










引言
- 在常见的字符串匹配中:给定n个字符换,查找某一个字符串,如果用暴力法的话,时间复杂度显然为 O ( m n ) O(mn) O(mn),m为 a v g ( Σ 字符串 ) avg(Σ字符串) avg(Σ字符串)。
- 暴力匹配所需字符串的代码如下:
#include<iostream> #include<string> using namespace std; const int N = 100; string ss[N]; int main() { int n; cin>>n; for(int i = 0; i < n; i++) cin>>ss[i]; string p; cin>>p; for(int i = 0; i < n; i++) { if(p.size() != ss[i].size()) continue; for(int j = 0; j < p.size(); j++) { if(p[j] != ss[i][j]) break; else if(p[j] == s[i][j] && j == p.size()-1) { cout<<"find it"; return 0; } else continue; } } cout<<"fail to find"; return 0; } - 显然,如果要匹配的n个字符串的数量很大的话,那么暴力法的效率将会非常的低。那么,有什么好的,更高效的匹配方法呢?
Trip树
- 在日常生活中,大家都有查英文字典的经历,比如查找单词
cat,那么把字典先翻到c处,再翻到第二个a,第三个单词t处,就可以找到我们所需要的单词。查询次数仅仅为3次。也即查找某个单词的次数仅仅为其单词的长度。 - 字典树(Trip,又名前缀树),便是模拟查字典的这个操作的一个
糕级高级数据结构。字典树是一颗多叉树,如英文字母的字典树为26叉树,阿拉伯数字0~9则为10叉树。 - 那么,该如何构造字典树呢?我们先给定以下单词:
tree,trip,man,mom,may,mana,将其建立成为一颗以下26叉树:
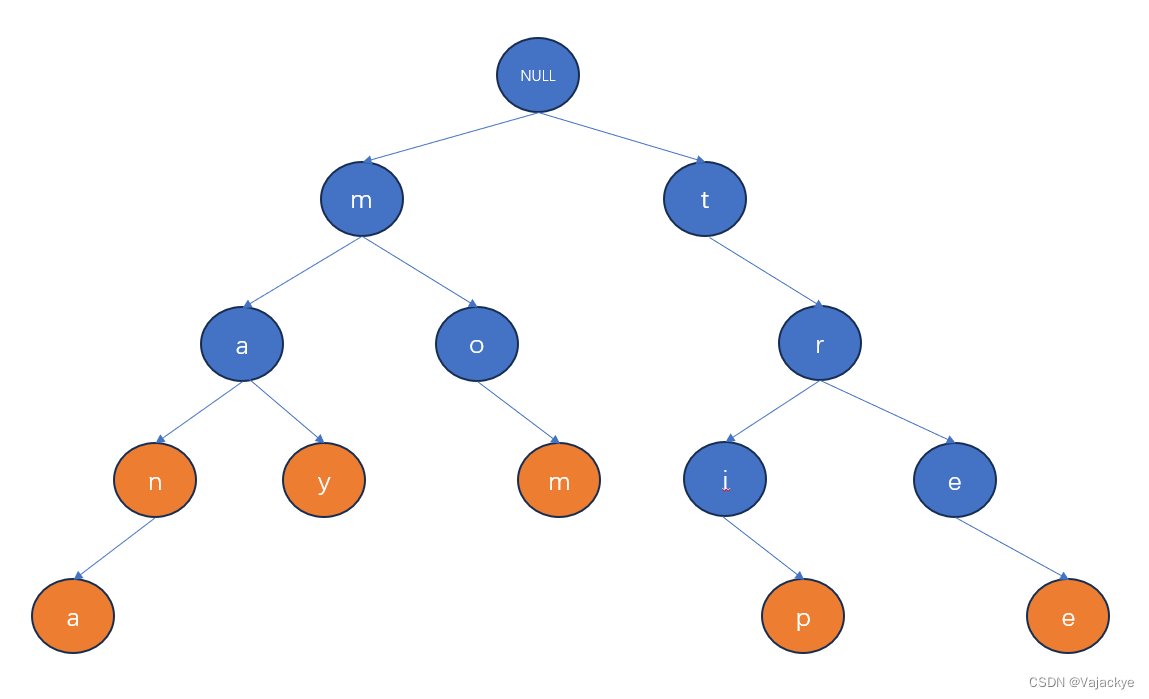
- 如图,多个具有相同前缀的单词,共用前缀。为确定每一个单词出现过,我们用橙色标出,代码则可设置一个相应的标记,表示存在这个单词 (题目给出的,生活中有该单词,题目未给也不存在)
- 如图可发现,我们仅用很少的结点,存储了好几个单词。由此图我们可以得出前缀树的一些性质:
- 根节点不放字符!
- 从根节点到某一结点,路径上的所有字符连接起来就是该节点对应的字符串。
- 一个完整的单词被一条链存储,且一个结点的所有孩子结点都具有相同的前缀。
- 给一道例题进行详解(核心代码为
insert()建树操作):
维护一个字符串集合,支持两种操作:
1.I x向集合中插入一个字符串 x x x.
2.Q x询问一个字符串在集合中出现了多少次。
输入格式:第一行包含整数 N,表示操作数。接下来 N行,每行包含一个操作指令,指令为
I x或Q x中的一种。输出格式:
对于每个询问指令
Q x,都要输出一个整数作为结果,表示 x
在集合中出现的次数。每个结果占一行。数据范围: 1 < = N < = 2 ∗ 1 0 4 1 <= N <= 2*10^4 1<=N<=2∗104
- 题目来源:AcWing:835.字符串统计
#include<iostream>
#include<string>
#include<algorithm>
using namespace std;
const int N = 2e5+10;
int son[N][26], cnt[N], idx = 0; //0号结点是根结点,空结点。
//新插入一个字符串(可重复插入)
void insert(string ss)
{
int p = 0; //从根节点往下遍历,找到空结点后插入新字符,并cnt标记出现次数++
for(int i = 0; i < ss. size(); i++) //树叉深度为ss的长度
{
int u = ss[i] - 'a'; //找到26个单词中的某个
if(!son[p][u]) son[p][u] = ++idx; //向下遍历,不存在该字母,则建立该字母结点,存在则直接执行下面语句
p = son[p][u]; //子结点
}
cnt[p]++; //最后会停在字母最后一个单词处
}
//查询和插入类似
int Query(string ss)
{
int p = 0; //根结点
for(int i = 0; i < ss.size(); i++)
{
int u = ss[i] - 'a';
if(!son[p][u]) return 0; //不存在该单词
p = son[p][u];
}
return cnt[p];
}
int main()
{
ios::sync_with_stdio(0);
cin.tie(0),cout.tie(0);
int n;
cin>>n;
while(n--)
{
char op;
string ss;
cin >> op;
cin >> ss;
if(op == 'I')
{
insert(ss); //新添加一个字符串,字符串可重复出现,通过cnt标记出现次数
}
else
{
//查询某个字符串出现次数
cout<<Query(ss)<<endl;
}
}
return 0;
}
-
由以上代码看出:
- 前缀树是一个牺牲空间换取时间的算法,其
son[N][26]每层存1个字符,故图上虽然显示多个结点在同一层,但实际上,每一层有26个结点,但只有一个结点用上。 - cnt[]用于统计第几层有单词,单词出现次数。
- 前缀树是一个牺牲空间换取时间的算法,其
-
字典树的应用广泛,是后续的回文树,AC自动机等算法的基础。
-
常见的应用场景有:
- 字符串的快速检索,时间复杂度为 O ( l o g M ) , M 为字符串长度 O(logM),M为字符串长度 O(logM),M为字符串长度
- 字符串排序
- 求单词的最长公共前缀。
- 求N个整数的最大异或对。















 591
591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









