






引言
这是我写的第二篇与离散数学有关的算法,希望能对大家有所帮助。下面我们就一起来认识一下什么是哈夫曼算法,哈夫曼算法有什么用。
Huffman(哈夫曼)算法
算法历史
1952年,David A. Huffman在麻省理工学院攻读博士时发表了《一种构建极小多余编码的方法》(A Method for the Construction of Minimum-Redundancy Codes)一文,它一般就叫做Huffman编码,这种算法有效地解决了在编码字符串时带来的存储空间浪费问题。
算法原理
huffman算法的编码是一种可变长度的编码算法。在解释过程中,我们可以假设有一个很长很长的字符串,其中只包含六个字符A1、A2、A3、A4、A5、A6。如果按照传统的固定长度编码,可以将其编译为下表所示:
| A1 | A2 | A3 | A4 | A5 | A6 |
| 000 | 001 | 010 | 011 | 100 | 101 |
以上就是固定长度的编码了,下面我们按照可变长度编码:
| A1 | A2 | A3 | A4 | A5 | A6 |
| 00 | 11 | 011 | 101 | 010 | 100 |
可以发现,按照这样进行编码,部分源符号在编码过程中会短一些。如果我们需要编码的符号长度为50万字,假设A1、A2出现的概率为30%、30%,其余字符出现的概率为10%。那么,按照固定长度编码则可能需要3*50=150万个0和1来存储这些字符。按照可变长度来存储的话就是50*0.6*2+50*0.4*3=120万。如此一来是不是就减少了许多。
但是如果按照可变长度编码符号的话,可能会出现一个潜在的问题,那就是编码的歧义。下面我们来看一段编码:
| A1 | A2 | A3 | A4 | A5 | A6 |
| 0 | 1 | 101 | 100 | 110 | 1100 |
假设这是一段可变编码,其中的符号对应着下方的编码,如果我们按照如此编码一段符号为01100。
其中不难发现,如果把这段编码的0-1-100如此分开,则解码为A1A2A4,但是情况却不仅仅如此。我们还可以将这段编码理解为0-1100,0-110-0。此时的结果就可能是A1A6或者A1A5A1,产生了很大的歧义,我们不希望如此,于是huffman算法的出现就帮助我们解决了这一难题。
前缀编码
既然我们不希望编码出现歧义,那么我们就需要一种无论何种情况下,编码结果都只可能唯一的编码,就是所谓的前缀编码。
前缀编码的概念是没有一个编码是其它编码的前缀,也可将其理解为无前缀编码。这种编码我们可以通过离散数学中的二叉树来获得。
二叉树
在计算机科学中,二叉树(英语:Binary tree)是每个节点最多只有两个分支(即不存在分支度大于2的节点)的树结构。通常分支被称作“左子树”或“右子树”。二叉树的分支具有左右次序,不能随意颠倒。
下面我们就使用二叉树来解决以下问题:
假设有一串字符,其中包含A1、A2、A3、A4、A5、A6六个符号,出现频率如下表:
| 符号 | A1 | A2 | A3 | A4 | A5 | A6 |
| 出现频率 | 0.13 | 0.18 | 0.16 | 0.07 | 0.32 | 0.14 |
问题:求这留个符号的最优编码?
我们先将每个需要编码的符号节点放置在一个集合中,然后根据其权重将其中最小的两个节点拿出后与一个新增的父节点连接,之后将新增父节点再次放入优先序列中,接着选取更新后的优先序列中的权重最小的节点,与下一个新增父节点连接,以此类推。
| 节点集合 | A1(13)、A2(18)、A3(16)、A4(7)、A5(32)、A6(14) |
上表就是一个节点集合,我们选择最小的两个节点A4和A1,连接到新增节点0后,再将0放入:
| 节点集合 | 0(20)、A2(18)、A3(16)、A5(32)、A6(14) |
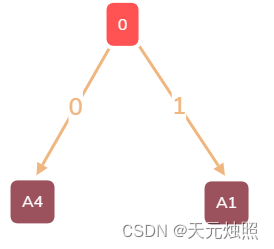
再次比较集合中的节点权重大小,将A6和A3拿出,连接新增父节点1,放入集合中。
| 节点集合 | 0(20)、A2(18)、A5(32)、1(30) |
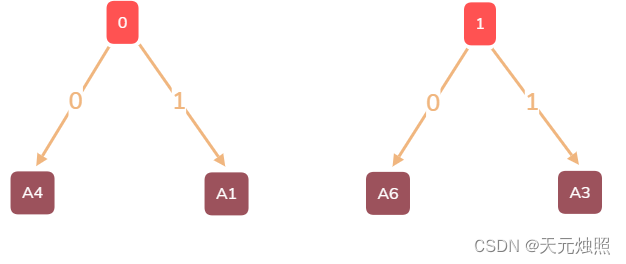
重复这个过程直到集合中没有内容,最终便得到了能够编码这6个字符的二叉树,也是最小二叉树:
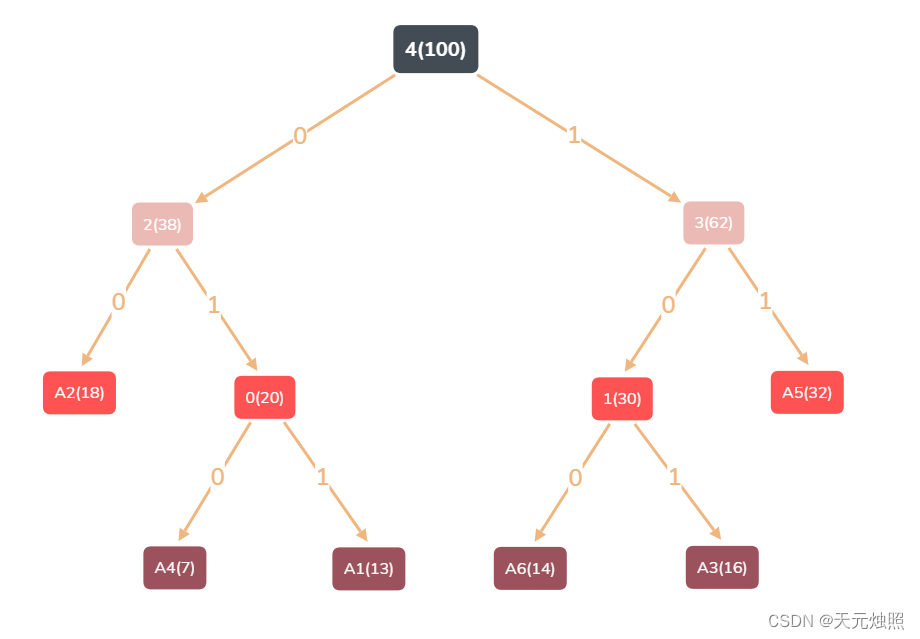
这样选取最小节点不断连接的方法就是huffman算法。
程序设计
设计介绍
根据以上解释,我们可以设计一个二叉树类和一个节点类,如下:
(Node)类
import java.util.Comparator;
public class Node implements Comparator<Node> {
//存储节点号数
private String node;
//存储节点权重
private int weight;
//存储节点的根节点和其左右子节点
private Node root=null;
private Node left=null;
private Node right=null;
//初始化节点
public Node(String node,int weight){
this.node = node;
this.weight = weight;
}
//空构造函数用于有限序列的排序
public Node(){}
//get和set方法
public String getNode() {
return node;
}
public void setNode(String node) {
this.node = node;
}
public int getWeight() {
return weight;
}
public void setWeight(int weight) {
this.weight = weight;
}
public Node getRoot() {
return root;
}
public void setRoot(Node root) {
this.root = root;
}
public Node getLeft() {
return left;
}
public void setLeft(Node left) {
this.left = left;
}
public Node getRight() {
return right;
}
public void setRight(Node right) {
this.right = right;
}
//排序算法
public int compare(Node n1, Node n2) {
return Integer.compare(n1.getWeight(), n2.getWeight());
}
}
(BinaryTree)二叉树类
import java.util.ArrayList;
import java.util.List;
import java.util.PriorityQueue;
public class BinaryTree {
private final List<Node> nodeList;//存储节点的最初集合
private final List<List<Node>> treeList;//存储树的集合
private int nodeNum;//录入数据时节点的编号
//初始化nodeList和treeList
public BinaryTree() {
this.treeList = new ArrayList<>();
nodeList = new ArrayList<Node>();
}
//录入节点数据
public void insert(String node, int weight) {
nodeList.add(new Node(node, weight));
}
//huffman算法
public void huffman() {
//建立优先队列
PriorityQueue<Node> pq = new PriorityQueue<Node>(nodeList.size(), new Node());
//在队列中添加节点集合内容
pq.addAll(nodeList);
//开始构造最小生成树
while (pq.size() > 1) {
//取出优先队列中权重最小的节点
Node node1 = pq.poll();
//再次取出队列中权重最小的节点
Node node2 = pq.poll();
//确保第二次取出的值不为null
assert node2 != null;
//构造两个节点的根节点
Node node3 = new Node(String.valueOf(nodeNum++), node1.getWeight() + node2.getWeight());
//设置node3为其子节点的父节点
node1.setRoot(node3);
node2.setRoot(node3);
//设置node3的子节点
node3.setLeft(node1);
node3.setRight(node2);
//将根节点加入队列
pq.add(node3);
//添加节点连接
List<Node> temp1 = new ArrayList<>();
List<Node> temp2 = new ArrayList<>();
temp1.add(node1);
temp1.add(node3);
temp2.add(node2);
temp2.add(node3);
//构造最小生成树
treeList.add(temp1);
treeList.add(temp2);
}
}
//返回最小生成树的集合
public List<List<Node>> getTreeList() {
return treeList;
}
//打印最小生成树的连接逻辑
public void printTree() {
for (List<Node> treeList : treeList) {
int count = 0;
for (Node node : treeList) {
System.out.print(node.getNode() + "(" + node.getWeight() + ")");
if (count < 1)
System.out.print("<-");
count++;
}
System.out.println();
}
}
//打印源符号编码
public void printCode() {
for (Node node : nodeList) {
System.out.println(node.getNode() + ":" + code(node));
}
}
//使用递归获得源符号编码
public String code(Node node) {
if (node == null || node.getRoot() == null)
return "";
return code(node.getRoot()) + ((node.getRoot().getLeft().equals(node)) ? "0" : "1");
}
}
(Main)类【用于测试】
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner cin = new Scanner(System.in);
BinaryTree bt = new BinaryTree();
int n = cin.nextInt();
for (int i = 0; i < n; i++) {
bt.insert(cin.next(), cin.nextInt());
}
bt.huffman();
System.out.println("Huffman Tree:");
bt.printTree();
System.out.println("Code:");
bt.printCode();
}
}测试结果
测试数据
6
A1 13 A2 18 A3 16 A4 7 A5 32 A6 14运行结果
Huffman Tree:
A4(7)<-0(20)
A1(13)<-0(20)
A6(14)<-1(30)
A3(16)<-1(30)
A2(18)<-2(38)
0(20)<-2(38)
1(30)<-3(62)
A5(32)<-3(62)
2(38)<-4(100)
3(62)<-4(100)
Code:
A1:011
A2:00
A3:101
A4:010
A5:11
A6:100总结
如果大家没有看懂我讲的算法原理的话,可以去看b站上的动画演示:
最后,感谢大家阅读我的文章,如有什么不妥之处可以在评论区指出,谢谢大家,祝大家学业进步啦!















 687
687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









