








目录
简介:
这一节不会进行模拟实现,只会聊聊deque的底层
原因是我们学习deque是为了后面的适配器打基础,deque本身并不重要
初识deque
deque是一个双端队列,它是基于vector和list的优点为一身(但又不突出)
deque对头部数据进行处理时,时间复杂度会到达O(1) 弥补了vector的缺点
deque支持随机访问,也就是它支持了[]的重载,弥补了list的缺点
既然弥补了vector的缺点和list的缺点,那么为什么我们平时使用的时候好像没有使用过这个容器
不急,我们先看看deque的底层实现
deque的底层实现
deque插入
首先deque在实现时先有一段缓冲区(buffer)来存储数据
可以看到,图上的缓冲区满了
deque的尾插规则就是
如果缓冲区没满,那么直接在缓冲区后面插入
如果缓冲区满了,那么就重新申请一个buffer并插入数据
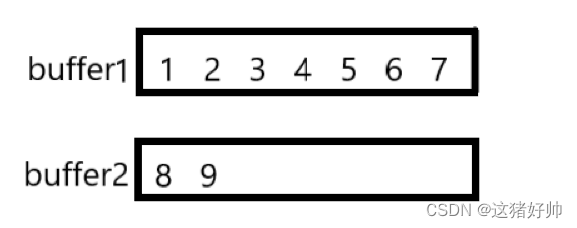
我们看到,buffer可能是存有多个的,既然有多个我们就需要对buffer进行管理
deque中就有了中控器
中控器是用来存储buffer指针的指针数组,我们直接用二级指针(因为中控也是要增容的)表示即可
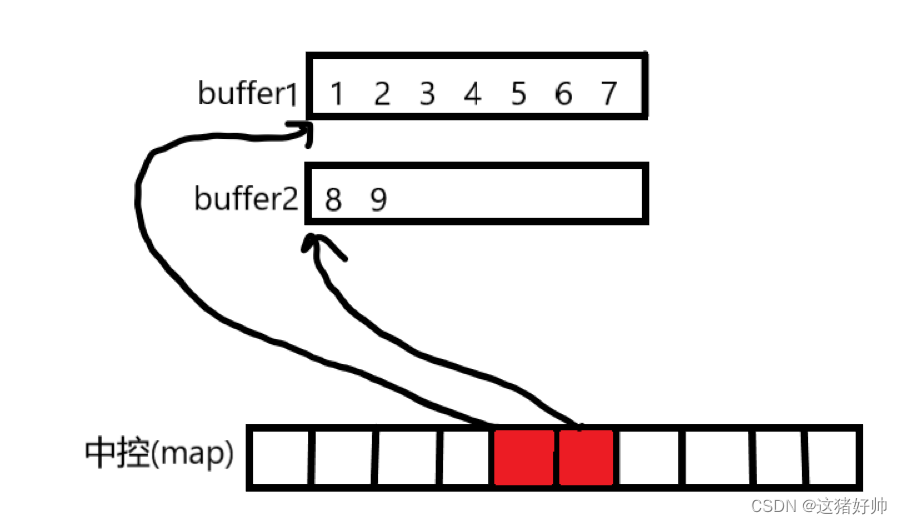
deque头插的规则:
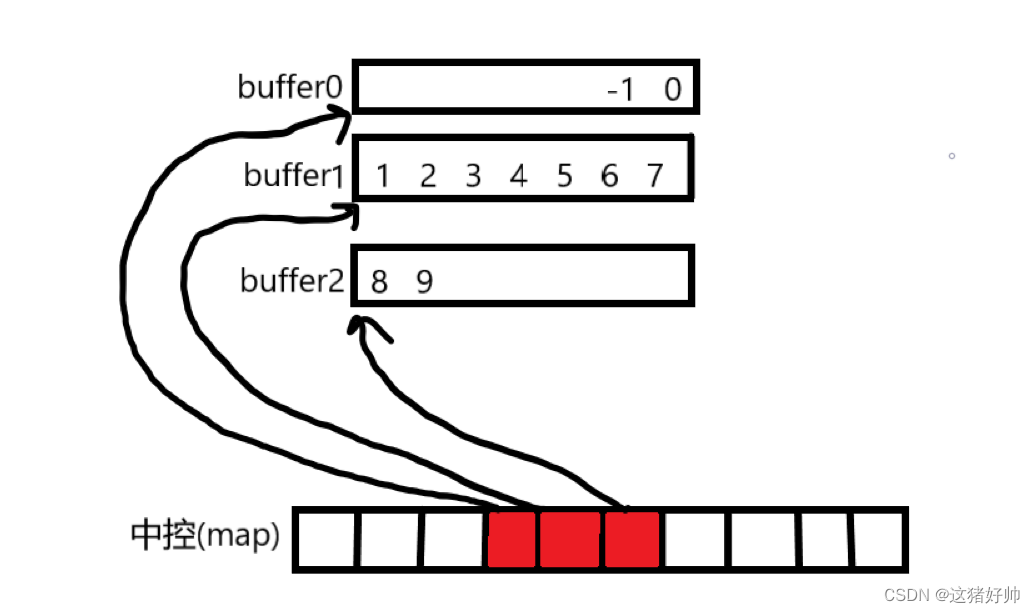
deque在进行头插的时候也是要重开一个buffer的
跟尾插不同的是,重新开的buffer进行头插时是从buffer的尾部开始插入的
例如,我们在上面图的基础上,先头插入一个0,再头插入一个-1
以上就是deque的头插和尾插的原理,接下来我们看看它的随机访问是如何实现的
deque的operator[]
T& operator[](size_t n);
首先先判断n是否大于第一个buffer的数据
如果小于第一个buffer的数据,那么返回的就是第一个buffer对应n的位置的数据
如果大于第一个buffer的数据,计算规则如下
(n-第一个buffer的数据多少)/每个buffer的大小 = 对应数据所在的第几个buffer
(n-第一个buffer的数据多少)%每个buffer的大小 = 数据在buffer中对应的下标
注意:buffer对应的大小应该从0开始
如上图,我们计算一下[8]所对应的数据
(8-2)/8 =0
(计算出来的是第一个buffer之后第0个buffer,这个是从0开始的)
(8-2)%8 = 6
(计算出来的6是对应buffer[6]所对应的数据)
最终,也就计算出了对应的数据在buffer1下标为6的位置也就是7
deque的迭代器
如图:
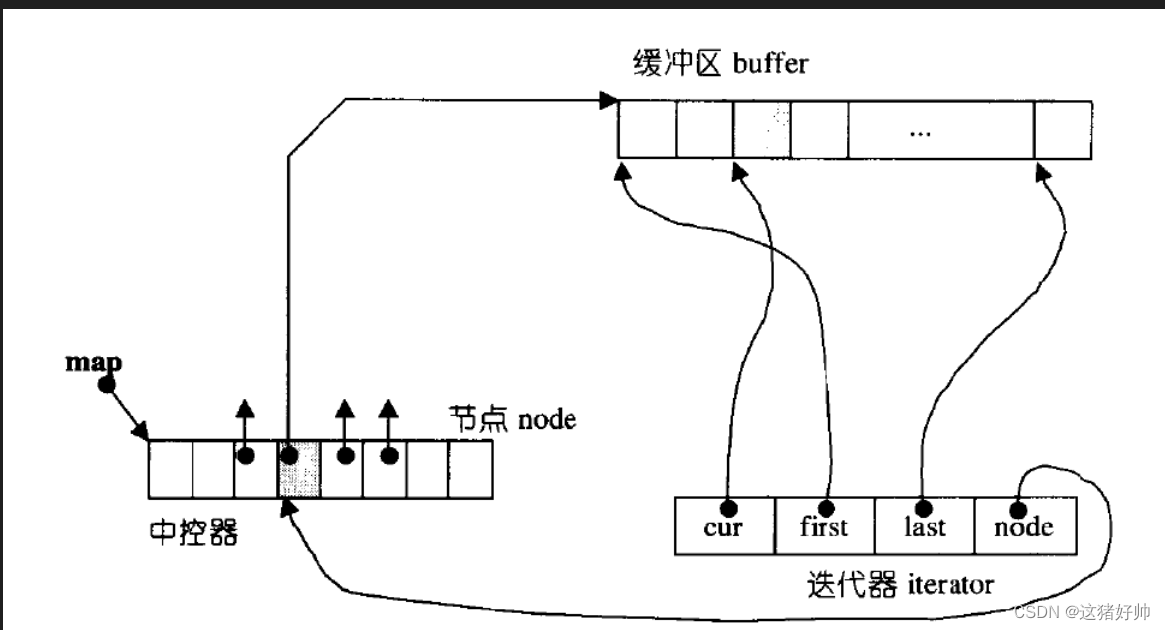
(节选自STL源码剖析)
可以看到,deque的迭代器中有四个成员:cur、first、last、node,那他们对应的功能是什么呢?
cur:指向的数据
first:指向的是这段buffer所在的开始位置
last:指向的是这段buffer所在的结束位置
node:指向的是这段buffer在中控所对应的下标
可以看出,deque的迭代器其实是蛮复杂的
当我们进行++时,迭代器会进行判断,cur是否等于last
如果cur等于last,就让node指向下一个buffer,并把cur指向buffer的first
如果cur不等于last,就让cur指向下一个下标所对应的数据即可
deque的缺陷
既然我们在实际当中不经常使用deque,那么他肯定是有所缺陷的
正如它的优点是与vector和list相比,那么它的缺点肯定也是跟这两个容器相比
所谓成也萧何,败也萧何
与vector比的缺陷
首先我们比较一下它的随机访问和vector的随机访问
deque的随机访问是要通过计算的
vector的随机访问是通过下标直接找到,不需要计算
那么deque如果进行大量的随机访问,效率就会比vector慢很多很多
我们写一个代码测试一下
#include<iostream>
#include<deque>
#include<vector>
#include<ctime>
using namespace std;
#define NUM 10000000 //10000000次随机访问
void TestDequeVector()
{
deque<int> d;
vector<int> v;
srand((long long)time(nullptr));
for (int i = 0; i < 10000; ++i)
{
int x = rand();
d.push_back(x);
v.push_back(x);
}
int begin1 = clock();
for (int i = 0; i < NUM; ++i)
{
d[i % 10000]++;
}
int end1 = clock();
cout << "deque:" << end1 - begin1 << endl;
int begin2 = clock();
for (int i = 0; i < NUM; ++i)
{
v[i % 10000]++;
}
int end2 = clock();
cout << "vector:" << end2 - begin2 << endl;
}
int main()
{
TestDequeVector();
return 0;
}
与list相比的缺陷
虽然说deque的头部插入和list的头部插入都达到了O(1)
但他们两的区别在于中间插入
deque的中间插入是需要挪动数据的(因为如果扩容了小buffer,那么下标就无法进行访问了)
list的中间插入一如既往的稳定,时间复杂度还是O(1)
#include<iostream>
#include<list>
#include<deque>
#include<ctime>
using namespace std;
#define NUM 10000 //插入的数据
void TestDequeList()
{
list<int> l;
deque<int> d;
//先插入100000个数据,不然不好统计中间插入
for (size_t i = 0; i < 100000; ++i)
{
l.push_back(i);
d.push_back(i);
}
size_t mid = 100000 / 2;
list<int>::iterator lit = l.begin();
deque<int>::iterator dit = d.begin();
while (mid)
{
//找到中间数据
++lit;
++dit;
mid--;
}
//从这里开始记录clock
int begin1 = clock();
for (size_t i = 0; i < NUM; ++i)
{
lit = l.insert(lit, 1);
}
int end1 = clock();
cout << "list insert : " << end1 - begin1 << endl;
int begin2 = clock();
for (size_t i = 0; i < NUM; ++i)
{
dit = d.insert(dit, 1);
}
int end2 = clock();
cout << "deque insert : " << end2 - begin2 << endl;
}
int main()
{
TestDequeList();
return 0;
} 
deque的优势
1、空间利用率比起list较高
2、 与vector相比支持头插和尾插,且都达到了O(1)时间复杂度(作为适配器的主要条件)
3、与list相比无需频繁申请空间
4、与vector相比扩容代价小(空间满了以后只需扩容中控,中控一次扩容可以存放很多数据)
5、与vector相比空间浪费少
那么这期deque介绍就到这里了,感谢大家的支持















 302
302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









