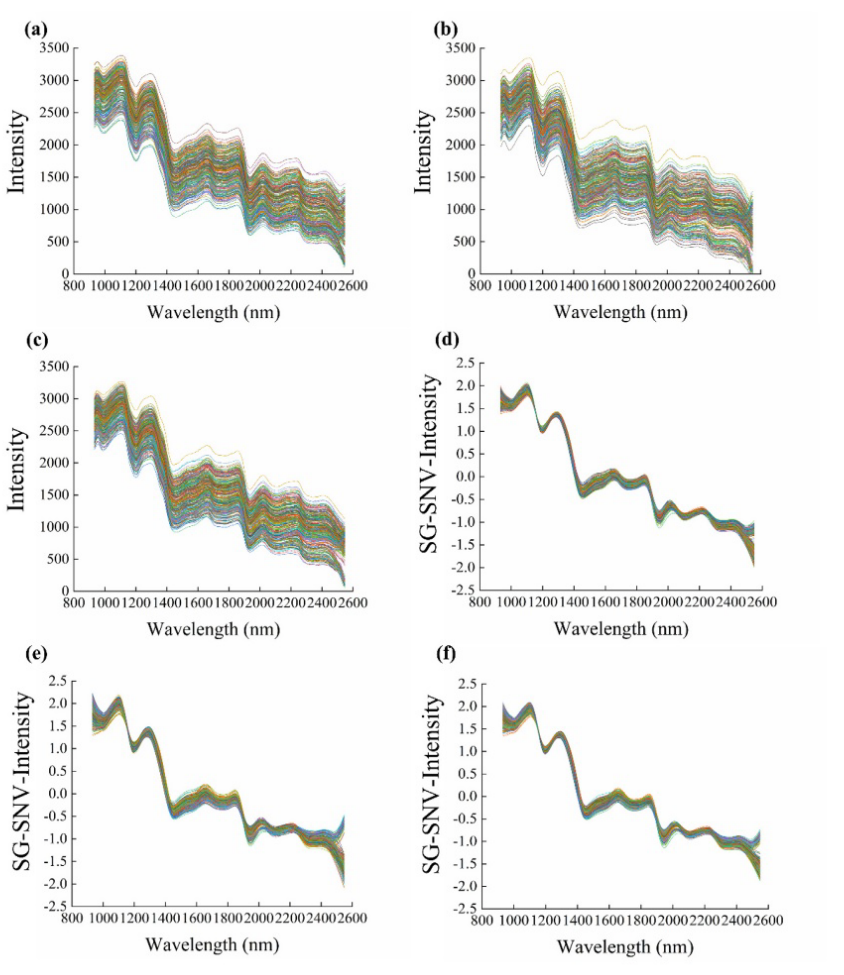
图4.原始光谱和预处理光谱
(a)、(b)、©分别为胚侧胚乳侧和混合后的原始光谱。(d)、(e)和(f)分别为胚胎侧胚乳侧和混合后的预处理光谱。
3.2. 基于全光谱的PLSR和LS-SVM模型
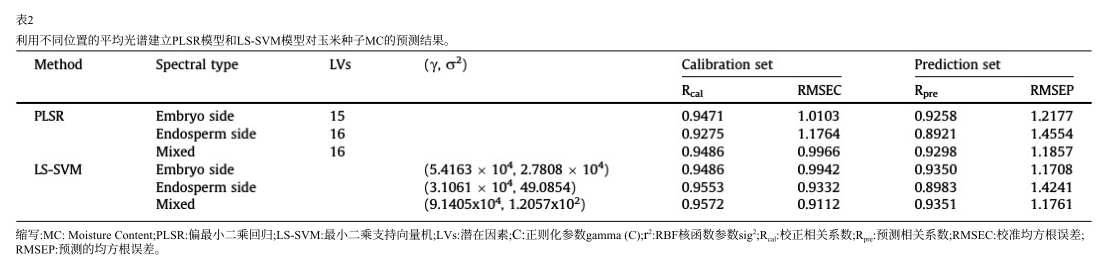
首先在不同类型全光谱预处理的基础上,建立了PLSR和LS-SVM模型,用于预测玉米单粒种子的MC。利用光谱与玉米种子MC之间的定量关系,建立基于校准集中样本的校准模型。预测集用于评估校准模型的实际预测能力。表2为PLSR和LS-SVM模型对玉米种子MC的预测结果。从表2可以观察到,基于胚侧和混合侧光谱建立的模型性能优于胚乳侧。对于PLSR和LS-SVM模型,分别以预处理前区光谱和混合区光谱作为输入,两者对MC的预测结果基本一致。更具体地说,从表中也可以看出,虽然LS-SVM模型的性能略好于PLSR模型,但这种差异非常小,不能作为判断哪个模型更好的标准。此外,整个光谱区域的波长过多也不利于模型预测速度和鲁棒性的提高。因此,模型仍需进一步优化。因此,在接下来的研究中,我们将利用预处理后的胚侧光谱和混合光谱建立PLSR和LS-SVM模型。
3.3. 特征波长的选择
3.3.1. CARS波长选择
首先采用竞争自适应重加权采样(CARS)算法,基于全光谱数据选择有效波长。使用全光谱数据和校准集中样品的MC值作为输入。对于CARS算法,将蒙特卡罗采样(MCS)运行次数设置为50次,并通过10倍交叉验证确定所选波长的数量。图5a、b、c分别为波长数、5倍RMSECV值以及各波长回归系数路径随MCS运行数增加的变化趋势。CARS特征波长选择分为快速选择和精细选择两个阶段(图5a)。具体来说,当采样运行次数小于10次时,采样变量的数量急剧下降,随后略有下降。在开始阶段,选择的波长数由于使用EDF而急剧下降,然后变得相对稳定。10倍的RMSECV值(图5b)在采样运行1-10次时下降,因为无信息波长被消除,然后在采样运行10-30次时缓慢变化。最后,当采样运行超过30次时,这些值迅速增加,因为一些有用的波长也被消除了。在图5c中,每条曲线记录了每个波长在不同采样运行时的系数路径。RMSECV最低的最优子集用蓝线标记。另外,可以发现一些有趣的现象,RMSECV值在采样点(L1线)跃升到一个新的水平,因为波长系数(P1点)同时降为零。这一解释同样适用于L2和P2。这些结果表明,如果没有这些波长,模型的有效性会降低。这就是为什么它们被称为最佳波长。通过CARS计算,从全光谱中选择22个波长用于预测玉米种子的MC。
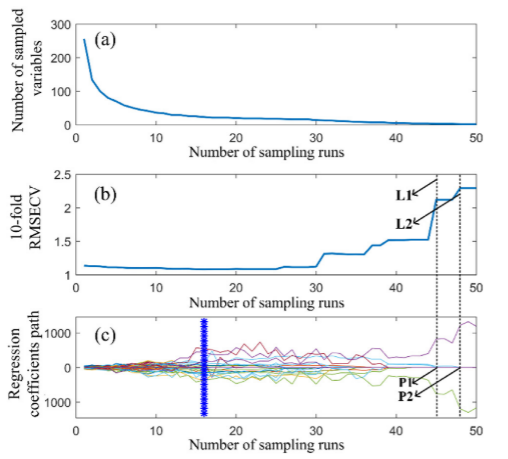
图5.波长(可变)选择CARS
波长(可变)选择CARS。(a)采样变量数量的变化趋势,(b) 10倍RMSECV, ©各变量的回归系数随运行次数的增加。蓝线表示具有最低10倍RMSECV的位置。
CARS是一种快速的波长选择方法,但由于蒙特卡罗采样的影响,波长选择结果不稳定。因此,CARS算法运行200次才能得到统计结果。均值和标准差如表3所示。
CARS基于胚胎侧光谱选择的特征波长数约为15-27个。基于混合光谱的特征波长数为15-31个。与全光谱相比,波长数量大大减少。CARS根据胚胎侧光谱和混合光谱在200次以内选择的波长频率分别如图7a和图8a所示。从图7a可以看出,高频波长主要集中在960 nm、1100 nm、1300 nm、1800 nm、2200 nm和2400 nm左右。从图8a可以看出,高频波长主要集中在960 nm、1100 nm、1300 nm、1500 nm、1800 nm和2000 nm附近。
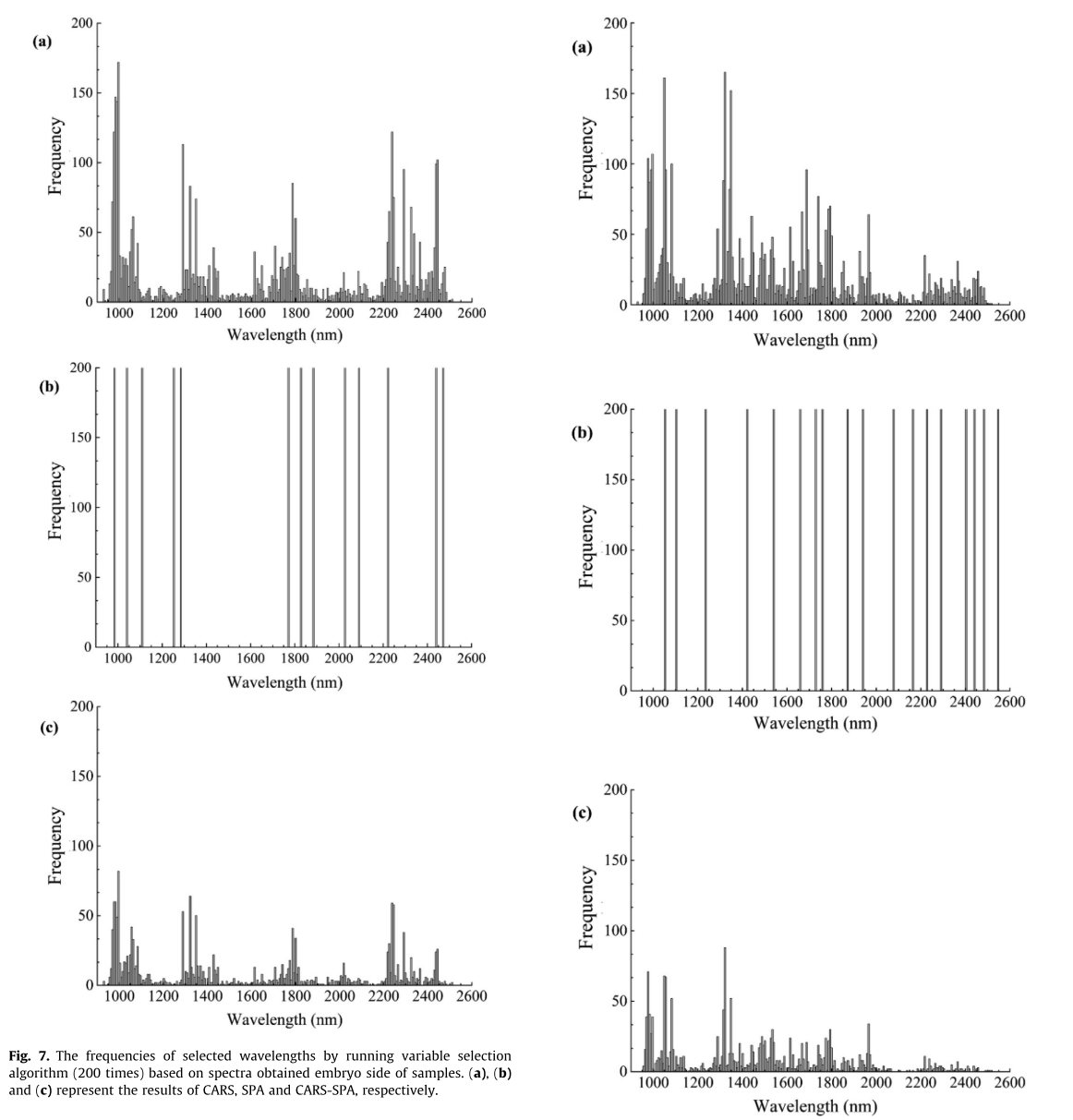
图7.根据获得的样品胚胎侧光谱,运行变量选择算法(200次)所选波长的频率。(a)、(b)和©分别代表CARS、SPA和CARS-SPA的结果。
图8.基于混合光谱,通过运行变量选择算法(200次)得到所选波长的频率,得到样本的两面。(a)、(b)和©分别代表CARS、SPA和CARS-SPA的结果。
3.3.2. CARS-SPA波长选择
CARS波长选择完成后,进一步采用SPA去除冗余波长。以图6为例,给出了基于混合侧光谱的SPA特征波长选择结果。RMSE的变化如图6a所示,其中红色方框表示所选波长的数量。可以发现,红色方框的位置对应RMSE的最低值(RMSE = 1.1425),最佳波长数为12。通过SPA选择的12个最佳波长如图6b所示。
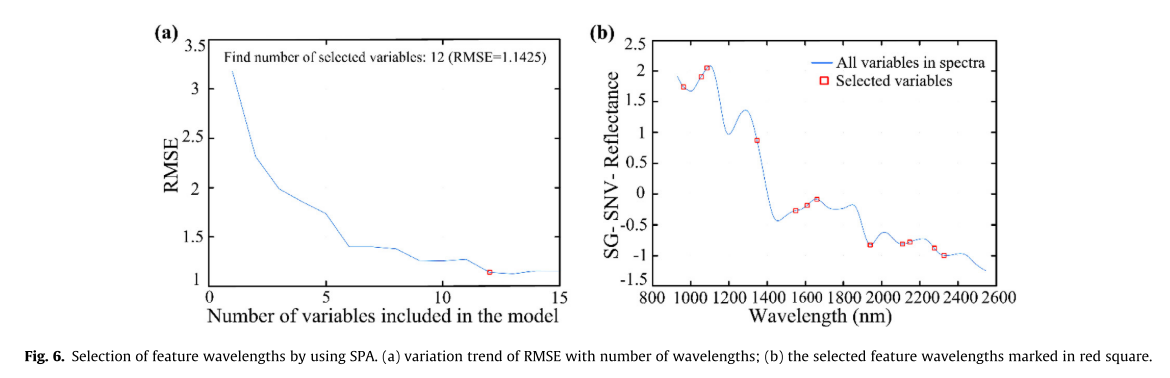
图6.通过使用SPA选择特征波长
(a)RMSE随波长数的变化趋势;(b)选择的特征波长用红色方框标记。
CARS-SPA波长选择算法也运行了200次。作为对比,采用SPA波长选择算法,并运行200次。统计结果也列在表3中。通过SPA算法,胚胎侧光谱和混合光谱的波长数分别为13和18。CARS-SPA基于胚侧光谱和混合光谱选择的最佳波长数分别为7-11和6 - 12。显然,CARS-SPA选择的特征波长数量是最少的。SPA和CARS-SPA算法在200次内选取的特征波长频率图如图7和图8所示。
图7b和图8b分别为基于胚侧光谱和混合光谱的SPA统计结果。可以观察到,在全光谱的基础上,每次SPA操作选择的波长是相同的。对比图7b和图8b, SPA算法应用于胚胎侧光谱时,1500 nm左右的光谱将被忽略。图7c和图8c分别是基于胚侧光谱和混合光谱的CARS-SPA统计结果。从图7c来看,高频波长主要集中在960 nm、1100 nm、1300 nm、1800 nm、2200 nm、2400 nm。由图8c可知,高频波长主要集中在960 nm、1100 nm、1300 nm、1500 nm、1800 nm和2000 nm附近。
3.4. PLSR和LS-SVM模型
基于胚侧全谱数据和混合数据,建立了PLSR和LS-SVM模型。如表3所示,无论是单一PLSR模型还是LS-SVM模型,不同位置全谱数据建立的模型的性能几乎没有差异。PLSR模型与LS-SVM模型比较,后者略优于前者。利用CARS选择的波长作为输入,分别建立PLSR和LS-SVM模型进行MC预测。结果如表3所示。对于PLSR和LS-SVM模型,基于混合光谱数据建立的模型比基于胚侧光谱数据建立的模型具有更好的MC预测性能。PLSR模型与LS-SVM模型的MC预测结果((Rpre= 0.9259±0.0075,RMSEP = 1.2361±0.0545)均优于LS-SVM模型。
利用SPA选择的波长作为输入,分别建立PLSR和LS-SVM模型。如图7和图8所示,由于每次SPA操作选择的波长相同,因此SPA-PLSR和SPA-LS-SVM模型的预测结果是稳定的。各模型的预测结果也如表3所示。尽管基于SPA和CARS的模型性能相似,但SPA可以获得更少的变量。更少的波长有利于提高操作速度和开发在线检测设备。因此,SPA-LS-SVM模型的预测能力略优于SPA-PLSR模型。其中,基于混合光谱数据得到的SPA-LS-SVM模型效果最好,Rcal= 0.9474,Rpre= 0.9341,RMSEC = 1.0072%, RMSEP = 1.1819%。
在基于CARS-SPA选择的波长建立的CARS-SPA-PLSR和CARS-SPA-LS-SVM模型中,无论是使用胚胎侧光谱还是混合光谱,CARS-SPA-PLSR的预测能力都较差。结果也列于表3中。基于混合光谱数据的CARS-SPA-LS-SVM模型预测效果最佳((Rpre= 0.9311±0.0094,RMSEP = 1.2131±0.0702)。
3.5. 模型的比较
如表3所示,波长选择算法可以减少波长的数量。从表中可以明显看出,基于CARS或SPA的模型可以在保持较高精度的同时减少波长数。原因是波长选择算法可以减少无用信息的数量,保留特征波长[36,60]。然而,CARS-SPA-PLSR的预测精度最低,而CARS-SPA-LS-SVM的预测精度较高。
从表3的数据来看,很难确定哪种模型更适合预测单个玉米的MC。针对每种类型的模型,分别建立了200个独立模型,用于预测玉米种子中的MC。图9显示了所有独立模型的Rpre和RMSEP的箱线图。显然,基于混合光谱建立的模型的性能比基于胚胎侧光谱数据建立的模型具有更好的稳定性和预测精度。
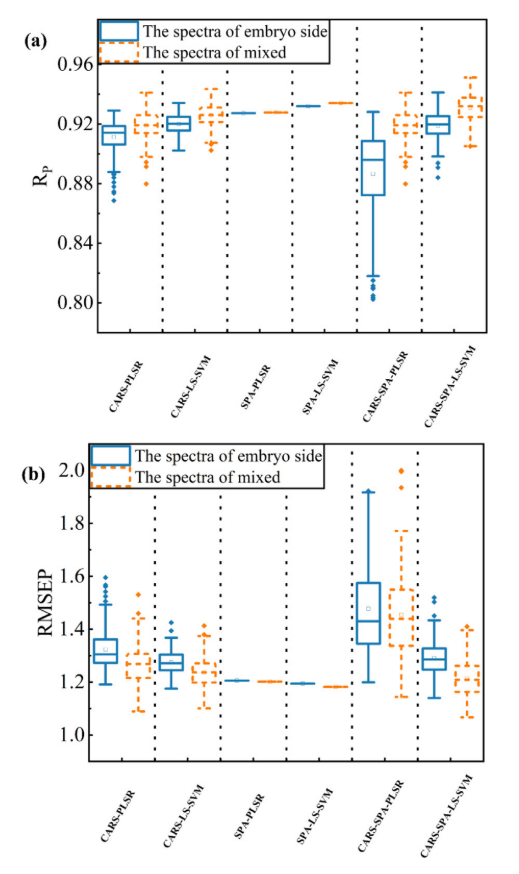
图9.运行200次的Rpre和RMSEP的箱线图。
(a)和(b)分别表示Rpre和RMSEP的箱线图。
通过对比分析图7与图8可以发现,基于胚芽侧光谱构建的波长选择算法在1400–1600 nm特征波段存在系统性忽略现象。然而,1450 nm处的吸收峰是由O-H拉伸引起的,第一泛音与含水量有关。从图9也可以看出,LS-SVM模型的预测性能优于PLSR模型。其原因可能是光谱中存在潜在的非线性信息,并与化学成分有关。因此,LS-SVM模型可以利用非线性信息建立更好的模型。同时,基于SPA的模型具有较高的稳定性和预测精度。因此,基于混合光谱的SPA-LS-SVM可以检测到单个种子的MC。然而,波长的数量是模型性能的指标之一。表3显示了基于不同波长选择方法的波长数。CARS显著地减少了波长的数量。基于不同位置的光谱数据,SPA可以将波长数减少到13、18个,基于SPA的模型非常稳定。基于CARS-SPA的波长数最少。与SPA相比,波长数明显减少,但CARS-SPA的性能仍然可以接受。更少的波长有利于开发成本更低的多光谱在线检测设备。综上所示,基于混合光谱的CARS-SPA-LS-SVM模型适用于玉米种子MC的预测。
由表3可以看出,CARS-SPA基于混合光谱数据选择的波长数为6-12。图10a为基于6、7、8、9、10、11、12不同波长数建立的CARS-SPA-LS-SVM模型的预测结果。为了比较,我们还选择频率较高的波长(CARS-SPA测量的6-12个波长)作为输入(见图8c),构建LS-SVM模型。带R和RMSE的预测结果如图10b所示。
图10a显示了不同波长数下的模型性能——波长数几乎相同。因此,最好的模型只需要6个波长就可以完成建模。CARS-SPA选取的6种近红外波长分别为961.7、1023.7、1060.9、1322.8、1498.7和1536.5 nm。其中,961.7、1322.8和1498.7 nm位于960、1200和1450 nm的吸收峰附近,与水分含量有关。
从图10b中可以看出,随着波长数的增加,模型的性能变化很大。前12个高频波段包括1322.8、974.1、1048.5、1054.7、1347.9、
1316.6、980.3、998.8、967.9、1968.1、1079.5和1796.1 nm,从高频到低频依次排列。当使用前9个高频波长建立模型时,模型出现
过拟合。原因是前9个高频波长是几个连续波段的组合,可能会降低模型的稳定性。当模型的输入是前10个高频波长时,模型的性能得到了显著提高。参考前人的研究,1968.1 nm位于1950 nm的吸收峰附近,这也与玉米种子中的MC有关。这一结果可以解释为:前10个高频波长的有机组合减少了共线性,提高了精度。
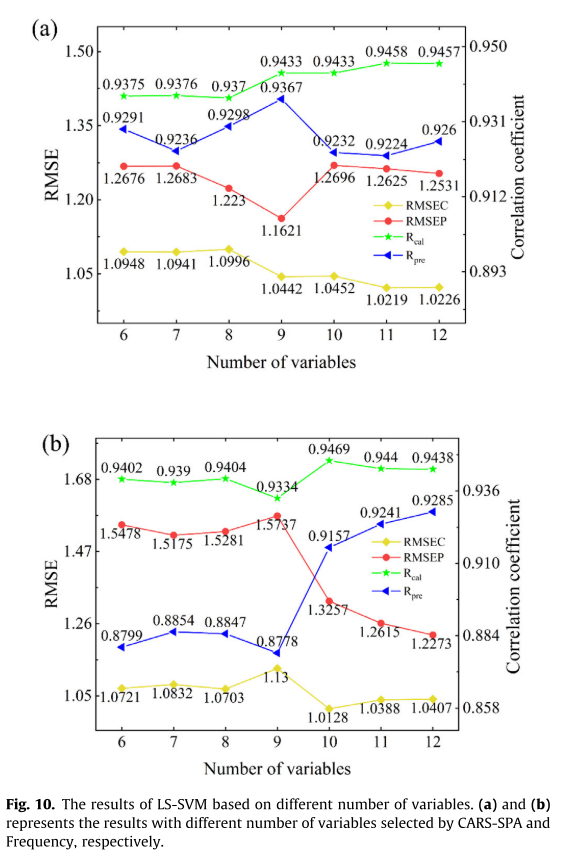
图10.基于不同数量变量的LS-SVM结果。
(a)和(b)分别表示CARS-SPA和Frequency选择不同数量变量的结果。
4. 结论
本研究验证了长波近红外高光谱成像(HSI)系统检测单粒玉米种子水分含量(MC)的可行性,并构建了简化且稳定的新型单粒玉米种子MC测定模型。与胚乳侧光谱相比,基于胚侧光谱和混合光谱的模型对单个玉米种子的MC检测具有更好的预测精度,其中混合光谱效果最好。混合变量选择方法CARS耦合SPA (CARS-SPA)在波长选择上取得了最好的性能。非线性模型比线性模型具有更好的预测能力。CARS-SPA-LS-SVM模型是综合模型精度和模型复杂度的最优模型。最佳CARS-SPA-LS-SVM模型仅使用6个波长即可完成MC的预测,最后选择基于混合光谱数据的CARS-SPA-LS-SVM模型用于单个玉米种子MC的检测。我们的研究结果表明,稳定性是评估模型性能的重要因素,并且可以使用几个关键波长来获得最优模型。但当特征波长是连续波长的组合时,预测模型的稳定性和准确性会降低。以往的研究通常使用特征波长选择算法只选择一次特征波长,结果存在不确定性,并且这些方法的稳定性无法测量。本文利用特征波长选择算法进行了200次独立实验,并建立了回归模型来测量稳定性。本文的思路以前没有报道过,这也体现了本文的创新之处。本文的研究结果为今后研究中特征选择算法的选择提供了现在的思路和参考。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











