






排行榜是游戏中重要的功能,如何才能实现一个高效的排行榜呢?我所在的项目组做的是SLG游戏,我们游戏的很多活动都有排行榜。上周接到一个跨服排行榜的功能案,需求是让现有的排行榜支持跨服。
一、问题描述
目前每个服的玩家大概4W人,如果战力排行榜做成跨服,开到300个服时,上榜人数会超过1kw。虽然很少有游戏能开到300个服,但作为服务器程序设计功能时必须要考虑极端情况,选择适合的方案,不然可能有推倒重来的风险。下面介绍2种实现排行榜的方案,一是快速排序,另一种是redis实现。
二、快速排序实现
实现方式如下:
- 玩家分数变化时,更新到内存缓存,比如map。
- 用快速排序定时对内存中的数据排序,生成成榜单。
- 把排序生成的榜单推送到对应的区服。
优化:
假如配置榜单只显示前1k名的玩家,除首次排序外,我们可以只让分数>最后一名的玩家参与排名,避免每次都全量排。排完名把1k名以外的玩家移除排序缓存,以保证参与排序的玩家不会越来越多。这样做可以解决排序基数大的问题,把每次需要排序的玩家从1kw减少到1k左右。
但这种方式还是很有局限,比如,不管玩家不上不榜,都要显示自己的名次。这是不是要对所有玩家名排序呢?或者有一个GM需求是从后台查看某榜单前N名的玩家,那又该如何应对呢?
游戏中排行榜比较主流的做法是用redis排序,那么redis内部是如何实现的呢?下面我们结合源码来一探究竟。
三、跳表实现
排行榜的另一种实现方式是使用redis中的有序集合SortedSet,其底层是通过跳跃表实现的。跳跃表拥有非常好的查找、插入、删除性能(logn),而且可以很方便的获取名次区间内的节点,这恰好是排行榜需要的功能。
1.1 基本思想
跳表非常像一个有序双向链表,它的插入,删除操作都跟双向链表操作类似,需要更新当前节点前驱和后继节点的指针。不同在于,比链表的节点多了层高和跨度的概念。
层高:节点的层数,插入节点时随机生成。 查找节点时,从层高最高的节点开始查找,如果查找score > 当前层下一个节点的score,则继续在当前层查找,否则进入下一层用同样的方法查找,直到查找成功或失败。
跨度:也叫跳数,第i层当前节点到第i层下一个节点的距离,这是跳表的核心。 当查找一个节点时,从当前节点到下一个节点可能直接跳过N个节点,查找路径上的跳数和就是节点在跳表中的名次(升序)。

1.1 数据结构
本文使用的源码版本为redis 6.0跳表结构由2部分组成:
-
跳表节点:跳表是由节点组成的双向链表
typedef struct zskiplistNode { //其实就是命令ZADD key score member中的member,member值在跳表中是唯一的,当score相同时会根据member(ele)字典顺序升序排节点 //sds可以看成对char*的封装,redis中的字符串都用sds表示。[参考]https://redisbook.readthedocs.io/en/latest/internal-datastruct/sds.html sds ele; //分数用于节点排序(升序),对应命令中的score double score; //指向上一个节点,ZREVRANGE相关命令会用到,因为跳表是按score升序的有序链表 //但排行榜通常需要按score降序,假如取[1~3]名的玩家,我们首先需要把指针移到跳表尾部 //通过backward取到前3名 struct zskiplistNode *backward; struct zskiplistLevel { struct zskiplistNode *forward; //下一个节点 unsigned long span; //跨度,当前节点到同层下一个节点的跨度 } level[]; //节点层级,每个节点可拥有1~32个层级 } zskiplistNode; -
跳表节点信息:记录了跳表节点的基本信息
typedef struct zskiplist { //header指向头节点, tail指向最后一个节点。需要注意的是,头节点是个特殊节点,不包含数据。尾节点是个包含数据的正常节点。 struct zskiplistNode *header, *tail; unsigned long length; //跳表节点数 int level; //最大层高 } zskiplist;
1.2 查找
下图是一个节点数为10,层高为4的跳表结构。
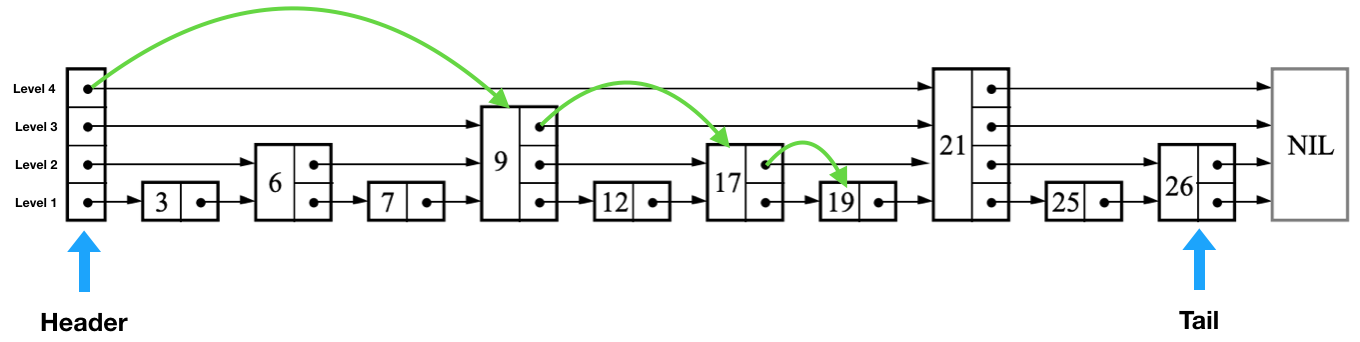
绿色箭头为查找score为19的节点需要经历的路径,步骤如下:
- 从header节点不为NULL的最高层开始查找,本例为level4。
- level4的forward指向的节点score为21, 21 > 19, 则查找下一层(level3)
- level3指向的节点score为 9, 9 < 19, 则当前指针指向score为9的节点
- score为9节点的forward节点值为21, 21 > 19, 则查找下一层(level2)
- level2的forward节点值为17, 17 < 19, 则当前指针指向score为17的节点
- score为17节点的forward节点值为21, 21 > 19, 则查找下一层(level1)
- score为17节点(level1)的forward节点值为19, 查找成功
源码:
/*通过分数和key查找跳表节点,找到则返回节点的排名,否则返回0
*需要注意的是,节点的排名是从1开始的,因为0为header节点*/
unsigned long zslGetRank(zskiplist *zsl, double score, sds ele) {
zskiplistNode *x;
unsigned long rank = 0;
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {//从跳表最高层开始查找
while (x->level[i].forward && //如果当节点forward不为NULL,且forward.score < score,则当前指针x指向同层的下一个节点
(x->level[i].forward->score < score ||//或者 score相等且forward的ele < ele (score相等时,按ele值升序排,我们目标是找到score和ele都等于等查找值的元素)
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) <= 0))) {
rank += x->level[i].span; //rank累加
x = x->level[i].forward; //指向同层下一个节点
}
/*如果没找到的话 x 指向 zsl->header, header节点的ele值为NULL, 所以如果x->ele不为NULL 且 等于 els 说明找到,则返回它的rank*/
if (x->ele && sdscmp(x->ele,ele) == 0) {
return rank;
}
}
return 0;
}
1.3 插入
#define ZSKIPLIST_MAXLEVEL 32 /* 最大层数 */
#define ZSKIPLIST_P 0.25 /* 概率为25% */
/*为即将插入的节点随机一个层数[1, 32],随到2层概率为1/4,随到3层的概率为1/4*1/4
* 随机到32层的概率为1/2^63*/
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
/* 在zsl上插入一个节点*/
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x; //update为待更新的节点层,因为插入节点后,这些节点层的forward指针和span都可能发生变化,记录是方便插入后修改
unsigned int rank[ZSKIPLIST_MAXLEVEL]; //待更新节点层的排名
int i, level;
/*这个for的逻辑跟zslGetRank里面的一样,从header最高层开始查找,直到找到新节点的插入位置,不同的是这里记录了查找路径上插入节点后需要更新的节点层以及排名*/
serverAssert(!isnan(score));
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
/*为即将插入的节点随机一个层高,若随机到的层高>当前跳表高大层高,则需要把header > level的层指向新节点的层,
*这里先缓存到update,后面再作修改。
*同时把header->level[i].span值设为zsl->length, 这样做是为了方便后面的公式计算新节点以及update中的span*/
level = zslRandomLevel();
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level; //把跳表的level设置为新高度(level)
}
x = zslCreateNode(level,score,ele); //new一个新节点
//从最低层到最高层更新新节点的各层,以及新节点插入后,影响到的update缓存中的节点层
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward; //普通的链表插入
update[i]->level[i].forward = x;
/*rank[0] - rank[i] 结果为 插入节点与插入位置第i层上一个节点之间的跨度,假设为delta
*update[i]->level[i].span为i层待更新节点的跨度 - delta 就是插入节点的 span */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
//因为插入了一个节点,所以待更新节点的跨度为 delta + 1
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* 高于插入层级的span也要+1,因为在以前跨度的中间插入了一个了个节点 */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
/*计算插入节点的backward指针 以及插入节点下一个节点的backward指针*/
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;//跳表总节点数+1
return x;
}
1.4 删除
/* 从跳表中删除一个元素,删除成功返回1(找到且成功删除),失败返回0
* 如果参数node为NULL,从跳表中删除节点后,直接释放空间,否则只从链表(跳表)上删除,
* 把这个节点通过*node返回给调用方,调用用方可能复用这个节点。*/
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
/*跟查找插入类似,删除一个节点时,需要记录删除节点后,要影响到的节点层(更新它们的sapn)*/
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
x = x->level[i].forward;
}
update[i] = x;
}
x = x->level[0].forward;
if (x && score == x->score && sdscmp(x->ele,ele) == 0) {/*如果找到节点*/
zslDeleteNode(zsl, x, update);/*先从跳表中删除,并更新update节点层的span*/
if (!node)/*如果要复用则通过*node返回,不复用则直接释放*/
zslFreeNode(x);
else
*node = x;
return 1;
}
return 0; /* 没找到返回0 */
}
/*删除节点,参数x为待删除节点*/
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
for (i = 0; i < zsl->level; i++) {
/*如果update[i]是待删除节点前一个节点,则update[i]->level[i].span为自己的span+删除节点的sapn-1*/
if (update[i]->level[i].forward == x) {
update[i]->level[i].span += x->level[i].span - 1;
update[i]->level[i].forward = x->level[i].forward; /*更新update[i]的forawrd指针*/
} else {
/*因为是从update[i]的跨度中删除一个节点,所以update[i]的span需要-1*/
update[i]->level[i].span -= 1;
}
}
if (x->level[0].forward) {/*如果x不是最后一个节点,更新x下一个节点的backward为x的backward*/
x->level[0].forward->backward = x->backward;
} else {/*如果x是最后一个节点,把跳表的tail指针指向backward*/
zsl->tail = x->backward;
}
/*如果删除的节点层级是跳表中最高的,则需要更新跳表的level*/
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;
/*删除一个元素,节点数-1*/
zsl->length--;
}例:通过玩家ID而非分数来查询排行榜中玩家的排名,可以采用如下方法:
- 在redis的跳表结构中,同时以分数score和玩家ID作为键存入记录。
比如:
zadd rankboard 100 "user1"
zadd rankboard 90 "user2"
- 为每个玩家创建一个索引键,值为分数。
比如:
set user1:rank 100
set user2:rank 90
- 查询玩家排名时:
-
首先通过ID键获取玩家的分数值
-
再通过分数值在跳表中查找排名
例如:
get user1:rank
zrevrank rankboard 100
这样就可以通过玩家ID直接获取其排名,同时利用跳表保持基于分数的排名有效。
这需要额外的数据结构索引来支持,但操作简单方便通过ID查询排名。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









